
智能体交换必须保留结构化交互:助手通过一次或多次工具调用进行交错推理,随后用户轮流将相应的工具结果返回至模型上下文。推理回放依赖于模型和回合制:一些推理应该保留,而一些应该放弃。
推理引擎负责支持这种更具表现力的交互模型,并生成正确分割的 API 结果。在连接的线束使用响应之前,需要进行工具调用解析和推理解析。编码等高价值代理式工作流还依赖于响应灵敏的线束体验:推理细分、工具调用事件和请求元数据需要随着回合的展开而返回,而不是在最终文本响应后才到达。
本文将分享使用 NVIDIA Dynamo 运行真实代理客户端的实践经验:我们如何增强解析器和 API 覆盖范围、优化流式传输行为,并将这些解析器层级提取为独立且可复用的模块。
这些更改基于第一篇博文所述的性能考量,该博文重点介绍了代理推理背后的服务架构,包括前端、路由器和 KV 缓存管理。后续工作则聚焦于正确性、用户体验的一致性以及性能优化。
代理式线束仍在快速发展。Claude Code、Codex 和 OpenClaw 通过不同的 API 表面暴露了许多相同的压力点,因此以下示例重点介绍了自定义服务堆栈需要重现的核心行为。
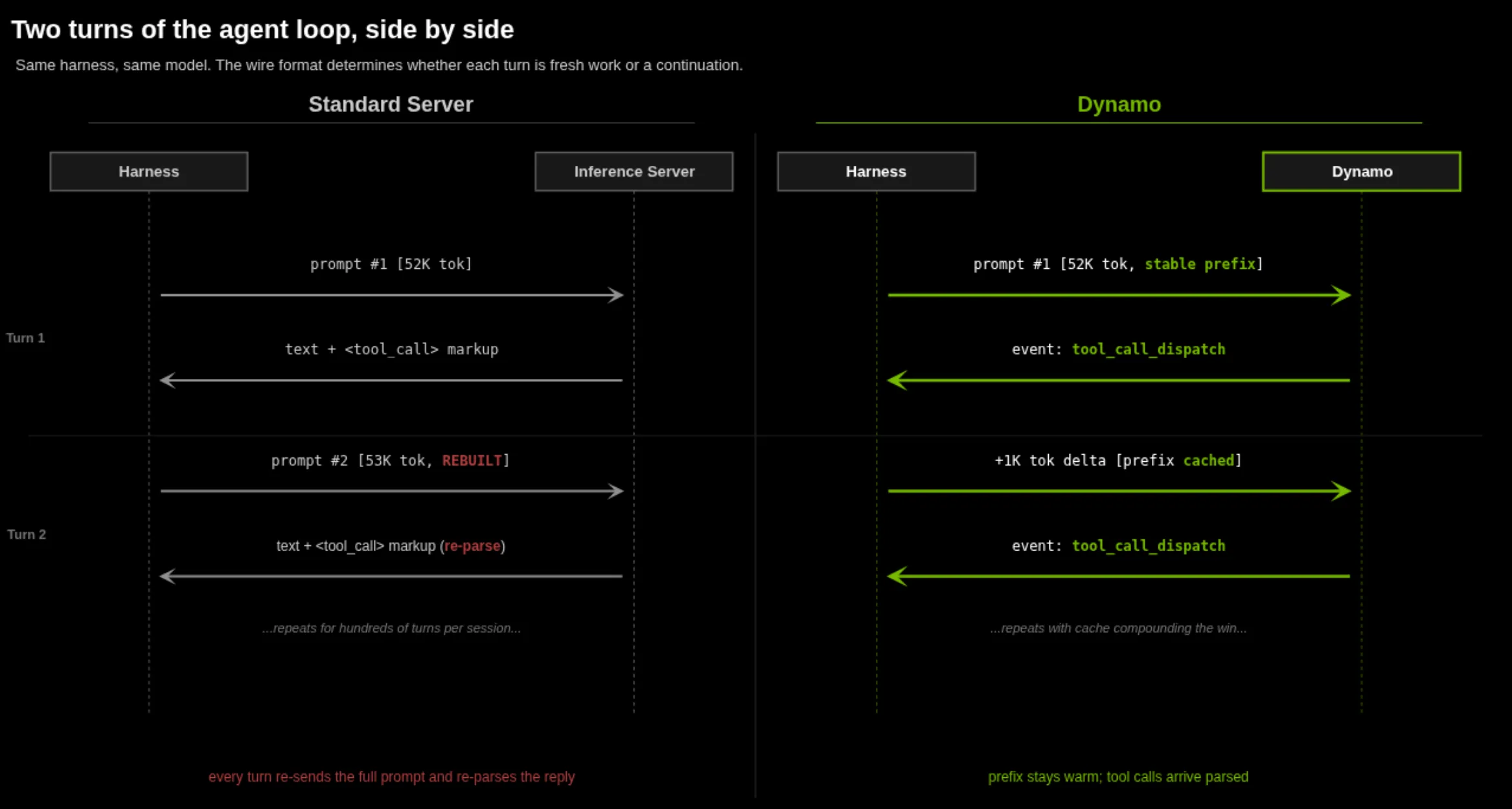
面向线束的 Dynamo 设置
我们的实验使用了新发布的 nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4 模型,但同样的问题也适用于模型、推理解析器和工具调用解析器。
要重现我们的结果,请使用兼容 Anthropic 的 API 和保留提示、推理和工具状态的标志配置前端:
--enable-anthropic-api向工具公开 Anthropic Messages API。许多工具可以回退到默认的 Messages API,但这种体验会降低。--strip-anthropic-preamble删除了 Anthropic 计费报文头,该报文头可能会破坏 KV 重用的稳定性。--enable-streaming-tool-dispatch允许完整的工具调用在解码后立即开始执行,而不是等待回合结束。
综合所有这些内容:
python -m dynamo.frontend \ --http-port 8000 \ --enable-anthropic-api \ --strip-anthropic-preamble \ --enable-streaming-tool-dispatch |
在工作端,此部署中的重要设置为:
--dyn-tool-call-parser <parser>和--dyn-reasoning-parser <parser>以线束所期望的模型特定格式重建工具调用和推理块。这些解析器还可控制是否应保留、转换或放弃先前回合的推理。
提示稳定性是缓存重用的关键
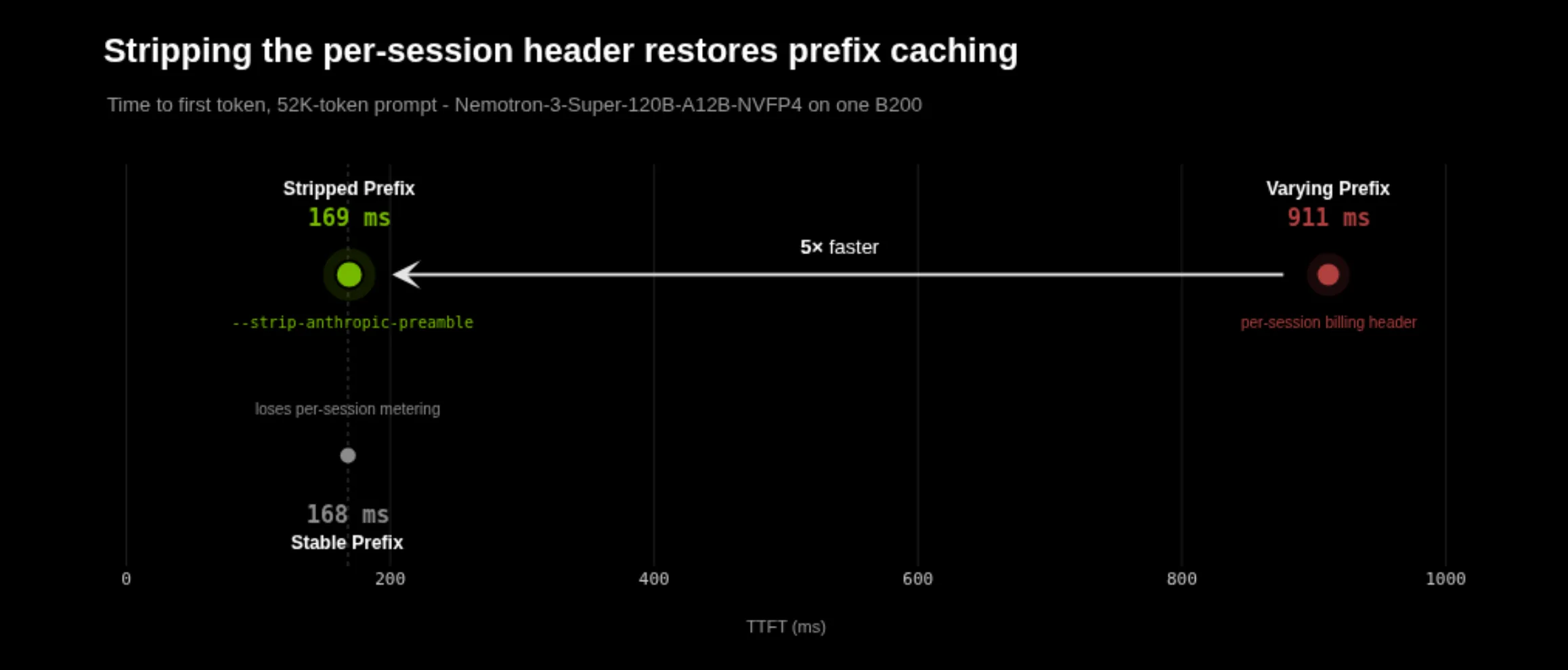
