
随着芯片设计、制造和多物理场仿真复杂性的持续提升,在电子设计自动化(EDA)、计算流体动力学(CFD)以及高级优化工作流程中处理大规模问题已成为普遍需求。这些计算负载推动了传统求解器的演进,并对可扩展性和性能提出了更高要求。NVIDIA CUDA 直接稀疏求解器(cuDSS)专为用户设计,能够在仅需极少代码修改的情况下实现稀疏求解器的大规模高效运行,助力新一代工程与设计实现突破性的速度与效率提升。
您可以使用混合显存模式,借助 CPU 和 GPU 来处理单个 GPU 显存无法容纳的大规模问题,或在多个 GPU 上分发工作负载,甚至可轻松扩展至多个计算节点。本博客将探讨 cuDSS 用户在解决大规模问题时可采用的策略。
入门指南
首先,本博客假设您已有使用 cuDSS 的工作代码。您可能已参考 GitHub 上的入门示例(此处 和 此处),这些示例展示了如何在单个 GPU 上运行 cuDSS,并通过 Get 和 Set 函数调整默认求解参数。这些示例涵盖了矩阵的创建与主要 cuDSS 对象的初始化,以及执行 cuDSS 的三个核心阶段:分析、数值分解和求解。
由于近年 GPU 显存容量不断提升,单个 GPU 已能处理规模较大的稀疏问题。然而,在应对真正的大规模问题(超过一千万行且非零元超过十亿个)时,仍需采用有效策略,以确保 cuDSS 能够快速高效地运行。第一种方法依然基于单个 GPU,但引入了一些技术手段,用以应对这些更具挑战性的问题,同时无需对代码进行大规模修改。<!–
重新思考数据类型:INT64 为何如此重要
创建 cuDSS 的密集或稀疏矩阵时,您可能会使用 cudssMatrixCreateDn() or cudssMatrixCreateCsr() 函数,或同时使用这两个函数。文档中对这些函数的描述如下。
cudssMatrixCreateDn
cudssStatus_t cudssMatrixCreateDn(
cudssMatrix_t *matrix,
int64_t nrows,
int64_t ncols,
int64_t ld,
void *values,
cudaDataType_t valueType,
cudssLayout_t layout
)
第二个函数 cudssMatrixCreateCsr() 接下来显示。
cudssMatrixCreateCsr
cudssStatus_t cudssMatrixCreateCsr(
cudssMatrix_t *matrix,
int64_t nrows,
int64_t ncols,
int64_t nnz,
void *rowStart,
void *rowEnd,
void *colIndices,
void *values,
cudaDataType_t indexType,
cudaDataType_t valueType,
cudssMatrixType_t mtype,
cudssMatrixViewType_t mview,
cudssIndexBase_t indexBase
)
在 0.7.0 之前的 cuDSS 版本中,稀疏矩阵索引仅支持 32 位整数。具体而言,rowStart、rowEnd 和 colIndex 的底层数据类型只能是 int,参数 indexType 也仅能为 CUDA_R_32I。自 cuDSS 0.7.0 版本起,您可采用类型为 int64 的 64 位整数索引数组,并将 indexType 设为 CUDA_R_64I,从而能够处理规模更大的问题。
注意:输入矩阵的行数和列数少于 2 × 31 是有限制的(但使用 64 位索引时,输入矩阵可以包含更多的非零元素)。
混合显存模式 – 模糊 CPU 与 GPU 之间的界限
cuDSS 混合显存模式旨在利用 GPU 和 CPU 显存,在求解超大规模稀疏线性问题时,克服单个 GPU 显存的限制。
但是,需要权衡取舍:CPU 和 GPU 之间的数据传输需要时间,并且受总线带宽的限制。虽然处理的问题规模越大,这些传输对性能的影响就越明显,但得益于现代 NVIDIA 驱动程序的优化以及快速的 CPU/GPU 互连(例如 NVIDIA Grace Blackwell 节点中的 CPU/GPU 互连),这种开销可以得到有效控制,且在某些问题规模下,混合内存的性能将显著提升。
默认情况下,混合内存模式处于禁用状态,因此启用该模式的首要步骤是调用函数 cudssConfigSet() 来配置 CUDSS_CONFIG_HYBRID_MODE,,以通知 cuDSS 启用混合内存模式。请注意,此项设置必须在调用 cudssExecute() 之前完成。
默认情况下,设备内存由 cuDSS 自动管理。它能够管理所需的设备显存,其大小相当于整个 GPU 所包含的显存容量。此外,用户可在分析(符号分解)阶段之后,通过设置自定义限制来指定较小的显存占用,该限制范围可从 CUDSS_DATA_HYBRID_DEVICE_MEMORY_MIN 值到可用设备显存(可通过 NVIDIA CUDA 运行时 API cudaMemGetInfo 查询)。需要注意的一些亮点:
- 即使混合内存处于开启状态,cuDSS 仍会优先尝试使用设备内存(若条件允许,尽量避免使用 CPU 内存),以获得更优的性能表现。
- 充分使用 GPU 显存有助于提升性能(可减少 CPU 与 GPU 之间的数据传输)。
- 可针对每个设备设置混合内存的使用限制(如下一个文本块所示)。
示例代码将引导您获取最低设备显存需求并相应地设置显存限制,从而实现对显存占用的精细控制。
...
