NVIDIA TensorRT
NVIDIA® TensorRT™ 是一个工具生态系统,可供开发者实现高性能深度学习推理。TensorRT 包括推理编译器、运行时和模型优化,可为生产应用提供低延迟和高吞吐量。TensorRT 生态系统包括 TensorRT 编译器、TensorRT-LLM、TensorRT Model Optimizer 和 TensorRT Cloud。
TensorRT 的工作原理
与仅使用 CPU 的平台相比,推理速度提高了 36 倍。
TensorRT 基于 NVIDIA® CUDA® 并行编程模型构建,包含用于优化在所有主要框架上训练的神经网络模型的库,对这些模型进行高精度校正以获得较低的精度,并将其部署到超大规模数据中心、工作站、笔记本电脑和边缘设备。TensorRT 使用量化、层和张量融合以及内核调优等技术来优化推理。
TensorRT 为使用量化感知训练技术训练的模型提供训练后量化和支持,以优化深度学习推理的 FP8、FP4 和整数格式。推理精度的降低可显著降低延迟,满足许多实时服务以及自主和嵌入式应用程序的需求。
主要特性
大语言模型推理
NVIDIA TensorRT-LLM 是一个开源库,可通过简化的 Python API 在 NVIDIA AI 平台上加速和优化大语言模型 (LLM) 的推理性能。
