
AI 在不断发展,推理模型对 token 的需求不断增加,对 AI 基础设施的每一层都提出了新的要求。计算比以往任何时候都更需要高效扩展,以更大限度地提高 token 的生产效率,并提高模型创作者和用户的工作效率。
现代 GPU 以峰值容量运行,每一代都会推动更高的吞吐量,但系统性能越来越多地受到代理式循环中 CPU 受限的串行任务的控制,这是核心计算机科学原理的经典示例,称为阿姆达尔定律。
这种动态在两类工作负载中尤为明显:强化学习 (RL) ,用于训练具有编码或工程等新专业技能的模型,以及代理式动作,使 AI 智能体能够使用网络浏览器、数据库、代码解释器和其他软件等工具来完成现实环境或沙盒中的任务。
这两种工作负载结合了两种历史上独立的 CPU 特性。单个环境需要强大的单线程性能来快速执行复杂的代码,这与工作站类似。与此同时,现代 AI 系统会同时启动数千个此类环境,从而产生典型的服务器基础设施大规模吞吐量需求。
NVIDIA Vera CPU 专为现代 AI 工作负载而设计,其主要设计特性包括:
- 卓越的单核性能:快速执行单个任务至关重要,并且必须在大量并发用户和代理式任务的恒定负载下维持性能。
- 每个核心的高显存和网络带宽:确保在负载下一致的 SLA,从而高效移动数据量,以执行实时分析和上下文切换任务。
- 高效的机架级协同设计: AI 工厂必须快速部署和管理容量,以满足智能体需求,同时更大限度地提高能效。
无论 Vera CPU 是直接连接到加速器,还是在线缆端的独立 CPU 上执行任务,使用 Vera 构建的数据中心都能更大限度地提高 AI 基础设施投资的效率。
后训练现实
强化学习需要模型不断评估其输出,识别成功或失败的结果。例如,学习进行软件开发的模型使用在加速器上运行的模型生成大量代码,然后将这些代码传送到 CPU 集群进行构建、运行和测试,并以反馈 – 奖励循环的形式发挥作用 (参见图 1) 。
这些任务涵盖代码库研究、编译、运行时执行、脚本编写、数据转换和其他常见操作。总体而言,此流程需要许多类似于沙盒的并发环境,每个环境都配备全套工具。通常,单个 CPU 核心从一组加速器生成的请求中端到端执行每个轻度线程的案例。

为了更大限度地提高加速器利用率并执行快速模型迭代,该周期的 token 生成和训练阶段的时间表 (或策略) 十分紧张。通常,在 CPU 上运行的一些评估作业完成作业时为时已晚,无法影响周期中的下一步。当这种情况发生时,模型需要更长的时间才能学习到相同的质量,而宝贵的 tokens 会被浪费。
代理循环需要以独特的方式融合高单核性能、海量数据带宽和确定性执行,同时尽可能降低所采用 CPU 的尾部延迟。
这些要求是 NVIDIA Vera CPU 设计的重点 (图 2) ,与竞争平台相比,其沙盒性能最高可提升 50%,显存带宽为 1.2 TB/s,并且 88 个 Olympus 核心采用 NVIDIA 空间多线程 (SMT) 技术,可实现 AI 工厂所需的任务并发。
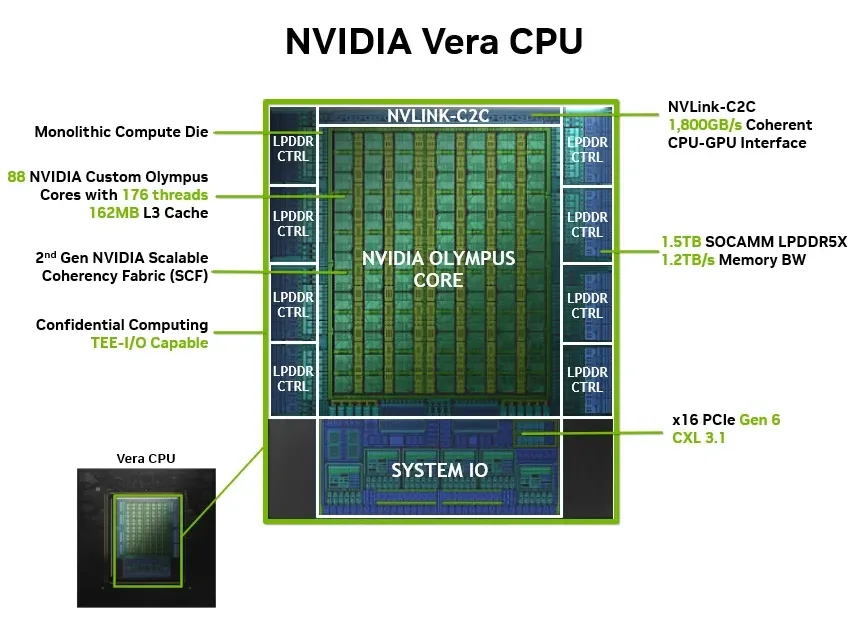
NVIDIA Olympus 核心
为了满足对支持 AI 的高性能核心的需求,NVIDIA 推出了首款完全定制的数据中心 CPU 核心 — — NVIDIA Olympus Core。在 Vera 平台上,Olympus 与第二代 NVIDIA 可扩展一致性结构 (SCF) 首次亮相,后者最初是为 NVIDIA Grace CPU 开发的。
