
随着 AI 工作负载的扩展,实现高吞吐量、高效资源利用和可预测的延迟变得愈发关键。 NVIDIA Run:ai 通过智能调度和动态 GPU 分割技术应对了这些挑战。GPU 分割功能由 NVIDIA Run:ai 在各类环境(云、NCP 和本地)中全面支持。
本文介绍了 NVIDIA 与 AI 云服务商 Nebius 联合开展的基准测试工作,旨在评估 NVIDIA Run:ai 的分数 GPU 分配技术如何提升大语言模型(LLM)推理性能。 Nebius’ AI Cloud 提供了坚实的基础设施支持,包括专用 NVIDIA GPU、NVIDIA Quantum InfiniBand 网络,以及大规模的高性能与弹性能力,从而在生产环境中实现上述性能优势。
所有基准测试均通过 NVIDIA NIM 微服务 执行。该方法可实现标准化的生产级模型部署,确保在不同环境中性能、安全性和生命周期管理的一致性。
结果表明,分数 GPU 能够在不影響延遲 SLA 的前提下,顯著提升有效容量:
- 仅使用 0.5 个 GPU 分数即可实现 77% 的 GPU 全吞吐量和 86% 的 GPU 全并发用户容量,首个 token(TTFT)的生成时间低于一秒
- 在采用 0.25 GPU 分数的较小模型上,并发推理用户数量最多可提升 2 倍
- 在共享 GPU 上运行混合工作负载(如聊天、推理、嵌入)时,系统支持的总用户数最高可增加 3 倍
- 在 0.5、0.25 和 0.125 GPU 分数之间,吞吐量实现近似线性扩展,TTFT 受影响程度适中
- 具备生产级自动扩展能力,横向扩展过程中无延迟激增或错误峰值
此基准测试表明,部分 GPU 调度已不再仅是一种优化技术,而是大规模多模型 LLM 推理在生产环境中高效运行的基础能力。
LLM 推理企业面临的挑战
