
在视觉 AI 系统中,模型吞吐量不断提高。周围的工作流阶段必须与时俱进,包括解码、预处理和 GPU 调度。在上一篇文章中,使用 NVIDIA CUDA 加速的 VC-6 构建高性能视觉 AI 工作流被描述为数据与张量之间的差距,即 AI 工作流阶段之间的性能不匹配。
The SMPTE VC-6 (ST 2117-1) 编解码器通过基于图块的分层架构弥补了这一差距。图像编码为可逐步改进的质量级别 (LoQ) ,每个级别都增加了细节增量。这可实现仅对所需分辨率、感兴趣区域或彩平面进行选择性检索和解码,并随机访问独立可解码帧。工作流只能检索和解码模型所需的内容。
但是,高效的单图像执行并不会自动转化为高效的扩展。随着批量大小的增长,瓶颈从单镜像内核效率转变为工作负载编排、启动节奏和 GPU 占用率。
本文重点介绍为批量推理和训练工作负载扩展 VC-6 解码所需的架构更改。由于 NVIDIA Nsight Systems 和 NVIDIA Nsight Compute 允许开发者识别系统和内核级别的约束条件,因此他们利用 NVIDIA Nsight Systems 和 NVIDIA Nsight Compute 重新设计了 VC-6 CUDA 实现,以实现批量吞吐量。与之前的实施方案相比,每张图像的解码时间最多可减少 85%,批量执行 LoQ-0 (约 4K) 的解码时间为亚毫秒,较低的 LoQ 的解码时间约为 0.2 毫秒,且输出质量相同。这显著提高了生产视觉 AI 工作负载的工作流效率。
隆重推出 VC-6 批处理模式实现
新实现围绕多项架构更改而构建,包括批量模式和内核级优化。
批量模式:从 N 个解码器到单个解码器
- 重新设计执行模型
- 通过更改算法,使用单个解码器同时解码多张图像
- 改进并行化
- 利用现有并行化维度 (图块、平面) 旁边的新工作维度 (图像) ,将初始 VC-6 图块层次结构工作转移到 GPU。
- 小批量管线
内核级优化
- Nsight 计算驱动范围解码器内核优化