/* Enable hybrid mode where factors are stored in host memory
Note: It must be set before the first call to ANALYSIS step.*/
int hybrid_mode = 1;
CUDSS_CALL_AND_CHECK(cudssConfigSet(solverConfig, CUDSS_CONFIG_HYBRID_MODE,\
&hybrid_mode,sizeof(hybrid_mode)), status,\
"cudssConfigSet CUDSS_CONFIG_HYBRID_MODE");
/* Symbolic factorization */
...
/* (optional) User can query the minimal amount of device memory sufficient
for the hybrid memory mode.
Note: By default, cuDSS would attempt to use all available
device memory if needed */
size_t sizeWritten;
int64_t device_memory_min;
CUDSS_CALL_AND_CHECK(cudssDataGet(handle, solverData,\
CUDSS_DATA_HYBRID_DEVICE_MEMORY_MIN,\
&device_memory_min, sizeof(device_memory_min),\
&sizeWritten), status,
"cudssDataGet for\
CUDSS_DATA_HYBRID_DEVICE_MEMORY_MIN");
printf("cuDSS example: minimum amount of device memory\n"
"for the hybrid memory mode is %ld bytes\n",
device_memory_min);
/* (optional) User can specify how much device memory is available for
cuDSS
Note: By default, cuDSS would attempt to use all available\
device memory if needed */
int64_t hybrid_device_memory_limit = 40 * 1024 ; // in bytes = 40 KB
CUDSS_CALL_AND_CHECK(cudssConfigSet(solverConfig,\
CUDSS_CONFIG_HYBRID_DEVICE_MEMORY_LIMIT,\
&hybrid_device_memory_limit,\
sizeof(hybrid_device_memory_limit)),\
status, \
"cudssConfigSet for\
CUDSS_CONFIG_HYBRID_DEVICE_MEMORY_LIMIT");
printf("cuDSS example: set the upper limit on device memory\n"
"for the hybrid memory mode to %ld bytes\n",