企业 IT 部门通常依靠有限且固定的 GPU 资源来运作。在部署大语言模型(LLM)进行推理时,即使在流量较低的情况下,也需将专用 GPU(或多个 GPU)分配给单个 LLM 实例。这是因为模型必须在处理推理请求前加载全部权重,以确保生成 tokens(响应)的延迟足够低。
因此,多数 LLM 会消耗分配的所有 GPU,导致使用相同的可用 GPU 池来运行多个模型变得困难。在这种情况下,企业 IT 需手动维护 GPU 对 LLM 的分配,随着用户请求推理的数量持续增加,难以确定何时以及如何扩展 LLM,以维持聊天请求与生成 tokens 之间的延迟,且无法在非高峰时段重新利用空闲的 GPU。
理想情况下,企业需要一个弹性环境,其中 GPU 可用于运行多个 LLM,而不仅限于一个,同时不会显著影响可为这些用户执行推理或延迟的用户数量。他们能根据工作负载动态扩展 GPU,并在非高峰时段缩减 GPU,以便其他工作负载可共享相同的 GPU 资源。
借助 NVIDIA Run:ai 与 Nebius AI Cloud 拓展推理工作负载
NVIDIA Run:ai 平台凭借其高吞吐量 AI 工作负载调度程序,有效解决了这些痛点。该调度程序专为大规模 GPU 集群和动态分配分数 GPU 资源而设计,同时保持卓越性能。NVIDIA Run:ai 编排与 Nebius AI Cloud 基础设施相结合,构建出一个灵活且面向生产的框架,显著提升 GPU 投资回报率(ROI)。
在由 NVIDIA 和 Nebius AI Cloud 进行的基准测试中,NVIDIA Run:ai 在高峰时段将现有硬件的用户容量提升了 2 倍,表明企业能够显著扩展推理工作负载,而无需相应增加 GPU 投资。
动态 GPU 分数
NVIDIA Run:ai 可将 GPU 分解为更小的单元(例如分配 0.5 GPU),并同时为多个工作负载提供服务。用户只需直接指定其内存需求,调度程序即可在无需任何预配置的情况下按需分配资源。这一能力对推理工作负载尤为重要,因为较小的并发请求能够共享 GPU 资源,而不会显著影响性能。
