
NVIDIA CUDA 13.1 版本新增了基于 Tile 的GPU 编程模式。它是自 CUDA 发明以来 GPU 编程最核心的更新之一。借助 GPU tile kernels,可以用比 SIMT 模型更高的层级来实现算法。至于如何将计算任务拆分到各个线程,完全由编译器和运行时在底层自动处理。不仅如此,tile kernels 还能够屏蔽 Tensor Core 等专用硬件的细节,写出的代码还能兼容未来的 GPU 架构。借助 NVIDIA cuTile Python,开发者可以直接用 Python 编写 tile kernels。
什么是 cuTile Python?
cuTile Python 是 CUDA Tile 编程模型在 Python 中的实现,基于 CUDA Tile IR 规范开发。它支持用 Python 编写 tile kernels,以 tile-based 模型来定义 GPU kernels——既可以作为 SIMT 模型的替代,也能作为 SIMT 模型的补充。
SIMT 编程要求明确指定每个 GPU 执行线程的任务。理论上,每个线程都能独立运行,执行和其他线程不同的代码路径。但实际应用中,要充分发挥 GPU 性能,通常会采用单线程对不同数据执行相同操作的算法设计思路。
SIMT 模型的优势是灵活性高、可定制性强,但要达到顶级性能,往往需要大量手动调优。而 tile model 能够帮助屏蔽部分硬件底层细节,而聚焦于更高层级的算法设计。至于 tile 算法如何拆分为线程、如何调度到 GPU 上执行,这些工作都由 NVIDIA CUDA 编译器和运行时自动完成。
cuTile 是专为 NVIDIA GPU 设计的并行 kernels 编程模型,核心规则有四条:
- 数组是最核心的数据结构;
- Tiles 是 kernels 操作的数组子集;
- Kernels 是由多个 Block 并行执行的函数;
- Block 是 GPU 计算资源的子集,tiles 的操作会在各个 block 之间并行开展。
cuTile 能自动处理块级并行、异步执行、内存迁移等 GPU 编程的底层细节。它可以充分利用 NVIDIA 硬件的高级特性,比如 Tensor Cores、共享内存、Tensor 内存加速器,而且不需要手动编写相关代码。更重要的是,cuTile 能跨不同 NVIDIA GPU 架构迁移,不用重写代码,就能使用最新的硬件功能。
cuTile 适合哪些人使用?
cuTile 面向的是需要编写通用数据并行 GPU kernels 的开发者。目前我们重点针对 AI/ML 应用中常见的计算类型优化 cuTile,后续还会持续迭代——新增功能和性能特性,让它能优化更多类型的工作负载。
你可能会疑惑:CUDA C++ 和 CUDA Python 一直很好用,为什么还要用 cuTile 写 kernels?关于这一点,我们在另一篇介绍 CUDA tile model 的文章里有详细说明。简单来说,现在 GPU 硬件架构越来越复杂,我们提供这样一层合理的抽象,就是为了能让开发者更专注于算法本身,不用再花大量精力把算法手动适配到特定硬件上。
用 tile 模式写代码,既能利用 Tensor Cores 的性能,又能保证代码兼容未来的 GPU 架构。就像 PTX 是 SIMT 模型的底层虚拟指令集架构(ISA),CUDA Tile IR 就是 tile-based 编程的虚拟指令集架构。它支持用更高层级表达算法,软件和硬件会在底层自动把这种表达映射到 Tensor Cores,助力实现峰值性能。
cuTile Python 代码示例
cuTile Python 代码长什么样?如果你学过 CUDA C++,一定接触过经典的向量加法 kernels。假设数据已经从主机端拷贝到设备端,CUDA SIMT 实现的向量加法 kernels 如下——它接收两个向量,逐元素相加后生成第三个向量,是最基础的 CUDA kernels 之一。
__global__ void vecAdd(float* A, float* B, float* C, int vectorLength)
{
/* calculate my thread index */
int workIndex = threadIdx.x + blockIdx.x*blockDim.x;
if(workIndex < vectorLength)
{
/* perform the vector addition */
C[workIndex] = A[workIndex] + B[workIndex];
}
}
在这个 kernel 里,每个线程的任务都要明确指定。而且你启动 kernel 时,还得手动选择要启动的 blocks 和线程数。
再看等效的 cuTile Python 实现:不用指定每个线程的操作,只需把数据拆成 tiles,定义好每个 tile 的数学运算就行,剩下的工作全由 cuTile 自动处理。
cuTile Python kernel 代码如下:
import cuda.tile as ct
@ct.kernel
def vector_add(a, b, c, tile_size: ct.Constant[int]):
# Get the 1D pid
pid = ct.bid(0)
# Load input tiles
a_tile = ct.load(a, index=(pid,) , shape=(tile_size, ) )
b_tile = ct.load(b, index=(pid,) , shape=(tile_size, ) )
# Perform elementwise addition
result = a_tile + b_tile
# Store result
ct.store(c, index=(pid, ), tile=result)
ct.bid(0) 是用于获取(本例中)第 0 维度块 ID 的函数,例如,它的作用相当于 SIMT kernels 开发者使用 blockIdx.x 与 threadIdx.x。ct.load() 函数则用于从设备内存中加载指定索引和形状的 tile 数据,数据加载到 tiles 后,即可用于计算,所有计算完成后,ct.store() 会将 tiled 数据写回 GPU 设备内存。
完整实现代码
接下来,我们将展示如何在 Python 中调用这个 vector_add kernels,并提供一份你可直接运行的完整 Python 脚本。以下是包含 kernels 定义与主函数的完整代码。
"""
Example demonstrating simple vector addition.