开发者可在数据中心或工作站中的 NVIDIA GPU 上加速 LLM 性能,包括原生 Windows 上的 NVIDIA RTX™ 系统 – 具有相同的无缝工作流。
在云端编译
NVIDIA TensorRT Cloud 是一项以开发者为中心的服务,可针对给定的限制条件和 KPI 生成超优化引擎。鉴于 LLM 和推理吞吐量/ 延迟要求,开发者可以使用命令行界面调用 TensorRT Cloud 服务,为目标 GPU 超优化 TensorRT-LLM 引擎。云服务将自动确定满足要求的最佳引擎配置。开发者还可以在各种 NVIDIA RTX、GeForce、Quadro® 或 Tesla® 级 GPU 上使用 ONNX 模型构建经优化的 TensorRT 引擎。TensorRT Cloud 面向特定合作伙伴提供有限访问权限。申请需要获得批准才能访问。
优化神经网络
NVIDIA TensorRT 模型优化器 是先进模型优化技术 (包括量化、稀疏和蒸馏) 的统一库。它为 TensorRT-LLM 和 TensorRT 等下游部署框架压缩深度学习模型,以高效优化 NVIDIA GPU 上的推理。
主要框架集成
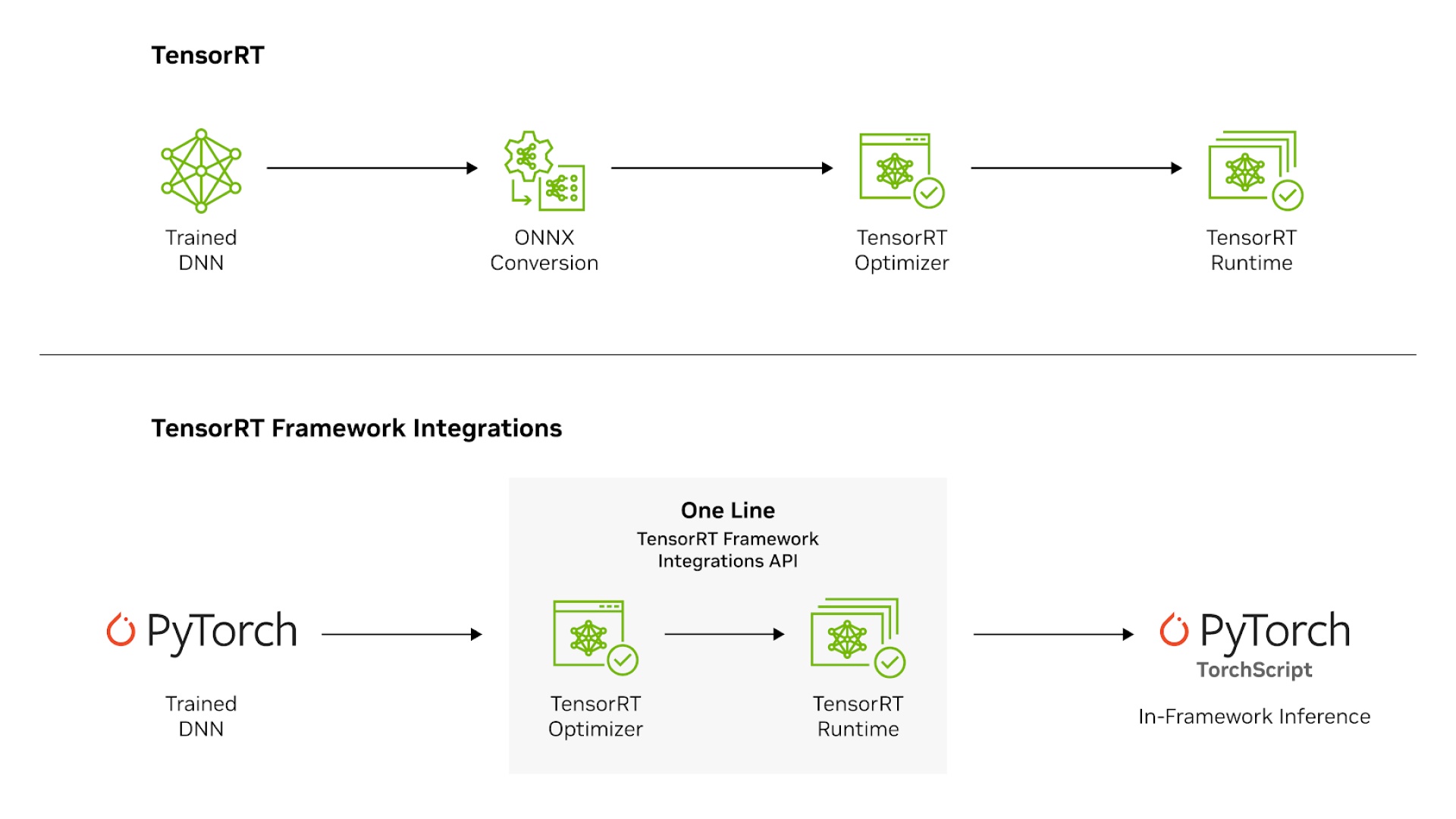
