
联邦学习 (FL) 研究通常从一个看似简单的问题开始:我们接下来应该尝试什么?在实验开始之前,新的聚合规则、FedProx 系数、服务器优化器设置、SCAFFOLD 变体或模型架构调整可能看起来都很有前景。
运行结束后,更棘手的问题开始出现:更改是否确实改善了指标?比较公平吗?这台升降机值得运行吗?创意应该保留、缩小范围还是放弃?
本文将介绍一个新的 NVIDIA FLARE 示例,展示有界 AI 智能体 动作、固定基准合同、实验分类帐、基于文献的恢复和可复制的报告如何帮助 FL 研究人员更快地评估更多想法。
NVIDIA FLARE 中的 Auto-FL 是什么?
NVIDIA FLARE Auto-FL 是一个 AI 驱动的自动化研究循环,旨在测试和优化联邦学习策略。
这个想法很简单:从类似的基准任务开始,为智能体提供清晰的研究控制平面,设置固定的训练预算,限制突变表面,并将每个结果记录在实验分类帐中。之后,智能体可以自主迭代候选 FL 策略,同时保留 FLARE 客户端 API 和 Recipe API 合同。
Auto-FL 没有将开放式研究问题交给智能体,而是从公平、可比较的基准开始:具有固定训练预算和一致评分的有界 FL 模拟。根据该共享基准,智能体可以在结构化工作流中探索候选 FL 策略,以保持协议的稳定性、保持比较可衡量性并追踪结果。
智能体主导的实用实验循环应受到足够的限制,以避免破坏 FL 合同,可测量到足以比较想法,足够稳定,适合长期运行的自主活动,并且足够详细,可将已完成的 Auto-FL 活动转化为可复制的来源报告,而不仅仅是一个充满日志的目录。
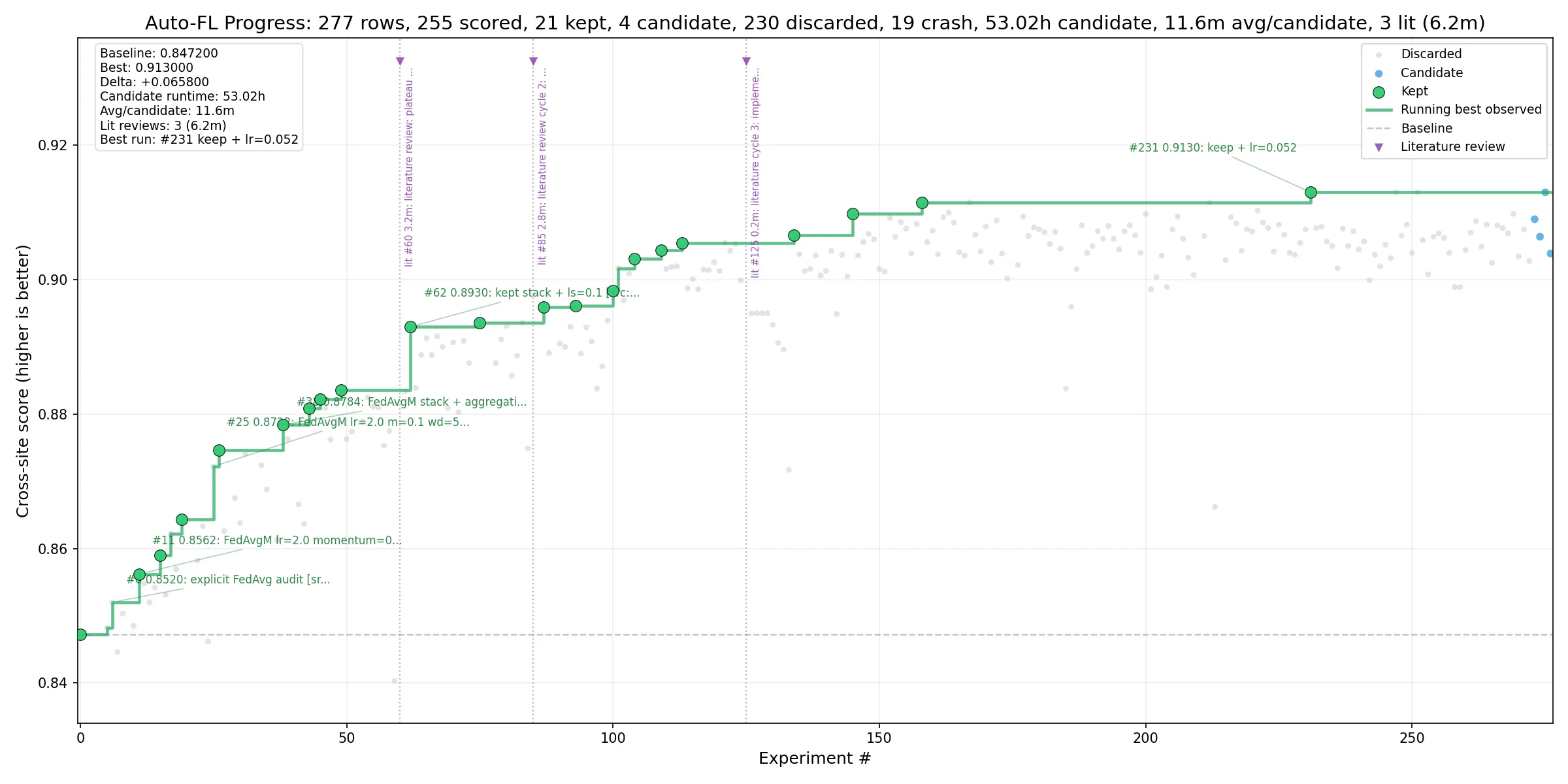
图 1 显示了 NVIDIA FLARE CIFAR-10 模拟工具的 Auto-FL 活动进度。每个点表示实验总帐中记录的候选结果;灰色点表示丢弃结果,蓝色点表示活跃候选结果,绿色点表示保留运行结果,绿色步进线表示一段时间内观察到的最佳跨站点评估分数,紫色线表示记录的文献 – 审查事件。
Auto-FL 如何明确研究循环?
编码代理对于快速进行复杂的代码更改非常有用。FL 实验不同于普通的本地模型调优,因为实验的正确性取决于服务器、客户端、模型更新、元数据、数据拆分和评估逻辑之间的合同。应聘者可以提高报告的分数,同时悄无声息地更改要比较的内容,例如,通过改变评估数据、模型容量、通信预算、本地计算或服务器 – 客户端更新语义。
