共同设计的硬件、软件和模型是提供更高 AI 工厂吞吐量和更低词元成本的关键。测量这一点远远超出了峰值芯片规格。严格的 AI 推理性能基准对于理解推动 AI 工厂收入增长的现实世界词元输出至关重要。
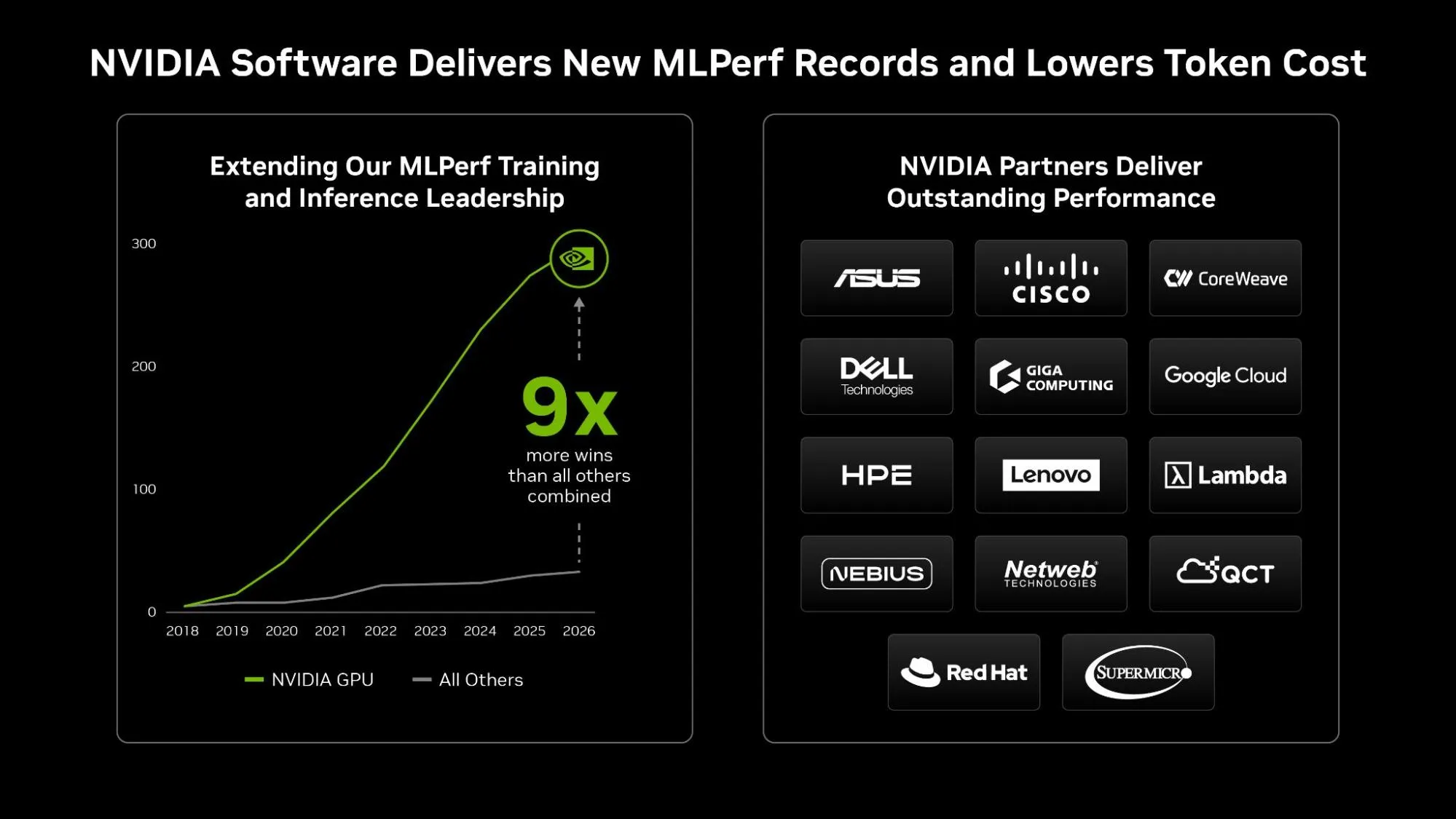
MLPerf Inference v6.0 是一系列行业基准测试中的最新版本,可用于衡量各种模型架构和用例的性能。在最新一轮测试中,由 NVIDIA Blackwell Ultra GPU 驱动的系统在各种模型和场景中提供了最高的吞吐量。因此,自 2018 年以来,NVIDIA MLPerf 训练和推理累计获胜次数达到了 290 次,是所有其他提交者加起来的 9 倍。
这一轮,NVIDIA 合作伙伴生态系统广泛参与,拥有 14 家合作伙伴,这是所有平台上提交的合作伙伴数量最多的一轮。华硕、思科、CoreWeave、Dell Technologies、GigaComputing、HPE、联想、Nebius、Netweb Technology、Supermicro、和 Lambda 在 NVIDIA 平台上提供了出色的性能。
本文详细介绍了最新的基准测试更新、在 NVIDIA 平台上实现的行业领先性能,以及助力实现这一目标的全栈工程。
新的基准测试,新的性能记录
MLPerf 推理基准测试套件会定期更新,以确保其反映对社区至关重要的模型、模式、用例和部署场景。只有 NVIDIA 平台在本轮提交了所有新增模型和场景的结果,并且在所有这些模型和场景中都提供了最高的性能。
这一轮 MLPerf 推理增加了几项新测试,包括:
- DeepSeek-R1 Interactive: 继在 MLPerf Inference v5.1 中添加基于稀疏混合专家 (MoE) 架构的 DeepSeek-R1 推理 LLM 之后,MLCommons 添加了一个新的交互式场景,与服务器场景相比,最小词元速率提高了 5 倍,首次词元的时间缩短了 1.3 倍,这代表了更高的交互性部署
- Qwen3-VL-235B-A22B: 总共具有 235B 个参数的视觉语言模型。这代表了 MLPerf 推理套件中的第一个多模态模型。测试了两个场景:离线和服务器。
- GPT-OSS-120B: 由 OpenAI 开发的 120B 参数 MoE 推理 LLM。此基准测试包括三种场景:离线、服务器和交互式
- WAN-2.2-T2V-A14B: 4B 参数文本转视频生成式 AI 模型。测试了两个场景:单流,用于测量处理单个视频生成请求的延迟;离线,用于测量批量处理场景中每秒处理的样本数量。
- DLRMv3 – 替代 DLRM-DCNv2 测试的生成式推荐基准测试。与之前的基准测试相比,它使用基于 Transformer 的架构来增加模型大小和计算强度。它测试离线和服务器场景。