TensorRT 直接集成到 PyTorch以及 Hugging Face 只需一行代码即可将推理速度提高 6 倍。TensorRT 提供了一个 ONNX 解析器来导入ONNX 将热门框架中的模型导入 TensorRT。MATLAB 通过 GPU Coder 与 TensorRT 集成,自动为 NVIDIA Jetson™、NVIDIA DRIVE® 和数据中心平台生成高性能推理引擎。
使用 Triton 进行部署、运行和扩展
使用 TensorRT 优化的模型进行部署、运行和扩展NVIDIA Triton* 将 TensorRT 作为后端的推理服务软件。使用 Triton 的优势包括动态批处理、并发模型执行、模型集成以及流式传输音频和视频输入的高吞吐量。
加速每个推理平台
TensorRT 可以针对边缘、笔记本电脑和台式机以及数据中心的应用优化模型。它为主要的 NVIDIA 解决方案 (例如 NVIDIA TAO、NVIDIA DRIVE、NVIDIA Clara™ 和 NVIDIA JetPack™) 提供支持,并与特定应用的 SDK (例如 NVIDIA NIM™、NVIDIA DeepStream、NVIDIA® Riva、NVIDIA Merlin™、NVIDIA Maxine™、NVIDIA Morpheus 和 NVIDIA Broadcast Engine) 集成。
TensorRT 为开发者提供了在生产环境中部署智能视频分析、语音 AI、推荐系统、视频会议、基于 AI 的网络安全和流式传输应用的统一路径。
开始使用 TensorRT
