
在当今的 AI 工厂环境中,性能并不是理论性的。它是经济、竞争和生存的。可用 GPU 时间每减少 1%,就意味着每小时损失数百万词元。数分钟的拥塞会累积到数小时的恢复时间。机架级功耗超额可能会导致功耗受限,并降低每瓦词元,从而悄无声息地大规模削弱工厂输出。随着 AI 工厂扩展到数千个运行各种任务关键型工作负载的 GPU,不可预测的拥塞、功耗限制、长尾延迟和有限可见性的成本呈指数级增长。
运营团队和管理员需要的不仅仅是仪表板。他们需要灵活性和远见。
NVIDIA 推出了 NVIDIA Mission Control,作为基于 NVIDIA 参考架构构建的 AI 工厂的集成软件堆栈,将 NVIDIA 最佳实践编码为统一的控制平面。Mission Control 3.0 版本进一步扩展,引入了架构灵活性、多组织隔离、智能功率编排和预测性 AIOps,以检测操作中的异常,并更大限度地提高词元的生产效率。

可解锁速度的灵活软件
NVIDIA Mission Control 3.0 引入了基于模块化服务构建的 API 驱动的新分层架构,可提供新的灵活性,从而改进以前紧密合的堆栈,这些堆栈需要跨硬件平台的同步版本和复杂验证。自动化网络管理和域电源服务等新组件为功耗优化提供了新的管理平面,通过将其他模块化服务引入单一控制平面,进一步扩展了 Mission Control 堆栈。
通过将开放组件与模块化设计相结合,这可快速支持最新的 NVIDIA 硬件,同时允许 OEM 系统提供商和独立软件供应商 (ISV) 将 Mission Control 功能直接集成到自己的生态系统中。这样一来,企业现在可以在自己的软件堆栈中获得更多的灵活性和选择,从而更容易定制解决方案,以应对其独特的业务和技术挑战。
多租户环境中的隔离
许多组织面临的一个技术挑战是在集中式 AI 工厂中支持多组织隔离。随着 AI 工厂从研究和实验发展为生产级任务关键型环境,跨多个团队的共享基础设施需要强大的组织隔离和安全的多租户。
