
这个大型语言模型 (LLM) 缩放规律的最新发展已经表明,当模型参数的数量进行缩放时,用于训练的令牌的数量也应该以相同的速率进行缩放。这个Chinchilla和LLaMA模型已经验证了这些经验推导的定律,并表明先前最先进的模型在预训练期间使用的令牌总数方面训练不足。
考虑到最近的发展, LLM 显然比以往任何时候都更需要更大的数据集。
然而,尽管有这种需求,大多数为创建用于训练 LLM 的大规模数据集而开发的软件和工具都没有公开发布或可扩展。这需要 LLM 开发人员构建自己的工具来策划大型语言数据集。
为了满足对大型数据集日益增长的需求,我们开发并发布了 NeMo 数据策展器:一种可扩展的数据策展工具,使您能够策展万亿个代币多语言数据集,用于 LLM 的预训练。
Data Curator 是一组 Python 模块,它使用 Message-Passing Interface (MPI),Dask 和 Redis Cluster 将以下任务扩展到数千个计算核心:
- 数据下载
- 文本提取
- 文本重新格式化和清理
- 质量过滤
- 精确或模糊重复数据消除
将这些模块应用于数据集有助于减轻梳理非结构化数据源的负担。通过文档级重复数据消除,您可以确保对模型进行针对唯一文档的培训,从而大大降低预培训成本。
在这篇文章中,我们概述了 Data Curator 中的每个模块,并证明它们能够提供超过 1000 个 CPU 内核的线性扩展。为了验证所策划的数据,我们还展示了使用Common Crawl 处理的文档进行预训练,相比于使用原始下载文档,能够显著改善下游任务的效果。
数据管理管道
此工具使您能够下载数据并进行大规模的提取、清理、消除重复数据和筛选文档。图 1 显示了典型的 LLM 数据策划流程,这是可以实现的。在以下各节中,我们将简要介绍每一个可用模块的实现。
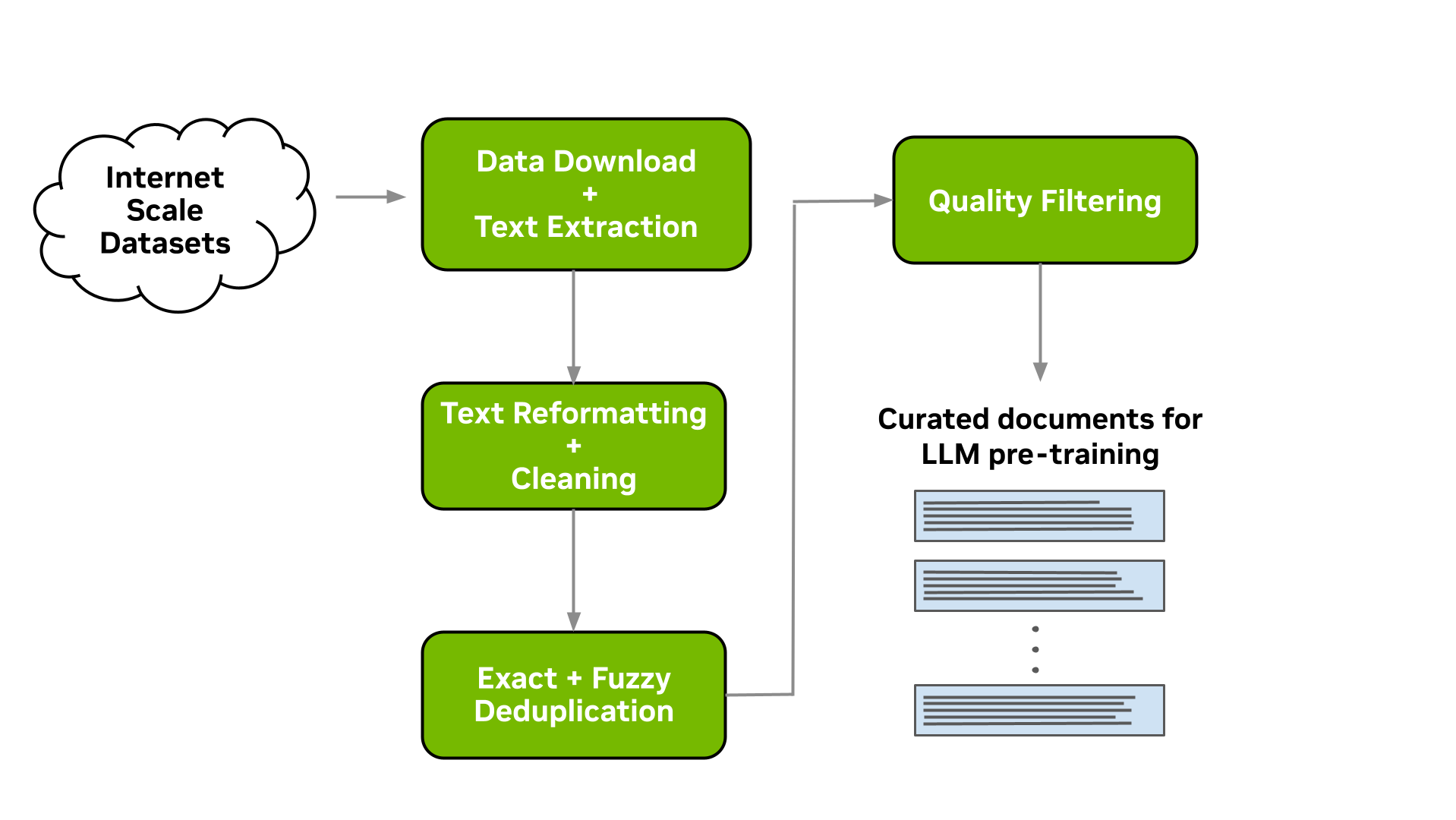