| 基准测试 | DeepSeek-R1 | GPT-OSS-120B | Qwen3-VL | Wan 2.2 | DLRMv3 |
| 离线 | 2494,310 词元/ 秒* | 1046,150 词元/ 秒 | 79 个样本/ 秒 | 0.059 个样本/ 秒 | 104637 个样本/ 秒 |
| 服务器 | 1555,110 词元/ 秒* | 1096,770 词元/ 秒 | 68 条查询/ 秒 | 21 秒** (单流) | 99997 条查询/ 秒 |
| 交互式 | 250634 词元/ 秒 | 677199 词元/ 秒 | *** | *** | *** |
*MLPerf Inference v6.0 中并非新场景
** Wan 2.2 采用单流场景,用于测量端到端请求延迟,而非服务器场景。越小越好。
*** 未在 MLPerf Inference v6.0 中进行测试
MLPerf Inference v6.0,封闭分区。结果于 2026 年 4 月 1 日从 www.mlcommons.org 检索到。NVIDIA 平台结果来自以下条目:6.0-0039、6.0-0073、6.0-0075、6.0-0076、6.0-0078、6.0-0081、6.0-0094。MLPerf 名称和徽标均为 MLCommons 协会在美国和其他国家 地区的注册商标和非注册商标。保留所有权利。严禁未经授权使用。详情请参见 www.mlcommons.org。
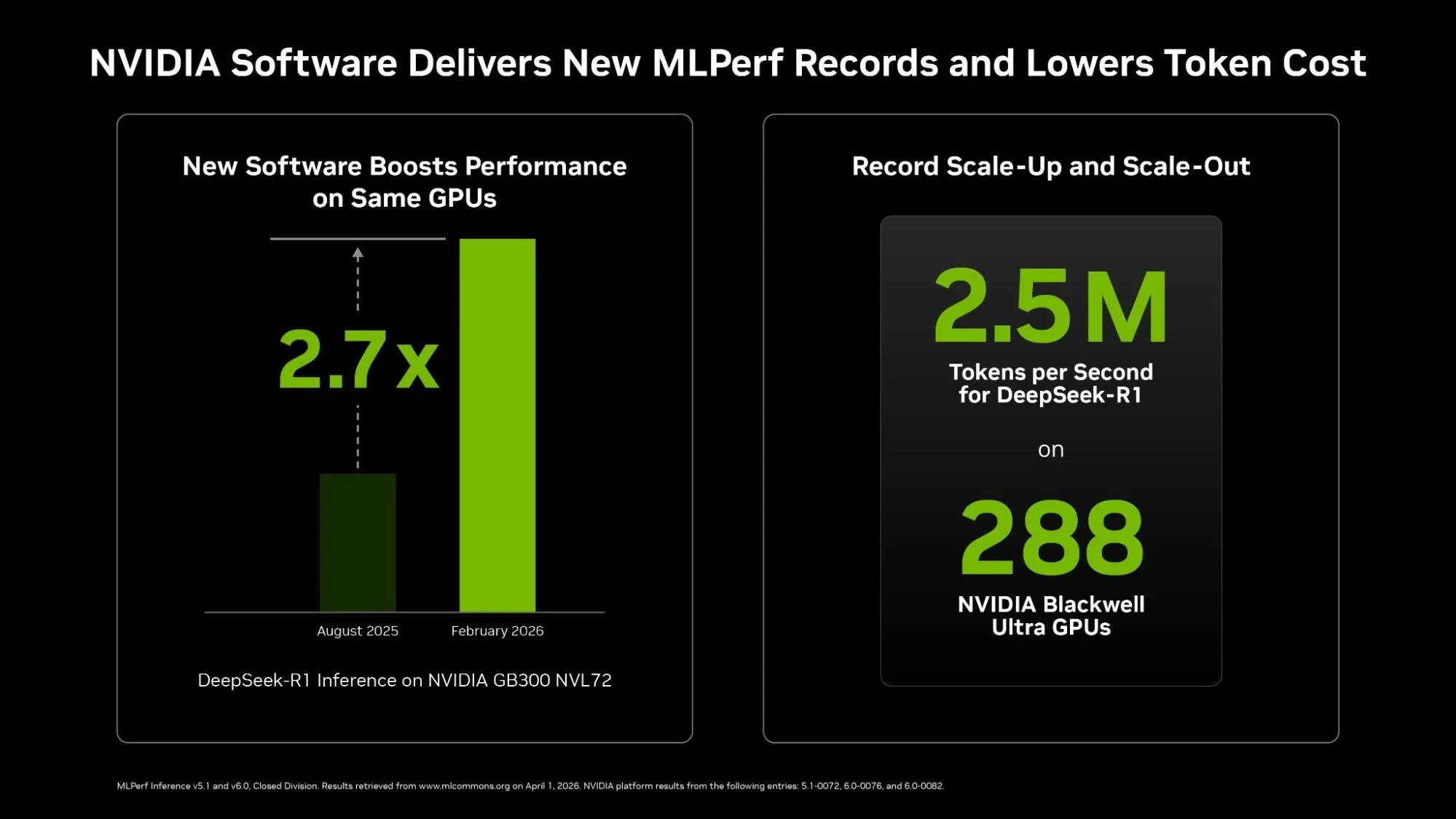
NVIDIA TensorRT-LLM 软件更新可在相同的 Blackwell Ultra GPU 上实现高达 2.7 倍的性能提升
NVIDIA 不断优化其软件堆栈的性能,以提高现有平台提供的词元吞吐量。这降低了词元的生产成本,并使 AI 工厂运营商能够为更多用户提供服务,从而在给定的基础设施占用空间内创造更多收入。
额外的性能还为运行未来的 AI 模型以及在要求严苛的场景 (例如更高的词元速率和更长的环境) 中服务现有模型提供了空间。这种持续改进使多年前推出的 NVIDIA GPU 能够在云端以高利用率保持工作效率。
在本轮测试中,NVIDIA 于去年推出了 GB300 NVL72,与六个月前首次提交的 DeepSeek-R1 基准服务器场景测试相比,词元吞吐量提高了 2.7 倍1。这意味着在相同的基于 GB300 NVL72 的基础设施和功耗占用下,词元的数量增加了 2.7 倍,将每个词元的制造成本降低了 60% 以上。NVIDIA 合作伙伴 Nebius 实现的这一加速展示了 NVIDIA 平台的核心优势:一个开放、广阔的生态系统,客户和合作伙伴可以在我们的软件堆栈上进行独特的优化和创新。