内存隔离在运行时执行,计算周期则在活动进程间公平分配。用户还可定义具有可突发上限(限制)的保障性最小值(请求),使工作负载在资源可用时能占用额外的 GPU 容量,并在需求变化时自动释放。
智能工作负载调度
NVIDIA Run:ai 调度程序作为运营的“大脑”,可分析工作负载优先级、资源需求与系统容量,从而优化资源分配。在高峰时段,优先处理延迟敏感型任务(例如实时推理),而非面向批量的训练作业,以确保满足服务水平协议(SLA)。
调度程序会根据运行推理的连续用户和 token 延迟(具体依据管理员设定的 SLA 标准)自动扩展大语言模型。这些策略共同提升了资源利用率,降低了运维复杂性,并减少了总体拥有成本(TCO)。
NVIDIA 与 Nebius 团队开展了基准测试,旨在评估 NVIDIA Run:ai 在大规模运行多种大语言模型推理任务时的表现。我们针对可同时处理的聊天请求数量进行了规模测试,并记录了首 token 延迟(TTFT)、输出 吞吐量(生成 tokens/秒)以及 GPU 利用率等关键指标。NVIDIA 的测试基于遵循 PCIe 优化的 NVIDIA 企业参考架构,并采用搭载 NVIDIA H100 NVL GPU 的集群进行。而在 Nebius AI Cloud 上,测试则运行于基于 HGX 架构的 NVIDIA HGX B200 GPU 企业级参考架构集群之上。
基准测试设置
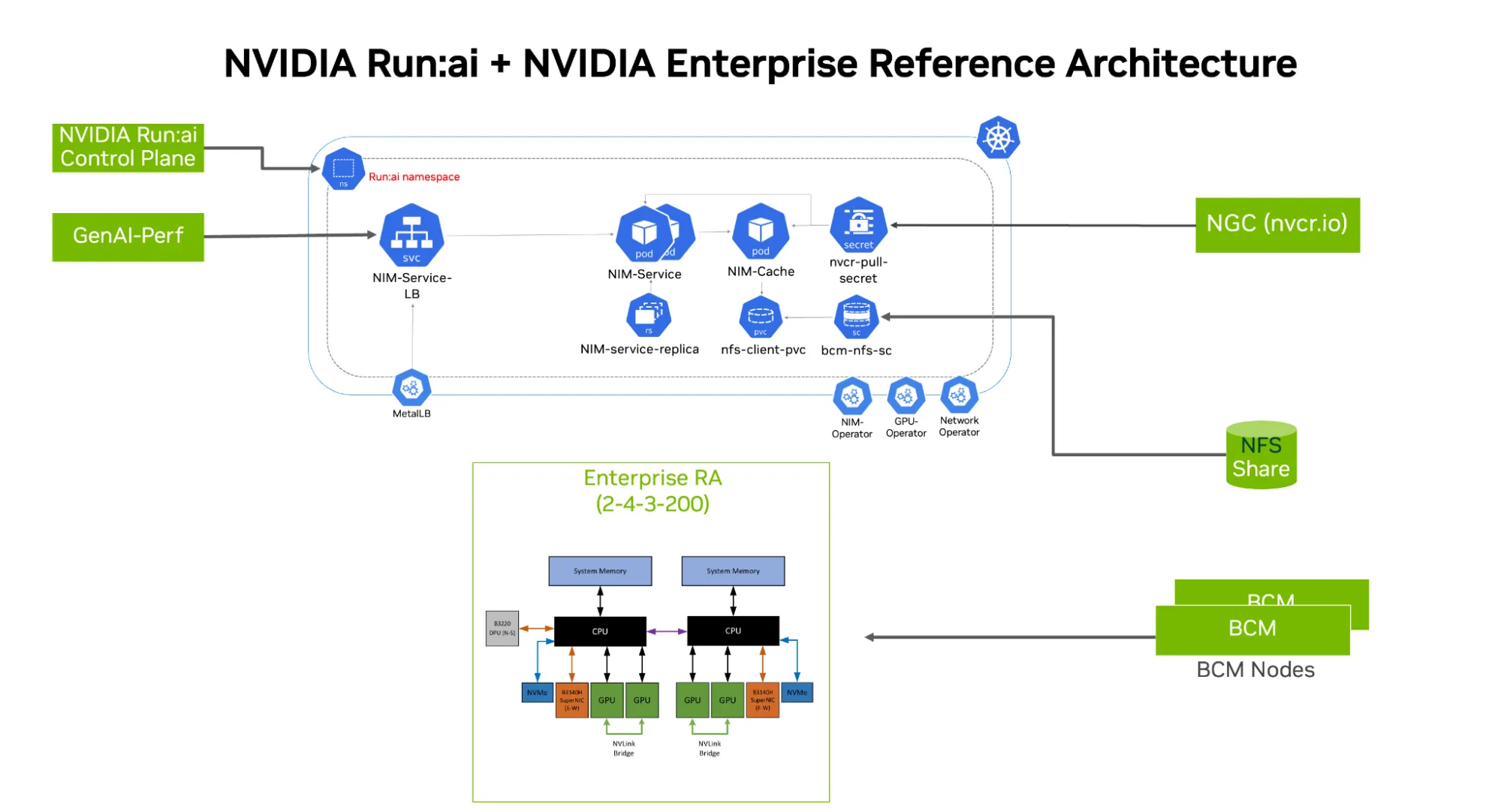
软件堆栈基于 NVIDIA 企业参考架构(图 1)。其中包括 NVIDIA AI Enterprise 堆栈,用于GPU生命周期管理的 NVIDIA GPU Operator,支持南北向与东西向网络通信的 NVIDIA Network Operator,用于下载各类模型权重的 NVIDIA NIM Operator,以及用于部署不同模型的 NVIDIA NIM 微服务。这是在由 Kubernetes 管理的节点集群中部署的。如需了解更多信息,请参阅 搭载 NVIDIA Run:ai 的NVIDIA NIM LLM 和 Vanilla Kubernetes for Enterprise RA。
