
设计和建造独特科学研究设施的科学家与工程师同样面临诸多挑战,其中包括处理超出当前计算基础设施承载能力的海量数据速率,以实现实时提取科学见解并推动实验进程。这些挑战制约了科学发现潜力的充分发挥,并显著延缓了知识的增长速度。
NVIDIA 的科学家和工程师利用这些设施开发基于并行和分布式计算的新解决方案,以消除这些障碍。本文将介绍两个典型示例,它们将复杂的物理问题转化为可处理的数学难题,这些问题在 GPU 加速的科学计算中显著受益,涉及美国能源部的两个重要项目:NSF-DOE Vera C. Rubin Observatory 和 SLAC 的 Linac Coherent Light Source II (LCLS-II)。
这些独特的大规模研究设施均历时十年建成,实现了前所未有的科学发现,为全球科学界提供支持。NVIDIA 加速计算与 GPU 加速的 Python 库 CuPy 和 cuPyNumeric 相结合,使实验能够获得实时反馈,而这在以往难以实现。研究团队利用加速时空图像分析(ASTIA)处理南半球天空的实时“影片”,并借助 cuPyNumeric 和 CuPy 进行纳米级成像(XANI)的 X 射线分析,从而实现 LCLS II 实验的实时调控,X射线分析为纳米级成像(XANI)。
过去需要九个月才能完成的数据分析,现在仅需四个小时即可完成。
天体物理学和超快 X 射线科学
实验领域的突破性进展使极高的数据采集率能够在其内部时间和长度尺度上捕捉比以往更多的物体。
在 Vera C. Rubin Observatory,天体物理学家与天文学家首次利用一部 32 亿像素的相机完整捕捉南半球的整个天空,每晚还能发现 2000 多颗新小行星。与此同时,在 LCLS II 上,科学家与工程师引导电子穿越 3 公里的隧道,使其转化为光子,再通过超快的 X 射线爆发,拍摄出原子尺度下材料变化的影像。
天体物理学:NSF-DOE Vera C. Rubin 天文台的 LSST 相机每晚将生成 20 TB 的图像数据,并以连续模式运行十年,每隔三到四个晚上即可完成对整个南半球天空的测绘。在一个月或更长时间内,LSST 相机累积的数据量将达到 PB 级,用于制作一部为期十年的延时宇宙影片。
X 射线科学:LCLS-II 可产生极为强大的 X 射线脉冲(每秒高达 100 万次爆发),与原始 LCLS 相比,亮度提升了 1 万倍。这有助于清晰描绘电子和原子在物质内部极快速、极微小的运动。LCLS-II 可在几天内生成 PB 级 X 射线数据,用于制作量子现象的动态影像,为物质行为提供前所未有的深入见解。

常见挑战:对大型数据集进行实时分析的需求,要求计算速度和内存能力超越传统系统。加速计算虽能提供更高的计算性能,但仍需借助分布式系统来应对问题的巨大规模。通过将 HPC 系统与加速硬件及专用网络相结合,科学家能够满足这些需求。借助 cuPyNumeric,程序员可以采用统一的编程模型,既适用于传统系统,又能充分发挥现代硬件的性能优势。
全面实现工作流程自动化:这两类设施不仅超越了批量分析,更倾向于采用模块化、高度并行的工作流,无论实验规模大小,均能稳定执行。数据的移动、转换与提取均实现自动化,人工监控则专注于假设构建与结果解读,而非手动干预或IT调优。
解决方案:NVIDIA 加速计算与 GPU 加速的 Python 库 CuPy 和 cuPyNumeric 相结合,为实验转向提供了实时反馈,而这一功能在过去因计算时间过长而无法实现。如今,通过在 NVIDIA DGX Grace Hopper、NVIDIA Blackwell、NVIDIA DGX Spark 以及 NVIDIA RTX PRO 上运行相同的科学分析流程,研究人员在性能和协作方面获得了显著提升的新优势。