TensorRT 是一个用于高性能深度学习推理的 API 生态系统。
下载 TensorRT Model Optimizer
TensorRT Model Optimizer (模型优化器) 可在 NVIDIA PyPI 上免费使用,并在 GitHub 上提供示例和方法。
开始使用 TensorRT 框架
TensorRT 框架将 TensorRT 编译器功能添加到 PyTorch 等框架中。
下载 ONNX 和 Torch-TensorRT
TensorRT 推理库提供通用 AI 编译器和推理运行时,可为生产应用提供低延迟和高吞吐量。
ONYX:
Torch-TensorRT:
体验棘手:使用 TensorRT 进行 Pythonic 推理
通过 Tripy 体验高性能推理和出色的易用性。通过直观的 API、即时模式的轻松调试、清晰的错误消息和一流的文档来简化深度学习部署。
出色的推理性能
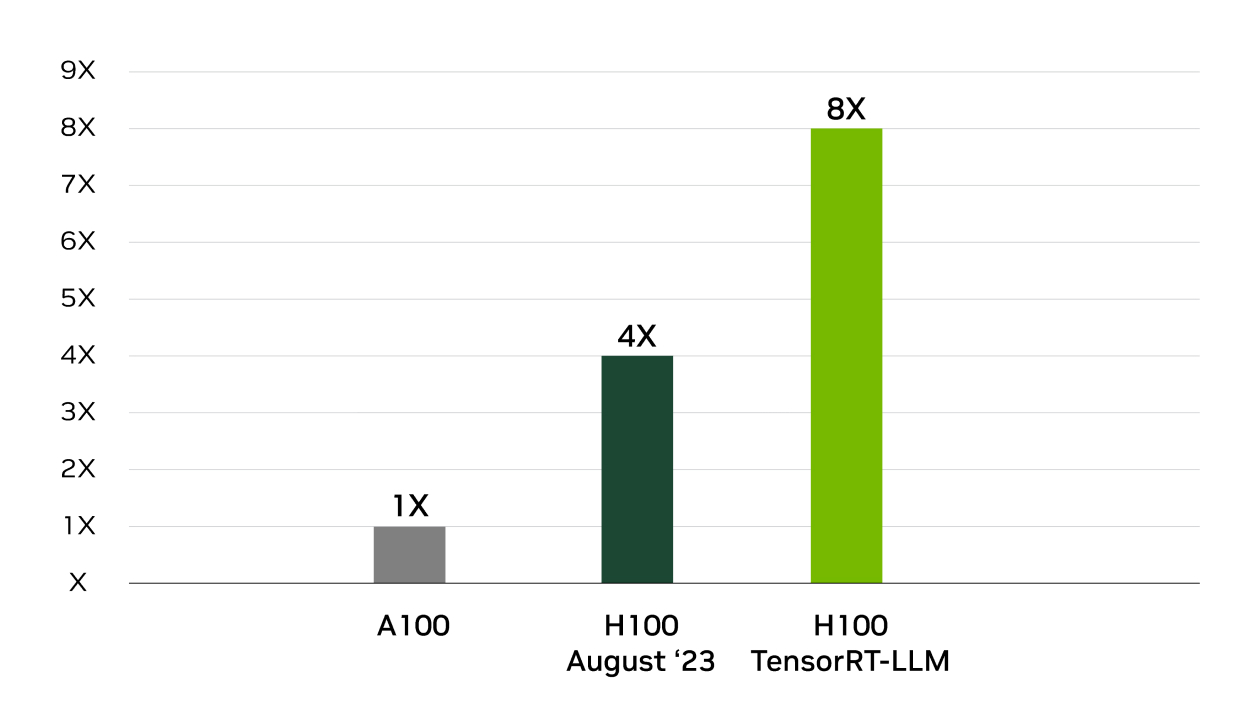
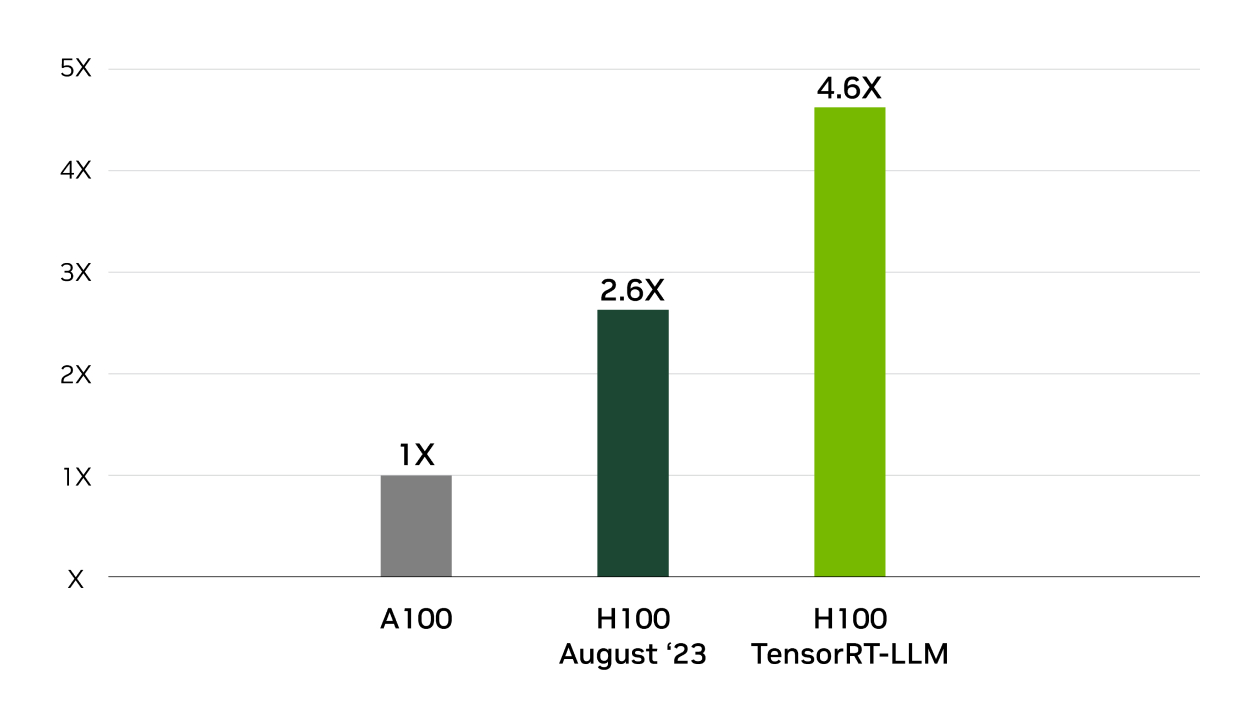
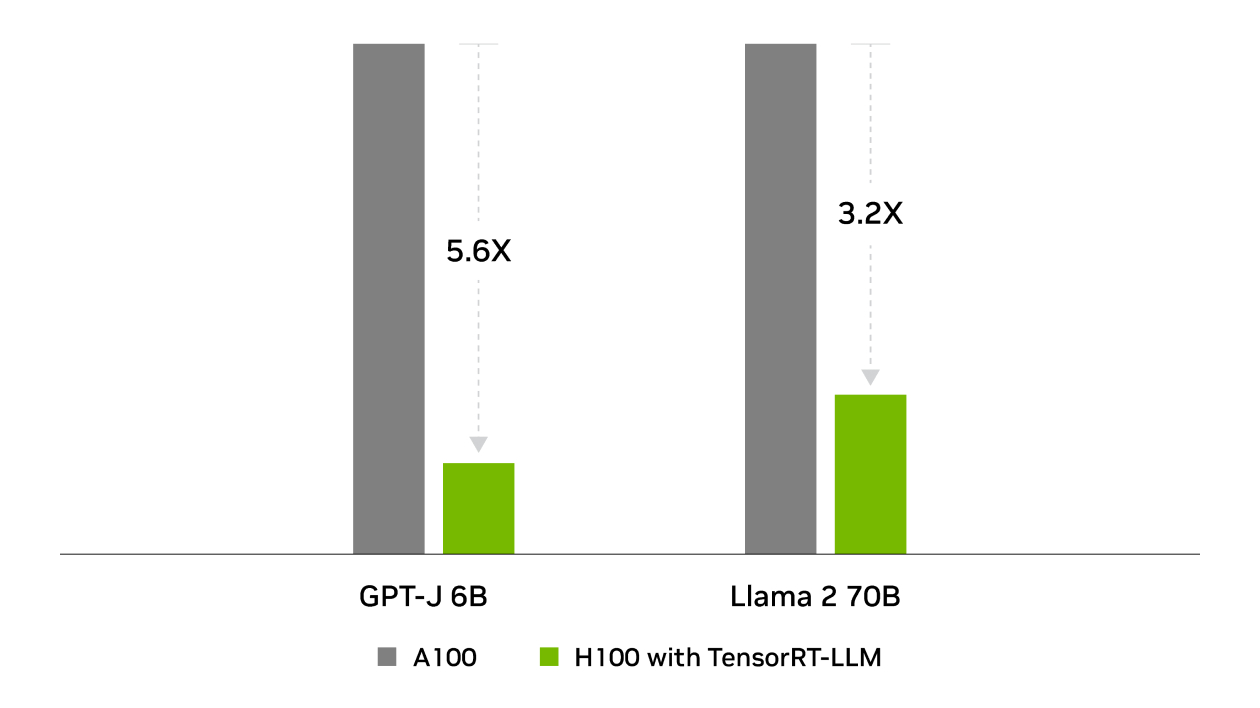
在行业标准的 MLPerf 推理基准测试中,NVIDIA 在所有推理性能测试中均战胜了 TensorRT。TensorRT-LLM 可加速用于生成式 AI 的最新大语言模型,提供高达 8 倍的性能提升、5.3 倍的 TCO 提升以及近 6 倍的能耗降低。
