
2025 年,NVIDIA 与 Black Forest Labs (BFL) 合作优化 FLUX.1 文本转图像模型系列,在 NVIDIA Blackwell 架构的 GeForce RTX 50 系列 GPU 上实现 FP4 精度的图像生成性能。
作为潜在扩散模型的自然延伸,FLUX.1 Kontext[dev]验证了上下文学习不仅适用于大语言模型(LLM),同样也是视觉生成模型的一种可行技术。为了提升使用体验,NVIDIA 与 BFL 合作,通过低精度量化实现了接近实时的编辑效果。
FLUX.2 实现了一次重大飞跃,提供了媲美顶尖企业级模型的公开多图像参考与质量。然而,由于 FLUX.2 [dev] 需要大量计算资源,BFL、Comfy 与 NVIDIA 展开合作并取得重要突破:将 FLUX.2 [dev]的内存需求降低 40% 以上,并通过 ComfyUI 实现本地部署。这种采用 FP8 精度的优化,使 FLUX.2[dev]成为图像生成领域广受欢迎的模型之一。
随着 FLUX.2[dev]成为开放权重模型的标杆,NVIDIA 团队与 BFL 合作,现很高兴分享其性能的又一次飞跃:在功能强大的数据中心 NVIDIA Blackwell GPU(包括 NVIDIA DGX B200 和 NVIDIA DGX B300)上实现 FLUX.2[dev]的 4 位加速。
本文将介绍团队在这些 NVIDIA 数据中心架构上用于加速 FLUX.2[dev]的各类推理优化技术,包括代码片段与入门步骤。这些优化措施的综合应用显著降低了延迟,实现了数据中心 GPU 的高效部署。
使用 FLUX.2 时 BF16 与 NVFP4 的视觉效果对比 [dev]
在深入探讨细节之前,请先查看 FLUX.2[dev]在默认 BF16 精度下的输出质量,以及采用 NVFP4 后获得的极为相近的结果(图 1 和 2)。
图 1 的提示是:“一只猫在舒适的沙发上安静地打盹。沙发位于一棵从月球表面生长出来的高大树木之上。地球悬挂在远处,是黑暗太空中一颗充满生机的蓝绿色明珠。一艘流线型的宇宙飞船停靠在附近,为整个场景投射出柔和的光线,而整幅数字艺术构图则散发出一种梦幻般的氛围。”

图 2 中的提示是,“一对穿着正式晚礼服回家的油画在没有雨伞的情况下陷入了倾盆大雨。”在这种情况下,识别差异更具挑战性。较为明显的是 BF16 图像中士的微笑和 NVFP4 图像背景中的多个雨伞。除此之外,这两幅图像的前景和背景都保留了大部分精细细节。

优化 FLUX.2 [dev]
FLUX.2[dev]模型由三个关键组件构成:文本嵌入模型(特别是 Mistral Small 3)、扩散 Transformer 模型以及自动编码器。NVIDIA 团队利用 TensorRT-LLM/feat/visual_gen 分支中暂存的原型运行时,将多种优化技术应用于开源扩散器的实现。
- NVFP4 量化
- 时间步嵌入感知缓存(TeaCache)
- CUDA 图
- Torch 编译
- 多 GPU 支持
NVFP4 量化
NVFP4 通过引入二级微块扩展策略,推进了微缩放数据格式的概念。该方法旨在显著减少精度损失,并包含两种不同的机制:按张量缩放和按块缩放。
每张量缩放是以 FP32 精度存储的值,用于调整整体张量分布,可进行静态或动态计算。相比之下,每块缩放通过将张量划分为包含 16 个元素的块,实时动态计算得出。
为更充分地提升灵活性,用户可以选择以更高精度保留特定层,并应用动态量化,如下所示的 FLUX.2[dev]示例所示:
exclude_pattern =
r"^(?!.*(embedder|norm_out|proj_out|to_add_out|to_added_qkv|stream)).*"
使用以下语句启用 NVFP4 计算:
from visual_gen.layers import apply_visual_gen_linear
apply_visual_gen_linear(
model,
load_parameters=True,
quantize_weights=True,
exclude_pattern=exclude_pattern,
)
TeaCache
TeaCache 技术用于加速推理过程。该技术利用扩散过程中生成的先前隐变量,有条件地跳过部分扩散步骤。为量化这一效果,我们进行了测试:在包含 20 个提示 且推理步数为 50 步的场景中,TeaCache 平均跳过了 16 步,使推理延迟降低了约 30%。
为确定 TeaCache 超参数的最优配置,我们采用了网格搜索方法。该配置可在计算速度与生成质量之间实现良好平衡。
dit_configs = {
...