hybrid_device_memory_limit);
/* Factorization */
...
/* Solving */
...
第一个 cuDSS 函数称为 cudssConfigSet(),在调用首个分析步骤符号分解前启用混合内存模式。接着,使用 cudssDataGet() 确定适应混合内存模式所需的最低设备内存量。cudssConfigSet() 是用于设定 cuDSS 设备内存量的函数调用。请注意,自动内存管理有时可能引发内存不足(OOM)错误。
对于集成此功能的开发者而言,有关调试技巧的文档堪称关键资料,请您务必先阅读,以免后续遇到困难。
混合显存模式的性能取决于 CPU 与 GPU 之间的显存带宽,以实现数据在 CPU 和 GPU 之间的传输。为说明这一点,图 1 展示了采用 cuDSS 混合内存模式求解矩阵规模从 100 万到 1800 万时的分解与求解加速情况。基准为单个 NVIDIA B200 GPU 节点。所观测到的加速比,是将相同模型在 Grace Blackwell 节点上的执行表现与在 x86 Blackwell 节点上的执行表现进行对比,反映出两个节点之间内存带宽的差异比例。

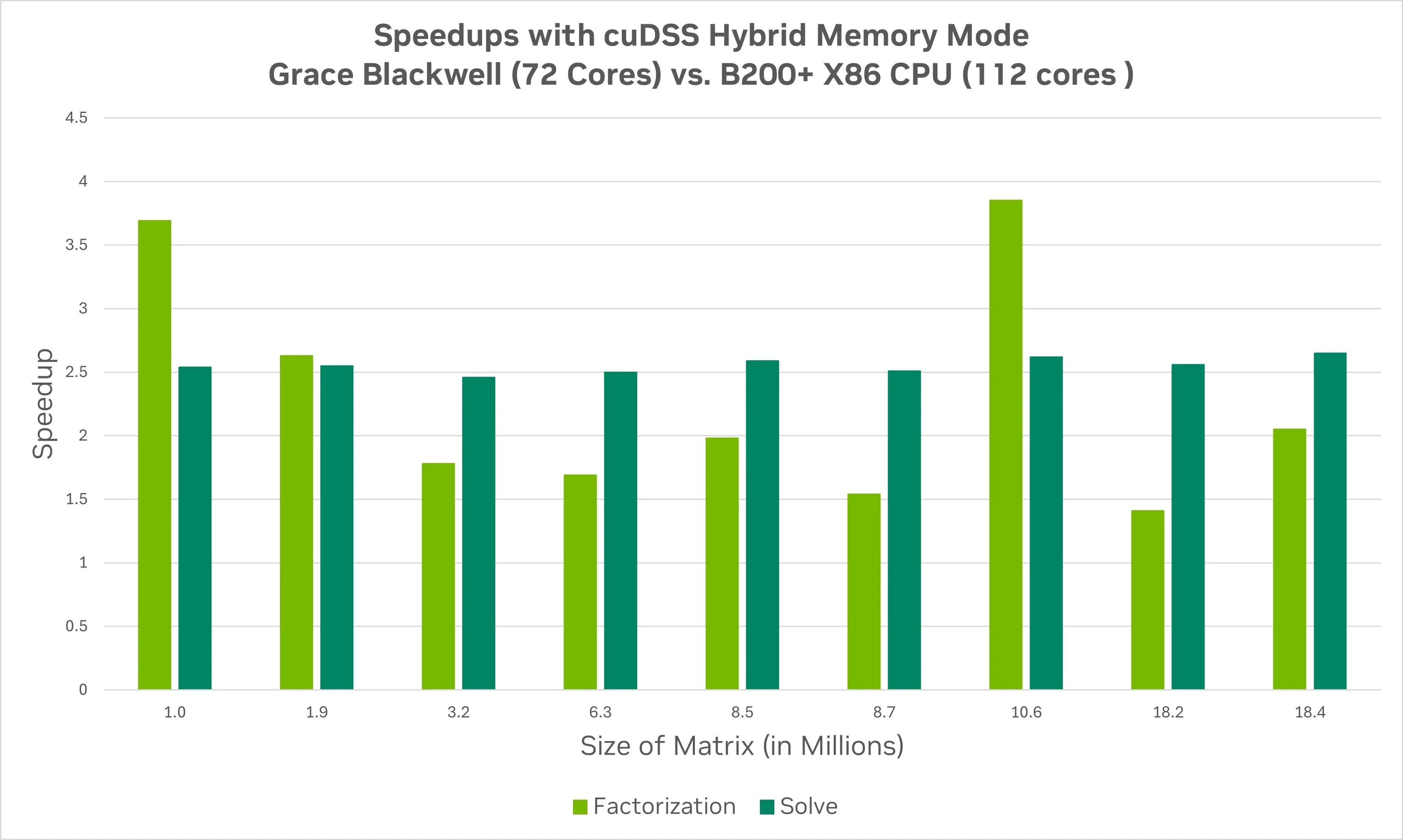
借助 INT64 和混合内存模式的 cuDSS 编码策略,我们能够应对规模更大的问题,并在需要时充分利用节点上的全部可用内存。然而,这种方法仍局限于单个 GPU。下一个策略则使我们能够利用多个 GPU 来处理更复杂的问题,同时也能通过使用更多 GPU 加速求解固定规模的问题。
肌肉倍增:多 GPU 模式 ( MG 模式)
cuDSS 多 GPU 模式(MG 模式)允许开发者在单个节点中充分利用所有 GPU,无需手动指定任何分布式通信层。cuDSS 可自动处理 GPU 间通信的全部细节。该模式在以下三种情况下尤为适用:
- 当问题规模过大,单个设备无法容纳时(无论是否采用混合内存)。
- 当用户希望避免因混合内存模式带来的性能损失时。
- 当用户关注强扩展性——通过增加更多 GPU 来解决问题,以更快地获得结果。
MG 模式的亮点在于开发者无需指定通信层:无需使用 MPI,无需使用 NCCL,也无需依赖其他通信库。cuDSS 可为您自动完成所有相关工作。
此外,由于 CUDA 在 Windows 节点上对 MPI 感知通信存在限制,MG 模式对于在 Windows 上运行的应用程序尤为关键。
下图 2 展示了在 NVIDIA DGX H200 节点上,针对约 3000 万行矩阵,在 1、2 和 4 个 GPU 配置下的求解时间(以秒为单位),其中分解时间显示在顶部图表,求解时间显示在底部图表。初始计算在单个 GPU 上执行,随后在 MG 模式下分别使用两个和四个 GPU 进行运行。如图所示,相较于单个 GPU,使用两个 GPU 求解模型可显著缩短计算时间,但相应增加了 GPU 资源的消耗。

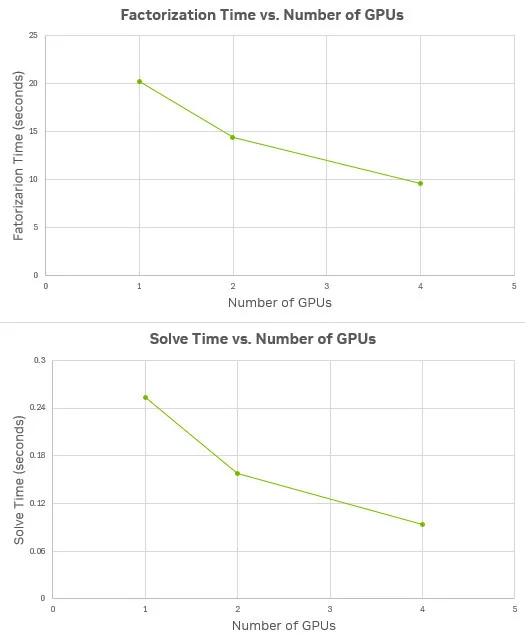
图 2。使用 Cadence 的 MCAE 应用在 H200 上对包含约 3100 万行和列、非零元素约 10 亿个的矩阵,进行 1、2 和 4 GPU 配置下的分解与求解所用时间。
此示例展示了如何利用 MG 模式。相关代码部分总结如下。请注意,其中包含使用混合内存模式的代码。这一点非常重要,因为若使用混合内存,则必须在所有要使用的设备上设置设备内存限制。
...