过去需要九个月才能完成的数据分析,如今借助 GPU 上的分布式计算,巧妙求解方程,仅用四个小时即可完成。NVIDIA GH200 Grace Hopper 超级芯片与 NVIDIA Blackwell 架构 提供统一显存,通过 GPU 加速释放庞大的问题规模,快速提取物理参数。这些模型被用于以空前的速度训练自主实验和科学分析所需的 AI 模型。
Vera C. Rubin 天文台加速工作流程與提示處理
LSST 使用一台 3.2 亿像素的相机扫描南半球的天空,在时空中穿梭观测,每晚可生成高达 20 TB 的图像数据。每个夜晚,该相机都会发现 2000 多颗此前未被观测到的新小行星。其主要科学目标包括:
- 利用精确的时间分辨率测量数据,追踪数十亿颗天体。
- 检测并分类以往未观测到的瞬变现象,例如超新星、近地天体和变星。
- 探寻宇宙持续膨胀过程中暗物质与暗能量的特征。
- 建立一个全年性存储库,记录南半球天空中各类天体在空间与时间维度上的位置信息,并向全球代理平台及天文望远镜网络发送警报,以便对单个恒星、星系、黑洞等目标开展更深入的后续观测。
迄今为止,天体物理学与天文学领域联合开发了一套基于开源 CPU 的数据处理流程,能够在 10 分钟内完成数据处理。每幅图像的采集耗时约为 40 秒。为实现近实时的数据处理,需加快计算速度,以便及时向全球望远镜发出警报并指导观测决策。
对于当前由全球天体物理学与天文学领域的科学家及工程师所开发的CPU集群处理工作流程而言,面对规模过大的数据流,需进行高级图像校正、基底构建、卷积运算、子像素差分、模式提取以及实时统计推断。
为了在更短时间内达成这些目标并提升数据处理操作的复杂程度,NVIDIA 与普林斯顿大学的科学家及工程师正共同开发一种名为加速时空图像分析(ASTIA)的 GPU 加速工作流程。该工作流程包括:
- 校准和基础构建: 快速校准大量 CCD 数据,消除伪影与失真,并为每幅采集图像构建基础函数,以实现坐标映射与转换。
- 链式转换: 扭曲、卷积、背景建模、图像减法、目标移动及误差计算(通过 CuPy 实现)均在 NVIDIA Grace Hopper 与 NVIDIA Grace Blackwell 平台上完成基准测试。
- 并行化: 支持以批量或交互式会话运行的并行化处理,涵盖映射、目标检测、拟合与编目等任务;数值计算耗时仅需数毫秒,而非数分钟。
- 包装和代理警报: 对新发现目标进行编目,提取轨道信息与坐标,并在数秒内向全球 LSST 社区发布全局警报。

LCLS II:通过并行计算与分布式计算实现扩展
在 LCLS II 中,超快 X 射线脉冲可捕捉材料和分子内原子与电子动态变化的影像。主要的科学挑战包括:
- 在单个会话中捕获数十 TB 的 3D X 光数据
- 快速解析散射 X 射线模式中的缺陷、声子色散、晶体结构、电子分布及量子现象
- 为实验调控提供实时反馈,使科学家能够即时调整参数,捕捉罕见的动态状态
这需要在单像素、单事件级别对数据进行处理与分析,并运用能够检测和重建复杂原子运动的数学模型,所有操作都必须满足严格的时间限制,从而让研究人员能够实时观察原子的移动。
纳米级成像(XANI)工作流程的高效X射线分析
在 LCLS 上,NVIDIA 与 SLAC 的科学家和工程师共同开发了并行处理 X 射线帧、拟合像素级元素的物理模型以及快速重建 3D 声子色散的分析流程,用于提取材料的热学、光学和电学特性。该分析结合模式匹配、非线性拟合与大规模归约技术,将实验结果以支持实时科学推理和自动仪器调控的方式进行系统性总结。