基础设施
相同的基准测试在两种硬件配置上运行:其一为符合 NVIDIA Enterprise RA 规范的本地集群,配备 64 个 NVIDIA H100 NVL GPU;其二为 Nebius AI Cloud 集群,配备 32 个 NVIDIA HGX B200 GPU。这种双重环境的设计,验证了结果在自建基础设施与公有云部署中的一致性与适用性。
模型选择
所选的四个模型涵盖了不同的规模、内存占用和推理应用场景(表 1)。这一范围有助于在具有不同显存需求的工作负载之间评估分数分配。
| 模型 | 参数数量 | 内存要求 | 应用例 |
| Llama 3.1 8B Instruct | 8B | ~16 GB | 通用聊天 |
| Phi-4-Mini | 3.8B | ~8 GB | 轻量级助手 |
| Qwen3-14B | 14B | ~28 GB | 推理 |
| Qwen-Embeddings-0.6B | 0.6B | ~1.5 GB | 文档嵌入和重排序 |
值得注意的是,规模最大的型号(Qwen3-14B)仅占用单个 NVIDIA H100 NVL GPU 80 GB 容量的 35%,这表明传统的全 GPU 分配方式可能导致大量容量被闲置。
方法
生成式 AI 性能用于模拟并发用户向各个 NIM 端点发送聊天请求。该工具可记录每个会话的延迟与吞吐量,以便在负载增加时进行有效测量。
主要指标包括:
- TTFT: 从请求提交到首个响应 token 的延迟
- 输出吞吐量: 每个会话每秒生成的 token 数量
- GPU 利用率: 负载状态下 GPU 显存的占用百分比