/* Creating the cuDSS library handle */
cudssHandle_t handle;
/* Query the actual number of available devices */
int device_count = 0;
cuda_error = cudaGetDeviceCount(&device_count);
if (cuda_error != cudaSuccess || device_count <= 0) {
printf("ERROR: no GPU devices found\n");
fflush(0);
return -1;
}
/* device_indices can be set to NULL. In that cases cuDSS will take devices
* from 0 to (device_count - 1)
*/
int *device_indices = NULL;
device_indices = (int *)malloc(device_count * sizeof(int));
if (device_indices == NULL) {
printf("ERROR: failed to allocate host memory\n");
fflush(0);
return -1;
}
for (int i = 0; i < device_count; i++)
device_indices[i] = i;
...
/* Initialize cudss handle for multiple devices */
CUDSS_CALL_AND_CHECK(cudssCreateMg(&handle, device_count, device_indices),\
status, "cudssCreate");
...
/* Creating cuDSS solver configuration and data objects */
cudssConfig_t solverConfig;
cudssData_t solverData;
CUDSS_CALL_AND_CHECK(cudssConfigCreate(&solverConfig), status,\
"cudssConfigCreate");
/* Pass same device_count and device_indices to solverConfig */
CUDSS_CALL_AND_CHECK(cudssConfigSet(solverConfig, \
CUDSS_CONFIG_DEVICE_COUNT, &device_count,\
sizeof(device_count)), status, \
"cudssConfigSet for device_count");
CUDSS_CALL_AND_CHECK(cudssConfigSet(solverConfig,\
CUDSS_CONFIG_DEVICE_INDICES, device_indices,\
device_count * sizeof(int)), status, \
"cudssConfigSet for device_count");
CUDSS_CALL_AND_CHECK(cudssDataCreate(handle, &solverData), status,\
"cudssDataCreate");
...