Auto-FL 明确了研究循环。智能体从 program.md 开始,充当控制平面。然后,它提出有界限的更改,运行相同的基准预算,提取可比分数,将结果附加到 results.tsv,并使用分类帐来决定要保留或丢弃的候选项。人类可以随时中断活动并分析实验历史记录。
Auto-FL 提供哪些组件?
Auto-FL 将运行该操作模型所需的组件打包在一个地方。它包括任务配置文件中的即用型实验工具。job.py 中的 FLARE 基准 recipe、client.py 中的客户端 API 训练循环、自定义 FL 聚合 Hook、其他模型和训练实用程序,以及突变护栏。该软件包还包括运行脚本、绘图实用程序、模板以及已完成活动的报告技能。
任务配置文件可以使用 FedAvg、FedOpt 式服务器更新、FedAdam、SCAFFOLD、聚合中值和 FedProx Hook 来定义受支持的策略面。Auto-FL 还支持边界架构搜索。这一点很重要,因为架构搜索可以将联合算法的比较转化为不受控制的模型容量比较。
| 组件 | 类别 | 角色 |
program.md |
主要切入点 | 面向智能体的研究控制平面 |
job.py 和 client.py |
任务配置文件 | 适用于 FL 实验的 FLARE Recipe API 和 Client API 工具 |
custom_aggregators.py |
任务配置文件 | FedAvg、FedOpt/ FedAdam、SCAFFOLD、medium 和相关 hook |
mutation_schema.yaml |
任务配置文件 | 用于智能体变化的有限突变表面 |
results.tsv |
Ledger | 针对分数、运行时、状态、目标、描述和构件进行实验性分类帐 |
plot_progress.py |
可用性 | 由总帐生成的进度图 |
autofl-nvflare |
技能 | 基于 NVFlare 的 Auto-FL 工具,遵循 自动搜索 式循环 |
autofl-nvflare-report |
技能 | 针对已停止运行的活动的活动后报告流程 |
Auto-FL 如何将智能体主导的编码转变为受控的实验工作流程?