- 并发扩展: 在维持 TTFT 与吞吐量于可接受范围的前提下(例如,用户数量增加导致延迟 SLA 下降的临界点),所能支持的同时在线用户数
测试条件
每个模型均在以下五种配置下进行了基准测试:
- 基准: 无 NVIDIA Run:ai(原生 Kubernetes 调度)的 LLM 推理
- 使用 NVIDIA Run:ai 的完整 GPU: 每个模型副本分配 1.0 个 GPU
- 0.5 GPU 分数: NVIDIA Run:ai,每个模型副本分配 0.5 个 GPU
- 0.25 GPU 分数: NVIDIA Run:ai,每个模型副本分配 0.25 个 GPU
- 混合模式: 多个 LLM 共享同一 GPU 资源
对于 Qwen-Embeddings 模型,还进行了数据提取吞吐量的测试,以评估针对嵌入任务的特定工作负载。
使用 NVIDIA Run:ai 对结果进行基准测试
本节基于生成式 AI 性能的测试结果来呈现相关观察。
一半分配时的部分 GPU 效率
根据从生成式 AI 性能中获取的结果,NVIDIA Run:ai 从两方面进行了评估:与原生 Kubernetes 相比的调度程序利用率,以及在不同分配规模下的部分 GPU 效率。以下小节将详细阐述各项评估的发现结果。
无调度程序用度
与原生 Kubernetes 调度相比,NVIDIA Run:ai 在所有测试配置中均未引入可衡量的性能损失。在使用 64 个 GPU 时,采用完整 GPU 分配的 NVIDIA Run:ai 可支持 10200 名并发用户,而原生调度程序支持 9934 名并发用户,这表明调度程序本身不会带来额外的性能开销。
部分 GPU 效率
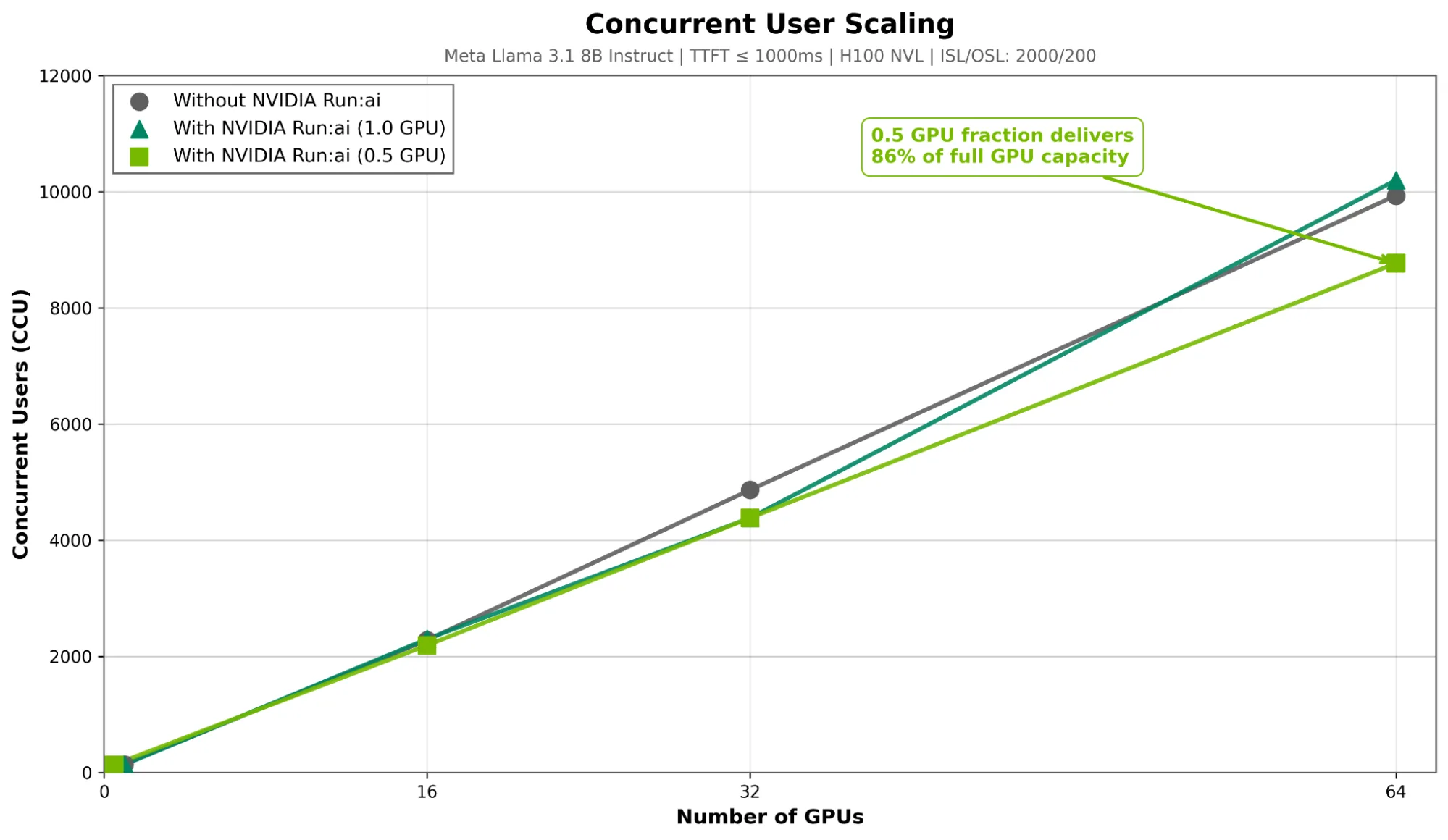
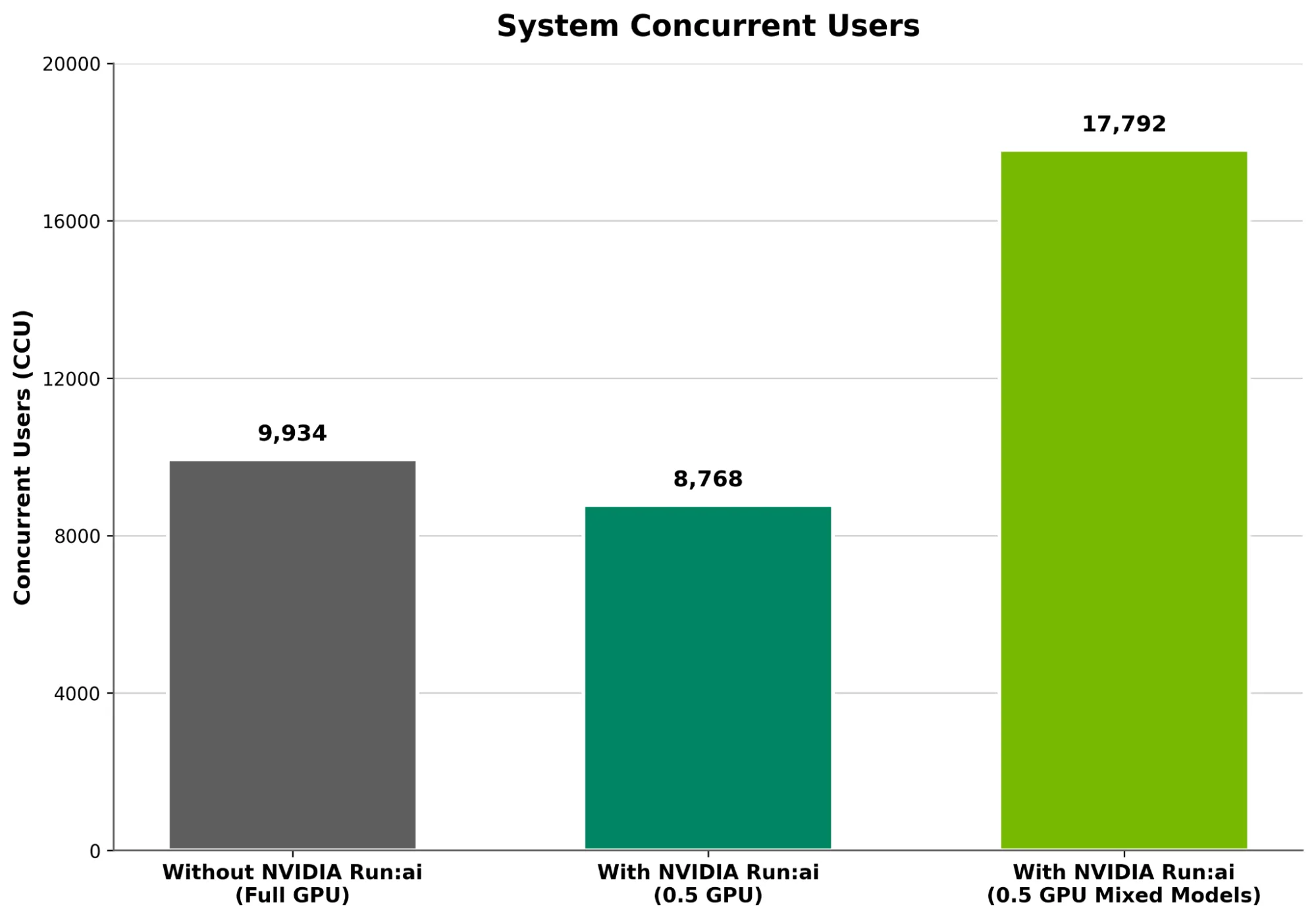