克劳德 Code 会发送数千个词元可重复使用的提示支架,其中大部分旨在跨用户和会话保持相同。但是,每个提示词都以会话特定的计费报文头开头,当请求被路由到自定义端点而未被剔除时,这会导致缓存丢失:
x-anthropic-billing-header: cc_version=0.2.93; cch=abc123def456==;You are Claude Code, an interactive CLI tool... |
这些头文件会毒害 KV 缓存,并阻止其被重复使用,即使在同一用户的会话中也是如此。位置为 0 的变化行意味着每个新会话都以不同的词元前缀开始,因此其背后的稳定指令和工具定义永远不会为了重复使用而整齐排列。
为了恢复 KV 缓存的重复使用,Dynamo 添加了 --strip-anthropic-preamble。该修复在机械上是小的,在操作上是重要的:在词元化之前删除不稳定的计费报文头,以便稳定提示从词元 0 开始。
测量的影响很大。在采用 52K-词元提示的 Dynamo NVIDIA B200 部署中,稳定前缀以 168 毫秒的 TTFT 速度着陆。在前缀中保留每个会话的不同报文头,将其推送至 912 毫秒。在分词之前删除计费报文头,返回到了 169 毫秒。在此工作负载中,不稳定报文头每次请求的处理时间为 744 毫秒,并将可重复使用的系统提示变成冷预填充。对于使用相同部署的新用户或打开新会话的相同用户,TTFT 的数量大约减少了 5 倍。
推理和工具解析的细微差别
下一阶段的推理回放并没有统一的正确形式。一些模型在普通助手转弯时故意放弃预先推理。交错工具调用的代理轮次有所不同:推理跨度通常需要始终附加到它们所解释的工具调用上。真正的合同是模型特定和回合特定的。
Anthropic 在 4 月 23 日发布的 Claude Code postmortem 中提供了该策略的具体应用实例:之前的思考可在会议恢复时被清除,以减轻缓存提示过期后重新预填充的负担。
当代推理模型往往会产生两种不同类型的辅助转弯:
- 推理,然后直接回复用户
- 推理,然后进行一次或多次工具调用
代理式模型特别擅长生成回合,其中许多推理和工具调用部分出现在单个响应中,其模式如下:
<think>reasoning_0</think> tool_call_0 <think>reasoning_1</think> tool_call_1 |
在下一回合中,每个推理范围都需要与其解释的工具调用保持连接。Dynamo 现在完全支持这种交错格式。以前,我们可以将相同的转弯重建为:
<think>reasoning_0 reasoning_1</think> tool_call_0 tool_call_1 |
如果将助手回合重建为一个通用推理块,然后是一次工具调用图块,则模型仍具有相同的词元,但会丢失使其有意义的序列和分隔符。这种分组排序源自传统模型,这些模型每次只执行一次推理跨度和一次工具调用。