最重要的转变是运营。Auto-FL 可将智能体主导的编码转变为受控的实验工作流程。智能体读取控制平面、审查文献、提出候选表面、仅变异允许的表面、运行实验、提取分数、记录结果,并决定是否保留、缩小或丢弃候选表面。
控制平面位于 program.md 中。捆绑的本地技能文件在操作规则中指导智能体。这使得人类能够保持研究主导的角色:定义问题、设置预算、决定允许哪些突变以及审查总帐,而 AI 智能体则执行重复性工作,尝试有界候选策略并记录结果。
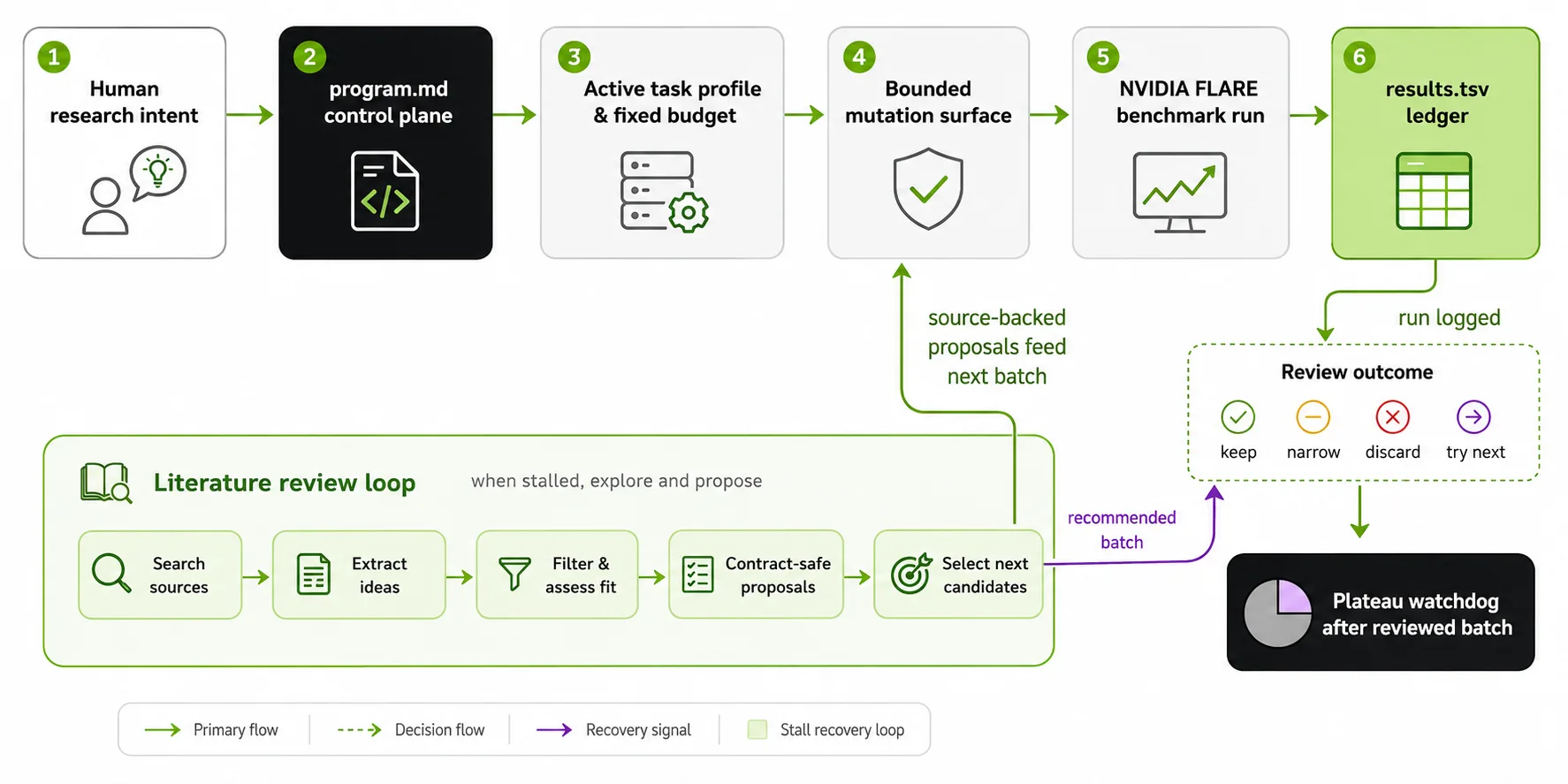
图 2 展示了以文献为依据的 Auto-FL 研究循环。工作流始于研究意图、program.md、活动任务配置文件、固定预算和有界突变表面。候选 FLARE 运行时将结果附加到 results.tsv;审核的批量会被保留、缩小、丢弃,或用于选择下一个候选批量。
在进展稳定时,工作流进入结构化文献审查循环,执行由来源支持的搜索、提取挑战卡、筛选和评分提案卡、记录文献事件,并将合同安全的提案返回到同一边界实验循环。
基于文献的恢复有什么作用?
Auto-FL 可跟踪总帐 (results.tsv) 中的性能。在分类帐显示搜索方向已停止后,有用的活动不应继续进行局部小更改。因此,我们在这一时刻引入了基于文献的恢复路径。