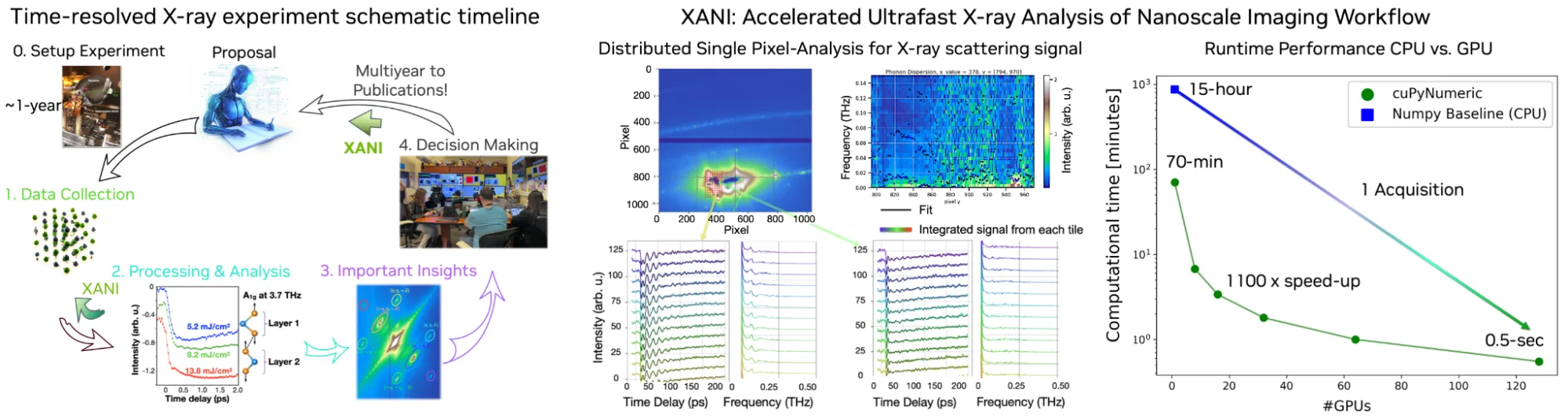
XANI 如何加速堆栈?
- 数据提取: 高吞吐量连接可将图像或实验数据快速传输至本地集群、超级计算机或本地 DGX Spark 存储。
- 并行化: cuPyNumeric 通过战略性地划分全局数据数组,实现可用资源间的高效并行化。随后,它将子分区上的操作映射到独立的处理单元以分配计算任务。运行时还会将科学计算代码分解为依赖关系驱动的任务图,从而在所有已分配资源中实现工作的隐式并行与动态调度。
- 运算符链: XANI 以一系列内核形式执行复杂的变换图(如求和、卷积、基变换),有效降低延迟和内存移动开销。通过 Python 任务实现的互操作性,支持嵌入第三方单 GPU Python 库(例如 CuPy),用于数据并行操作。
- 分布式扩展: cuPyNumeric 支持将数组和矩阵计算从桌面环境扩展到数千个 GPU 的集群,可处理超出单个节点显存容量的数据集——所有操作均原生运行于 Python 环境中。
- 协作与控制: 研究人员可交互式访问其计算环境与结果,实时监控 GPU/CPU 利用率,并借助内置工具进行性能分析。
加速计算助力实现基于物理信息的 AI 模型训练
CUDA Python 堆栈提供了一个集成化解决方案,可用于:
- 在现有解决方案缺失的情况下,开发与 Python 生态系统高度兼容的加速数学内核和函数。
- CuPy 提供与 GPU 兼容的 NumPy 和 SciPy 接口,支持在单个 GPU 上实现并行计算,从而显著提升数值计算速度。
- cuPyNumeric 提供熟悉的 NumPy/SciPy 接口,借助高级运行时管理能力,可将计算任务分布到多个 GPU 和计算节点上。
- XANI 采用高性能数组运算与转换链设计,针对矩阵数学、子像素形变和多项式投影等任务进行了优化。该软件包通过 GPU 内核与高级工作流集成,实现超快 X 射线表征的加速。
- 上述所有代码均经过优化,可在基于 Grace Hopper 和 Grace Blackwell 的服务器上高效运行。对于个人测试与开发,在 DGX Spark 或 RTX PRO 上运行这些代码相比在 CPU 系统上可显著加快结果产出。
将 GPU 和 CUDA Python 用于科学研究的提示
要使用 GPU 和 CUDA Python 解决科学问题,请遵循以下策略:
- 确定关键的科学问题,进而明确可线性求解的相关数学运算与模型。构建工作流,先使用 NumPy 处理原始数据并实现模型求解,随后将其迁移至本地 CuPy 以实现并行化。对于涉及数千到数十亿规模、需多节点系统支持的计算任务,引入 cuPyNumeric,使相同代码能在多个 GPU 与计算节点间分布执行,延续前述一致的编程模式。
- 针对超快 X 射线成像及其他像素级模型拟合工作负载,XANI 提供了一个基于 Python 的开放流程,封装了高性能 GPU 内核,并利用 cuPyNumeric 在可用资源上分发矢量化任务,实现跨多个 GPU 的任务调度。有需求的团队可克隆 XANI,将其作为参考架构,根据自身领域特点调整具体步骤(如数据提取、算子图构建、拟合与归约过程),从而借助 cuPyNumeric 的分布式执行能力,达成集群规模的加速效果。
