
LLM 上下文长度呈爆炸式增长,架构正朝着更复杂的注意力机制发展,例如多头潜在注意力(MLA)和分组查询注意力(GQA)。因此,AI 的“思维速度”越来越受限于矩阵乘法的大规模吞吐能力,而 Softmax 函数的前置数学运算也逐渐成为瓶颈。
超越是指无法表示为具有合理系数的多项式方程的根的函数。这类函数因而超出了加法和乘法等基本代数运算的范畴,而这正是 Tensor Core 擅长的精确运算领域。在 softmax 的具体场景中,涉及的超越函数里,计算开销较大的是自然指数函数,该函数在特殊函数单元(SFU)上执行。在 NVIDIA 组装指令(SASS)中,此函数通过 MUFU.EX2 指令调用。当强大的矩阵引擎需等待 SFU 数据路径完成注意力得分的归一化时,这种架构上的分工便会在注意力块内形成 softmax 的性能瓶颈。
NVIDIA Blackwell Ultra 通过将 SFU 吞吐量提升至标准 NVIDIA Blackwell 架构的两倍,有效缓解了这一瓶颈。
本博客将深入探讨注意力循环中的 softmax 机制,分析 Blackwell Ultra 的硬件优化如何消除工作流中的停顿,并提供基准测试,帮助您自行测量原始 MUFU.EX2 的加速效果。
注意力的工作原理
现代大语言模型的一个基础组件是注意力机制,该机制能够动态地将静态的 token 向量转化为上下文感知的动态表示。其核心在于对信息进行重新加权,使各个 token 能够调整彼此之间的相对重要性。为了实现这种交互,序列中的每个 token 都会被映射到三个不同的功能角色中:
- 查询: 表示当前 token 旨在理解自身所处上下文的内容。
- 密钥: 表示其他 token 用于匹配的配置信息;序列中 preceding tokens 的密钥反映了它们与当前查询的相关性。
- 值: 包含实际信息内容;当查询与密钥匹配成功后,对应的“值”即被传递至当前 token,作为所获取的具体数据。
下图 1 显示了实际注意力。我们有两个句子,在两种不同的语境中使用“狗”一词。起初,可以看到两个“狗”的指代表达在嵌入空间中(即在多维空间中捕捉语义和细微差别的数字向量)完全相同。
