
企业数据本身具有高度复杂性:现实世界中的文档是多模态的,包含文本、表格、图表与图形、图像、扫描页面、表单以及嵌入式元数据。财务报告的关键信息往往体现在表格中,工程手册则依赖图表传递核心内容,而法律文档通常包含批注或扫描件。
检索增强生成 (RAG) 创建的目的是让 大语言模型(LLM) 基于可信的企业知识,在响应查询时检索相关源数据,以减少幻觉现象并提升准确性。然而,若 RAG 系统仅处理周围的文本,便会忽略嵌入在表格、图表和图形中的关键信息,导致生成的答案不完整或出现错误。
智能体的能力取决于其构建所依赖的数据基础。因此,现代 RAG 必须具备多模态特性,能够理解视觉与文本上下文,以实现企业级的准确性。 NVIDIA 企业 RAG Blueprint 正是为此而设计,提供了一套模块化的参考架构,将非结构化的企业数据与基于这些数据构建的智能系统连接起来。
该blueprint仍是NVIDIA AI数据平台的基础层,有助于弥合计算与数据之间的传统差距。通过将检索和推理更贴近数据层,它能够保持数据治理,减少操作摩擦,并让智能系统即时利用企业知识。最终构建出现代AI数据堆栈,即一种能与模型协同进行检索、丰富和推理的存储体系。
虽然企业 RAG Blueprint 提供了多种可配置选项,但本文重点介绍其中五个关键配置,这些配置能显著提升企业用例中的准确性和上下文相关性:
- 基准多模态 RAG 工作流
- 推理
- 查询分解
- 通过过滤元数据,提升检索速度与准确性
- 多模态数据的视觉推理
本文还介绍了如何将该 blueprint 嵌入 AI 数据平台,实现从传统资源库向 AI 就绪型知识系统的转变。
此博客中的准确性指标采用 RAGAS 框架,使用知名公共数据集进行测量。详细了解如何评估 NVIDIA RAG Blueprint 系统。
1. 文档提取和理解
在智能体提供见解之前,必须完全基于您的数据。此基础配置专注于智能文档提取与核心 RAG 功能。
企业 RAG Blueprint 使用 NVIDIA NeMo Retriever 提取多模态企业内容(文本、表格、图表和信息图),并将这些内容嵌入文本,以便在向量数据库中建立索引。在查询阶段,Blueprint 执行语义检索、重排序,并利用 Nemotron LLM 生成基于检索结果的答案。
为更充分地提升性能,此基准有意避免图像描述和复杂的推理过程,因而成为生产部署的理想起点。可在 Docker 上部署此基准。
文档提取和理解的优势
这种基础配置是 Blueprint 高效的工作流,针对准确性和吞吐量进行了优化,同时将 GPU 成本和时间保持在较低水平,直至首个 token (TTFT)。此配置为检索质量和 LLM 接地建立基准性能。
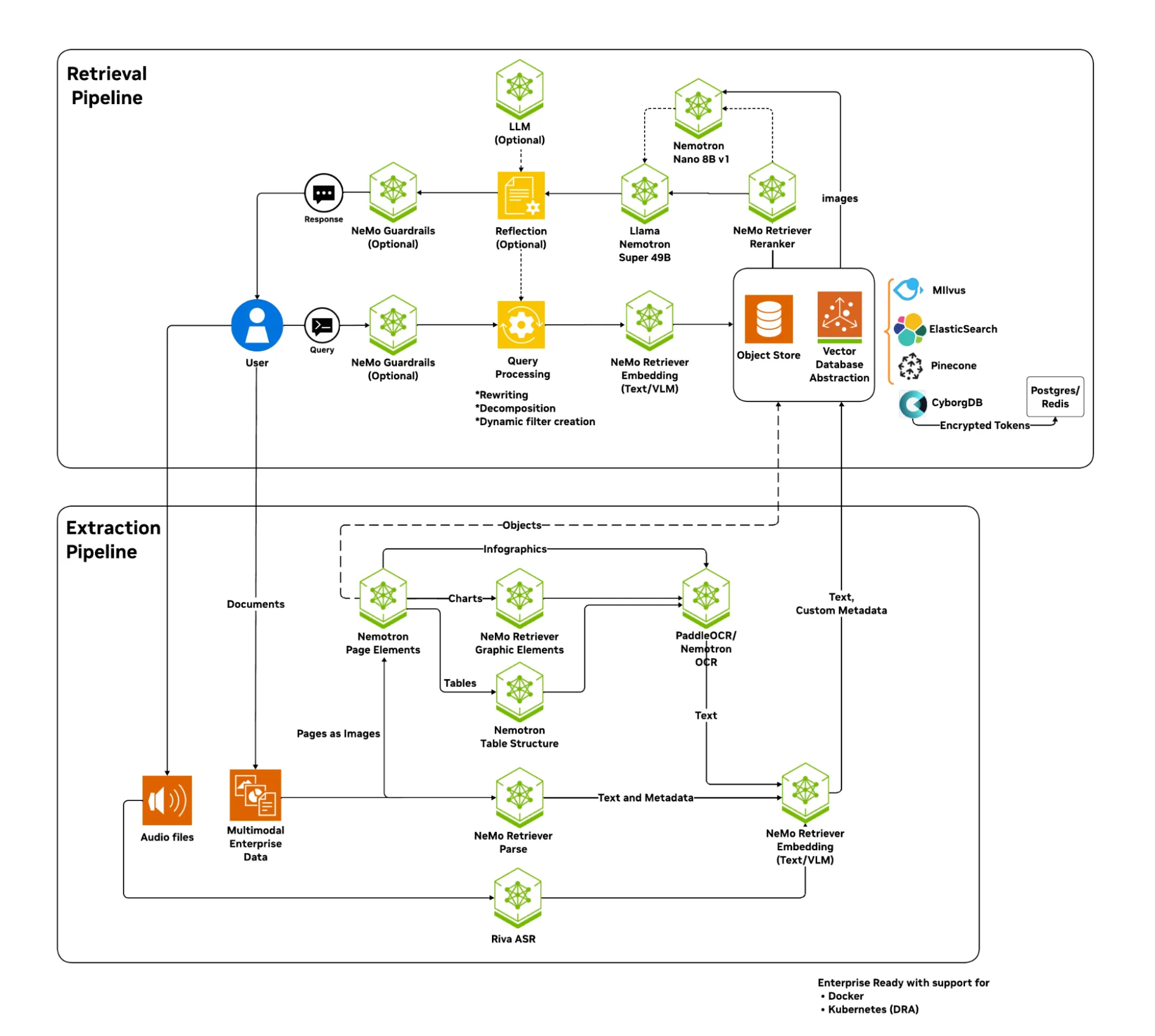
表 1 汇总了多个数据集的整体影响。
| 准确性 (v2.3 默认) MM = 多模态,TO = 仅文本 |
||
| 数据集 | 类型 | 精度 |
| RAG Battle | MM | 0.809 |
| KG RAG | MM | 0.565 |
| FinanceBench | MM | 0.633 |
| BO767 | MM | 0.910 |
| HotpotQA | TO | 0.671 |
| Google Frames | MM | 0.509 |
2. 推理
当您在 RAG blueprint 中开启推理功能时,可启用 LLM 对检索到的证据进行解释,并综合逻辑生成答案。对于许多应用而言,这一调整能有效提升准确性。 支持对 NVIDIA 企业 RAG Blueprint 进行推理。
表 2 汇总了多个样本数据集的整体影响。
| 准确性 (v2.3 默认) 加推理 MM = 多模态,TO = 仅文本 |
|||
| 数据集 | 类型 | 推理 | 默认 |
| RAG Battle | MM | 0.85 | 0.809 |
| KG RAG | MM | 0.58 | 0.565 |
| FinanceBench | MM | 0.69 | 0.633 |