除了顺序错误外,我们还发现推理过程常在下一轮开始前被过早丢弃。对某些模型而言,依次放弃先前的思考(尤其是在不调用工具的情况下)已成为一种固定行为,也是模型微调的一部分(DeepSeek-R1 是最明显的例子)。然而,在交错的代理轮次中,先验推理本应解释工具调用序列,这种过早丢弃行为就会导致错误。这一问题较难察觉,因为用户虽能在返回的响应中看到推理被正确解码,但实际上在进入下一轮之前,这些推理已在后台被悄然清除或丢弃。
我们使用 Dynamo 和 TRT-LLM 部署验证了这一点:Nemotron-3 -Super-120B-A12B-NVFP4 基于 4XB200,TP = 4,具有 --enable-anthropic-api、--strip-anthropic-preamble、--enable-streaming-tool-dispatch、nemotron_deci 推理解析器和 qwen3_coder 工具调用解析器。
综合推理和工具调用
在调用工具之前进行推理的模型会生成响应,其中 <think> 内容会先流动,然后是 <tool_call> XML。在 Nemotron 中,两个不同的解析器 (用于推理的 nemotron_deci 和用于工具调用的 qwen3_coder) 必须将该流拆分成正确的 Anthropic Messages API 内容块,而不会相互影响。
我们通过 Anthropic Messages API 发送了 5 次相同的提示:一个系统提示,指导模型逐步思考,两个工具定义 (计算器和天气) ,以及用户消息,“仔细思考 15^ 23 等于什么,然后使用计算器验证”。代表性回合的响应结构:
{ "content": [ { "type": "thinking", "thinking": "I need to calculate 15 * 23. Let me think: 15 * 20 = 300, and 15 * 3 = 45, so 300 + 45 = 345. I'll use the calculator to verify.\n" }, { "type": "tool_use", "id": "call-a3364797-3160-4e84-b567-5c495694d502", "name": "calculator", "input": { "expression": "15 * 23" } } ], "stop_reason": "tool_use", "usage": { "input_tokens": 403, "output_tokens": 95 }} |
同时串流两个解析器
流式传输路径使解析器交互更加明显。流式传输请求会生成一系列 SSE 事件,而事件类型序列会准确显示这两个解析器如何分割词元流:
1ms message_start 82ms content_block_start type=thinking 82ms content_block_delta (thinking tokens stream here, ~7ms apart) ... (~70 thinking deltas over ~520ms)602ms content_block_stop602ms content_block_start type=text602ms content_block_delta800ms content_block_stop800ms content_block_start type=tool_use800ms content_block_delta800ms content_block_stop814ms message_delta stop_reason=tool_use814ms message_stop |
思维块以词元串流词元,从 82 毫秒到 602 毫秒不等。然后出现一个简短的文本块 (原始词元流的思考区域和工具调用区域之间的空白) 。然后,tool_use 块作为单个结构化单元以 800 毫秒的速度生成。message_stop 以 814 毫秒的速度跟随。
在 PR = 7358 之前,此往返旅程并未生成正确的人类活动事件序列。修复包含三个部分:
- 推理解析的所有者:推理解析过去在多个相互竞争的层中进行。后端解析器可以将模型输出分割为
reasoning_content和 normalcontent,而 Anthropic 流转换器在将同一流映射到 Anthropic 内容块时仍试图推理<think>边界。PR# 7358 明确了所有权。如果后端路径已生成结构化推理增量,则 Anthropic 转换器会信任这些增量,并仅将其映射到响应格式中。 - 模板原生推理 (如果可用) :Dynamo 现在会检查活动中的聊天模板是否知道如何读取
reasoning_content。Nemotron 和 Qwen3 等模板会直接读取该字段,因此 Dynamo 不使用该字段,而是让模板决定要保留的先前想法数量。如果模板仅理解content,Dynamo 将回退到旧版表征:通过将<think>块插入content来保留推理,或者在模型/ 解析器策略指出先前的思考不应该延续到下一轮时将其排除在外。Rust 预处理路径 (ModelInput::Tokens) 和 Python 工作路径 (ModelInput::Text) 均使用相同的条件规则。 - 尊重每个请求的思考控制:许多模板默认使用
truncate_history_thinking=true来保存上下文。这对于普通聊天来说是合理的,但它消除了智能体工作流中之前工具调用背后的推理。Dynamo 现在仅针对实际运行推理的请求更改该行为:当配置推理解析器且客户端未禁用思考时,Anthropic 路径会设置enable_thinking=true和truncate_history_thinking=false。这样可满足下一代上下文智能体的需求,而不会更改默认的请求或模型,而这些请求或模型应该在运行时不考虑。
在我们的 B200 实验中,使用 52K-词元系统提示和包含大约 500 个词元思维的助手转向,不变的下一个转向前缀以 167 毫秒的 TTFT 速度着陆,而突变思维以 2022 毫秒的速度着陆。与更改下一轮前缀中的推理内容相比,每个请求的数量增加了 1.9 倍,约为 155 毫秒。