- 经过优化,内核速度提高了约 20%
以下各节将详细介绍对 VC-6 解码器的这些更改。至于任何 CUDA 优化,我们计划从 Nsight Systems 等系统级分析器入手,以识别和修复初始性能瓶颈,然后使用 Nsight Compute 优化各个内核。
从 N 个解码器移至单个解码器
图 1 的顶部显示了使用 NVIDIA CUDA 加速 VC-6 构建高性能视觉 AI 工作流中所详述的起点,如 Build High-Performance Vision AI Pipelines with NVIDIA CUDA-Accelerated VC-6 中所述。
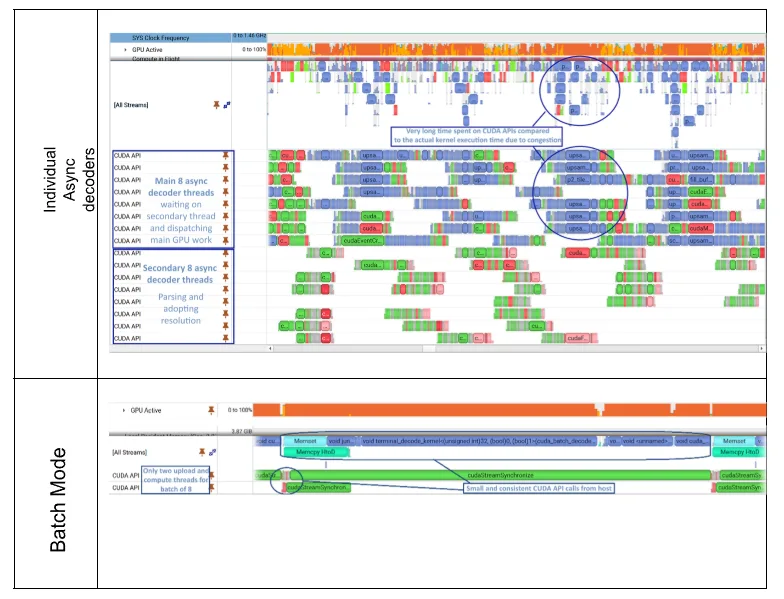
中间行显示 CUDA API 使用率较高,每行对应一个单独的解码器实例,每个实例解码一张图像。在“All Streams” (所有流) 中,GPU 上许多并发运行的小型内核都以蓝色显示。顶部行显示设备利用率。浅橙色表示利用率不足,深橙色表示满载。在本例中,即使分配了足够多的工作,也很少显示充分利用情况。因此,分析算法并非最佳。
这种低效的原因是执行大量的小型内核。每次核函数启动都会产生一些相关的用度,例如调度和核函数资源管理。在此设置中,每个内核的持续开销和每个内核的少量工作量会导致开销与实际工作量之间的比率降低。
改变这种情况需要改变范式,从许多小的内核转变为几个更大的内核。
在这种情况下,NVIDIA Nsight 推动了对执行模型的重新设计,将用于 N 张图像的 N 个解码器转变为可同时解码 N 批图像的单一解码器。这种新的执行模型将固定的工作量重新分配到更少的内核中,每个内核都有更多的工作量。图 1 的底部显示了重新实现的效果。它仅显示两条 CUDA API 时间线,仅显示少量大型内核,并显示完整的 GPU 利用率 (由深橘色 GPU 利用率表示) 。
将更多工作转移到 GPU 上
