
在 AI 时代,电力是终极限制,每个 AI 工厂 都在硬极限内运行。这使得每瓦性能 (将功率转换为创收智能的速率) 成为现代 AI 基础设施的决定性指标。
AI 数据中心现在以与能源生态系统直接相关联的词元工厂的形式运营,在这些工厂中,对土地、电力和外壳的使用决定了部署,效率决定了输出。在固定功率范围内增加收入完全取决于如何在 每瓦特的智能性能 中最大限度地提高 AI 基础设施和 五层 AI 蛋糕 生态系统。
本文将介绍 NVIDIA 架构、系统和 AI 工厂软件如何更大限度地提高堆栈每一层的每瓦性能,以及这些效率提升如何转化为更高的词元吞吐量和每兆瓦收入。
提升 NVIDIA GPU 架构的每瓦性能
NVIDIA 架构和平台旨在提高每代产品每瓦特产生的智能数量。在六代架构中,NVIDIA 将每兆瓦的推理吞吐量提高了 1000,000 倍 (图 1) 。
从长远来看,如果汽车的平均燃油效率在类似的时间内与芯片一样迅速提高,那么一加仑的汽油就足以让您踏上月球和返回月球。
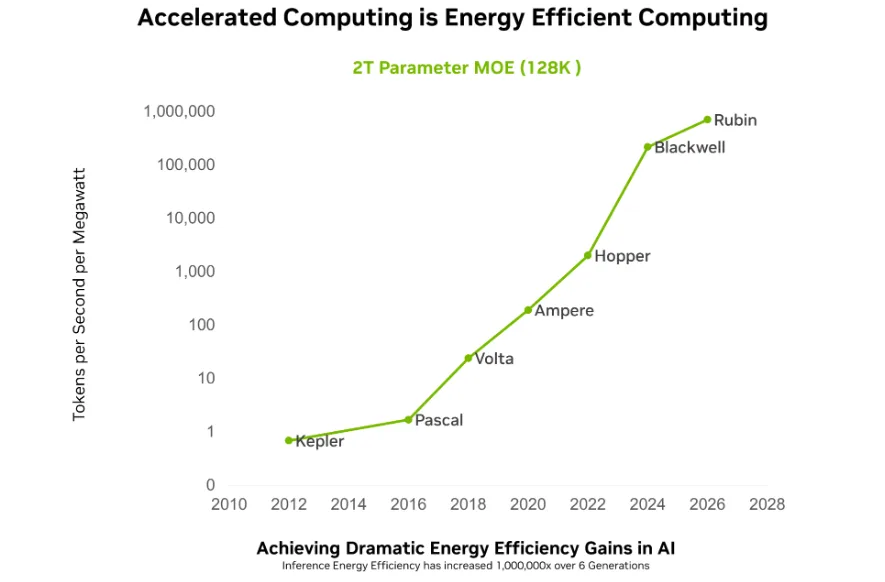
NVIDIA Hopper 与上一代产品相比,引入了许多架构创新,显著提高了能效。这些提升的关键在于 Hopper Transformer 引擎,它将第四代 Tensor Core 技术与 FP8 加速和软件相结合,可显著提高性能功耗比。
NVIDIA Blackwell 改进了高带宽内存 (HBM) 、NVIDIA NVLink 交换机和网络 (适用于 NVIDIA HGX 架构和 NVL72 机架级设计) 以及支持 NVFP4 的 Tensor Core,从而进一步奠定了这一基础,提高了每瓦吞吐量。近期的 SemiAnalysis InferenceX 数据显示,与使用 DeepSeek-R1 的 Hopper 相比,NVIDIA 软件优化和 NVIDIA Blackwell Ultra GB300 NVL72 系统可将每兆瓦的吞吐量提高 50 倍,并将词元成本降低 35 倍。
NVIDIA Vera Rubin 平台进一步提高了效率。Rubin GPU、Vera CPU、NVLink 6 和全机架散热系统共同设计为单个 AI 工厂平台。值得注意的是,与传统 CPU 相比,NVIDIA Vera CPU 的效率提高了 2 倍,性能提高了 50%。对于 Kimi K2 (32K/ 8K) 而言,这种端到端方法可将 AI 工厂的每兆瓦推理吞吐量提高 10 倍,并将词元成本降低约 10 倍。Vera Rubin 与 NVIDIA Groq 3 LPX 搭配使用,可将每兆瓦的吞吐量提高 35 倍,将万亿参数、高上下文工作负载的收入提高 10 倍,从而打造出超低延迟、高吞吐量推理的全新高级级别。
这些效率提升在 AI 工作负载中很明显,也反映在更广泛的计算性能衡量标准中。HPC 和超级计算社区使用 Green500 基准测试 来衡量高精度 (FP64) 效率,而 NVIDIA 超级计算系统在排行榜上名列前茅,在由 NVIDIA 技术加速的十大系统中,有九个系统。
通过极致协同设计提高效率
要在架构代际之间实现这些巨大的效率提升,需要为堆栈的每一层设计效率。