/* Symbolic factorization */
CUDSS_CALL_AND_CHECK(cudssExecute(handle, CUDSS_PHASE_ANALYSIS,\
solverConfig, solverData, A, x, b),\
status, "cudssExecute for analysis");
...
/* Query CUDSS_DATA_HYBRID_DEVICE_MEMORY_MIN should be done for each device
* separately by calling cudaSetDevice() prior to cudssDataGet.
* Same for getting CUDSS_DATA_MEMORY_ESTIMATES.
* Same for setting CUDSS_CONFIG_HYBRID_DEVICE_MEMORY_LIMIT with
* cudssConfigSet()
*/
int default_device = 0;
cudaGetDevice(&default_device);
for (int dev_id = 0; dev_id < device_count; dev_id++) {
cudaSetDevice(device_indices[dev_id]);
int64_t hybrid_device_memory_limit = 0;
size_t sizeWritten;
CUDSS_CALL_AND_CHECK(cudssDataGet(handle, solverData,\
CUDSS_DATA_HYBRID_DEVICE_MEMORY_MIN,\
&hybrid_device_memory_limit,\
sizeof(hybrid_device_memory_limit),\
&sizeWritten),\
status, "cudssDataGet for the memory estimates");
printf("dev_id = %d CUDSS_DATA_HYBRID_DEVICE_MEMORY_MIN %ld bytes\n",
device_indices[dev_id], hybrid_device_memory_limit);
}
/* cuDSS requires all API calls to be made on the default device, so
* resseting device context.
*/
cudaSetDevice(default_device);
/* Factorization */
CUDSS_CALL_AND_CHECK(cudssExecute(handle, CUDSS_PHASE_FACTORIZATION,\
solverConfig, solverData, A, x, b),\
status, "cudssExecute for factor");
/* Solving */
CUDSS_CALL_AND_CHECK(cudssExecute(handle, CUDSS_PHASE_SOLVE, solverConfig,\
solverData, A, x, b), status, \
"cudssExecute for solve");
...
设置 MG 模式非常简单。首先,确定节点上的设备数量,可以全部使用,也可以根据需要选择特定数量的设备。然后,将设备索引设置为从设备 0 开始的连续编号(代码默认使用第一个 device_count 设备,您可根据需要将其更改为指定的设备编号)。您可以通过命令行或文件输入设备数量及设备编号列表,从而提升代码的灵活性。
之后,特定 MG 编码首先调用 cudssCreateMg() 初始化多个设备的 cuDSS 句柄。但在进入求解阶段之前,还需根据设备信息初始化 cuDSS 配置。具体而言,在使用 cudssConfigCreate() 创建 cuDSS 求解器配置对象后,应通过 cudssConfigSet() 设置 MG 模式下的配置参数,以适配相应场景。
CUDSS_CONFIG_DEVICE_COUNT, using the arraydevice_count.CUDSS_CONFIG_DEVICE_INDICES, using the arraydevice_indices.
然后,调用函数 cudssDataCreate() 为 cuDSS 创建求解器数据,并进入下一阶段的分析。
如果您使用的是混合内存模式,可能需要先为每个设备分别设置设备内存限制,如上面的代码所示。完成设置后,即可对矩阵进行分解并求解问题。
MG 模式的亮点在于,您无需为 GPU 之间的通信编写代码。cuDSS 会自动完成所有相关工作。然而,目前使用 MG 模式仍存在一些限制。
- 不支持将 MG 模式与多 GPU 多节点 (MGMN) 模式结合使用(下一节将讨论 MGMN)。
- 目前,分布式输入不受支持。
- 当使用
CUDSS_ALG_1或CUDSS_ALG_2进行重新排序时,MG 模式不可用。 - MG 模式不支持矩阵批量操作。