要点在于,线束、解析器和模板路径必须在每个模型的预期推理行为上保持一致。在普通转弯处丢弃思考可能对一个模型是正确的,而对另一个模型则是错误的。即使在允许普通转弯时,在工具调用转弯时保留交错推理可能也至关重要。在实践中,您不应该假设在 N 转弯处生成的词元会自动作为 N+1 转弯处的前缀保持不变。这是否正确取决于所服务模型的推理解析器、工具解析器和聊天模板。
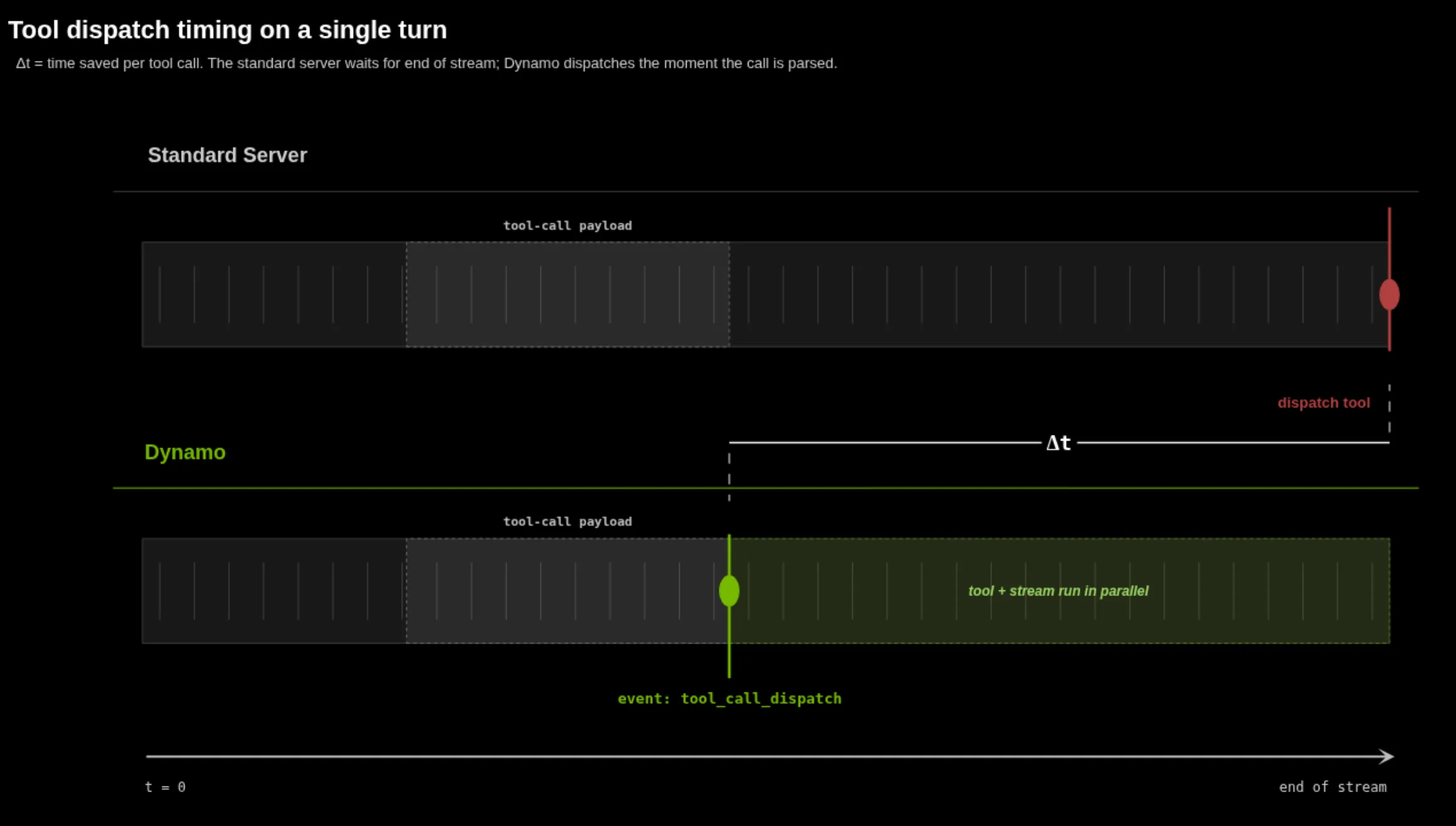
流式传输工具调用
流式传输词元可让用户感觉更灵敏、更动态。面临的挑战是保留该行为,同时仍将工具调用作为相干块。在旧的 Dynamo 路径中,推理词元正常返回串流,但工具调用一直处于缓冲状态,直到回合结束,然后立即将所有工具释放到工具上。即使模型已经决定调用什么,这也会降低响应速度并延迟工具执行。
| 州 省 自治区 直辖市 | 线束所见 | 当工具就绪情况变得可见时 |
| 缓冲 | 工具调用屏蔽块 | 仅在 finish_reason: "tool_calls" 处 |
| 内联流式传输 | 常规工具调用增量 | 一旦模型发出这些信号 |
| 发送 | 类型 event: tool_call_dispatch 侧信道 |
相同的结构完成点,但已经解析过 |
重要的过渡是从第一行过渡到后两行。此时,线束会停止等待直播结束,以了解需要采取行动。在不调度的情况下,线束会看到常规的词元流,并且必须通过累积增量并等待足够的结构出现来推理工具调用何时完成。启用“Dispatch” (调度) 后,Dynamo 可以发出类型化的 SSE 侧通道:
event: tool_call_dispatchdata: {"choice_index":0,"tool_call":{"index":0,"id":"call-...","type":"function","function":{"name":"calculator","arguments":"{\"expression\":\"42 * 17\"}"}}} |
该事件会一次性告知线束工具调用已准备好执行。没有线束侧增量组合,无需猜测参数是否完整,线束内没有自定义解析器。这使得 Dynamo 能够更轻松地与自定义线束兼容。
适用于 Claude Code 和 OpenClaw 的人类学 API 保真度
Claude Code 和 OpenClaw 都使用 Anthropic Messages API,而不仅仅是在端点后生成文本。匹配线束体验取决于一系列较小的行为,这些行为在临时测试中很容易被忽略:
GET /v1/models和GET /v1/models/{model_id}的模型元数据- 正确处理经过削减的模型 ID
- 实用的
input_tokens(以 tz 为单位) _ 43 - 接受
cache_control