Shows how to perform elementwise operations on vectors.
"""
from math import ceil
import cupy as cp
import numpy as np
import cuda.tile as ct
@ct.kernel
def vector_add(a, b, c, tile_size: ct.Constant[int]):
# Get the 1D pid
pid = ct.bid(0)
# Load input tiles
a_tile = ct.load(a, index=(pid,) , shape=(tile_size, ) )
b_tile = ct.load(b, index=(pid,) , shape=(tile_size, ) )
# Perform elementwise addition
result = a_tile + b_tile
# Store result
ct.store(c, index=(pid, ), tile=result)
def test():
# Create input data
vector_size = 2**12
tile_size = 2**4
grid = (ceil(vector_size / tile_size),1,1)
a = cp.random.uniform(-1, 1, vector_size)
b = cp.random.uniform(-1, 1, vector_size)
c = cp.zeros_like(a)
# Launch kernel
ct.launch(cp.cuda.get_current_stream(),
grid, # 1D grid of processors
vector_add,
(a, b, c, tile_size))
# Copy to host only to compare
a_np = cp.asnumpy(a)
b_np = cp.asnumpy(b)
c_np = cp.asnumpy(c)
# Verify results
expected = a_np + b_np
np.testing.assert_array_almost_equal(c_np, expected)
print("✓ vector_add_example passed!")
if __name__ == "__main__":
test()
如果已经安装好 cuTile Python、CuPy 等必要软件,运行代码很简单,直接执行以下命令即可:
$ python3 VectorAdd_quickstart.py
✓ vector_add_example passed!
恭喜!你已经成功运行了第一个 cuTile Python 程序。
开发者工具支持
cuTile kernels 的性能分析可以用 NVIDIA Nsight Compute,操作方式和 SIMT kernels 完全一样。
$ ncu -o VecAddProfile --set detailed python3 VectorAdd_quickstart.py生成性能分析文件后,用 Nsight Compute 图形界面打开,按以下步骤操作:
● 选中 vector_add kernel;
● 选择“Details”标签页;
● 展开“Tile Statistics”报告板块。
此时你会看到类似图 1 的界面。
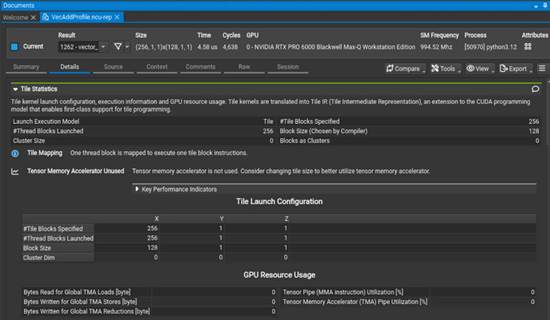
图 1. Nsight Compute 生成的性能分析报告,展示 vector_add kernel 的 tile 统计信息
请注意,Tile Statistics 板块包含了指定的 tile 数量、大小(由编译器自动选择),以及其他 tile 专属信息。
源码页面同样支持 cuTile kernels,还能查看源码行级别的性能指标——这和 CUDA C kernels 的支持方式完全一致。
如何获取 cuTile?
运行 cuTile Python 程序,需要满足以下环境要求:
- GPU 计算能力需为 10.x 或 12.x(后续 CUDA 版本会支持更多 GPU 架构);
- NVIDIA 驱动版本需为 R580 及以上(若要使用 tile 专属开发者工具,需升级到 R590);
- 安装 CUDA Toolkit 13.1 及以上版本;
- Python 版本需为 3.10 及以上;
- 安装 cuTile Python 包:执行 pip install cuda-tile 命令即可完成安装。
快速上手资源
想要深入学习,可以观看以下视频教程:
视频 1. cuTile Python 快速入门
同时,你也可以查阅 cuTile Python 官方文档。
即刻在 GitHub 上尝试示例程序,正式开启 cuTile Python 编程之旅。