并发用户扩展:在 64 个 GPU 上,0.5 GPU 配置可支持 8768 个并发用户,每位用户的 TTFT 时间均不超过一秒(1000 毫秒),达到 GPU 总容量(10200 CCU)的 86%。这表明,采用分数分配仅带来有限的性能权衡,使企业能够在共享 GPU 上运行多个模型,或更精细地扩展部署,而不会造成明显的容量损失(图 2)。
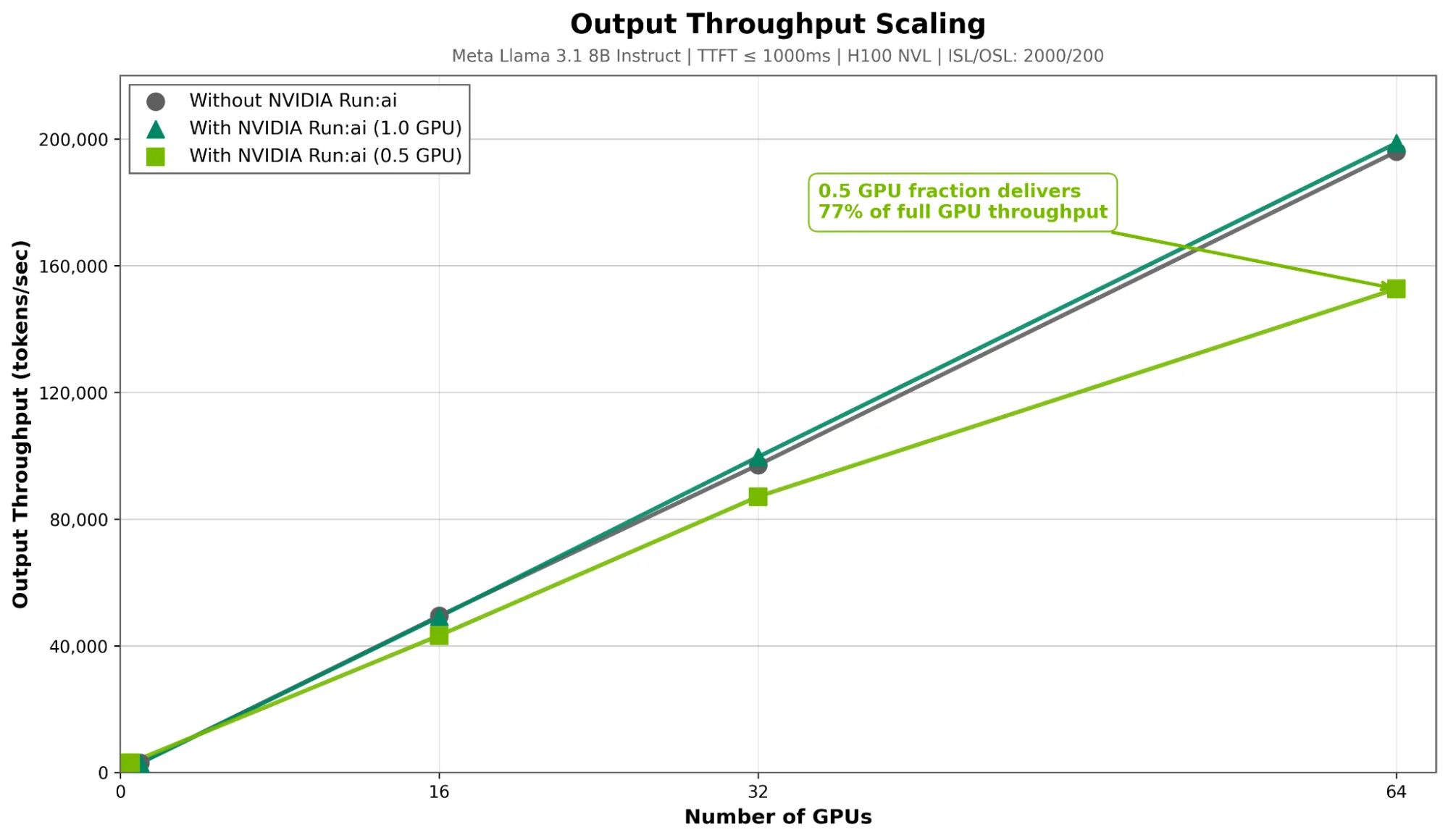
输出吞吐量:token 代吞吐量的效率相近。在使用 64 个 GPU 时,0.5 GPU 配置实现了 152694 tokens/秒 的吞吐量,达到 GPU 总吞吐量 198680 tokens/秒 的 77%,如图 3 所示。
三种配置(不包括 NVIDIA Run:ai、配备完整 GPU 的 NVIDIA Run:ai 和配备分数 GPU 的 NVIDIA Run:ai)均可从 1 个 GPU 线性扩展至 64 个 GPU。这种线性扩展关系表明,大规模部署中观察到的高效率并非小型部署中的伪影。
较小的模型利用四分之一 GPU 资源即可进一步扩展
较小的模型具有较轻的显存占用,这意味着它们能更高效地利用分数资源。Phi-4-Mini 使用 0.25 个 GPU 分数进行了测试,以评估其支持的并发性和吞吐量。
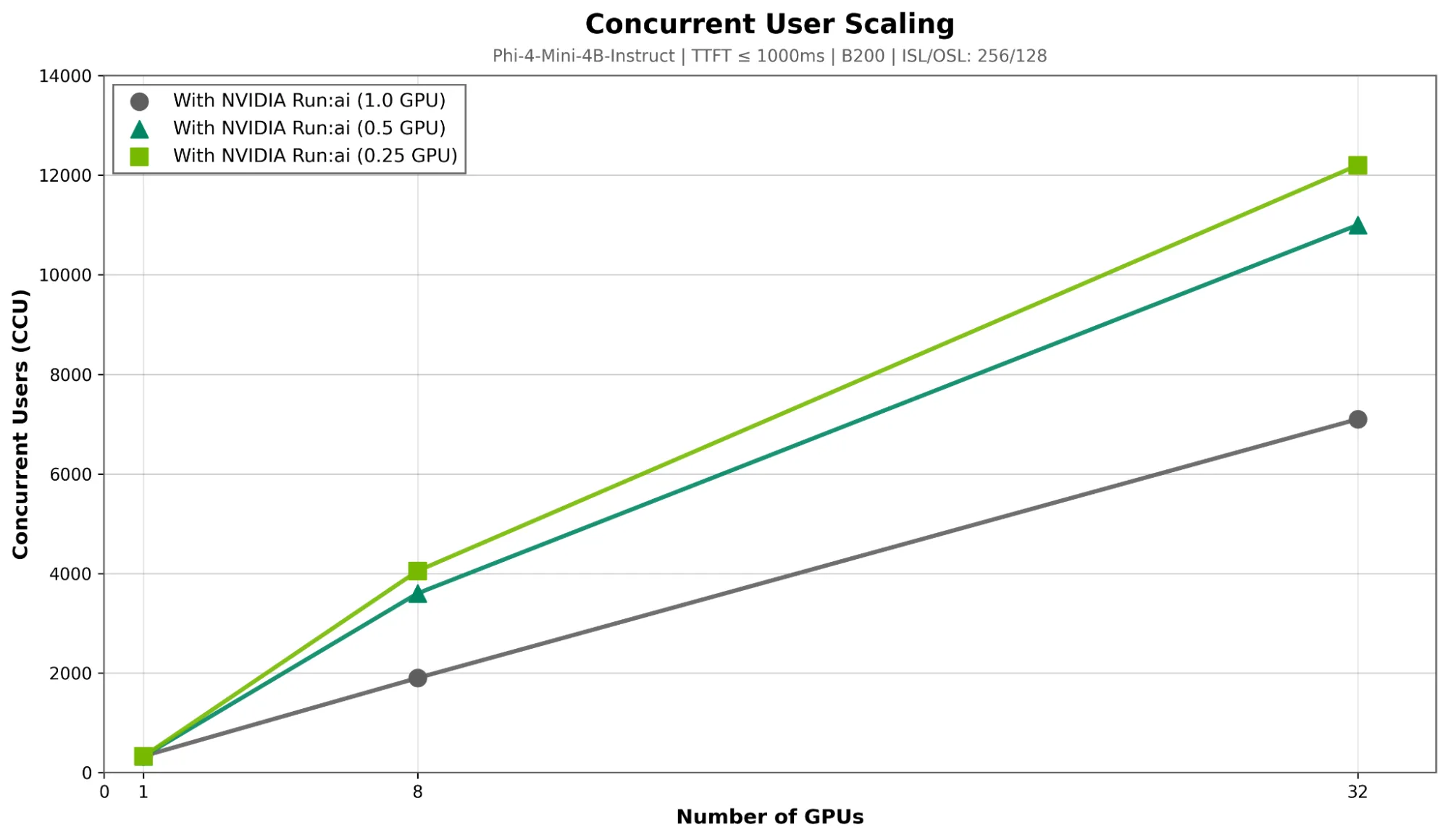
在 Phi-4 -Mini 等较小的模型上,采用 0.25 GPU 分数并由 NVIDIA Run:ai 支持时,可支持的并发用户数量相比全 GPU 分配提升 72%(图 4)。在使用 32 个 GPU 的情况下,该配置在 P95 TTFT 下达到约 45 万 tokens/秒(300 毫秒)(图 5)。Phi-Mini 参数量较小且张量效率较高,适合高密度分数部署。
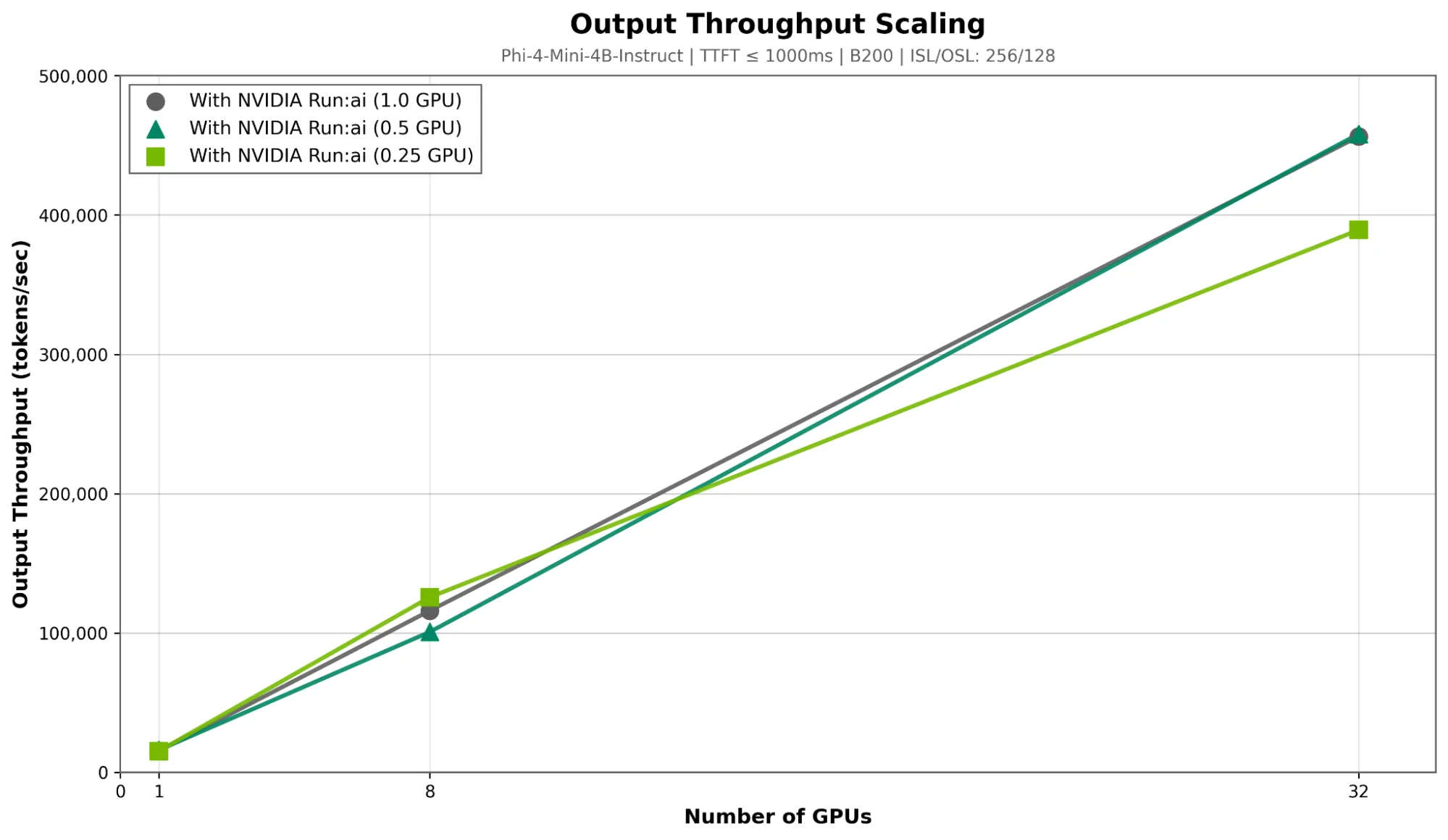
在 Nebius AI Cloud 的分数 GPU 上实现多模型托管