- 同一软件堆栈(CuPy、cuPyNumeric 和 XANI)可在一系列 NVIDIA 硬件平台上运行,包括 NVIDIA DGX Spark、NVIDIA RTX PRO 服务器,以及配备 NVIDIA Grace Hopper 和 NVIDIA Grace Blackwell 平台的 8 路服务器与工作站、桌面系统,还可扩展至 NVIDIA DGX SuperPOD。这些平台具备统一内存架构,有助于简化超出单设备容量的数据集处理。这意味着开发者与研究人员可在笔记本电脑、工作站、单台 DGX Spark 或小型实验室集群上复现简化的流程,随后将未经修改的代码直接迁移至云端或更大规模的本地 DGX 系统,借助开放库作为模板,专注于领域逻辑的实现,而非为新硬件重写代码。
- 采用 CUDA Python 实现科学仪器数据的快速处理与实时调控,并在数秒内提取科学洞察。
采用加速计算实现实时转向实验的优势
采用加速计算实现科学实验的实时转向可带来诸多优势,例如:
- 弹性可扩展性:相同的 Python 代码由 cuPyNumeric 和 CuPy 提供支持,可在小型本地集群上无缝运行,并能按需扩展至百亿亿次级计算资源或超级计算机节点。
- 缩短获得见解的时间:借助加速网络与设备级并行能力,数据可在到达时即时处理,从而在与仪器同步的时间尺度内实现科学发现、实验引导或事件检测。
- 资源优化:高密度、高能效的 DGX Spark 节点在紧凑的办公空间中提供媲美大型集群机架的性能。
- 统一显存:通过 NVLink C2C 技术,CPU 与 GPU 可共享单一虚拟地址空间,处理高达 128 GB 的大型数据结构,实现高带宽、低延迟和高并发性,从而提升 CPU-GPU 工作流程的性能与灵活性。对于基于物理信息的 AI 而言,这意味着更简洁的代码与更高的持续吞吐量,摆脱了较慢且延迟较高的 PCIe 链路的制约。
- 协作式科学:团队可通过共享数据、分布式计算任务和快速迭代工作流程实现高效协作,这对多机构联合研究、实验可重复性以及开放科学至关重要。
开始使用科学加速计算
XANI、cuPyNumeric、更广泛的 NVIDIA 加速计算堆栈以及 CuPy 已经在为生产规模的天体物理学与超快 X 射线科学研究提供支持。所有研究人员或开发者均可在自身工作流程中采用相同的开源 Python 库与 NVIDIA 平台。
XANI、CUDA Python、cuPyNumeric 和 CuPy 展现了百亿亿次级时代设施(例如 Rubin Observatory 和 LCLS-II)在科学计算能力上的代际飞跃。通过整合本地桌面级硬件、可扩展服务器基础设施、可扩展软件以及高性能网络,研究人员能够以更快的速度和更高的灵活性开发、测试并部署大规模数据工作流程。无论是分析单次天空调查,还是协调全球性实验,NVIDIA 加速计算都能助力科学团队实现近实时的洞察与发现。
开始使用 CUDA Python、cuPyNumeric 与 CuPy。
在 NVIDIA GTC AI 大会 上了解更多信息,该会议展示了 通过加速 HPC+ AI 工作流程,实现 Vera C. Rubin Observatory 和 X 射线自由电子激光的实时转向 【S81766】。
致谢
感谢 Yusra AlSayyad 和 Nate Lust(普林斯顿大学);Adam Bolton、Seshu Yamajala 和 Jana Thayer(SLAC 国家加速器实验室);以及 Lucas Erlandson、Emilio Castillo Villar、Malte Foerster 和 Irina Demeshko(NVIDIA)所做的贡献。