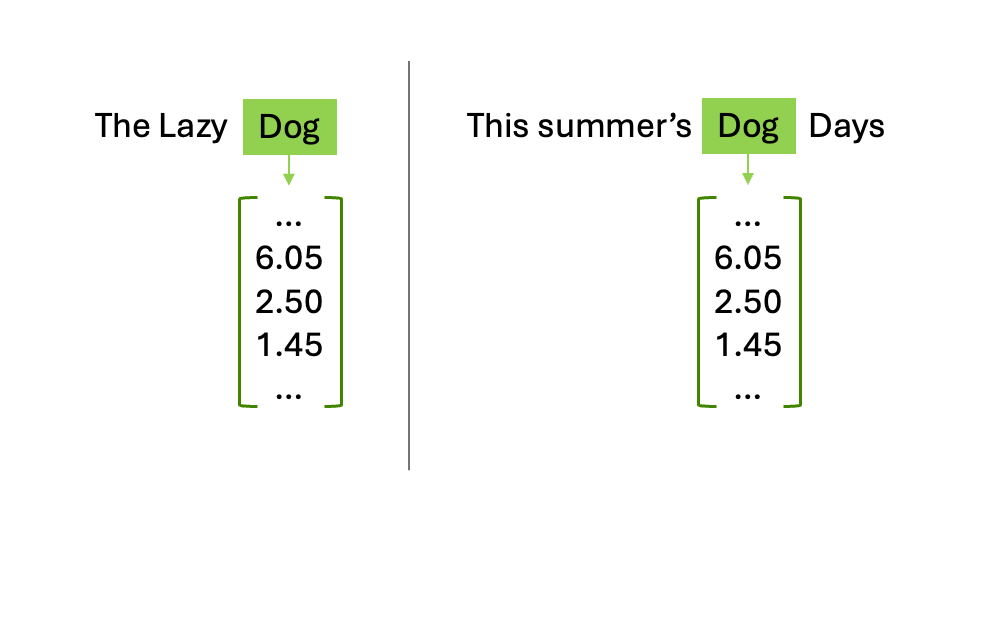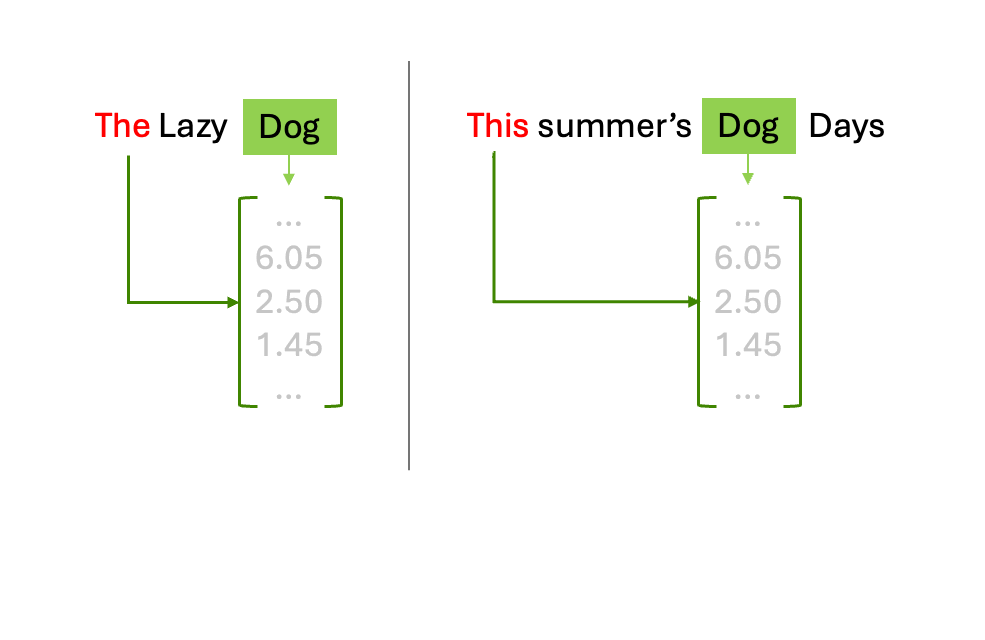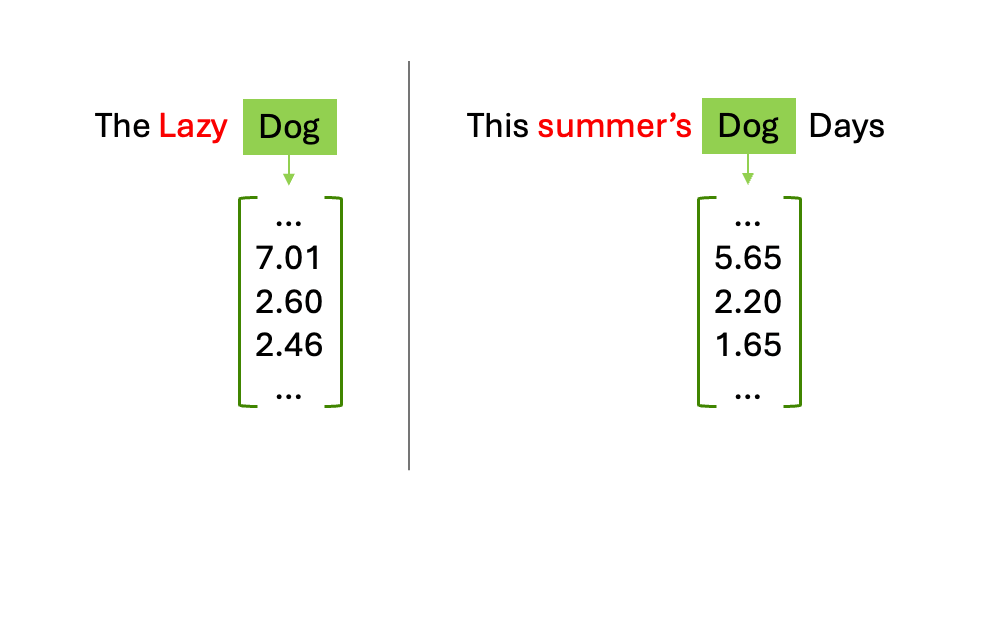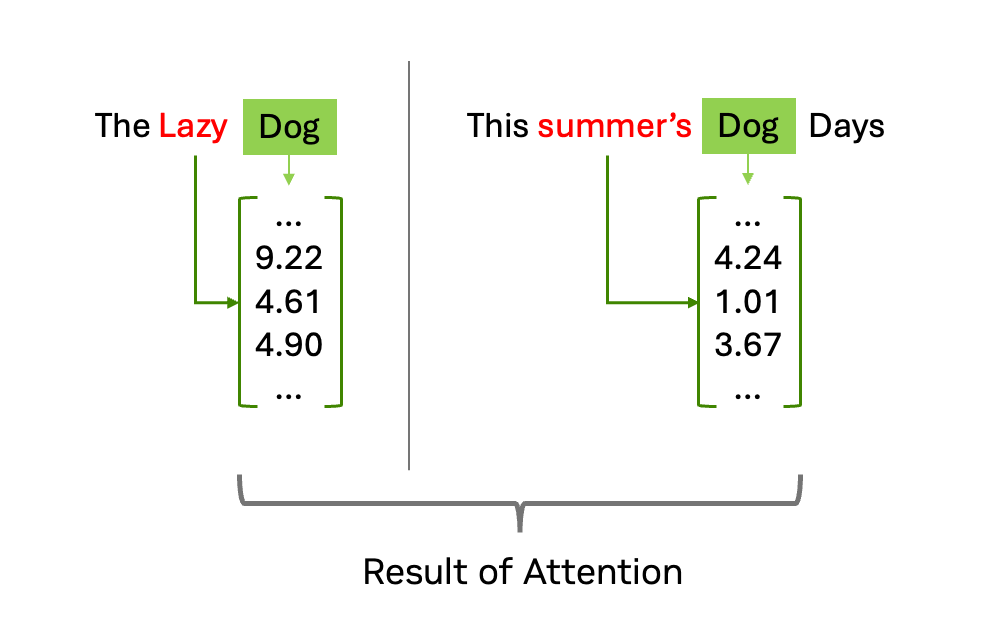
注意力操作的模型通过计算“狗”这一查询与序列中所有其他 token 对应的键之间的点积来实现。
如果对“dog”的查询与“lazy”的键高度匹配,则表明两者具有强相关性。这种交互使得“狗”这一词能够提取其相邻词的特定语义信息。在此过程结束时,“狗”的原始向量会依据其邻近词的内容被实际更新,从而从通用的词典定义演变为上下文相关的嵌入表示,能够“理解”其所指是慵懒的动物,还是酷暑时节的倦怠状态。
Softmax 与注意力的关系
Softmax 是将原始兼容性分数转化为可操作权重的关键决策阶段。在计算出查询与键之间的初始点积后,所得分数会经过 softmax 函数处理,归一化为总和恰好为 1 的概率分布。该步骤决定了模型的“注意力范围”,从而有效确定需要重点关注和忽略的 tokens。若缺少 softmax,模型将难以客观地权衡所获取的信息,导致信息融合过程混乱且难以控制。
然而,softmax 运算是长上下文 AI 中“性能悬崖”的主要来源。由于必须将序列中的每个 token 与其他所有 token 进行比较,长度为 8192 的序列便会生成一个庞大的 [8192 × 8192] 注意力矩阵。对该矩阵进行归一化需要执行数十亿次超越运算,且计算量随序列长度呈二次增长。这形成了一个瓶颈,即大规模的超越性数学运算可能严重拖慢整个推理流程。
Blackwell Ultra 专注于加速这些指数级计算,以缓解数学瓶颈,并确保系统在不牺牲吞吐量的前提下,高效处理大型上下文窗口所需的大规模归一化任务。
缓解 Blackwell Ultra 中的 softmax 瓶颈
