
随着 AI 数据中心迅速演变为 AI 工厂,传统的网络监控方法已难以满足需求。工作负载日益复杂,基础设施快速扩展,实时且高频率的洞察变得至关重要。有效的系统监控比以往任何时候都更为迫切。
本文将探讨高频采样与高级遥测技术如何应对这些挑战,并优化 AI 工作负载。该方法不仅提升了 NVIDIA Spectrum-X 以太网架构中 AI 工作负载的性能,还为用户提供主动的事件管理功能.
什么是 AI 网络遥测?
在 AI 工厂中,AI 工厂,遥测是指收集、传输和分析与系统性能、资源使用情况及其他操作指标相关的数据。这些实时数据对于管理与优化 AI 工作负载具有关键作用。
遥测在了解 AI 基础设施的性能与运行状况方面发挥着至关重要的作用。AI 模型(尤其是大规模 LLM 训练)高度依赖高性能计算资源,而这些资源又依赖于 GPU、CPU 和存储系统等组件之间的高效数据传输。
为什么流网络遥测对人工智能很重要?
传统的网络监控依赖于基于轮询的技术,按照固定的时间间隔(例如每隔几秒或几分钟对设备进行一次查询)来获取数据。这种方法往往无法捕捉短期异常或瞬态网络问题,而这些问题可能对 AI 工作负载的性能造成显著影响。
因此,传统监控系统的粒度和可见性会明显降低。由于这些瞬变问题在几毫秒内出现,且迅速消失,通常难以被察觉。因此,它们可能中断 AI 工作负载、LLM 操作和推理流量,且不留下任何痕迹,导致宝贵的 GPU 周期被浪费、处理时间延长,进而降低整体系统效率。
相比之下,现代遥测技术通过高频率持续串流数据,提供对网络性能的精细且实时的可见性。这有助于实现主动的事件管理,而非被动的故障排除,并能够扩展以处理由数百乃至数千个节点和 GPU 生成的数据。