下载和文本提取
为许多 LLM 从业者准备自定义预训练数据集的起点是指向包含 LLM 预训练感兴趣内容的数据文件或网站的 URL 列表。
Data Curator 让您能够从数据存储库下载预先爬取的网页,例如Common Crawl,Wikidumps和ArXiv,并将相关文本提取到JSONL文件中。Data Curator 还提供了灵活性,允许您提供自己的下载和提取功能来处理来自各种来源的数据集。通过使用 MPI 和 Python 多处理器,您可以在运行时跨多个计算节点启动数千个异步下载和提取工作程序。
文本重新格式化和清理
在下载并从文档中提取文本时,一个常见的步骤是修复在提取过程中可能出现的所有与 Unicode 相关的错误,这些错误是由于文本数据未正确解码而产生的。Data Curator 使用 Fixes Text For You library (ftfy) 来修复所有与 Unicode 相关的错误。清理过程还有助于规范文本,从而在执行文档重复数据消除时提高召回率。
文档级重复数据消除
当从大规模网络爬网源,如公共爬网下载数据时,通常会遇到完全重复的文档和高度相似的文档(即近乎重复的文档)。使用这些重复文档对 LLM 进行预训练可能会导致泛化能力差和文本生成过程中缺乏多样性。
我们提供精确和模糊的重复数据消除实用程序,可从文本数据中删除重复数据。精确重复数据消除实用程序计算每个文档的 128 位散列,按散列将文档分组到桶中,每个桶选择一个文档,并删除桶中剩余的精确重复项。
模糊重复数据消除实用程序采用了基于 MinHashLSH 的方法,在此方法中,为每个文档计算 MinHashes,然后利用 min-wise 哈希的位置敏感属性对文档进行分组。将文档分组到存储桶后,将计算每个存储桶中文档之间的相似性,以检查在MinHashLSH中的应用。