通过在 Blackwell Ultra 架构中将指数级 SFU 的吞吐量提升一倍,NVIDIA 缓解了这一瓶颈,实现了更均衡、更高效的处理流程,从而提升了整体性能,尤其有利于对注意力机制影响显著的任务。
下图 2 展示了在上一代 NVIDIA Blackwell (GB200) 上运行的标准注意力机制(通常称为注意力循环)所具有的顺序依赖关系。请注意,流多处理器 (SM) 加载了两个同时执行注意力循环的线程块,这些独立的注意力循环以两种不同的绿色表示。
此工作流由三个不同阶段组成,必须按顺序执行:
- BMM1(分数计算):Tensor 核心执行矩阵乘法,用于计算原始注意力分数或对数。
- Softmax(归一化):工作流转移到 SFU,通过指数函数将这些分数归一化为概率。
- BMM2(上下文聚合):流程返回至 Tensor Core,将概率与值向量相乘以完成上下文聚合。

时间轴说明了 Blackwell GPU 在执行注意力内核时固有的延迟限制。由于第二个矩阵乘法 (BMM2) 作用于 softmax 的输出,因此必须在归一化完成之后才能开始。
Blackwell GPU SFU 的低吞吐量导致 Tensor 核心在分数计算 (BMM1) 和上下文聚合 (BMM2) 之间处于闲置状态。这种依赖关系阻碍了计算资源的充分流水化利用,从而延长了 softmax 操作的执行时间。
如图 3 所示,下一个时间轴展示了 Blackwell Ultra GPU 在 NVIDIA GB300 NVL72 和 NVIDIA HGX B300 系统中的直接影响,即在相同指令序列下,SFU 吞吐量提升一倍。

在视觉上,softmax 块的宽度减少了近 50%,表明硬件处理 MUFU 指令的速率提升了一倍。
Softmax 延迟的降低使整个工作流更加紧密。BMM1 与 BMM2 之间的差距显著缩小,使得 Tensor Core 能在查询键乘法和概率值乘法之间灵活切换,同时最大限度减少延迟。这带来了一个更密集的主循环,高性能矩阵引擎在总执行时间中占据更高比例,从而直接提升了整体推理吞吐量。
基准测试 MUFU.EX2 性能