这在 AI 工作负载中尤为关键,因为在这些工作负载中,毫秒级的同步是性能的核心。
此外,仅从网络角度解决问题未必意味着存在此类异常情况。以 AI 为中心的全面监控方法可在这些复杂的环境中取得更佳效果。
提供 RDMA 网络的可见性
AI 系统遥测的重要需求之一是了解远程直接内存访问 (RDMA) 网络。RDMA 技术通过允许系统之间直接访问内存来加速数据传输,无需经过 CPU。这显著提升了吞吐量并降低了延迟,使 AI 工作负载能够更快速地运行,并更充分地利用网络容量。
为了使 RDMA 发挥最佳性能,它依赖于真正的无损网络。然而,AI 工作负载对网络问题十分敏感,即便是微小的低效,也会对整体性能产生连锁影响。根据近期研究,RDMA 对网络异常尤为敏感,进而影响 GPU 训练效率。有关更多详细信息,请参阅用于元规模分布式 AI 训练的以太网 RDMA和用于大规模分布式 AI 训练的 RoCE 网络。
AI 工作负载(尤其是使用 NVIDIA 集合通信库(NCCL)的工作负载)依赖于节点间低延迟、高吞吐量且无损的通信。任何抖动、拥塞或丢包问题都会显著影响模型训练或推理的性能。
高频遥测至关重要,因为它能让操作员:
- 实时检测数据包丢失或硬件故障等问题
- 通过主动式故障排查保障 SLA
- 优化网络利用率、资源分配与负载均衡
- 基于数据驱动的决策,确保在大型集群中的可扩展性
如果没有正确的遥测,就无法检测到这些隐藏的 RDMA 相关问题,例如网络拥塞、微秒级延迟峰值以及数据包丢失。因此,遥测系统在实时识别和诊断这些问题方面至关重要,能够确保 AI 模型的训练与部署过程不会遭遇不必要的性能下降或瓶颈。
