
大规模扩散模型的近期进展深刻改变了生成式 AI 在多个领域的应用,涵盖图像合成、音频生成、3D 素材创建、分子设计等。这些模型在根据多种条件生成高质量、多样化输出的任务中,展现出前所未有的能力。
尽管取得了这些成功,采样效率低下依然是一个根本性瓶颈。标准扩散模型需要执行数十至数百个迭代降噪步骤,导致推理延迟较高且计算成本昂贵,限制了其在交互式应用、边缘设备以及大规模生产系统中的实际部署。
视频生成面临着尤为严峻的挑战。NVIDIA Cosmos 等开源模型以及商业文本转视频 (T2V) 系统虽已展现出卓越的文本转视频能力,但由于时间维度的存在,视频扩散模型的计算需求高出几个数量级。生成单个视频可能需要数分钟至数小时,这使得在智能体训练中实现实时视频生成、交互式编辑以及世界建模变得极具挑战性。
在不牺牲质量和多样性的情况下加速扩散采样已成为一项关键的开放挑战,而视频生成是其中要求最高、影响最为深远的应用之一。
本博客将介绍 NVIDIA FastGen,这是一个开源库,统一了先进的扩散蒸馏技术,能够将多步扩散模型加速为一步或几步生成器。我们回顾了基于轨迹和基于分布的蒸馏方法,展示了可复现的基准测试结果,表明在保持生成质量的同时,采样速度提升了 10 倍至 100 倍,并验证了 FastGen 在高达 140 亿参数的大型视频模型上的可扩展性。此外,我们还重点介绍了其在交互式世界建模中的应用,其中因果蒸馏技术实现了实时视频生成。
加速的关键方法是什么?
越来越多的研究人员开始探索扩散蒸馏,这项技术旨在将长降噪轨迹压缩为少量推理步骤。现有方法大致可分为两类:
- 基于轨迹的蒸馏—包括渐进式蒸馏和一致性模型,例如 OpenAI 的 iCT 和 sCM,以及麻省理工学院与卡内基・梅隆大学的 MeanFlow—可直接回归教师模型的降噪轨迹。
- 基于分布的蒸馏—例如 Stability.AI 的 LADD,以及麻省理工学院与 Adobe 的 DMD—则通过对抗性或变分目标来对齐学生与教师模型的分布。
这些方法已成功将图像域中的扩散采样减少到一至两个步骤。然而,每种方法都存在显著的权衡。基于轨迹的方法通常面临训练不稳定、收敛缓慢以及可扩展性不足的挑战,而基于分布的方法则往往内存消耗较大,对初始化敏感,并容易出现模式崩溃。此外,这些方法本身尚难以在真实视频等复杂数据上始终实现高保真的单步生成。
这激发了对统一且可扩展框架的需求,该框架能够集成、比较并改进扩散蒸馏方法,以实现稳定训练、高质量生成,以及对大型模型和复杂数据的可扩展支持。
FastGen 的优势
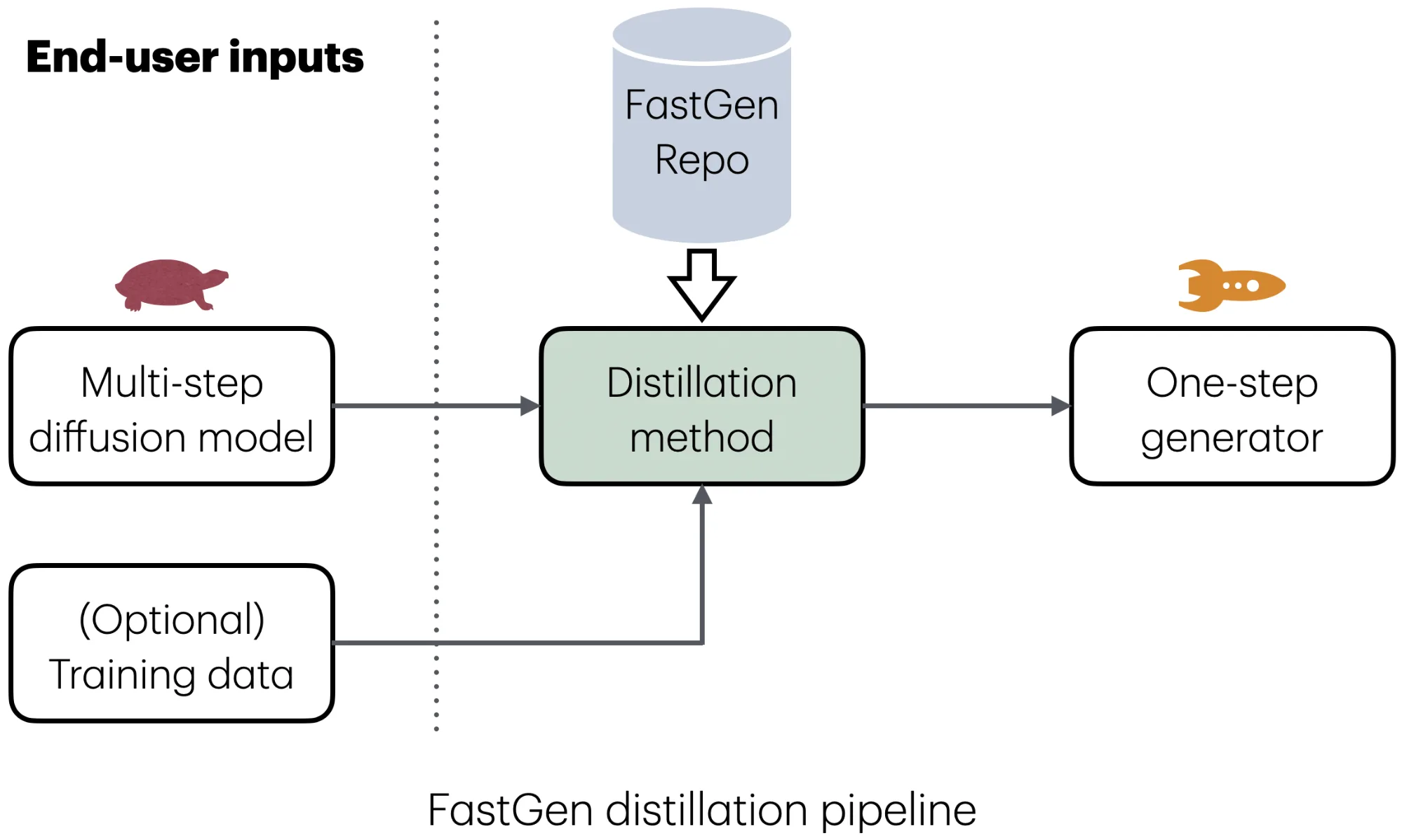
FastGen 是一个全新的开源多功能库,将先进的 Diffusion 蒸馏方法集成于一个通用的即插即用接口中。
统一且灵活的界面
FastGen 为跨不同任务加速扩散模型提供了统一的抽象。用户只需提供其扩散模型(以及可选的训练数据),并选择合适的蒸馏方法。随后,FastGen 将自动处理训练与推理流程,将原始模型转换为一步式或几步式生成器,同时最大程度地降低工程开销。
可复制的基准测试和公平比较