在前端可访问且兼容后,两个线束都可以指向 Dynamo 与 Anthropic 兼容的端点:
ANTHROPIC_API_KEY=local-dev-token \ANTHROPIC_BASE_URL=http://localhost:8000 \ANTHROPIC_CUSTOM_MODEL_OPTION=nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4 \ANTHROPIC_CUSTOM_MODEL_OPTION_NAME="Dynamo NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4" \claude --model nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4ANTHROPIC_API_KEY=local-dev-token \ANTHROPIC_BASE_URL=http://localhost:8000 \npx openclaw agent --local -m "Say ok" --json |
此领域的修复使自定义部署更接近原生后端行为。一个具体的例子表明,与长检查清单相比,这些错误的特征更好。在启动期间,线束会直接询问所选模型的详细信息,但 Dynamo 尚未为该端点提供服务:
GET /v1/models/nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4HTTP/1.1 404 Not Found |
另一个例子是 message_start 向 input_tokens: 0 报告,即使后续的最终响应中已包含实际计数。这导致每次新回合开始时,线束中的词元数量都会暂时下降至 0。 PR #7234 通过在流开始前填充 input_tokens 修复了该 Anthropic 路径。这些计数也用于长会话的控制平面:利用上下文长度来判断何时在下一个请求超出模型窗口前压缩对话。更广泛的分词器服务变更已通过 PR #7699 单独合入,该变更为引擎处理请求之前增加了 /v1/tokenize 和 /v1/detokenize 端点,以实现精确的词元计数。
响应和 Codex 保真度
Codex 版本中同一问题位于 v1/responses 侧。通过合规性测试并不等于能提供相同的用户体验。我们发现,有一个 Responses API 请求在内部往返过程中无法保留使其成为“响应”请求(而非“聊天完成”请求)的关键字段。要保留这些字段,需对 Dynamo 的 ResponseParams 路径进行架构调整,并完成 PR #6089 中的上游类型对齐工作。
Codex 应通过兼容 OpenAI 的 Responses API 指向 Dynamo,并启用请求压缩:
OPENAI_API_KEY=local-dev-token \codex exec \ -c 'openai_base_url="http://localhost:8000/v1"' \ -c 'features.enable_request_compression=true' \ -m nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4 \ "Say ok" |
Codex 模型元数据对请求进行调整
Codex 奇偶校验在第一个 POST /v1/responses 之前开始。CLI 将配置的模型字符串解析为本地模型目录记录,生成的 ModelInfo 控制围绕模型构建的线束状态:基础指令、历史记录格式、工具注册表、推理参数、详细程度控制、图像支持、上下文会计、工具输出截断、parallel_tool_calls 和最终响应负载。
如果 Codex 附加不同的目录元数据,两个端点可以为相同的底层模型提供服务,并且仍然驱动不同的智能体行为。当请求周围的线束发生变化时,该请求可能会根据模式进行验证。
工具输出截断就是一个很有用的例子。在下一次模型回合中,Codex 不会无限回放命令输出。shell 和工具观察结果在重新进入上下文之前,会根据所选模型的目录策略进行截断。在我们测试的目录快照中,gpt-5.5 使用了:
{ "mode": "tokens", "limit": 10000 } |
相比之下,自定义端点上的 openai/openai/gpt-5.5 使用的是回退元数据:
{ "mode": "bytes", "limit": 10000 } |
这些预算并不相同。与 10000-词元限制 ASCII 重编码输出相比,10000 字节限制会在更早的时间切断结构化日志、回溯、JSON 或测试输出。对于编码代理而言,这会更改模型在测试失败、搜索命令或编译器错误后可以检查的内容。模型可能需要额外的工具调用来恢复预期目录配置文件会保留的上下文。
推理设置也是目录衍生的。当所选模型元数据显示支持推理摘要时,Codex 会发送响应 reasoning 对象。在该路径中,Codex 还会请求 reasoning.encrypted_content,以便可以轮流回放推理状态。后备元数据会删除该路径。
提示更改。在 Codex 中,从后备/ 默认配置文件切换到 gpt-5.5 目录配置文件会更改系统提示。后备提示围绕通用的 Codex 操作 (# How you work、# AGENTS.md spec、# Tool Guidelines) 组织,并强调 AGENTS.md 优先级、规划、验证和 shell 搜索习惯。gpt-5.5 prompt 是另一个指令文档 (# Personality、# General、# Working with the user) ,它将智能体定义为实用的软件工程师,并在代码库读取、本地模式重用、范围编辑、脏工作树、apply_patch、协作更新和最终答案格式方面提供了更有力的指导。因此,目录锯齿会影响基础行为策略以及截断和推理等请求字段。