此外,AI 工作负载的性能分析能够以极高的粒度完成,从而有效识别模式、评估生产性能等。
内置遥测的 NVIDIA Spectrum-X 以太网 AI 网络架构
NVIDIA Spectrum-X 以太网 是一种基于以太网的 AI 网络解决方案,专为高性能 AI 工作负载设计。Spectrum-X 以太网将数据中心网络与在大型 AI 工厂上运行的复杂 AI 工作负载深度融合,实现协同高效运作。
Spectrum-X 以太网紧密集成:
- NVIDIA Spectrum SN5000 系列以太网交换机
- NVIDIA BlueField-3 SuperNIC 与 NVIDIA ConnectX-8 SuperNIC
- NVIDIA Hopper、Blackwell 及 Rubin GPU
- NVIDIA NetQ 遥测与分析平台
- Cumulus Linux 网络操作系统


每个组件都贡献自身的遥测数据,共同构成对网络运行状况和性能的整体视图。例如:
- DTS SuperNIC 遥测可能会显示标记为自适应路由的数据包数量。
- 交换机遥测数据可呈现实际的路由决策结果。
- NetQ 能够通过统一界面收集、关联并可视化这些数据,结合 NVIDIA AI 专业技术,将来自不同来源的原始遥测信息转化为有价值的 AI 洞察。
借助这种以洞察为导向的遥测系统,识别与解决网络问题变得更加直观便捷。
开放的可扩展性标准
遥测系统必须具备开放性且不受特定供应商限制,才能有效发挥作用。Spectrum-X 以太网支持:
- OpenTelemetry 接口