FastGen 在标准图像生成基准测试中复现了所有受支持的蒸馏方法。历史上,扩散蒸馏方法通常在不同的独立代码库中提出,并采用各异的训练方式,导致难以进行公平比较。通过统一实现方式与超参数选择,FastGen 实现了透明的基准测试,并为少步扩散社区提供了通用的评估平台。
下表 1 全面比较了蒸馏方法在 CIFAR-10 和 ImageNet-64 基准测试中的性能,展示了 FastGen 的再现能力。该表列出了 FastGen 统一实现下各方法在单步图像生成中的质量表现,以及对应论文中报告的原始结果(如括号内所示)。所有方法均按其蒸馏策略分类:一类是基于轨迹的方法,通过优化扩散过程中的轨迹实现加速(如 ECT、TCM、sCT、sCD、MeanFlow);另一类是基于分布的方法,旨在直接匹配生成数据的分布(如 LADD、DMD2、f-蒸馏)。
| 此处链接的研究论文中指出的加速图像生成方法,使用 Fréchet 起始距离(FID)分数来衡量生成质量 | 图像生成,用 Fréchet 起始距离 (FID) 分数来表示质量 | ||
| CIFAR-10 | ImageNet-64 | ||
| 基于轨迹的蒸馏 | ECT (Geng et al., 2024) | 2.92 FID from FastGen (3.60 reported in research paper) | 4.05 from FastGen (4.05 reported in research paper) |
| TCM (Lee et al., 2025) | 2.70 (2.46) | 2.23 (2.20) | |
| sCT (Lu et al., 2025) | 3.23 (2.85) | – | |
| sCD (Lu et al., 2025) | 3.23 (3.66) | – | |
| MeanFlow (Geng et al., 2025) | 2.82 (2.92) | – | |
| 基于分布的蒸馏 | LADD (Sauer et al., 2024) | – | – |
| DMD2 (Yin et al., 2024) | 1.99 (2.13)* | 1.12 (1.28) | |
| f-distill (Xu et al., 2025) | 1.85 (1.92)* | 1.11 (1.16) | |
超越视觉任务
虽然我们在此博客中演示了 FastGen 在视觉任务中的应用,但该库的通用性足以加速不同领域中的任何扩散模型。一个尤其值得关注的领域是面向科学的 AI 应用,其中样本质量通常与样本多样性同等重要。
通过将蒸馏方法与网络定义解相结合,FastGen 使添加新模型变得简单且即插即用。例如,我们已在 NVIDIA PhysicsNeMo 中利用 ECT 成功提炼出 NVIDIA 天气降采样模型校正器扩散(CorrDiff),实现了一步式公里尺度大气降采样。
如下图 2 所示,蒸馏模型在技能和传播方面与 CorrDiff 的预测相匹配,同时推理速度提升了 23 倍。

可扩展的高效基础设施
FastGen 还提供高度优化的训练基础设施,支持将 Diffusion 蒸馏扩展到大型模型。涵盖的技术包括:
- 完全分片数据并行 v2 (FSDP2)