"teacache": {
"enable_teacache": True,
"use_ret_steps": True,
"teacache_thresh": 0.05,
"ret_steps": 10,
"cutoff_steps": 50,
},
...
}
缓存机制的缩放系数通过经验确定,并采用三阶多项式进行近似计算。该多项式利用由文本转图像及多参考图像生成示例构成的校正数据集进行拟合。
图 3 说明了这种经验方法,展示了原始校准数据点以及由此生成的三度多项式曲线(以红色显示),该曲线用于建模调制输入差与模型输出差之间的关系。
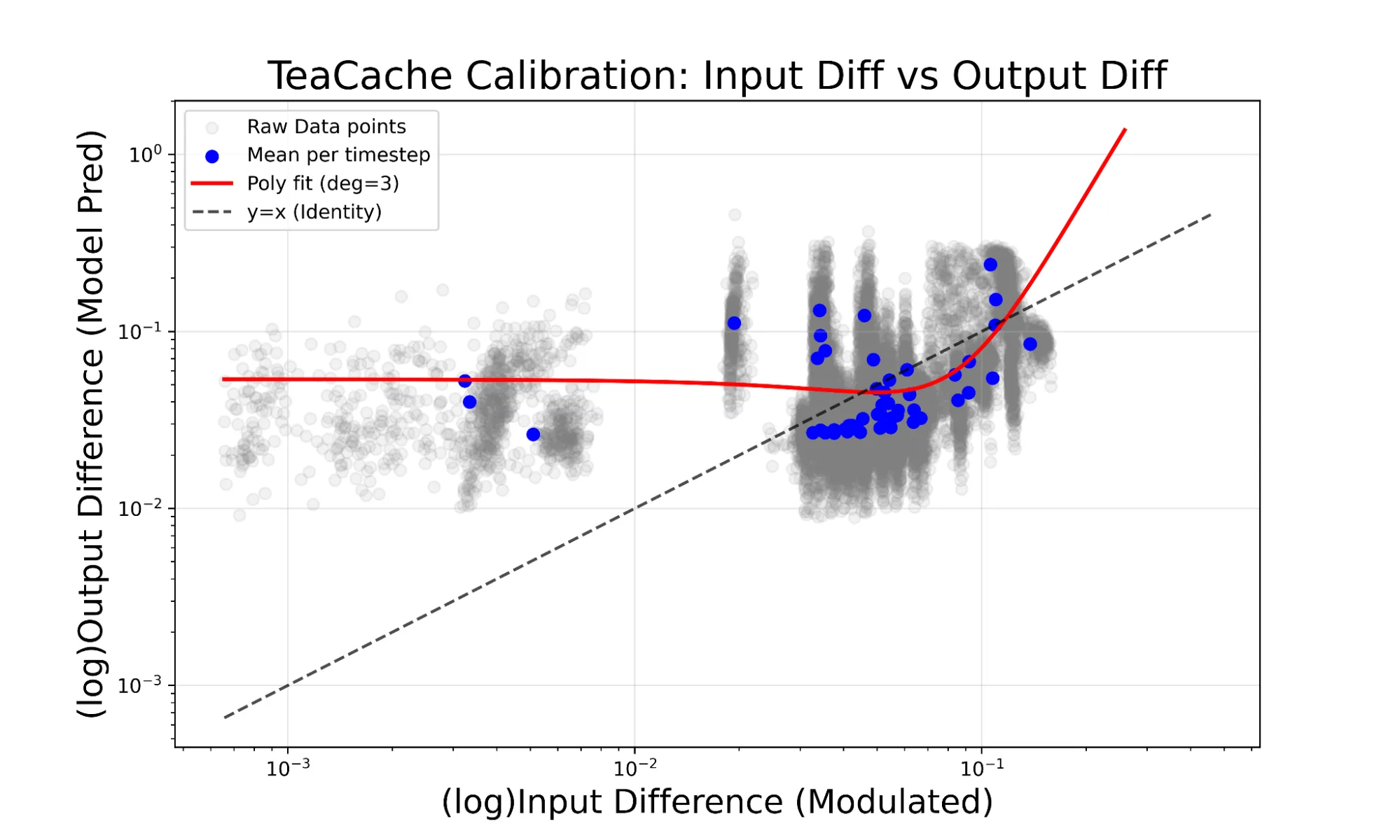
CUDA 图形
NVIDIA TensorRT-LLM visual_gen 提供了一个现成的封装器,支持 CUDA 图形捕获。只需导入该封装器并替换 forward 函数即可。
from visual_gen.utils.cudagraph import cudagraph_wrapper
model.forward = cudagraph_wrapper(model.forward)
Torch 编译
在团队的所有实验中,除基准运行外,均启用了 torch.compile,因为该功能在 FLUX.2[dev]中默认未启用。
model = torch.compile(model)
多 GPU 支持
使用 TensorRT-LLM 启用多个 GPU 进行 visual_gen 包含四个步骤:
- 修改
model.forward函数以插入处理 GPU 间通信的代码 - 将模型中的 attention 实现替换为