对于这两种重复数据消除实用程序, Data Curator 使用分布在计算节点上的 Redis Cluster 来实现分布式字典,用于将文档聚类到存储桶中。 Redis Cluster 实现的可扩展设计和八卦协议能够有效地将重复数据消除工作负载扩展到许多计算节点。
文档级质量筛选
除了包含相当一部分重复文档外,来自 web 爬网源(如 Common crawl )的数据往往还包括许多带有非正式散文的文档。例如,这包括许多 URL 、符号、样板内容、省略号或重复子字符串。从语言建模的角度来看,它们可以被认为是低质量的内容。
虽然已经表明,不同的 LLM 预训练数据集会导致 改善下游性能,但大量的低质量文档可能会 阻碍性能。Data Curator 为您提供了一个高度可配置的文档过滤实用程序,使您能够将自定义启发式过滤器大规模应用于语料库。该工具还包括语言数据过滤器的实现(基于分类器和启发式),以 提高整体数据质量和下游任务性能,特别是在应用于 web 爬网数据时。
扩展到多个计算核心
为了展示 Data Curator 中可用的不同模块的扩展能力,我们使用它们来准备一个由大约 40B 令牌组成的小型数据集。这涉及到在 5 TB 的 Common Crawl WARC 文件上运行前面描述的数据管理管道。
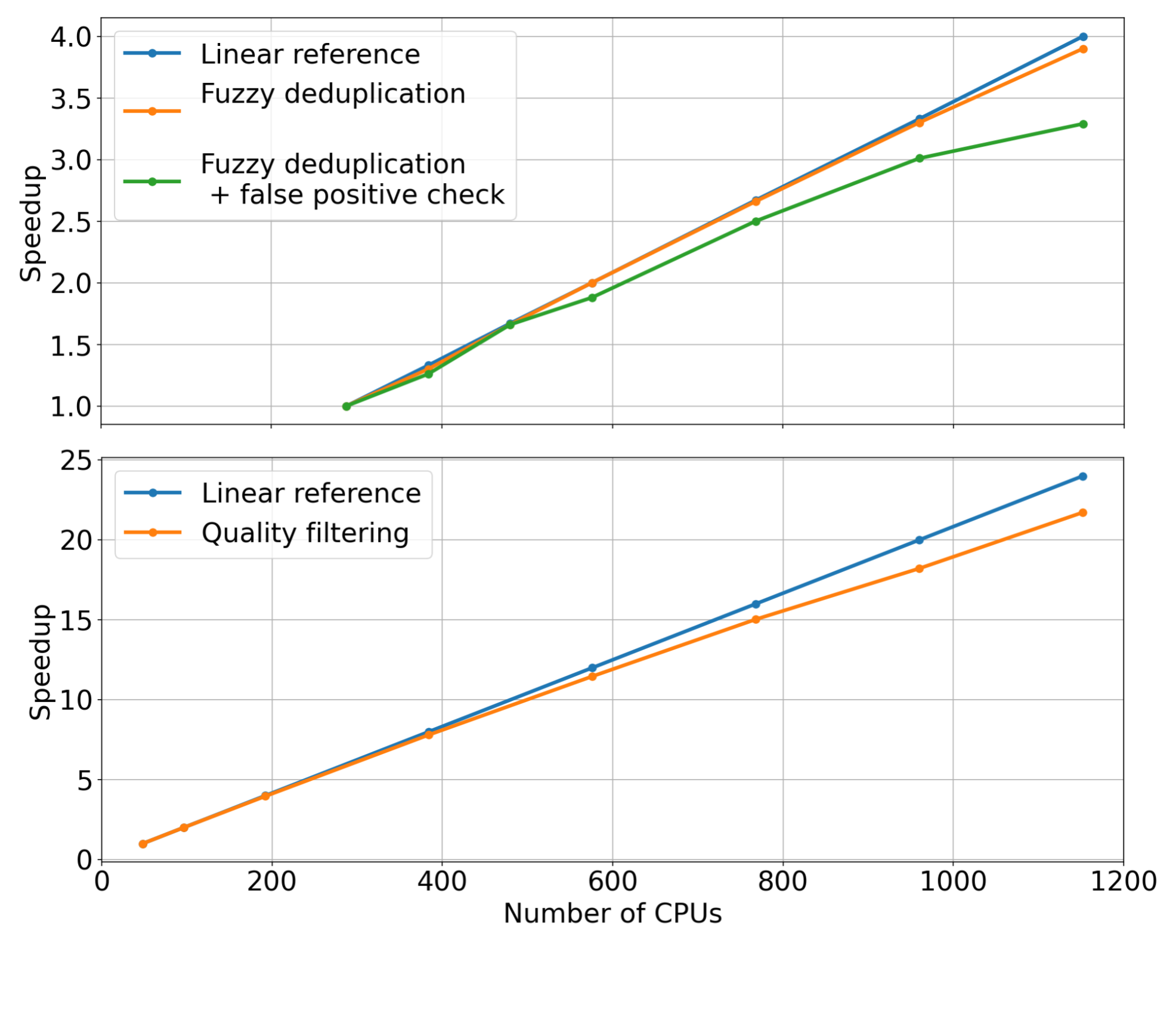
对于每个管道阶段,我们固定了输入数据集的大小,同时线性增加了用于扩展数据管理模块的 CPU 核心的数量(即强扩展)。然后,我们测量了每个模块的加速。测量的质量过滤和模糊重复数据消除模块的加速如图 2 所示。
通过检查测量的趋势,很明显,当增加用于分配数据管理工作负载的 CPU 核心数量时,这些模块可以达到显著的加速。与线性参考(橙色曲线)相比,我们观察到,当使用 1000 CPU 或更多时,两个模块都能够实现相当大的加速。
固化的预训练数据提高了模型的下游性能