1MLPerf Inference v5.1 和 v6.0,封闭分区。结果于 2026 年 4 月 1 日从 www.mlcommons.org 检索到。NVIDIA 平台结果来自以下条目:5.1-0072、6.0-0081。MLPerf 名称和徽标均为 MLCommons 协会在美国和其他国家 地区的注册商标和非注册商标。保留所有权利。严禁未经授权使用。详情请参见 www.mlcommons.org。
以下几项软件增强功能为 DeepSeek R1 在服务器和离线场景中的性能提升提供了助力:
- 更快的内核 –这包括高性能内核的组合,以及内核融合后使用更少的内核。
- 优化注意力数据并行—更好地平衡不同秩之间的上下文请求,从而显著提升端到端性能。
利用开源 NVIDIA TensorRT-LLM 推理服务软件和 NVIDIA Dynamo 开源分布式推理服务框架的最新功能,为新增的、更具挑战性的 DeepSeek-R1 Interactive 场景提供支持。其中包括:
- 分解服务: 此功能在 Dynamo 中分别对每个推理阶段 (预填充和解码) 的配置进行分离和单独优化,从而实现最佳的整体吞吐量。
- Wide Expert Parallel (WideEP) :对于交互性较高的场景,MoE 模型的执行时间受专家权重加载时间的限制。通过在 NVL72 节点上跨多个 GPU 对专家进行分割或分片,可以减少这一瓶颈,从而提高端到端性能。
- Multi-词元 Prediction (MTP) :在交互性较高的级别,批量大小较小,且性能主要取决于权重加载到内存中的速度,导致计算性能未得到充分利用。通过应用无法用于并行预测和验证其他词元的计算 (在此实现中最多应用 3 个) ,可提高高交互性下的吞吐量。
- KV 感知路由:Dynamo 的这种功能通过评估不同工作者的计算成本来路由推理请求。
在 MLPerf 推理基准测试于去年首次推出时,NVIDIA 是第一个也是唯一一个在 MLPerf 推理上提交 DeepSeek-R1 结果的平台。在本轮测试中,NVIDIA 不仅提升了 DeepSeek-R1 返回场景的性能,而且再次成为唯一一个提交新添加交互场景的平台。
甚至在近两年前推出的超大型密集 LLM Llama 3.1 405B 上,GB300 NVL72 在服务器场景中的性能也提高了 1.5 倍。
| 基准测试 | GB300 NVL72v5.1 | GB300 NVL72v6.0 | 加速 |
| DeepSeek-R1 (服务器) | 2907 词元/ 秒/gpu | 8064 词元/ 秒/gpu | 2.77 倍 |