ditAttnProcessor - 选择合适的并行算法并在 config 中设置并行规模
- 使用 Torchrun 启动
以下代码段提供了一个示例。将拆分代码插入 model.forward 的开头,可在多个 GPU 上分散输入数据:
from visual_gen.utils import (
dit_sp_gather,
dit_sp_split,
)
# ...
hidden_states = dit_sp_split(hidden_states, dim=1)
encoder_hidden_states = dit_sp_split(encoder_hidden_states, dim=1)
img_ids = dit_sp_split(img_ids, dim=1)
txt_ids = dit_sp_split(txt_ids, dim=1)
随后,在 model.forward 的末尾插入 gather 代码,然后返回:
output = dit_sp_gather(output, dim=1)
然后,将原始的 attention 实现替换为所提供的 attention 处理器,以确保在多个 GPU 之间实现正确的通信:
from visual_gen.layers import ditAttnProcessor
# ...
def attention(...):
# ...
x = ditAttnProcessor().visual_gen_attn(q, k, v, tensor_layout="HND")
# ...
在配置中设置合适的并行规模。例如,要在四个 GPU 上使用 Ulysses 并行:
dit_config = {
...
"parallel": {
dit_ulysses_size": 4,
}
...
}
随后,调用 setup_configs API 以激活配置:
visual_gen.setup_configs(**dit_configs)
使用多个 GPU 时,必须通过 torchrun 启动脚本。TensorRT-LLM visual_gen 将利用 torchrun 提供的等级信息,正确完成所有通信与任务分配。
性能分析
所有推理优化均集成于一个端到端的 FLUX.2 [dev]示例—低精度内核、缓存技术及多 GPU 推理。
如图 4 所示,与 NVIDIA H200 相比,NVIDIA DGX B200 架构的性能提升了 1.7 倍,即使在默认的 BF16 精度下亦是如此。此外,通过逐步应用推理优化技术(包括 CUDA Graphs、torch.compile、NVFP4 精度和 TeaCache),单个 B200 的性能可从该基准进一步提升至高达 6.3 倍的加速效果。
最终,与当前行业标准 H200 相比,采用 2 – B200 配置的多 GPU 推理可实现 10.2 倍的性能提升。
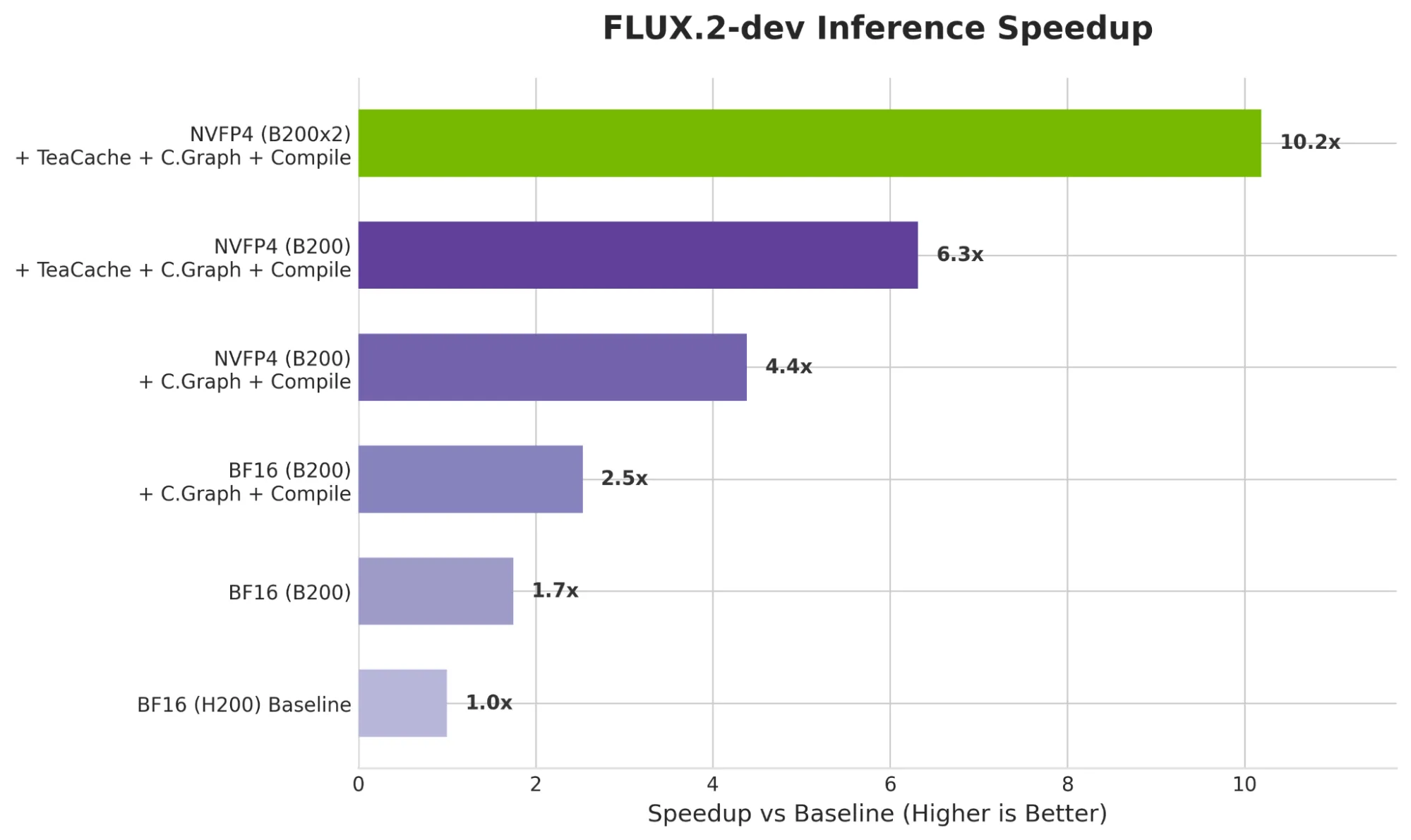
基准为原始的 FLUX.2 [dev],未进行任何优化,且未启用 torch.compile。优化版本系列则包含启用 torch.compile、CUDA Graphs、NVFP4 及 TeaCache。基准测试采用的扩散步骤数为 50。