- 自动混合精度 (AMP)
- 上下文并行 (CP)
- 灵活的注意力机制
- 高效的 KV 缓存管理
- 自适应有限差分 JVP 估计
通过这些优化,FastGen 能够高效地利用大规模模型进行蒸馏。例如,我们采用 DMD2 方法,将 14B 参数的 Wan2.1 T2V 模型 成功蒸馏为几步生成器,并在 64 个 NVIDIA H100 GPU 上于 16 小时内完成训练。
图 3 展示了 50 步教师模型与采用改进的 DMD2 方法的双步蒸馏学生模型在蒸馏 Wan2.1-T2V-14B 上的直观对比。尽管学生的采样速度比教师快 50 倍,其生成质量仍与教师十分接近。

用于交互式世界建模的 FastGen
交互式世界模型旨在模拟环境动态,并能够对用户操作或智能体干预作出实时且连贯一致的响应。它们需要:
- 高采样效率
- 长时视距一致性
- 基于动作的可控性
视频扩散模型能够捕捉丰富的视觉动态,为世界建模提供了坚实的基础,但其多步采样过程及被动表达方式会阻碍实时交互。
为解决这一问题,近期研究人员探索了因果蒸馏技术,该技术能够将双向视频扩散模型转化为分块级自回归模型。这种自回归结构支持实时交互,已成为构建交互式世界模型的良好基础。
FastGen 为多种因果蒸馏方法(包括 CausVid 和 Self-Forcing),其默认公式主要基于分布。
由于双向教师模型与自回归学生模型之间存在性能下降和轨迹不对齐的问题,基于轨迹的蒸馏尚未在因果蒸馏中得到广泛应用。FastGen 通过两种方式应对这些挑战:
- 热启动因果蒸馏: 在应用基于分布的目标前,可采用基于轨迹的方法对学生模型进行初始化。
- 通过扩散实现因果 SFT: FastGen 提供一种因果监督微调(SFT)方法,该方法首先训练多步块自回归模型,再将其作为基于轨迹蒸馏的新教师模型。
这些组件支持混合蒸馏流水线,将基于轨迹方法的稳定性与基于分布目标的灵活性有效结合。
在应用方面,FastGen 支持多种开源视频扩散模型,包括 Wan2.1, Wan2.2, 和 NVIDIA Cosmos-Predict2.5, 可为多个视频合成场景提供端到端的加速支持:
- 文本转视频 (T2V)
- 图像转视频 (I2V)
- 视频转视频 (V2V)
用户可灵活自定义蒸馏工作流,例如将 2B 模型扩展至 14B 模型、为 I2V 添加首帧调节,或在 V2V 任务中引入结构先验,如通过深度引导实现驾驶视频生成。
因此,FastGen 为推进交互式世界模型提供了必要的基础设施,实现了将扩散模型从无源合成器转变为实时交互式系统所需的快速、可控且时间一致的生成。
开始使用
FastGen 不仅仅是蒸馏技术的集合,而是一个用于加速扩散模型的统一研究与工程平台。通过将基于轨迹和基于分布的方法整合到一个可扩展且可复现的框架中,FastGen 降低了探索少步扩散模型的门槛,并支持跨方法的公平基准测试。
立即试用 FastGen— 插入您自己的扩散模型,选择蒸馏方法,见证多步生成器向单步执行器的转化。无论您的目标是加速视觉合成与科学发现,还是为交互式世界模型提供支持,FastGen 都能以灵活性和可重复性,助您在极短时间内将创意付诸实践。