- gRPC 网络管理接口(gNMI)
这样可以:
- 与各类第三方工具的互操作性
- 跨异构环境的可扩展能力
- 全面的指标覆盖范围,支持深入的根本原因分析
示例 1:对 LLM 工作负载进行故障排除
为完善 Spectrum-X 以太网遥测功能,NVIDIA 工程师在 NVIDIA Israel-1 超级计算机上,利用真实 AI 工作负载持续开展压力测试。
图 2-5 显示了以 PromQL 作为数据源的 Grafana 控制面板。Grafana 连接到 NetQ,并通过 PromQL 查询访问时间序列数据库。NetQ 从 Spectrum 以太网交换机、GPU、NIC、主机(通过 DTS)以及 SLURM AI 工作负载中收集实时 OTLP 遥测指标。最终,Grafana 作为可视化层,连接到 NetQ 的 PromQL API,用于生成展示这些指标的控制面板和图表。
长期运行的 LLM 工作负载预计将利用极高带宽。然而,遥测结果显示有效带宽出现了急剧且不规则的下降(图 2)。
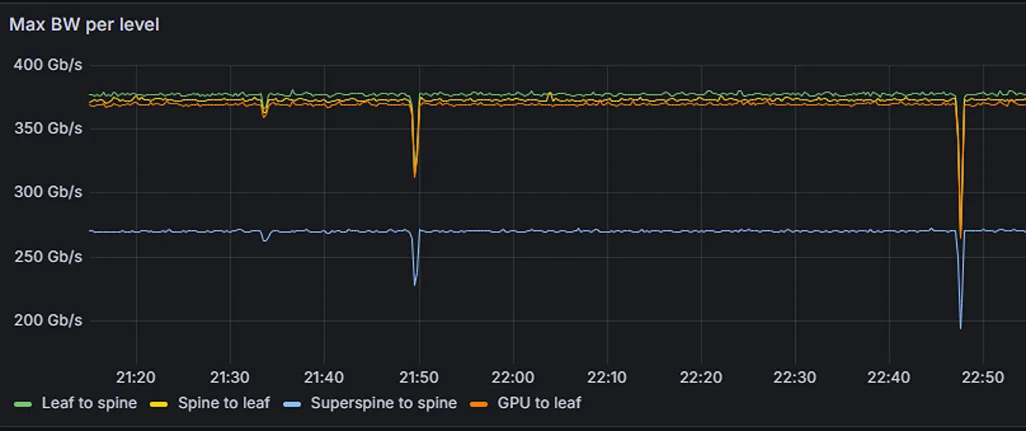
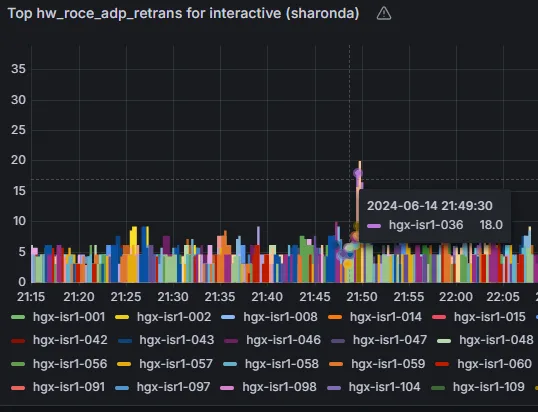
在进一步检查中,BlueField-3 DTS(通过 NetQ)显示 roce_adp_retrans 计数器值较高,表明存在 RoCE 数据包重传现象(图 3)。

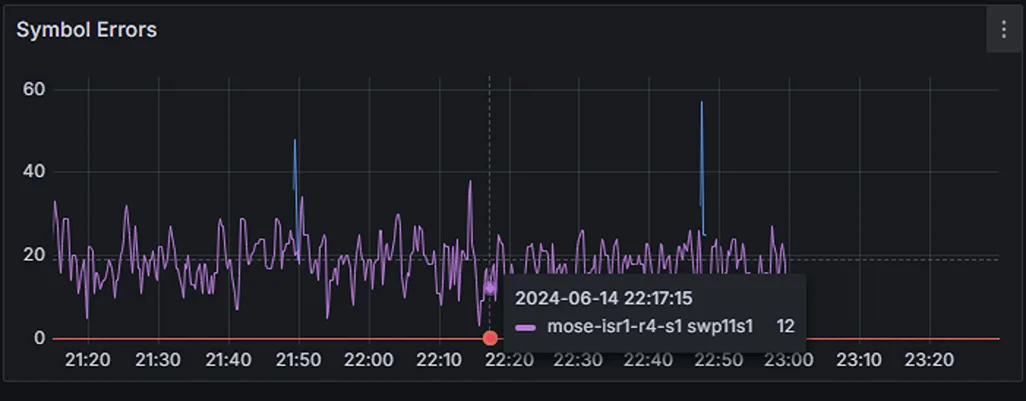
Switch Telemetry 在 Spine 交换机的特定端口(swp11s1)上精确定位了符号错误(图 4)。