为在具有控制流逻辑的内存密集型工作负载上实现持续的高每周期指令 (IPC) 操作而构建,Olympus 使用 10 宽指令获取和解码前端,以及能够评估每个周期两个已采取分支的神经分支预测器。它与 Arm v9.2 指令集和现有软件完全兼容,可在基于 Arm 的容器、二进制文件、库和操作系统上实现高性能。
借助 NVIDIA SMT,用户可以在每个线程的性能和运行时的线程数之间进行选择。这样,每个线程都能在重负载下获得稳定的性能、更强的隔离能力和可预测的尾端延迟。传统 SMT 依赖于时间共享资源和线程之间频繁的上下文切换,从而引入性能差异。
NVIDIA 可扩展一致性结构和内存子系统
Vera CPU 建立在单个整体式计算芯片和结构上,相邻的芯片实施内存和 I/ O 子系统,同时保持计算拓扑的一致性。
从应用程序的角度来看,每个核心与其他核心、缓存、内存和网络等资源的实际距离相同,并且提供统一的高吞吐量带宽。大多数延迟+ 敏感操作仍是本地操作,从而避免了通常在传统 CPU 上观察到的不必要的交叉裸片流量。
在 AI 工厂中,智能体任务、分析操作、KV 和 Blob 缓存、编排和控制平面的运行时路径本质上是不可预测的。在传统实现中,必须提前考虑处理器的拓扑结构和在其上运行的相邻任务的使用模式,以更大限度地提高应用程序性能。该设计可实现最佳性能,而无需进行这种调优。
第二代 SCF 将所有 88 个 Olympus 核心连接到一个共享的三级缓存和内存子系统,提供一致的延迟和 3.4 TB/s 的对分带宽,使 Vera CPU 能够在负载下维持超过 90% 的峰值内存带宽。每个核心的显存带宽高达 14 GB/s,约为传统数据中心 CPU 每核心速率的 3 倍,可确保提取 – 转换 – 加载 (ETL) 、实时分析和受内存限制的工作负载在每个核心处于活动状态时保持吞吐量。
Vera 的第二代 LPDDR5X 内存子系统“馈送 SCF”可提供高达 1.2 TB/s 的总带宽,而其内存功率不到传统 DDR 配置的一半,容量高达 1.5 TB,是上一代产品的 3 倍。Small Outline Compression-Attached Memory Modules (SOCAMM) 首次将低功耗内存引入数据中心,将焊接内存替换为可插拔、可升级的模块,将 LPDDR 效率与服务器级可维护性相结合。
整个 AI 工厂的性能
所有这些架构元素使 Vera CPU 能够在全插槽负载下,在编译器、脚本工具、运行时引擎、压缩和代理式工具调用方面,提供高达 1.5 倍的代理式沙盒性能 (图 3) ,而不是竞争激烈的 x86 平台。
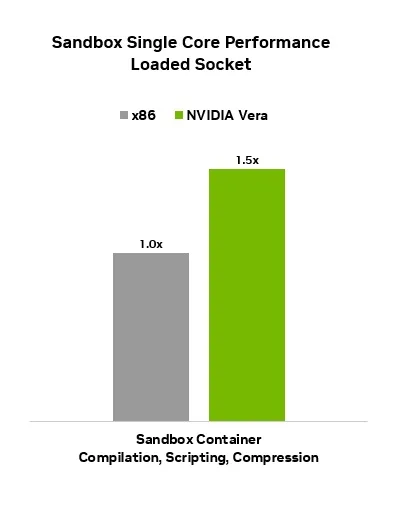
这一优势体现在三个维度上。在 RL 后训练中,速度提高 1.5 倍的沙盒会在更短的时间窗口内返回评估结果,使模型能够捕获最佳梯度 tokens,并加速训练周期。
在代理式推理中,它减少了用户的等待时间,提高了加速器利用率,减轻了 KV 缓存卸载的压力。
对于前沿训练问题,单核性能提高 50%,这意味着在达到时间限制之前完成更多的顺序测试,从而扩大模型可以学习的难题范围。
机架式代理环境