GPT-J 6B 推理性能提升 8 倍
Llama2 推理性能提升 4 倍
总体拥有成本
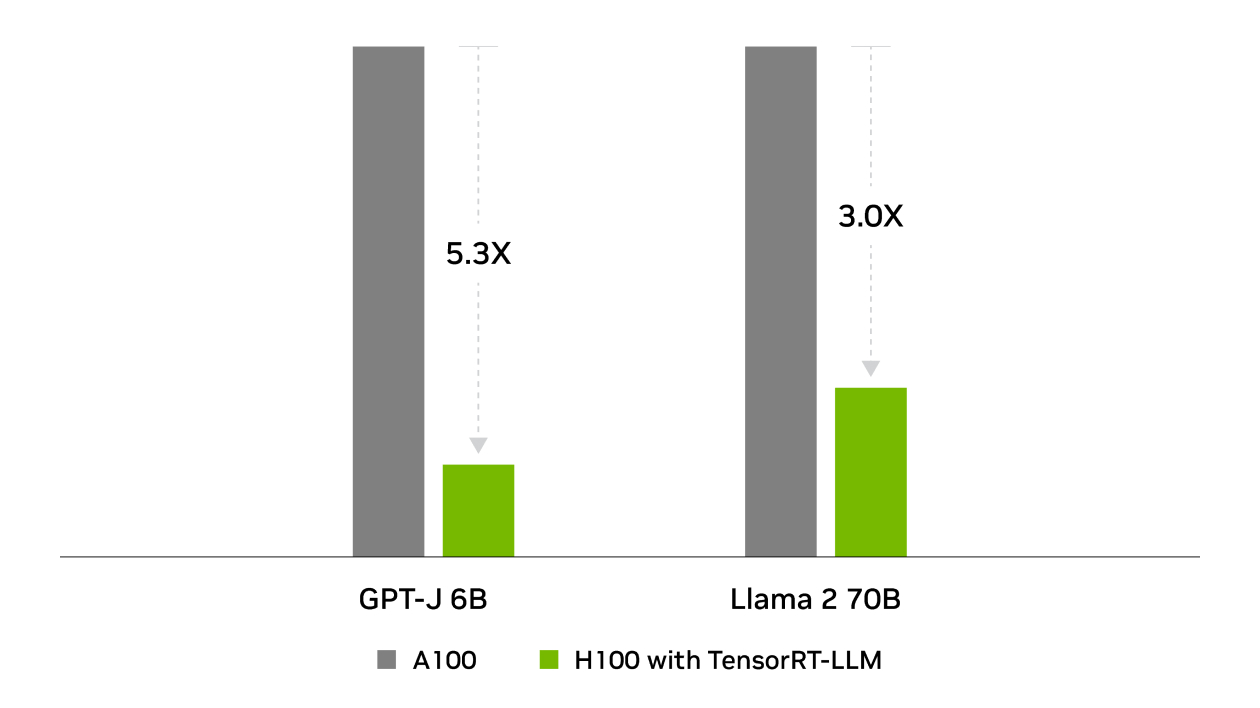
能源使用
入门套件
TensorRT 初学者指南
观看视频:开始使用 NVIDIA TensorRT
TensorRT-LLM 新手指南
观看视频:开始使用 NVIDIA TensorRT
TensorRT 模型优化器新手指南
Torch-TensorRT 初学者指南
下载 Notebook:使用 SSD 进行物体检测( Jupyter Notebook)
TensorRT Pythonic 前端新手指南:Tripy
TensorRT 生态系统
广泛应用于各行各业
更多资源
{kind=link}
道德 AI
NVIDIA 认为可信 AI 是一项共同责任,我们已制定相关政策和实践,以支持开发各种 AI 应用。根据我们的服务条款下载或使用时,开发者应与其支持的模型团队合作,确保此模型满足相关行业和用例的要求,并解决不可预见的产品滥用问题。
有关此模型道德因素的更多详细信息,请参阅模型卡 可解释性、偏差、安全性和隐私子卡。请在这里报告安全漏洞或 NVIDIA AI 问题。
立即开始使用 TensorRT,并使用合适的推理工具为任何平台上的任何应用开发 AI。