我们直接在 SWE-Bench Verified 的 50 任务子集中看到了这一点。在此设置中,这两条路径都达到了 OpenAI 服务的 GPT-5.5,区别在于端点及其附加的模型目录记录 Codex。当自定义端点使用模型 ID openai/openai/gpt-5.5 而不与 gpt-5.5 目录配置文件关联时,Codex 会使用通用的回退行为。在一次运行中,回退配置文件发出的工具调用数量大约是之前的一半:
| 目录配置文件 | 工具调用总数 | 每项任务 |
gpt-5.5 配置文件 |
2087 | 41.7 |
| 后备配置文件 | 1048 | 21.0 |
| 三角洲 | -1039 | -20.8 |
配对比较指出每个任务的方向相同:gpt-5.5 配置文件在 50 / 50 任务中使用更多工具,而后备配置文件在 0 / 50 中使用更多工具。排列测试将差值设为 p < 0.001 以下。
在添加模型目录别名以便 openai/openai/gpt-5.5 继承预期 gpt-5.5 配置文件后,相同的 50 个任务设置变得更加接近:
| 目录配置文件 | 工具调用总数 | 每项任务 |
gpt-5.5 配置文件 |
2081 | 41.6 |
| 别名支持的自定义配置文件 | 2205 | 44.1 |
| 三角洲 | + 124 | + 2.5 |
在本次运行中,其余差异在统计学上并不显著:置换测试大约为 p = 0.22,配对方向混合 ( 20 / 50 任务倾向于原生配置文件,28 / 50 倾向于别名支持的配置文件,2 / 50 绑定) 。
对于 Dynamo 而言,这意味着需要在目录和请求塑造层以及 HTTP 模式层评估 Codex 兼容性。如果 Codex 无法将模型 ID 解析到预期配置文件中,则在 Dynamo 收到请求之前,后备默认值可能会更改截断、搜索工具可用性、详细程度控制、推理摘要支持和并行工具调用支持。
下一步是什么
Dynamo 现在具备了 nvext.agent_hints: latency_sensitivity, priority, osl, and speculative_prefill。借助这些字段,线束能够传达更多关于转弯的信息,而不仅仅是提示词。等待用户回复的会话与处理长背景工具序列的会话有所不同,API 现在可以体现这些差异。
在 v1.1.0 系列中,Dynamo 开始将更多智能体栈作为可复用的模块提供。协议、解析器和分词器层被独立地进行版本控制,形成独立工具,包括 dynamo-protocols、Dynamo 解析器和 dynamo-tokenizers。这使得团队能够构建或自定义面向线束的服务路径,而无需将 Dynamo 的内部组件复制到单独的项目中。同时,这也为连接 AutoResearch 等运行时间较长的系统提供了桥梁。第一篇博文解释了代理式工作负载为何会对服务堆栈造成压力。本文则聚焦于正确运行这些工作负载所需的面向线束的契约,并为基于 Dynamo 端点 的高效长期代理奠定基础。