| BO767 | MM | 0.88 | 0.91 |
推理的优势
对于涉及数学运算或复杂数据比较的用例,典型的简单相似性搜索或混合搜索均难以满足需求。推理能力是纠正错误、确保准确理解上下文的关键。各数据集的准确性平均提升了 5%,部分案例更展现出显著的推理驱动型修正效果。
示例
在 FinanceBench 数据集中,基准配置错误地将 Adobe 2017 财年的运营现金流比计算为 2.91,而启用推理后,模型生成了正确的答案 0.83。此外,Ragbattle 数据集 demonstrates the accuracy improvement 从启用 VLM 后准确率有所提升。
3. 查询分解
回答复杂的用户问题通常需要从数据源的多个位置提取事实。 查询分解 可将单个问题拆解为若干子查询,针对每个子查询检索相应证据,再将结果整合为完整且有依据的响应。 启用 NVIDIA Enterprise RAG Blueprint 的查询分解功能。
查询分解的优势
查询分解可显著提升多跳问题及需跨多个段落或文档理解的上下文丰富问题的准确性。尽管该方法会增加额外的 LLM 调用(导致延迟和成本上升),但对于任务关键型企业用例而言,准确性的提升通常足以抵消这些代价。在必要时,还可将查询分解与推理结合使用,以进一步增强效果。
示例
随着 NVIDIA AI 数据平台合作伙伴持续优化,以提供更相关、更准确的检索,该功能可包含作为数据平台一部分的查询处理,也可将查询处理交由智能体完成。深入了解在某些用例中如何应用查询分解方法。
表 3 显示了部分数据集的整体影响。
| 准确性(v2.3 默认)结合查询分解 MM = 多模态,TO = 仅文本 |
|||
| 数据集 | 类型 | 查询分解 | 默认 |
| RAG Battle | MM | 0.854 | 0.809 |
| FinanceBench | MM | 0.631 | 0.633 |
| BO767 | MM | 0.885 | 0.91 |
| HotpotQA | TO | 0.725 | 0.671 |
| 谷歌帧 | MM | 0.6 | 0.5094 |
4. 筛选元数据,提升检索速度与准确性
作者、日期、类别和安全标签等元数据始终是企业数据不可或缺的组成部分。在 RAG 工作流中,可通过元数据过滤器缩小搜索范围,使检索结果与相应上下文保持一致,从而有效提升检索的准确性和效率。
RAG Blueprint 支持自定义元数据提取以及基于这些数据的自动查询生成。如需使用您的自定义元数据,请参阅自然语言生成实现高级元数据过滤。要深入了解此功能集的具体能力,可查看NVIDIA-AI-Blueprints/rag GitHub 仓库中的示例 Notebook。
元数据过滤的优势
元数据过滤能够缩小搜索范围,从而加快检索速度,并通过使检索结果与上下文保持一致来提升准确性。这使得开发者无需编写手动过滤逻辑,即可利用元数据实现更高的吞吐量和更强的上下文相关性。当元数据过滤功能直接集成到 AI 数据平台时,可让存储系统更加智能化,进一步提升检索效率并降低延迟。
示例
例如,请考虑以下通过元数据提取得到的两个文档:
custom_metadata = [
{
"filename": "ai_guide.pdf",
"metadata": {
"category": "AI",
"priority": 8,
"rating": 4.5,
"tags": ["machine-learning", "neural-networks"],
"created_date": "2024-01-15T10:30:00"
}
},
{
"filename": "engineering_manual.pdf",
"metadata": {
"category": "engineering",
"priority": 5,
"rating": 3.8,
"tags": ["hardware", "design"],
"created_date": "2023-12-20T14:00:00"