NVIDIA 将此视为一个极端的协同设计问题,即从芯片设计和制造到液冷等系统级创新,再到 AI 工厂编排进行优化。每一层都是下一层的复合体:高效的设计可减少能源浪费,将冷却能力转移到计算上,软件可确保每瓦产生有用的工作。
从源头提高工程效率
在芯片到达 AI 工厂之前,效率就已开始提高。NVIDIA 正在优化制造流程本身,以更快地提供更节能的芯片。
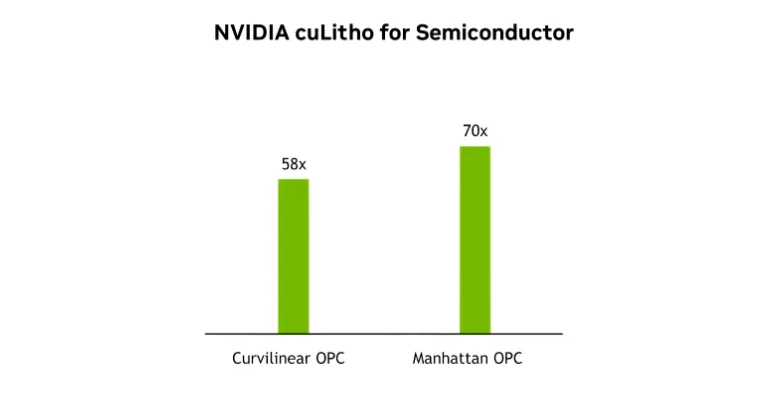
例如,用于加速计算光刻的 NVIDIA cuLitho 库在 GPU 上实现计算光刻的核心基元。它将掩码合成速度提高了 70 倍,并允许数百个 NVIDIA DGX™ 级系统取代数万台 CPU 服务器。在实践中,这意味着将光掩模周期从两周以上转变为通宵运行,只需消耗约九分之一的功率和八分之一的物理足迹,同时支持逆向光刻和曲线掩模等先进技术。
在材质层,NVIDIA cuEST 是一个 CUDA-X 库,旨在加速 NVIDIA GPU 上的第一性原理量子化学应用。它将基于量子化学的电子结构计算转变为生产工具。通过在密度泛函理论和相关工作负载方面提供高达 55 倍的速度提升,cuEST 使设备和工艺工程师能够探索工业规模的新的、更低泄漏的材料堆栈,而不是几个精心挑选的候选材料。其结果是管道中的材料和设备经过调优,可实现更低的泄漏和更好的开关行为,从而直接为晶体管级别提供更高的性能功耗比。
GPU+ 加速的电子设计自动化 (EDA) 流程放大了这种设计+ 时间加速。通过与其他 EDA 领导者合作,NVIDIA 正在将电子设计和自动化工作负载推向 GPU,使关键模块的迭代速度提升高达 15 倍。更快的迭代可提供更多机会来优化设计和验证流程、IR Drop、时钟和热热点。这反过来又产生了平面图和电网,减少了能源作为热量的浪费,并为主动计算提供了更多的输入功率。换言之,GPU+ 加速的 EDA 和制造工具可将每瓦性能转化为显式目标函数。
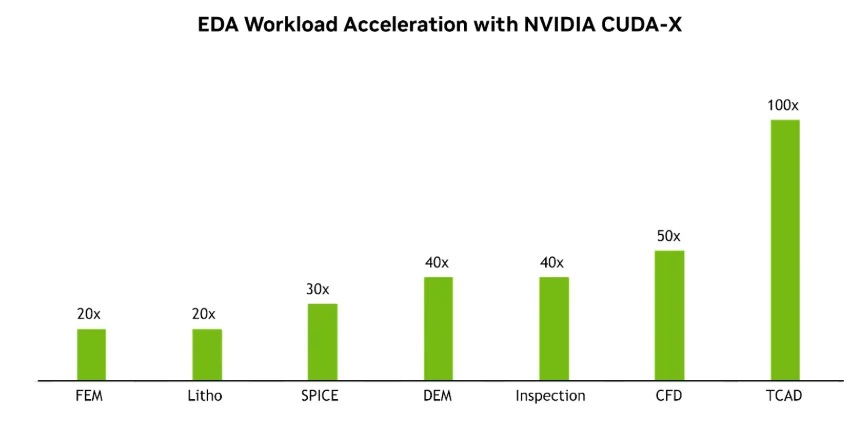
这些进步共同提高了设计和制造流程的效率,减少了交付新一代芯片所需的时间、能源和基础设施。
散热性能每瓦提升数
提高每瓦性能不仅限于芯片。系统冷却方式也会影响计算的可用功率。
NVIDIA Blackwell 系统可减少冷却用度,PUE 约为 1.25,风冷能力约为 20%。与前几代产品相比,这将更多的能源用于计算,与传统的风冷架构相比,能效提高了 25 倍,水效提高了300 倍以上。
NVIDIA Vera Rubin 采用 100% 液冷技术,并紧裸片到水冷路径,进一步提高了能源效率,使 AI 工厂能够以 1.1 PUE 的速度运行,而不会使冷却能源或耗水量按比例增加。
将进水温度维持在 45 ° C 可保持硅的温度和可靠性,而改进的热传递可提供比 Blackwell 更高的每瓦性能。在许多气候条件下,45 ° C 的进水可在很大程度上通过环境空气进行冷却,从而显著缩短压缩机的运行时间,从而减少冷却器的运行时间,同时更多的功率预算从冷却转向生成词元。相比之下,低温冷却要求更依赖于基于压缩机的系统,将设施有限电网分配的更大比例用于冷却而不是计算。
将效率转化为词元
随着每瓦特词元的增加,在固定功率范围内可容纳更多计费 AI 工作,从而降低每词元成本并扩大利润。实现这些收益需要缩小电网供应与可用计算之间的差距。以吉瓦级计算,在达到计算能力之前,可能会损失多达 40% 的功率。冷却效率低下会造成电力损失,而传统的过度调配会浪费容量。此外,如果运行得过于接近散热或电气限制,可能会出现故障。