在初始实施中,在 CPU 上对 VC-6 图块层次结构的根层和窄层进行解码。对于单图像解码,这些较窄阶段的工作量太小,无法支持 GPU 执行。在批量设计中,虽然每张图像的工作量仍然很小,但多张图像的聚合可提供足够的并行性,从而有效利用 GPU。
此外,还对算法进行了修改,消除了处理可变图像维度的主机侧逻辑。通过将其嵌入 GPU 内核,NVIDIA Nsight 表明这降低了同步点和提交延迟,同时提高了工作流的流畅性。
图 2 和 3 显示了解码图像在 LoQ-0 和 LoQ-2 下的利用率和 CPU 开销概览,这表明 LoQ-2 的效率更低。
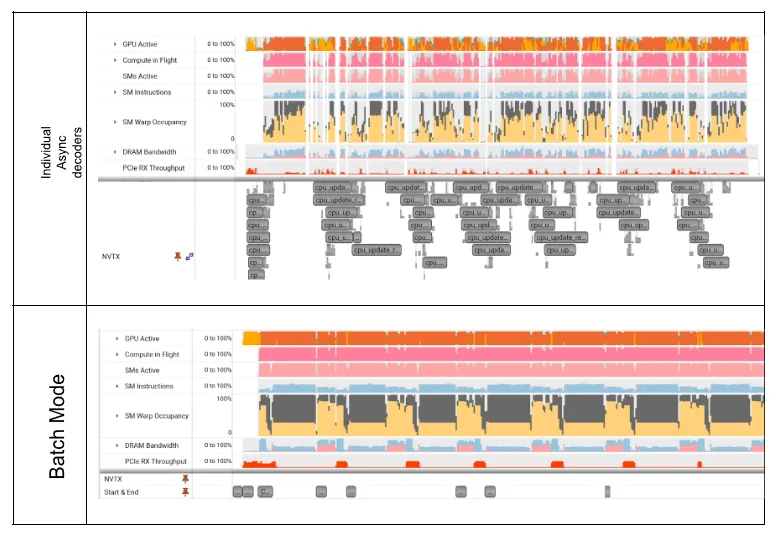
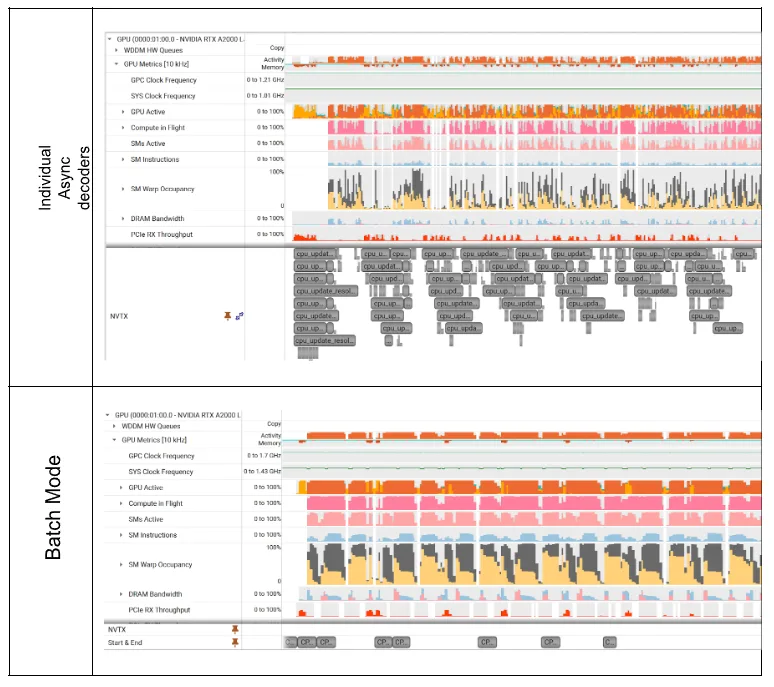
但是,在批处理模式 VC-6 (图 2 和图 3 底部) 下,GPU 执行即使是最小的 LoQ 也是可行的,因为多个图像的聚合工作负载可以在 GPU 上高效计算。
小批量管线
新的解码器设计将每个批量拆分成小批量。这些工作流包括 CPU 处理、PCIe 传输和 GPU 解码阶段。小批量图像同时驻留在工作流阶段,而各个阶段同时运行并隐藏彼此的成本。
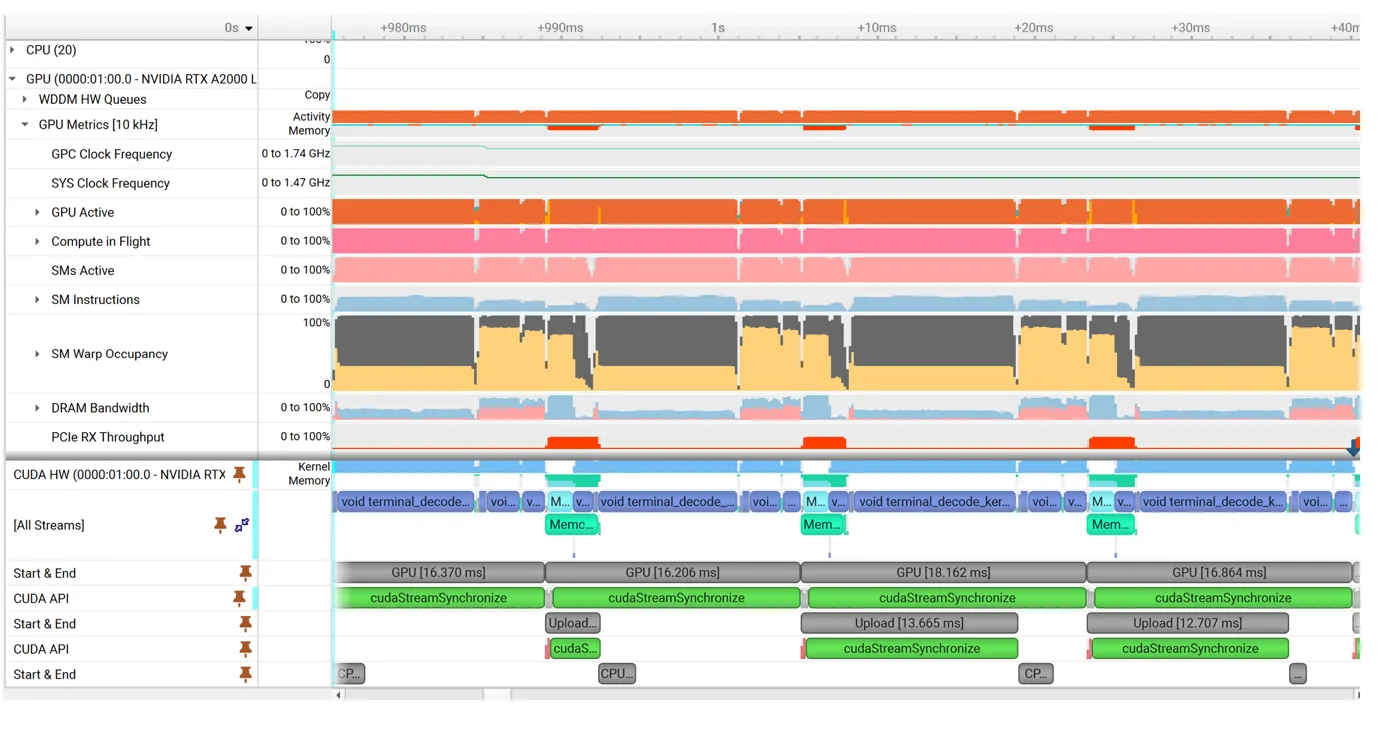
图 4 展示了这种小批量管线。与图 1 类似,CUDA API 调用从两个线程 ( UPLOAD 和 GPU) 进行调度,且主机端资源用量最少。工作聚合显著减少了 CUDA API 调用、内存操作和同步,同时在整个批量中分摊了内核启动用度。
内核级优化
Nsight Systems 透露,初始优化减少了 CPU 开销,而进一步改进则需要内核优化。实现范围解码器的 terminal_decode 核函数值得注意。Nsight Compute 强调了之前的非关键微架构限制。强调了以下算法问题:典型的低级低效,例如低流 SM 占用率、线程束离散、非合并内存访问和寄存器压力。这些见解对于开发者尽可能消除或最大限度地减少这些算法问题至关重要。