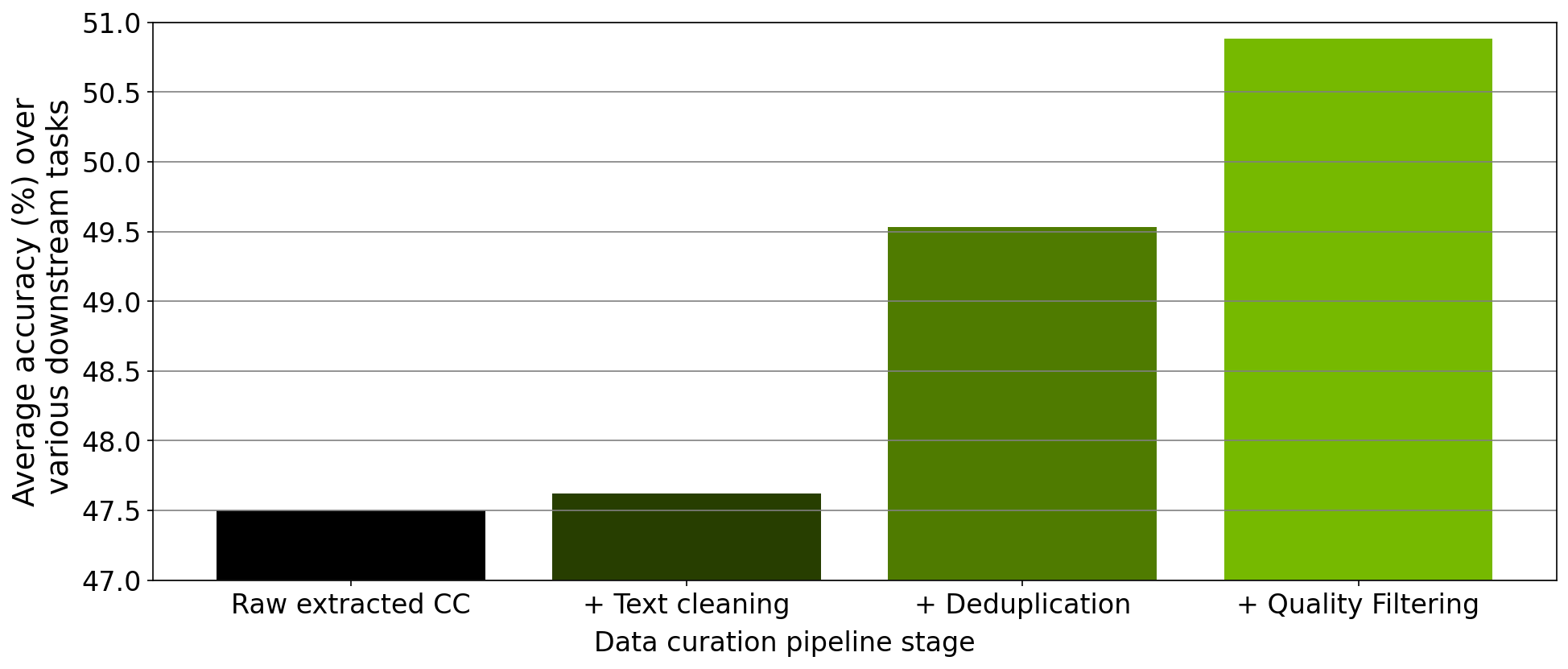
除了验证每个模块的缩放比例外,我们还对工具内实施的数据管理管道的每个步骤中收集的数据进行了消融研究。从下载的 Common Crawl 快照开始,我们在提取、清理、重复数据消除和筛选后,在此快照中策划的 78M 个令牌上训练了一个 357M 参数的 GPT 模型。
在每次预训练实验之后,我们在零样本设置中评估 RACE-High 、 PiQA 、 Winogrande 和 Hellaswag 任务中的模型。图 3 显示了我们的消融实验结果在所有四项任务中的平均值。随着数据在管道的不同阶段进行,所有四个任务的平均值都显著增加,这表明数据质量有所提高。
使用 NeMo 数据策展人策展 2T 代币数据集
最近,NVIDIA NeMo service 开始为早期访问用户提供定制 NVIDIA 训练的 43B 参数多语言大型基础模型的机会。为了预训练这个基础模型,我们准备了一个由 2T 令牌组成的数据集,其中包括来自各种不同领域的 53 种自然语言以及 37 种不同的编程语言。
策划这个大型数据集需要将我们在 data Curator 中实现的数据策划管道应用于 6K 以上的 CPU 集群上总共 8 . 7 TB 的文本数据。在这些代币的 1 . 1T 上预训练 43B 基础模型,产生了最先进的 LLM , NVIDIA 客户目前正在使用该 LLM 来满足其 LLM 需求。
结论
为了满足 LLM 预训练数据集管理的日益增长需求,我们推出了 Data Curator,这是 NeMo framework 的一部分。我们已经证明,这个工具能够收集高质量的数据,从而提高 LLM 的下游性能。此外,我们已经展示了 Data Curator 中的每个数据管理模块都可以扩展到使用数千个 CPU 核心。我们预计,这个工具将大大有利于 LLM 开发人员尝试构建预训练数据集。