NVIDIA Run:ai 支持动态分配部分 GPU 资源。在之前的测试中,相同数量的用户在分数 GPU 上运行。其中一项测试利用 NVIDIA Run:ai 在算力分配为 0.5 的 NVIDIA H100 NVL GPU 上同时加载了两个模型(Llama 3.1 8B 和 DeepseekR1-蒸馏-8B),实现了在单个 NVIDIA H100 NVL GPU 上并行运行两个推理模型。
结果表明,使用 NVIDIA Run:ai 时,并发用户数量是每个 GPU 部署单个 NIM Pod 的两倍(图 6)。当规模超过集群中 GPU 数量的 50% 时,性能影响逐渐增大。在极端情况下,并发用户的 TTFT 下降了 3 倍,而吞吐量仅下降了 0.4 倍。
传统的 Kubernetes 调度程序不支持此类分数分配。NVIDIA Run:ai 支持通过动态帧缓存分配加载多个模型,无需手动规划容量。
NVIDIA NIM 通过将每个模型封装为具备一致启动和健康信号的生产就绪型优化推理微服务来补充这一点。随后,NVIDIA Run:ai 在运行时实现内存隔离与公平的计算资源分配。二者结合使用,可安全地托管异构工作负载,避免跨模型干扰。
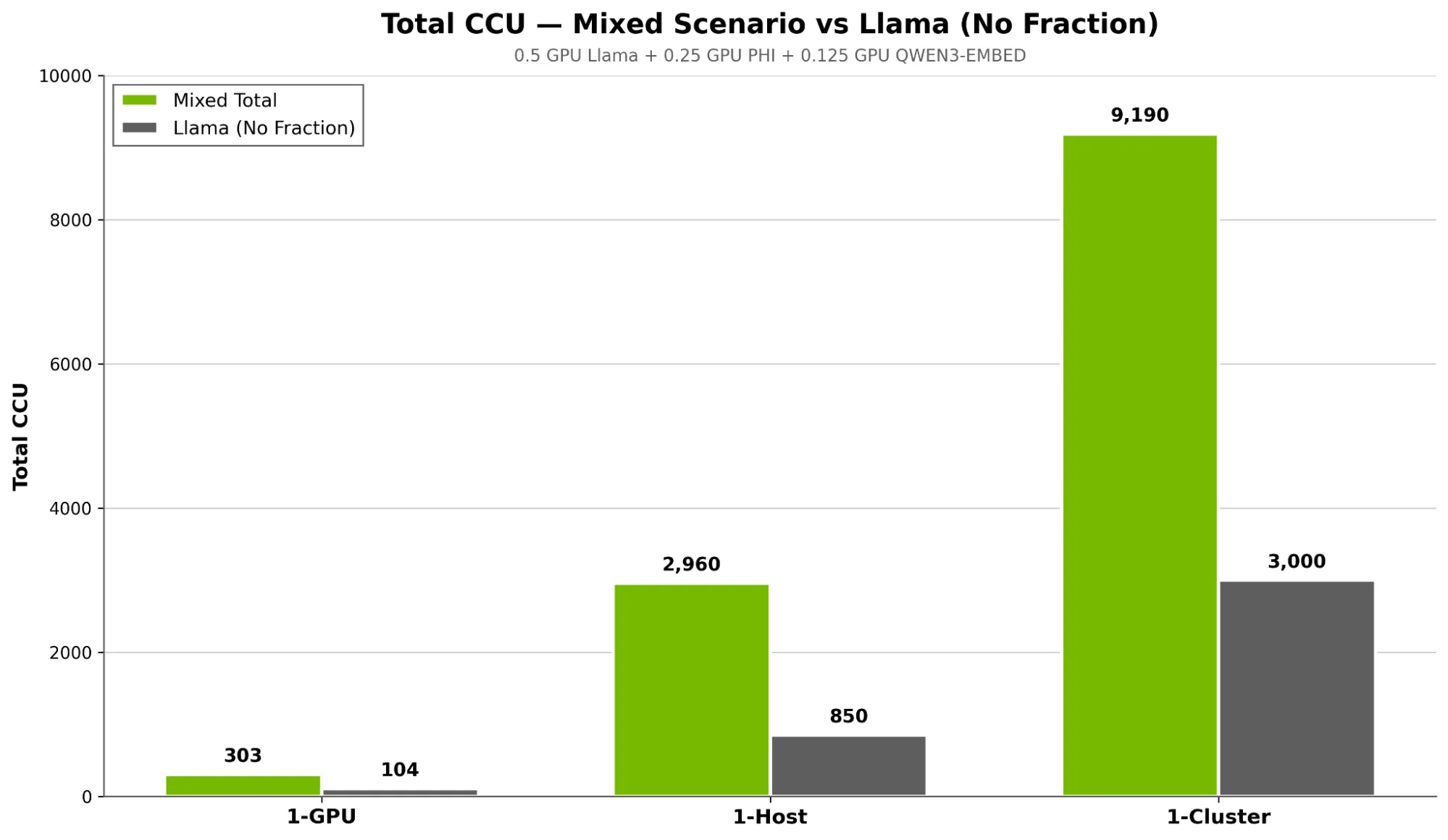
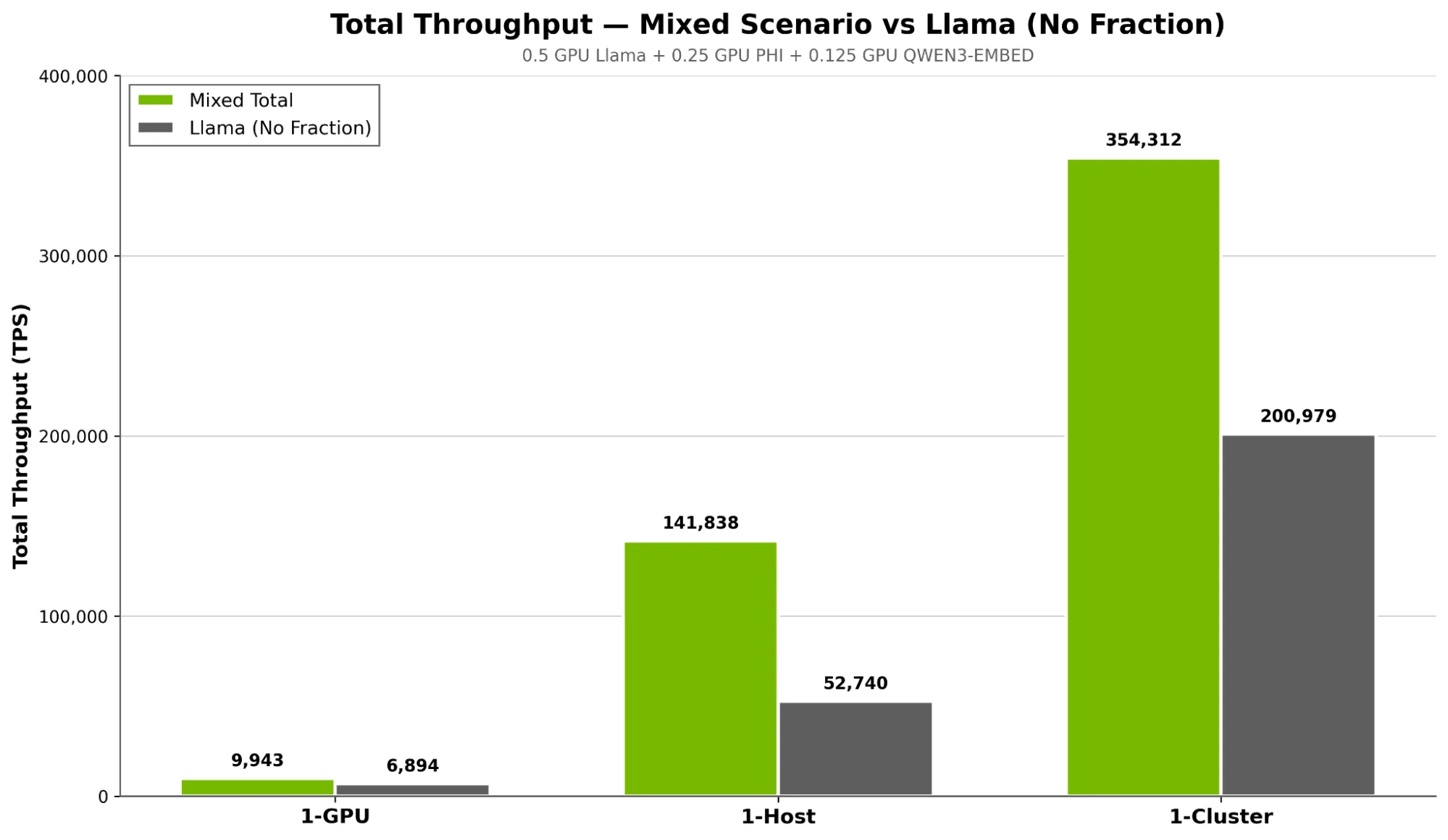
Nebius 进行了一次类似的测试,部署了 0.5 个 GPU 的 Llama 3.1 8B、0.25 个 GPU 的 Phi+ 4 Mini 和 0.125 个 GPU 的 Qwen+ 嵌入。该集群在无跨模型干扰的情况下实现了可预测的扩展,全规模下总吞吐量超过 35 万 TPS(图 8)。可支持推理的并发用户总数提升了近 3 倍(图 7)。这验证了 NVIDIA Run:ai 调度程序能够高效整合异构推理工作负载,同时避免延迟波动和利用率不稳定的问题。