为验证 MUFU 工作流理论吞吐量的经验准确性,可构建合成微基准。以下内核代码隔离指数指令,用于测量原始循环次数,避免受全局内存延迟或其他算术运算的干扰。
此测试线束启动线程网格,使每个线程执行 MUFU.EX2 指令的密集循环。通过测量执行时间并与时钟频率进行比较,可直接计算出有效指令吞吐量,并验证前述的带宽饱和点。
第 1 步:克隆以下仓库以获取 exp2-bg300.cu 基准测试。
git clone https://github.com/jamieliNVIDIA/mufu_ex2_bench.git
cd mufu_ex2_bench
第 2 步:编译(GB300 使用 sm100f,GB200 使用 sm103a)。
nvcc -O3 -gencode=arch=compute_103a,code=sm_103a --extended-lambda -o /tmp/exp2-gb300.out exp2-gb300.cu
样本结果
我们看到,对于所有测试数据类型,GB300 的 FLOPS 性能相较 GB200 提升了 2 倍,这与 SFU 吞吐量翻倍的情况相符。
Blackwell ( GB200)
exp2 BF16x2 2454 Gop/s (4908 GFLOPS)
exp2 BF16 4938 Gop/s
exp2 FP32 4943 Gop/s
Blackwell Ultra ( GB300)
exp2 BF16x2 4996 Gop/s (9992 GFLOPS)
exp2 BF16 9738 Gop/s
exp2 FP32 Time: 10024 Gop/s
Blackwell 与 Blackwell Ultra 中注意力机制的正向传播性能
从 Blackwell 到 Blackwell Ultra 的过渡,在 SFU 性能提升 2 倍的推动下,计算吞吐量得到针对性增强。此次硬件升级可直接加速 DeepSeek-V3 等模型的前向传播(FPROP)工作流。
FPROP 是输入数据在神经网络中“向前”传播的过程,即从输入层经过隐藏层传递到输出层,从而生成预测结果。模型每生成一个新词时,都需要执行一次完整的 FPROP 传递。