- MG 模式下的所有阶段均为同步执行。
- 在调用
cudssExecute之前,所有数据必须位于第一个设备(rank 0)上,随后 cuDSS 会根据需要将数据分发至其他设备。
扩大规模:面向分布式功耗的多 GPU 多节点 (MGMN) 模式
现在,如果单个节点无法满足需求,而您希望将计算任务扩展到多个节点,该怎么办?这正是 MGMN 模式的应用场景。通过引入通信层,您可以在单个节点或多个节点中的任意数量 GPU 上灵活运行,不受限制。这使用户能够处理更大规模的问题,或利用更多 GPU 加速问题求解。
cuDSS 采用抽象层,即一个轻量级通信“shim”层,可根据需要适配支持 CUDA 的 Open MPI、NVIDIA NCCL 甚至自定义 MPI。
此 示例为MGMN包含Open MPI和NCCL的代码。若需使用自定义的通信层,请参阅相关说明。
为说明如何使用通信层,我们在以下代码块中提供了 MPI 和 NCCL 的示例代码 ifdef。编译期间定义的某些常量对本示例至关重要,但未在代码块中显示,它们是 USE_MPI 和 USE_NCCL,用于确定所采用的代码路径。
此 ifdef 代码块适用于示例代码的第 520-535 行(这些行号可能随后续版本更新而变动,请仔细核对)。
#ifdef USE_MPI
#if USE_OPENMPI
if (strcmp(comm_backend_name,"openmpi") == 0) {
CUDSS_CALL_AND_CHECK(cudssDataSet(handle, solverData, CUDSS_DATA_COMM,\
mpi_comm, sizeof(MPI_Comm*)), \
status, \
"cudssDataSet for OpenMPI comm");
}
#endif
#if USE_NCCL
if (strcmp(comm_backend_name,"nccl") == 0) {
CUDSS_CALL_AND_CHECK(cudssDataSet(handle, solverData, CUDSS_DATA_COMM,\
nccl_comm, sizeof(ncclComm_t*)), \
status, \
"cudssDataSet for NCCL comm");
}
#endif
#endif
请注意,定义 MPI 或 NCCL 时,代码更改基本很小。两者之间的代码差异十分简单。您可以通过非常相似的方式使用自己的通信层。
如之前的代码段所示,在通过 CUDSS_DATA_COMM 将通信器指针传递给 cuDSS 后,除非您的代码有特殊需求,否则无需调用任何通信层函数。cuDSS 会使用“底层”预定义的通信层,因此您无需为此编写额外代码。请参考示例代码,了解如何在多个节点上使用该功能。
要实现您自己的通信层,可参考 cuDSS 文档“高级主题”部分,其中包含入门的详细说明。
通信层要求概述如下:
- 通过将所有通信相关的基元抽象为一个独立构建的小型 shim 通信层,实现 MGMN 模式的支持。
- 用户可根据选择的通信后端(如 MPI、NCCL 等)提供自定义的通信层实现。
- 对于不使用 MGMN 模式的应用程序,cuDSS 中启用的 MGMN 执行无需任何修改。
- 利用
cudssMatrixSetDistributedRow1D()函数,MGMN 模式支持输入 CSR 矩阵、稠密右侧向量或解的一维行分布(可重叠)(详见下一段)。
cuDSS MGMN 模式可选择接受预分布式输入,也可选择生成分布式输出。您可以在 rank 0 设备上同时使用 A 和 B,此时 cuDSS 将自动分发数据;或者,您也可以调用 cudssMatrixSetDistributedRow1d() 函数,明确告知 cuDSS 如何在设备与节点之间分布数据。开发者需确保数据位于正确的节点及设备上的正确位置。
要获得出色性能,关键步骤是合理选择 CPU:GPU:NIC 绑定。此处不讨论这一点,但会在其他地方进行记录。
MGMN 模式目前存在一些限制,
- 当使用
CUDSS_ALG_1 or CUDSS_ALG_2进行重新排序时,不支持 MGMN 模式。 - MGMN 模式不支持矩阵批量操作。
- 在 MGMN 模式下,所有阶段均为同步执行。
要点
稀疏线性系统出现在许多学科中。在解决实际问题需求的推动下,这些问题的整体规模正以极快的速度增长。开发者必须寻找高效且快速的方法来应对这些挑战。NVIDIA cuDSS 提供了一个易于使用的库,可利用 NVIDIA GPU 来处理日益庞大的问题。
如需了解可与 cuDSS 一起使用的更多功能,建议您阅读文档中的高级功能部分。该部分不仅包含此处所展示特性的详细信息,还介绍了其他有助于求解大规模稀疏线性问题的功能。此外,本节还将说明如何在开发代码时利用 cuDSS 进行日志记录。这一功能非常实用,因为调试并行代码往往具有挑战性,而 cuDSS 提供了出色的支持,可在代码执行过程中获取日志信息。
在客户页面上订阅 cuDSS,及时掌握最新创新动态。