借助 NVIDIA Run:ai 自动扩展 NIM LLM
NVIDIA Run:ai 可根据并发用户数、吞吐量或延迟值自动扩展推理 Pod。Nebius 将 Llama 3.1 8B 设置为在并发用户数超过 50 时触发扩展,从而由 NVIDIA Run:ai 向 NIM 推理服务分配额外的 GPU 资源。
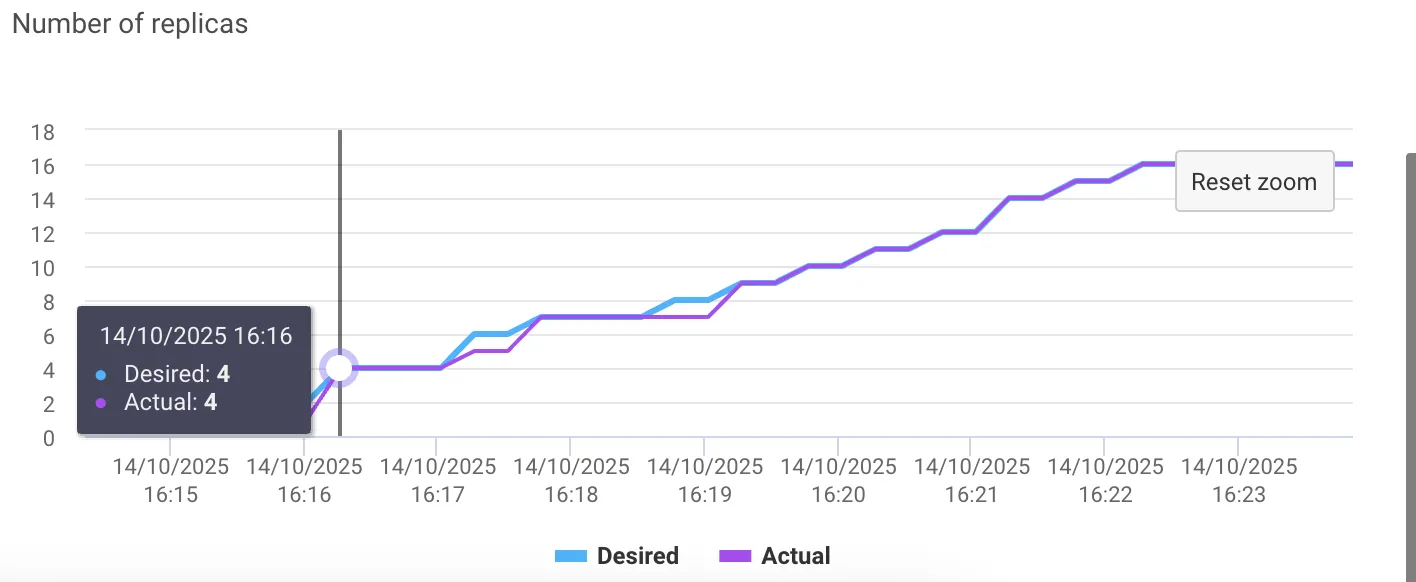
随着需求增加,副本数量从 1 个平稳扩展至 16 个。自动扩展示意图显示,TTFT 无明显峰值,在 Pod 预热期间 GPU 利用率保持稳定,HTTP 错误率可忽略不计,表明分数 GPU 推理能够在保障服务水平协议的前提下实现弹性扩展。
开始在 NVIDIA Run:ai 中使用 GPU 分数
NVIDIA Run:ai 通过动态分配、拆分和智能工作负载调度实现高效的 GPU 利用率。结合 Nebius AI Cloud 的专用 GPU、NVIDIA 网络和超大规模弹性,企业能够实现:
- 部分调度下 GPU 利用率提升,有效消除碎片化与空闲资源
- 在 0.5 和 0.25 GPU 切片(嵌入任务为 0.125)中实现接近线性的吞吐量扩展,对首次生成延迟(TTFT)影响较小
- 支持混合工作负载完全共存:在同一节点上并行执行嵌入、生成与摘要任务
- 适用于部分 LLM 推理的生产级自动扩展,横向扩展过程中无 SLA 风险
- 单个 GPU 可承载更多工作负载,提升并发能力,降低集群规模需求
有关此基准测试的执行摘要,请参阅在 Nebius 上使用 NVIDIA Run:ai 实现高效生产级推理的扩展方案。
开始使用新版 NVIDIA Run:ai v2.24。 如需了解更多信息,请查看 NVIDIA GTC 2026 会议“利用开放模型扩展推理:Nebius token 工厂如何实现控制与效率(由 Nebius 演示)【S82234】”。