增强的 Mission Control 控制平面将 AI 工厂管理堆栈转换为软件定义的虚拟化架构。Mission Control 服务与物理管理节点解,并使用 NVIDIA 提供的自动化功能部署在基于虚拟机 (KVM) 的平台上。虽然每个组织都有专用的计算机架和管理节点,但网络交换机是共享的,需要额外的隔离才能实现多租户。NVIDIA Spectrum-X 以太网的共享网络架构使用 VXLAN 进行逻辑分割,使用 PKey 对 NVIDIA Quantum InfiniBand 进行分割。
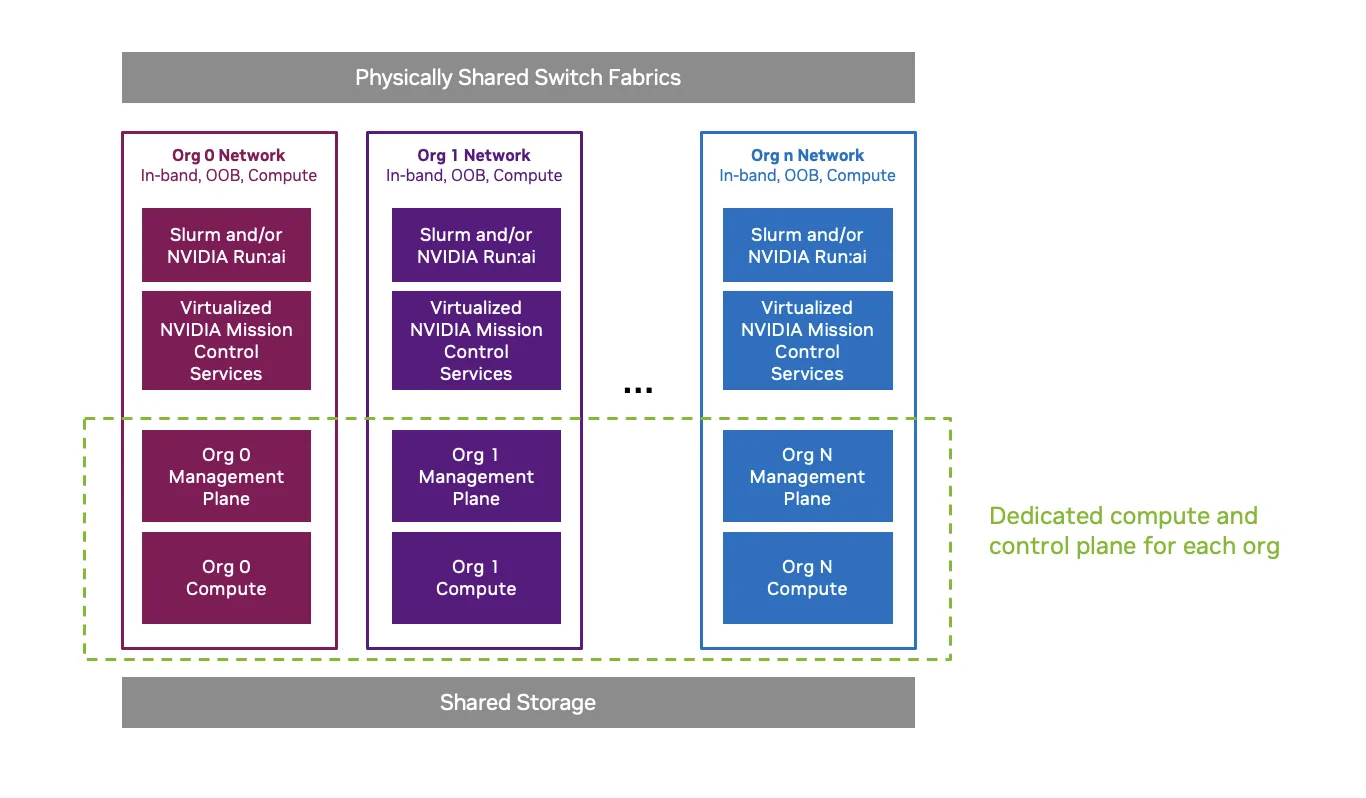
该架构可减少物理管理基础设施的占用空间,建立硬租户隔离,并为多组织 AI 工厂奠定安全的基础。这反过来又降低了总体拥有成本,允许运营商灵活地将多个组织载入共享基础设施,减少了购买和运营多个集群的需求,降低了物理足迹,同时仍然为每个组织提供强大的隔离和自助服务。
力量:无形的约束
AI 工厂词元生产的另一个日益受到关注的问题是,由于固定公用事业和监管合规性等经济限制,固定的功率范围。每一代 GPU 都能提供更高的性能,但设施功耗自然会受到现有数据中心基础设施和可用电网的限制。挑战显而易见:如何在不超过功率限制的情况下增加词元输出和机架密度?
Mission Control 之前迭代中的电源管理帮助组织负责任地管理复杂的电源问题,但它是被动的。作业先安排好,电力政策随后强制执行。虽然这是在平衡功耗和性能方面迈出的重要一步,但需要更多动态解决方案来大规模管理此过程,尤其是在 Slurm 和 Kubernetes 混合环境中。这就是 Mission Control 3.0 版本的发展之处。