NVIDIA DSX 可以弥补这一差距。 Vera Rubin DSX AI Factory 参考设计和 Omniverse 数字孪生 blueprint 将 AI 工厂视为动态系统,持续监控和调整功率、冷却和工作负载行为。系统以 Max-Q (每瓦最高性能点) 运行,而非低效峰值。域电源服务、工作负载电源配置文件和任务控制可编排机架和集群,实现高效运营。对于一座 500 兆瓦的 AI 工厂,DSX Max-Q 可帮助生态系统合作伙伴运营 AI 工厂,在相同的功率范围内将 GPU 数量增加多达 30%,并提高每瓦吞吐量,而 DSX Flex 则可根据实时电网条件调整需求,以释放闲置容量。
行业领导者证明,采用代理式液冷和 Max-Q 操作的 AI 工厂每瓦可提供更多词元。未用于冷却或闲置容量的每一瓦特都会变成一瓦特,产生词元和收益。
从词元到每兆瓦收入
推理推动收入增长。词元是智能单位,每兆瓦吞吐量决定了 AI 工厂的潜在收益。随着功率上限和需求的爆炸式增长,运营商必须像跟踪收入和利润一样密切跟踪吞吐量和词元率。
随着模型的增长,上下文窗口会扩大,输出长度也会增加。正如 NVIDIA 首席执行官黄仁勋在 GTC 2026 大会主题演讲中所解释的,AI 产品将形成一个范围:免费层吸引用户,中层模型平衡规模和速度,而具有大规模上下文窗口和超高吞吐量的高级层会使每百万词元的高价格。更智能的模型需要更高的价格,使每一次向上移动都成为直接的收入杠杆。
Hopper、Blackwell 和 Vera Rubin 等 NVIDIA 平台将每瓦词元曲线推向上行,特别是在高值层时。Blackwell 将获利集中的地区的吞吐量提高了 35 倍。Vera Rubin 将高端级别提升了一个数量级。采用极致协同设计、NVL72-scale 系统和超低延迟互连技术,可在相同功率范围内,以更高密度实现更高的价值层。
对于运营商而言,指标很简单:每兆瓦的收入。1GW 的 AI 工厂可在免费、中端、高端和超高层级之间分配电力。吞吐量和价格的加权乘积成为收入引擎。在相同的功耗下,下一代硬件可以带来 5 倍或更多的收入。添加专用系统 (例如用于工程工作负载的超低延迟切片) 可以解锁额外的步骤更改。推理性能和效率的每一次提升都会增加经济效益。
在当今功率上限和 AI 需求激增的环境中,NVIDIA AI 基础设施中通过极端协同设计实现的效率和吞吐量提升只有在大规模捕获的情况下才能实现。 NVIDIA Omniverse DSX Blueprint 可确保 AI 工厂以峰值效率持续运行,将每瓦可用功率转化为有用的计算能力。
了解详情
功率是现代 AI 的终极制约因素:在固定电网容量的情况下,更大限度地提高每瓦性能 (即能源转化为收益+ 产生词元的速率) 是 AI 基础设施的决定性指标。NVIDIA 架构和平台旨在提高每代产品每瓦特产生的智能数量。在六代架构中,NVIDIA 将每兆瓦的推理吞吐量提高了 100 万倍。
如需了解更多信息,请参加 CERAWeek 2026,探索行业领导者如何在功率限制的情况下扩展智能、提高每瓦智能,以及推进节能芯片设计。