如下图 4 所示,通过将 SFU 的吞吐量提升一倍,GB300 能够显著缩短注意力块中 softmax 层的执行时间。这种更高效的归一化过程使得 GPU 在处理注意力分数上耗费的时间减少,从而有更多时间利用高速矩阵引擎执行下一层的计算,直接提升了前向传播的整体速度。
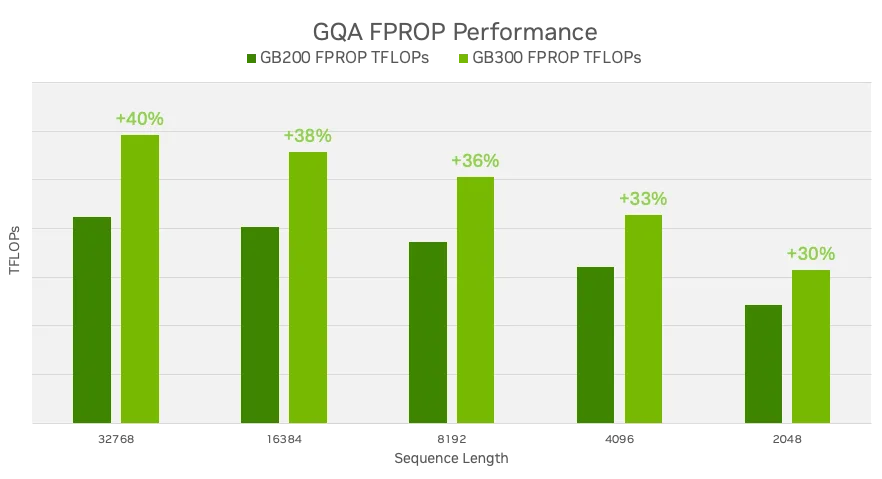
基准测试结果显示,FP8 运算的 FPROP 吞吐量提升了约 35%。** 这一提升在 FP8 中尤为显著,因为矩阵数学运算本身已非常高效。在此低精度模式下,softmax 所耗费的时间在整体步长中占据更大比例。
入门指南
Blackwell Ultra 上 DeepSeek-V3 的性能表现凸显了推理过程中一个关键但常被忽视的瓶颈:非线性运算的计算成本。
通过优化和压缩注意力机制,先进的模型能够有效提升 softmax 运算相对于标准线性计算的计算密度,从而使 SFU 成为总吞吐量的调节器。
Blackwell Ultra 可直接解决这一瓶颈。通过将这些专用设备的吞吐量提升一倍,Blackwell Ultra 能有效缓解此前导致强大 Tensor Core 闲置的严重流量拥堵问题。基准测试结果验证了这一改进,显示 FP8 前向传播性能提升了 35%。
对于高度优化的现代架构而言,实现更快推理的关键不仅在于更高效的 Tensor Core,还在于确保非线性数学单元的运算速度能够匹配推理需求。
访问 NVIDIA 的 trtllm-gen 存储库,了解更多信息,包括基准测试以及如何在工作负载中利用这种 SFU 加速。将 MUFU.EX2 的 SFU 吞吐量提升一倍,仅仅是实现 Blackwell Ultra 快速注意力的多项功能之一。NVIDIA 出色的软硬件协同设计通过以下技术,全面加速整个注意力循环:
请持续关注 NVIDIA 技术博客,以获取后续文章。
致谢
特别感谢 cuDNN 工程团队建立基准并开发软件优化,从而实现这一前沿性能。