通过将域电源服务直接整合到 Mission Control 中,电源成为一级调度基元,可帮助组织利用其电源策略优化词元生产。此电源管理服务可在传统 Slurm 工作负载或由 NVIDIA Run:ai 编排的 Kubernetes 原生工作负载 (已集成并包含在 Mission Control 堆栈中) 中实现功耗感知工作负载布局。域电源服务还支持用于训练和推理的 MAX-P 和 MAX-Q 配置文件,并通过利用 Mission Control 与设施楼宇管理系统的集成来提供机架和拓扑感知型预订转向。
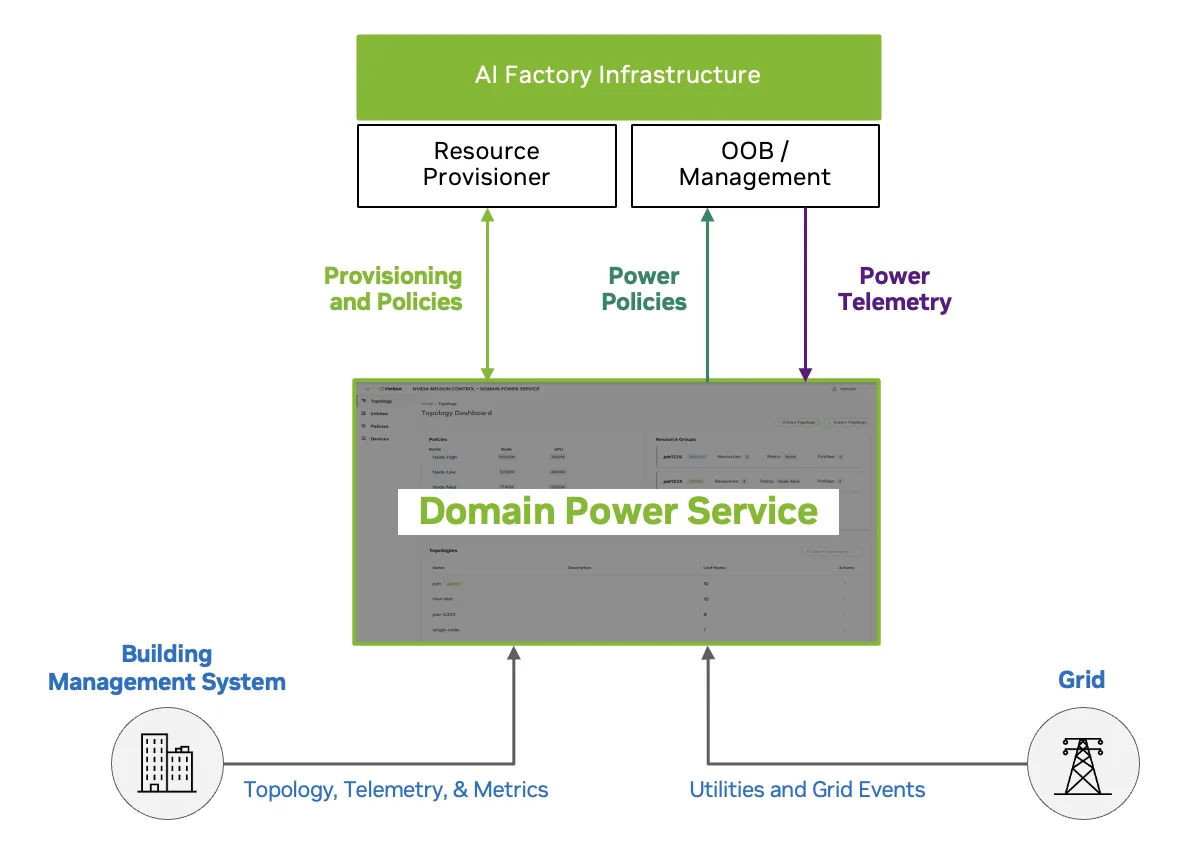
在 NVIDIA 运行 MAX-Q 配置文件的一个示例中,域电源服务允许数据中心以 85% 的功率运行,吞吐量损失仅为 7%。它能够通过动态利用 Mission Control 集成的功率配置文件来实现这一点。
该集成使数据中心运营商能够定义设施限制,AI 从业者可以放心地选择与其工作负载优先级相匹配的性能或效率模式。治理仍然是集中式的,同时灵活性可确保 AI 工厂能够进行调整,以获得出色的每瓦性能和每美元性能。
从仪表板到实时决策
除了为动态电源管理提供新服务外,Mission Control 3.0 版本还通过与 NVIDIA AIOps 采集器和平台堆栈 (NACPS) 集成来增强现有的异常检测能力,从而实现 AI 驱动的预测性异常检测。NACPS 的核心是 AI 集群模型,这是一种基于图形的基础设施和工作负载表示,可跨 GPU、NVIDIA NVLink 纵向扩展、NVIDIA Spectrum-X 以太网或 NVIDIA Quantum InfiniBand 横向扩展以及 NVIDIA BlueField DPU 南北网络创建拓扑感知视图。此视图与集群模型中的作业拓扑相结合。
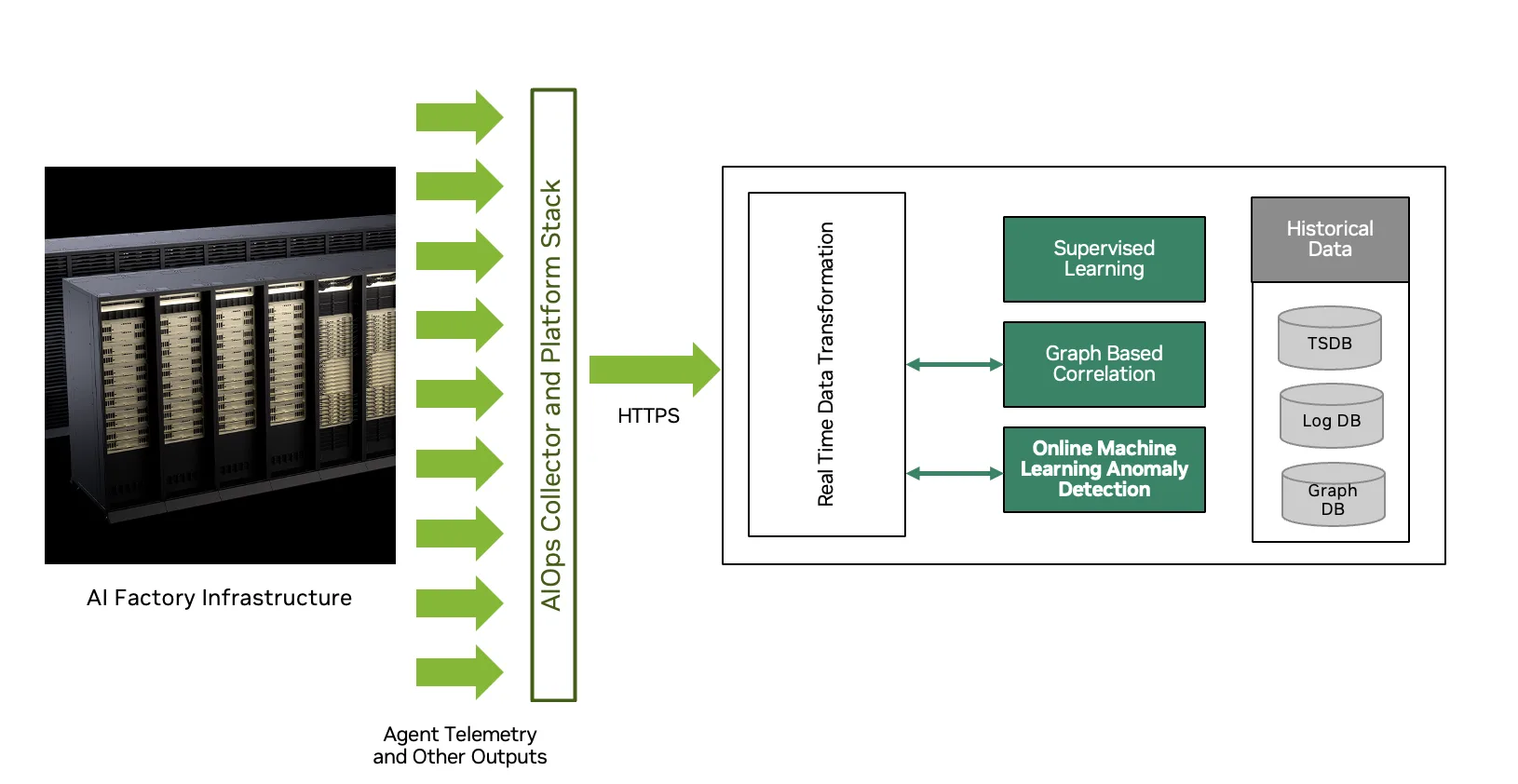
NACPS 结合了基于指标的无监督式在线机器学习、基于自然语言处理 (NLP) 的日志分析 (用于检测未知问题) 、基于已标记事件训练的监督式学习,以及基于规则的确定性护栏。