智能体使用分类帐来总结当前的最佳堆栈、最近的候选堆栈、重复崩溃、无效或更糟糕的想法以及活跃的突变合同。当运行似乎处于停滞状态时,工作流将从本地扫描转移到源代码支持的文献循环。目标是停止猜测,确定活动遇到的故障模式,然后返回少量合同安全提案。
在文献循环中,智能体填写结构化工作表,搜索相关方法,提取挑战卡,创建提案卡,过滤重复和先前失败的想法,并根据预期收益、实施风险、合同安全、证据、新颖性和运行时成本对提案进行评分。然后,选定的提案重新进入同一边界实验循环:仅更改允许的表面,在固定任务合同下运行,提取可比分数,并将结果附加到分类帐中。
Auto-FL 最终报告中包含哪些内容?
在人类手动停止 Auto-FL 活动后,报告技能将用于包含 results.tsv 的实验分支。它会创建最终进度图、编写报告并提交报告伪影。
这份最终报告是连接自主迭代和研究人员审查的桥梁。它总结了基准和最佳分数、绝对和相对提升、运行时成本、最终堆栈、崩溃注释、无效或较差的想法,以及推荐的下一步实验。在 Auto-FL 循环中,丢弃的候选项在已提交的分类帐中仍然可见,而保留的代码更改则提交到实验分支上。智能体和人类研究人员可以利用该记忆来避免再次尝试相同的低价值想法。
如何根据您的数据集和任务调整 Auto-FL?