}
}
将元数据与动态过滤器表达式结合使用时,“Show me high-rated AI document with machine learning Tags created after January 2024”(显示我在 2024 年 1 月之后创建的带有机器学习标签的高评分 AI 文档)这类查询将被转换为自动生成的过滤表达式查询,例如:
filter_expression = `content_metadata["category"] == "AI" and content_metadata["rating"] >= 4.0 and
array_contains(content_metadata["tags"], "machine-learning") and content_metadata["created_date"] >= "2024-01-01”`
启用元数据过滤后,系统从一个文档(ai_guide.pdf)中检索出10个重点引用,在目标域上实现了100%的精度,同时将搜索空间缩减了50%。
5. 多模态数据的视觉推理
企业数据蕴含丰富的视觉信息。当传统纯文本嵌入无法满足需求时,视觉语言模型(VLM)如 NVIDIA Nemotron Nano 2 VL(12B)可将视觉推理引入工作流。深入了解如何在 RAG Blueprint 中利用 VLM 实现生成。

视觉推理的优势
视觉推理对于处理真实的企业文档至关重要。在生成路径中集成视觉语言模型(VLM),可使 RAG 系统能够解读图像、图表和信息图,从而准确回应那些关键信息位于结构化视觉元素(而不仅限于周围文本)中的查询。
示例
在 RAG Blueprint 中为 Ragbattle 数据集启用 VLM 时,准确性明显提升,尤其是在答案包含于视觉元素中的情况下。需要注意的是,启用 VLM 推理会增加额外的图像处理延迟。建议根据实际需求在准确性和响应速度之间进行权衡。深入了解 VLM 如何提升 Ragbattle 数据集的准确性。
将企业存储转化为主动知识系统
企业 RAG Blueprint 展示了逐步采用这五项功能(从推理和元数据驱动的检索到多模态理解)如何直接提升智能体的准确性和接地性。每一项功能都在延迟、token 成本与上下文精度之间实现了独特的平衡,提供了一个灵活且可调适的框架,适用于多种企业应用场景。
这加速了数据基础本身的发展。NVIDIA AI 数据平台能够将企业数据转化为可供 AI 搜索的知识。随着 NVIDIA 合作伙伴持续推动存储产品的演进,该 blueprint 可作为提供嵌入式 RAG 功能的参考,利用元数据实现权限管理、变更追踪,并在存储层直接提供高准确度的检索能力。
NVIDIA 存储合作伙伴正基于 NVIDIA 参考设计构建 AI 数据平台,将企业存储从被动存储库转变为 AI 工作流中的主动智能系统。这一转变催生了新一代企业数据基础设施:更快速、更智能,专为生成式 AI 时代而打造。
NVIDIA 企业 RAG Blueprint 的新增功能
最新版本的 NVIDIA EnterpriseRAG Blueprint 进一步聚焦于支持代理式工作流。通过引入浅层与深度策略,实现了先进的文档级摘要功能,使智能体能够快速评估相关性、缩小搜索范围,并在准确性与延迟之间实现平衡。新增的数据目录提升了大型语料库的可发现性与治理能力,结合升级后的先进 Nemotron RAG 模型,进一步优化了检索质量以及推理和生成性能,使 RAG 成为企业级知识系统中更高效、更适配代理需求的基础架构。
开始使用企业级 RAG
准备好将这五项功能集成到您的 RAG 用例中了吗?立即在 NVIDIA Enterprise RAG Blueprint 中免费获取模块化代码、文档和评估 Notebook。
借助 NVIDIA AI 数据平台,让企业数据具备 AI 就绪能力,并通过嵌入式 RAG 功能将生产数据转化为智能知识系统。联系 NVIDIA AI 存储合作伙伴,启动您专属的 NVIDIA AI 数据平台。