遥测技术可从 GPU、交换机、主机、网络接口卡 (NIC) 和调度器持续串流到 NACPS。事件和异常会自动跨层关联,从而实现上下文驱动的根本原因分析,同时降低警报噪声。系统理解的不是孤立的指标,而是关系。
当检测到异常时,Mission Control 可以通过自动硬件恢复触发自动修复工作流,该工作流可与 NVIDIA Base Command Manager 或适用于 Kubernetes 工作负载的 NVIDIA Run:ai 中的 Slurm 集成协同工作。
该系统不仅仅监控基础架构。它理解它并据此采取行动。
操作员不再需要追踪症状。他们拥有远见卓识。
另一类 KPI:利用率与词元生产
随着 AI 工厂运营的不断发展,运营团队需要考虑不同类型的 KPI。传统数据中心针对利用率进行了优化,但 AI 工厂需要针对词元生产进行优化。
为了使 AI 工厂针对词元生产进行优化,企业需要考虑以下指标:每个 GPU 和每个机架的词元产量,以及每瓦特和兆瓦的词元产量。每一次低效都会直接降低整体词元输出。如果未检测到和缓解网络结构中的拥塞,或者单个机架意外超过其功率限制,或者计算节点在作业中遇到异常情况,AI 工厂将失去词元一代产品和潜在收入。
然而,当 AI 工厂以智能方式运行时,它能够将每兆瓦的功率精确转换为词元,从而更大限度地提高产量。
开始使用 Mission Control
Mission Control 3.0 旨在最大限度地减少 AI 工厂操作员的效率低下问题,并增加词元输出。通过跨领域关联遥测、智能地编排功耗、模块化架构以提高敏捷性,以及利用 AI 增强自主补救,它将基础设施从被动平台转变为性能优化的主动参与者。
资源:
敬请关注我们关于 NVIDIA Mission Control 3.0 的最新版本说明和实施指南。
您还可以观看礼来公司主持的 NVIDIA GTC 2026 会议的点播回放,了解有关使用强大的智能软件构建和部署高性能 AI 基础设施的第一手见解。