除了默认的 CIFAR-10 模拟之外,Auto-FL 模式适应性强。通过将主要控制平面与任务配置文件 (指定数据集、指标和突变约束) 解,研究人员可以将相同的自主实验学科应用于各种模型系列,而无需重建底层工具。
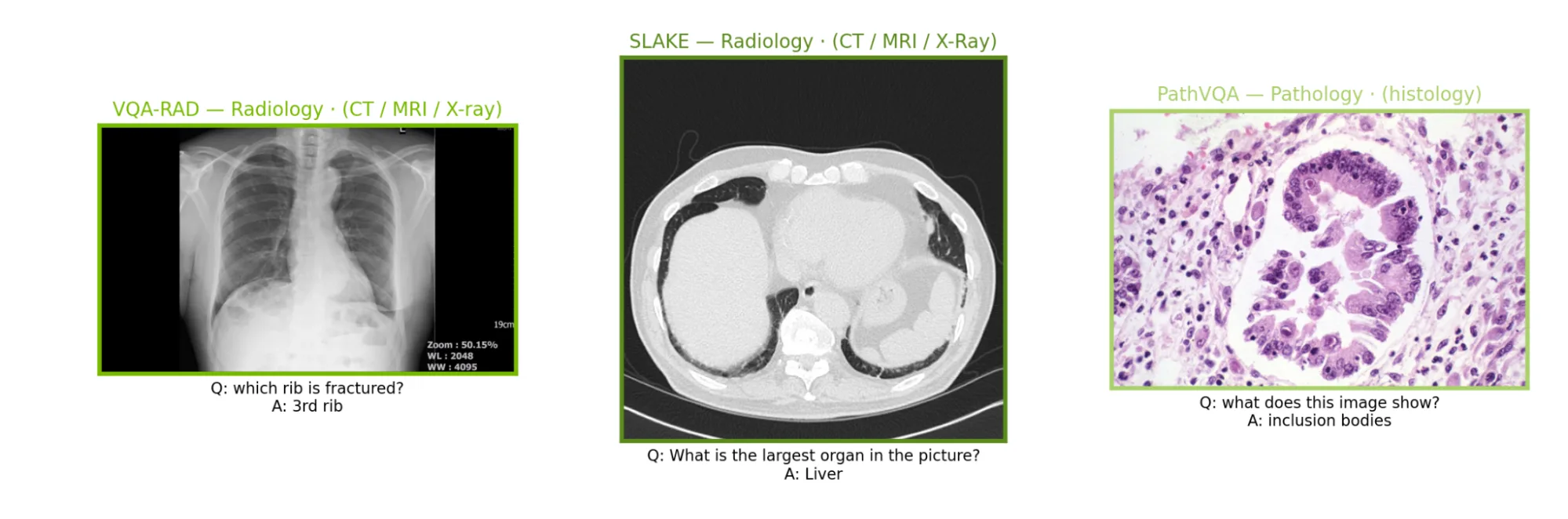
为展示这种灵活性,本示例中包含了医学视觉语言模型 (VLM) 任务。此示例将联邦 Qwen3-VL LoRA 训练工作流集成到 NVIDIA FLARE 客户端和 recipe API 中。该设置模拟了三个不同的医疗数据站点:VQA-RAD、SLAKE 和 PathVQA。这种联合方法侧重于 LoRA 适配器,并使用 token-level F1 进行评估。
同样,任务配置文件是有意限制的。它修复了站点映射、提示和评估语义、模型参考、适配器等级、数据限制、轮次数、种子策略、最终评估客户端和运行时上限。在此合同中,智能体可以探索任务安全的选择,例如学习率、本地优化器步骤、站点特定的学习率扩展、梯度累积、FedProx 式正则化和 LoRA 聚合变体。
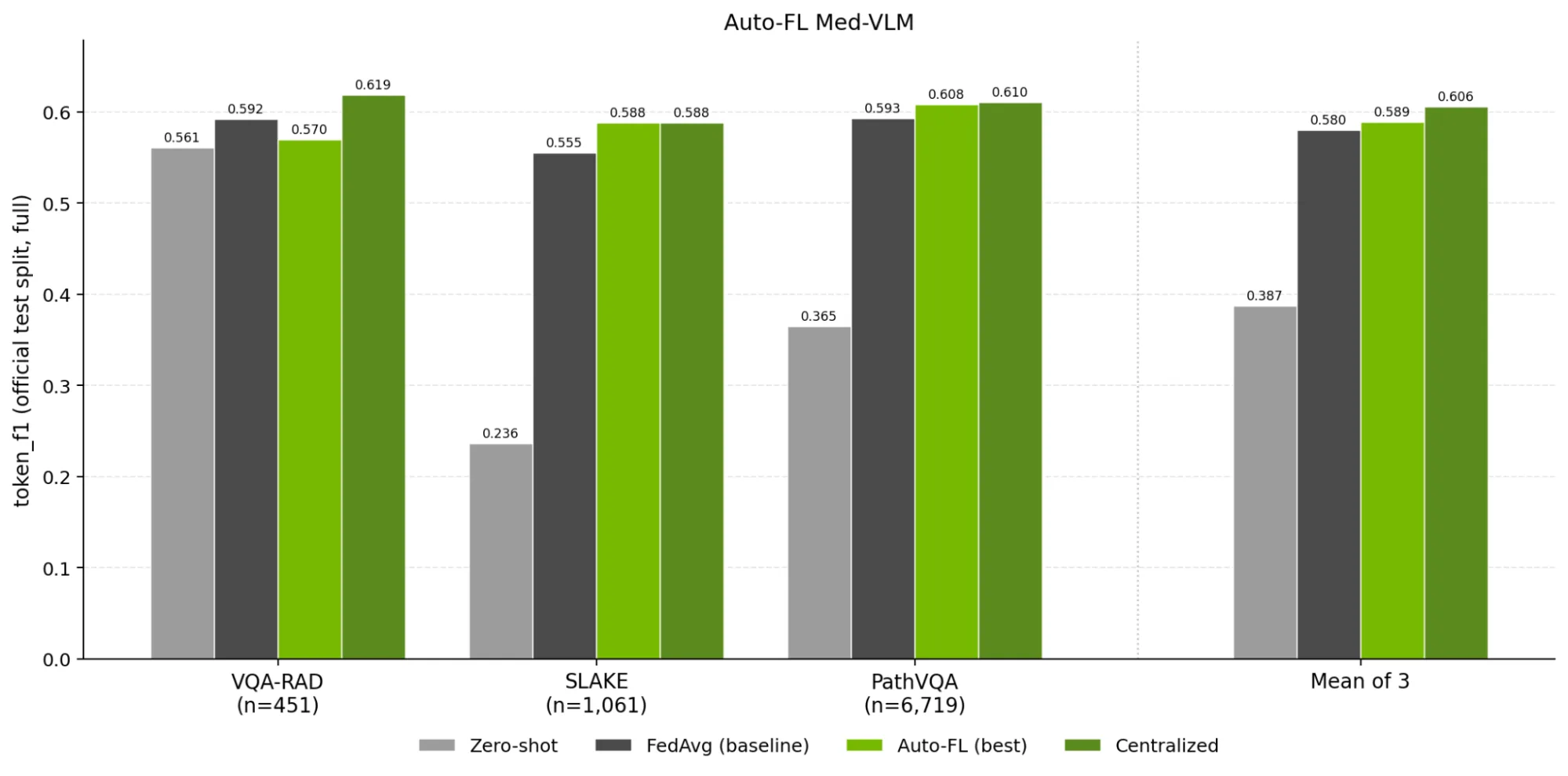
通过使用相同的 Auto-FL 技能和主要切入点,与零样本和基准性能相比,智能体可以改进此特定任务配置文件的结果,如图 4 所示。直条在每个数据集测试拆分上显示 token-F1。Auto-FL 的收益集中在更难分布的站点上,而不是在数据集之间保持一致。
开始使用 NVIDIA FLARE Auto-FL
将 Auto-FL 研究示例 用作起点,而不是固定的支架。首先,运行基准并检查生成的分类帐。然后,根据您自己的 FL 问题、数据集和任务调整突变表面和评分合同。模式是可移植的:保持预算不变,保持指标可比性,使突变表面显式显示。您可以通过调整特定于任务的配置文件和脚本 (例如 任务配置文件 和 mutation 模式 ),定义任务详细信息,从而使这一概念适应其他场景。
使用编码智能体的自动 FL 技术并不神奇。这是一个实用的支架,可以更快地提出更好的 FL 研究问题。该价值来自智能体周围的结构:控制平面、专用文献回顾循环、安全突变面、固定预算、可比分数以及记录每个候选项的分类帐。有了这些组件,智能体可以承担 FL 实验中的大部分重复性工作,同时保持研究人员所需的可比性和再现性。