| DeepSeek-R1 (离线) | 5842 词元/ 秒/gpu | 9821 词元/ 秒/gpu | 1.68 倍 |
| Llama 3.1 405B (服务器) | 170 词元/ 秒/gpu | 249 词元/ 秒/gpu | 1.52 倍 |
| Llama 3.1 405B (离线) | 224 词元/ 秒/gpu | 271 词元/ 秒/gpu | 1.21 倍 |
MLPerf Inference v5.1 和 v6.0,封闭分区。结果于 2026 年 4 月 1 日从 www.mlcommons.org 检索到。NVIDIA 平台结果来自以下条目:5.1-0072、6.0-0017、6.0-0078、6.0-0082。每个芯片的性能是通过总吞吐量除以报告的芯片数量得出的。每芯片性能并不是 MLPerf Inference v5.1 或 v6.0 的主要指标。MLPerf 名称和徽标均为 MLCommons 协会在美国和其他国家 地区的注册商标和非注册商标。保留所有权利。严禁未经授权使用。详情请参见 www.mlcommons.org。
此外,NVIDIA 针对新增的多模态、视频生成和推荐基准测试提交的作品均由针对 NVIDIA 平台优化的开源软件框架提供支持。Qwen3-VL 视觉语言提交作品使用了 vLLM 开源框架,展示了社区如何快速构建高级多模态优化,以加速 NVIDIA Blackwell Ultra 等最新 GPU 上的图像密集型推理工作负载。WAN-2.2 文本转视频提交使用了 TensorRT-LLM VisualGen,可加速 NVIDIA GPU 上基于扩散的视频生成工作流。
对于 DLRMv3,该提交基于两个开源项目构建:用于基于 Transformer 的高性能推荐推理的 NVIDIA recsys-example 和用于 GPU 加速嵌入表查找的 NV Embedding Cache。在这一要求更严苛的生成式推荐基准测试中,这两者对于实现创纪录的吞吐量至关重要。
通过广泛而持续的工程设计,NVIDIA 正在不断提高现有模型上现有硬件的性能,这些结果证明了这一点。同时,NVIDIA 与模型构建者和开源推理框架密切合作,确保最新模型在发布当天就能在 NVIDIA 平台上运行。
借助 NVIDIA Quantum-X800 InfiniBand 平台进行横向扩展推理,每秒可实现数百万个词元
NVIDIA 还使用与 NVIDIA Quantum-X800 InfiniBand 横向扩展网络互联的四个 GB300 NVL72 系统提交结果,在 DeepSeek-R1 模型的离线和服务器场景中大规模创造了新的吞吐量记录。
| DeepSeek-R1 | 4 块 GB300 NVL72 | 词元/ 秒 |
| 离线 | 2494310 |