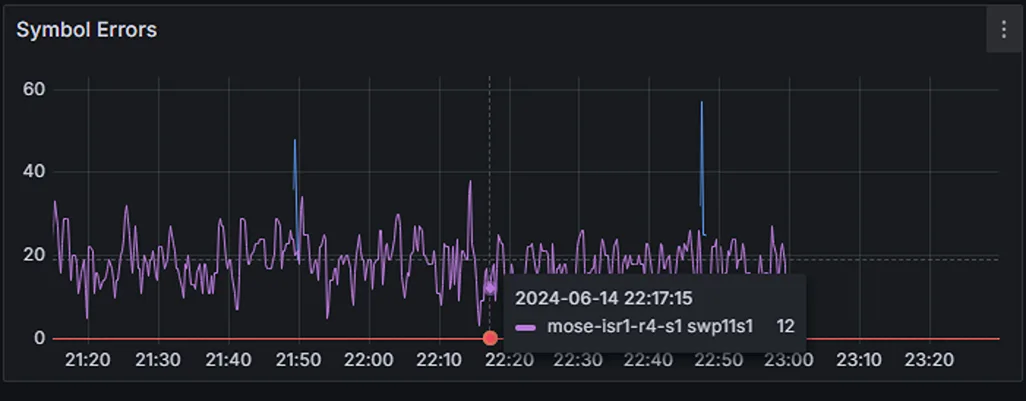
禁用故障端口后,带宽使用量恢复正常,确认了根本原因(图 5)。
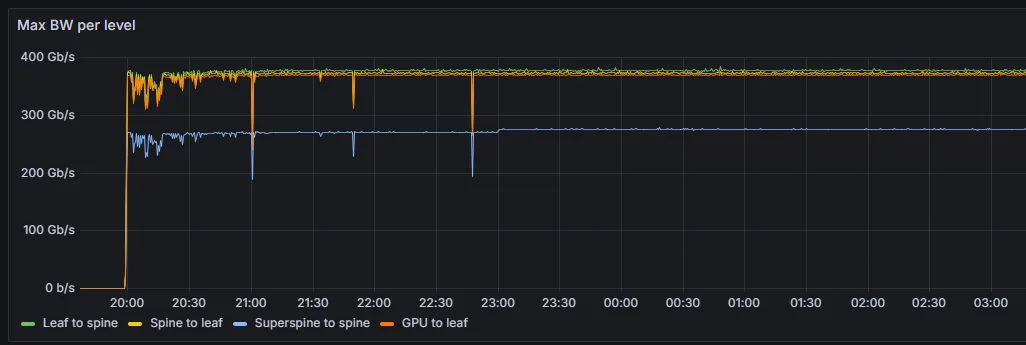
如示例所示,Spectrum-X 遥测解决方案从 AI 架构中的多个来源采集原始遥测数据,并将其转化为可操作的洞察。
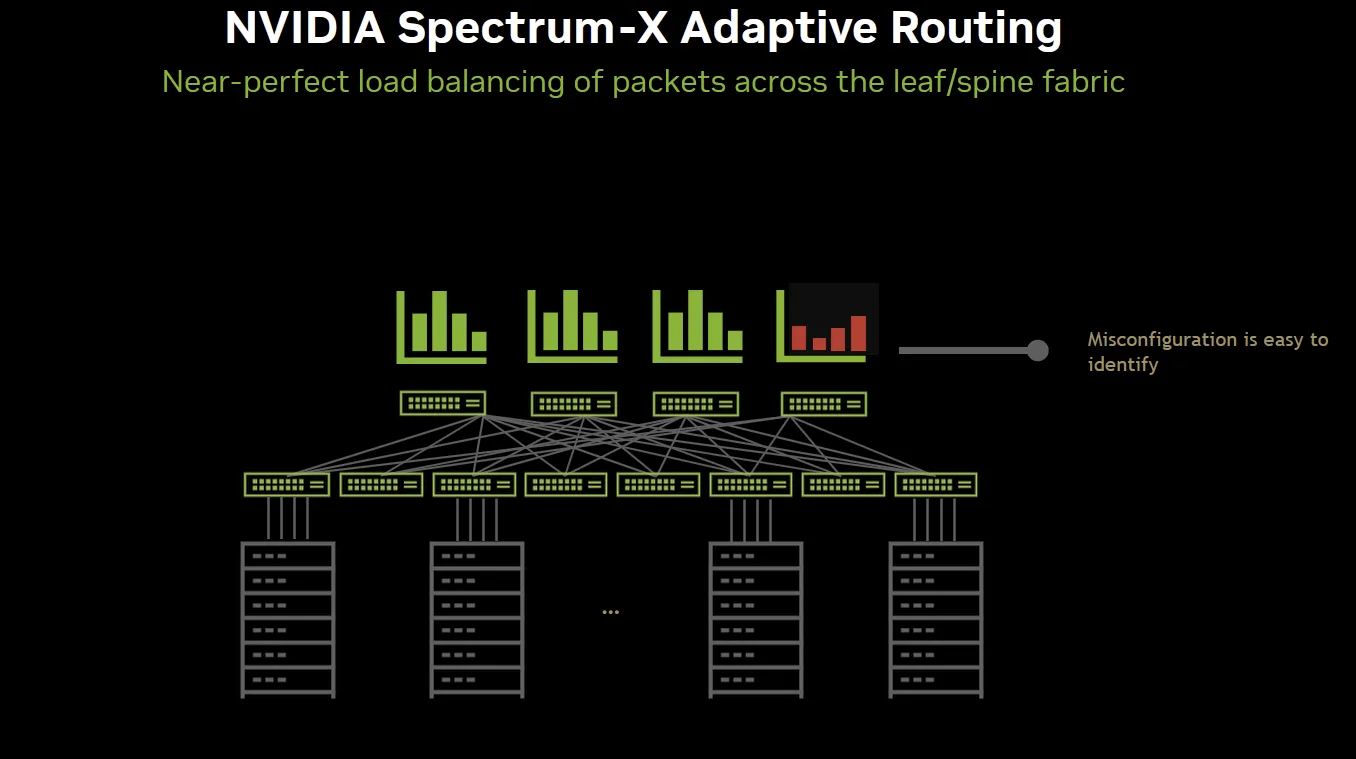
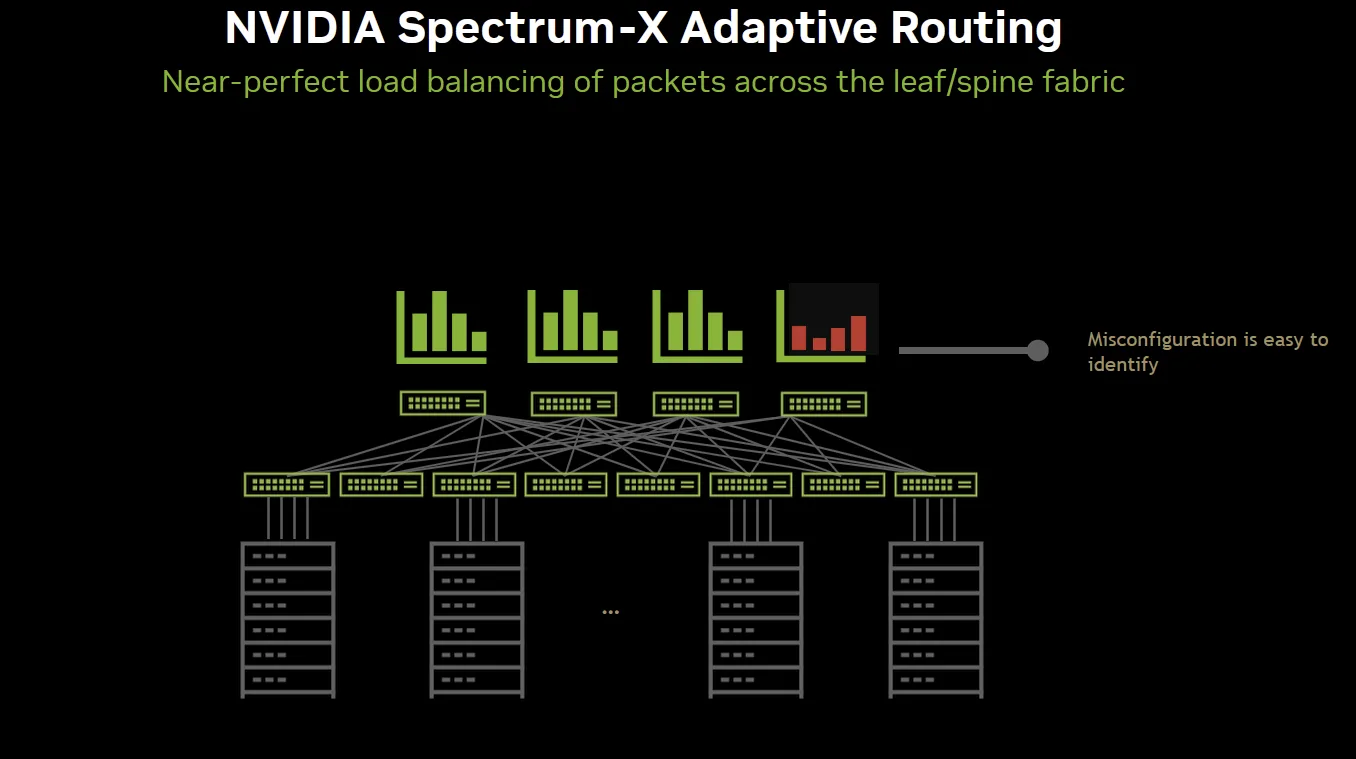
示例 2:检测网络中的配置错误
Spectrum-X 以太网遥测解决方案的另一个用例是,对网络流量的持续精细监控可能揭示网络中的错误配置。在运行良好的 Spectrum-X 以太网网络中,RoCE 流量在 Spine/Leaf 链路之间应实现均衡分布。借助 Spectrum-X 以太网的实时遥测技术,可通过 NetQ 以细致的方式观察到这一状态。而在此情况下,网络未呈现理想的均衡分布,因此可以推断,叶子交换机之间存在配置差异,因为这是导致流量不平衡的唯一原因。
开始使用 NVIDIA Spectrum-X 以太网
AI 工作负载需要极高的性能、更低的延迟和更高的可靠性。唯有涵盖应用程序、GPU、SuperNIC 和交换机结构的整体遥测方法,才能提供满足这些需求的实时洞察。
借助 Spectrum-X 以太网,NVIDIA 提供了一套集成化解决方案,确保 AI 基础设施高效、可预测且具备弹性。深入了解 NVIDIA Spectrum-X 以太网 网络平台。