每个 AI 工厂都需要数百万个 CPU 核心来实现 RL 和工具使用的代理式循环。要释放 AI 基础设施的潜力,必须快速部署。对于许多 AI 工厂运营商而言,Vera CPU 将成为其车队中的第一款,并将登陆专为高机架功率和液冷设计的数据中心。
新的 NVIDIA Vera CPU 机架在与目前部署的 NVL72 产品相同的规划限制、机架基础设施、冷却和功率下提供了惊人的密度和性能。
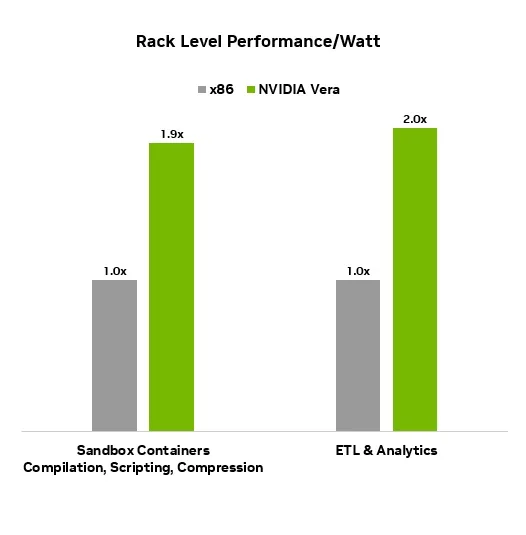
Vera CPU 机架的容量超过 22.5 K,与基于 x86 的服务器机架相比,可提供超过 4 倍的容量和每瓦 2 倍的性能 (图 4) 。AI 工厂在机架层面部署和管理容量,大幅缩短了建设时间,并缩短了新容量的上市时间,同时简化了场地规划。
每个 Vera CPU 都与 NVIDIA BlueField-4 智能网卡连接,这些智能网卡包含基于 Grace 的专用管理核心,可分流安全和管理等网络任务,并确保系统中的高性能容量可完全用于代理式任务。
Vera 平台和配置
除了 Vera CPU 机架之外,NVIDIA 还为现代 AI 工厂的各种工作负载设计了一整套基于 Vera 的平台。通过提供多种密度、散热能力、配置和外形规格选择,Vera 的设计和系统合作伙伴正在实现快速部署和容量构建,以适应任何数据中心设施可用空间的限制。
| 平台 | 说明 | 场景 |
| NVIDIA Vera Rubin NVL72 | 集成式 AI 工厂机架通过高带宽 NVIDIA NVLink-C2C 和 NVIDIA NVLink 纵向扩展网络将 Vera 主机 CPU 和 Rubin GPU 紧密合。 | 大规模 AI 工厂、前沿模型训练、推理和高吞吐量推理。 |
| NVIDIA Vera CPU 机架 | 液冷 (LC) CPU 机架架构,每个 1U 托盘最多 4 个节点,每个机架可扩展至 256 个 Vera CPU,从而实现密集、高效的计算。与 NVL72 一起快速构建机架级容量。 | AI 工厂基础设施、代理式流程、编排层、数据处理、HPC 和 CPU 密集型服务。 |
| 单插槽和双插槽 Vera 平台 | 灵活的服务器平台基于一到两个 Vera CPU 构建,每个插槽可支持高达 1.5 TB 的 LPDDR5X,CPU 之间支持 1.8 TB/s 的 NVLink-C2C 连接,采用双插槽设计,适用于任何设施。 | 云基础设施、企业、分析、存储、HPC、配备 NVIDIA PCIe GPU 的服务器和 AI 工厂。 |
| NVIDIA HGX Rubin NVL8 | 通过 PCIe 将 Vera 主机 CPU 与 Rubin GPU 搭配使用的加速计算平台,可在多种服务器设计中实现 CPU-GPU 性能的平衡。 | AI 推理、技术计算、分析和企业 HPC 部署。 |

平台可用性
Vera 系统将于 2026 年下半年通过思科、戴尔、HPE、联想和 Supermicro 等主要 OEM 提供 。有关更多详情,请参阅 Vera CPU 网页。
详细了解 Vera CPU 和 Vera Rubin。
NVIDIA Vera 在各种工作负载 (包括代码编译、解释器、脚本编写、运行时引擎、ETL、数据分析和图形) 中与 AMD EPYC Turin 和英特尔至强 6 GRANITE RAPIDS 的性能比较。