| 服务器 | 1555110 |
MLPerf Inference v6.0,封闭分区。结果于 2026 年 4 月 1 日从 www.mlcommons.org 检索到。NVIDIA 平台结果来自以下条目:6.0-0076。MLPerf 名称和徽标均为 MLCommons 协会在美国和其他国家 地区的注册商标和非注册商标。保留所有权利。严禁未经授权使用。详情请参见 www.mlcommons.org。
凭借 288 块 Blackwell Ultra GPU (在 MLPerf 推理中提交给所有基准测试的最大规模) ,提交的结果创造了新的系统级吞吐量记录,每秒可处理数百万词元。
展望 MLPerf 端点
提供的推理吞吐量需要在许多芯片、系统架构、数据中心设计和软件中进行极端的协同设计。最新的 MLPerf Inference v6.0 结果显示,在行业标准基准测试中,NVIDIA 可为各种工作负载 (从大规模 LLM 到高级视觉语言模型,再到生成式推荐系统等) 提供出色的推理吞吐量。
随着模型规模的增长和上下文长度的增加,AI 推理工作负载也在继续快速发展。随着代理式 AI 的日益普及,需要超高速词元速率的高级用例也层出不穷。
作为 MLCommons 联盟的成员,NVIDIA 一直致力于引领 MLPerf Endpoints 基准测试的定义。MLPerf Endpoints 将为社区提供一个严谨、可审计的图景,让社区了解所部署的服务在真实 API 流量下的表现,捕捉仅靠芯片级基准无法揭示的关键性能指标,同时提供定义 MLPerf 基准的严谨性和结果完整性。
如需了解 NVIDIA 平台在训练、推理和高性能计算方面的最新性能,请参阅我们的深度学习产品性能页面。
致谢
NVIDIA MLPerf Inference v6.0 的结果反映了公司内许多才华横溢的工程师的工作成果。我们感谢以下人士 (按姓氏排序) 做出的贡献:
Tomar Bar-on、Nitin Sai Bommi、Viraat Chandra、Alice Cheng、Jerry Chen、Xiaoming Chen、Jesus Corbal San Adrian、Ashutosh Dhar、Kefeng Duan、Wookje Han、Kyle Huang、Kris Hung、Rashid Kaleem、Khubaib Khubaib、Zihao Kong、Tin-Yin Lai、Tao Li、Forrest Lin、Wanqian Li、Alex Liu、Jintao Peng、Yuxian Qiu、Junyi Qiu、Xiaowei Shi、Olivia Stoner、Jacob Subag、Tong Tong、Harshil Vagadia、Shobhit Verma、June