该团队发现,在单个 GPU 上,NVFP4 和 TeaCache 在加速与输出质量之间实现了良好的权衡,分别达到了约 2 倍的加速效果。torch.compile 是一种广为人知的近似无损加速技术,大多数开发者对其较为熟悉,但其提升幅度相对有限。CUDA 图形主要对多 GPU 推理具有优势,可在 NVIDIA B200 上通过多 GPU 实现逐步扩展。最后,实践表明,通过文本编码器的 FP8 量化,整个工作流表现出高度可靠性,为大规模部署带来了额外优势。
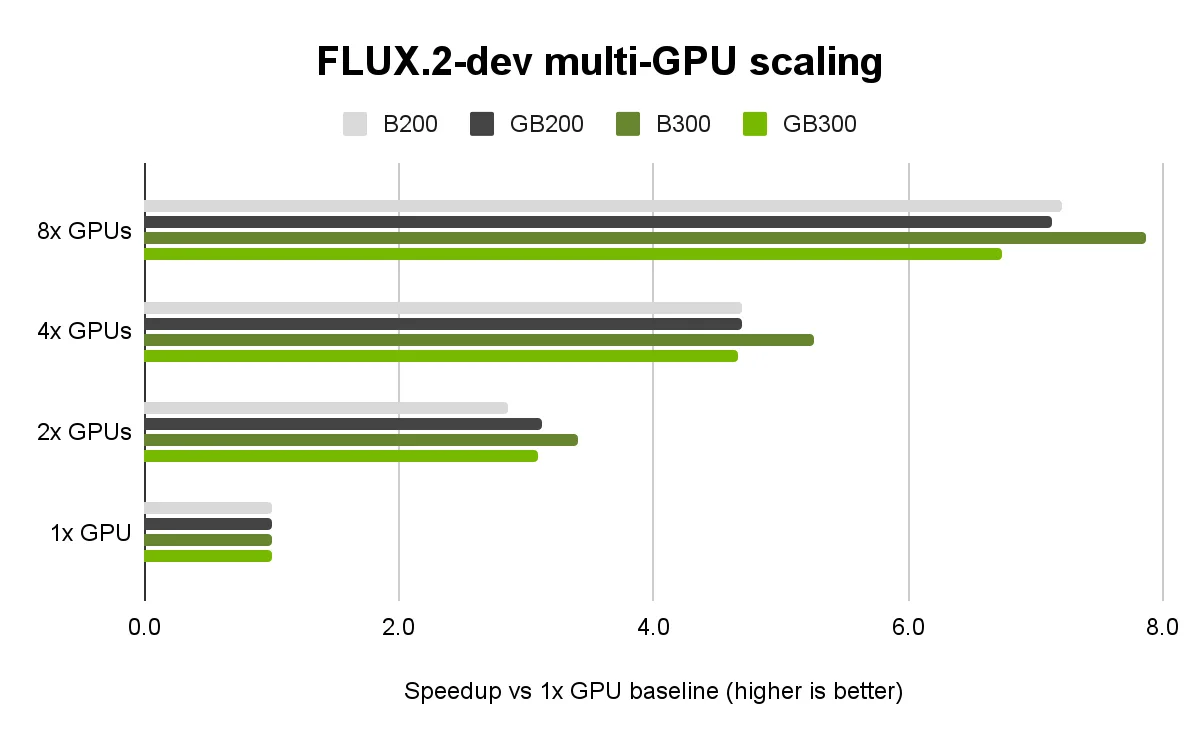
在多 GPU 环境下,TensorRT-LLM visual_gen 的序列并行能够实现接近线性的扩展效果,与增加更多 GPU 时的性能提升趋势一致。在 NVIDIA Blackwell B200 和 GB200,以及 NVIDIA Blackwell Ultra B300 和 GB300 GPU 上,同样可观察到这一表现。针对 NVIDIA Blackwell Ultra GPU 的其他优化工作仍在持续进行中。
开始在 NVIDIA Blackwell GPU 上使用 FLUX.2
FLUX.2 是图像生成领域的一项重要突破,成功实现了高质量输出与用户友好型部署选项的结合。NVIDIA 团队携手 BFL,在功能强大的 NVIDIA 数据中心 GPU 上显著加速了 FLUX.2 [dev]的运行性能。
将新技术应用于 FLUX.2[dev]模型(包括 NVFP4 量化和 TeaCaching),可带来推理速度的显著代际提升。这些优化的综合效果大幅降低了延迟,有助于在 NVIDIA 数据中心 GPU 上实现更高效的部署。
要开始使用这些先进的优化技术构建自己的推理工作流,可查看 NVIDIA/TensorRT-LLM/visual_gen GitHub 仓库中的端到端 FLUX.2 示例及配套代码。