Nsight Compute 源热图和 Warp Stall Sampling (所有样本) 突出显示了每个源线所花费的测量时间。它们表明,在范围更新逻辑中,需要在整数除法上花费大量时间 (图 5) 。由于 GPU 未针对整数除法进行优化,准确性也不容协商,因此无法优化这些运算。

对于在共享内存上作为二进制搜索实现的解码器表查找,Nsight Compute 还揭示了明显的短记分牌停顿 (图 6) 。
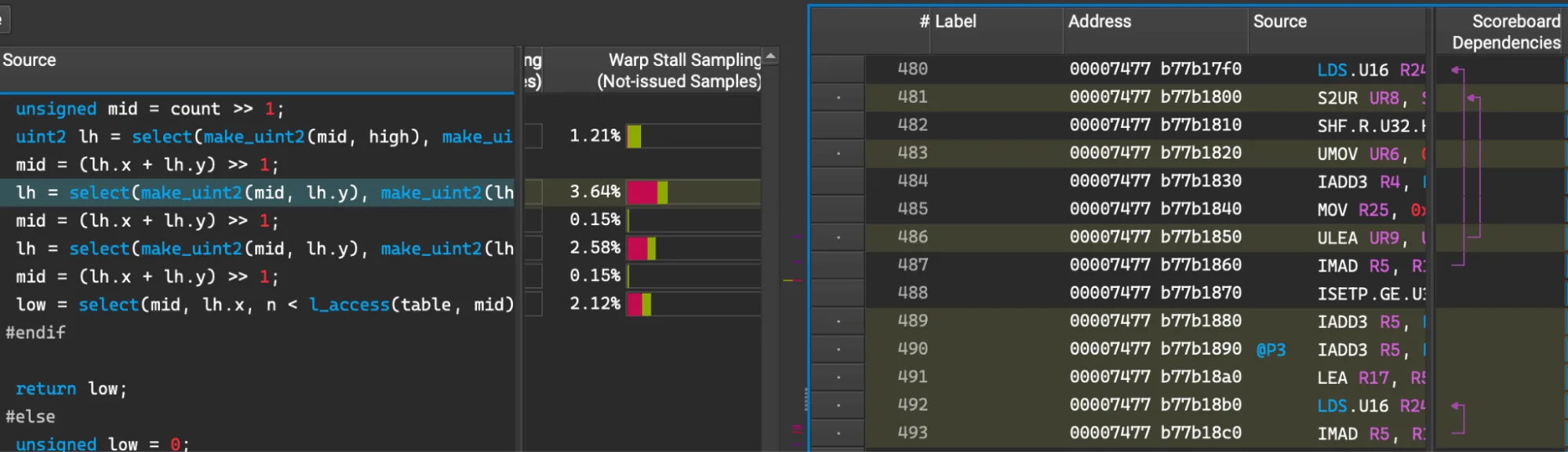
这些卡顿指向共享内存负载 (图 6 中的 LDS) ,否则,动态索引到本地数组会导致本地内存访问速度变慢。由于查找表的大小不变,因此可以将此方法替换为局部变量和展开循环。与二进制搜索相比,这种详尽的搜索可将索引固定为驻留在寄存器中的固定大小数组。对两个范围解码器应用这两项更改后,此内核的速度提高了约 20%。
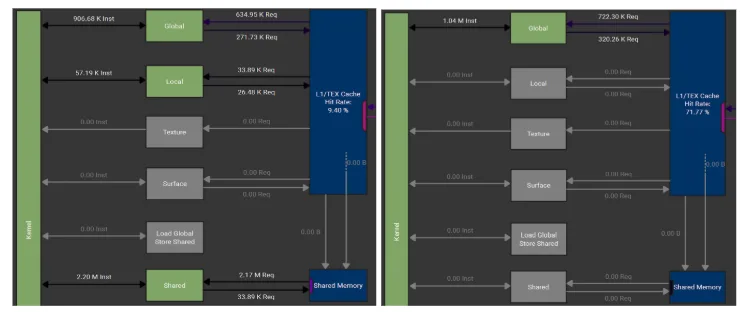
图 7 显示了 Nsight Compute 的内存图表。从视觉上看,它确认修改后既未使用共享内存 (最后一行) ,也未使用本地内存 (第 2 行) 。
这样一来,寄存器的使用量就会增加,从每个线程 48 个寄存器增加到 92 个。在这种情况下,考虑到每线程限制为 255 个寄存器,并且此内核的网格维度相对较小,这种做法是可以接受的。由于在此阶段,针对每个 SM 的高块驻留不是优先事项,因此额外的寄存器压力不会限制整体吞吐量。
另一项优化是将自定义选择例程替换为 cub::DeviceSelect 函数调用。这简化了代码,并将当前和即将推出的硬件的维护和优化工作分流至 CUB。
性能扩展和更新的结果
图 8 使用 UHD-IQA 数据集 (可通过 V-Nova on Hugging Face 获取) 在四个 LoQ ( LoQ-0 = 4K、LoQ-1 = 2K、LoQ-2 = 1K、LoQ-3 = 0.5 K) 下对不同批量大小下的每张图像的解码时间进行了比较。
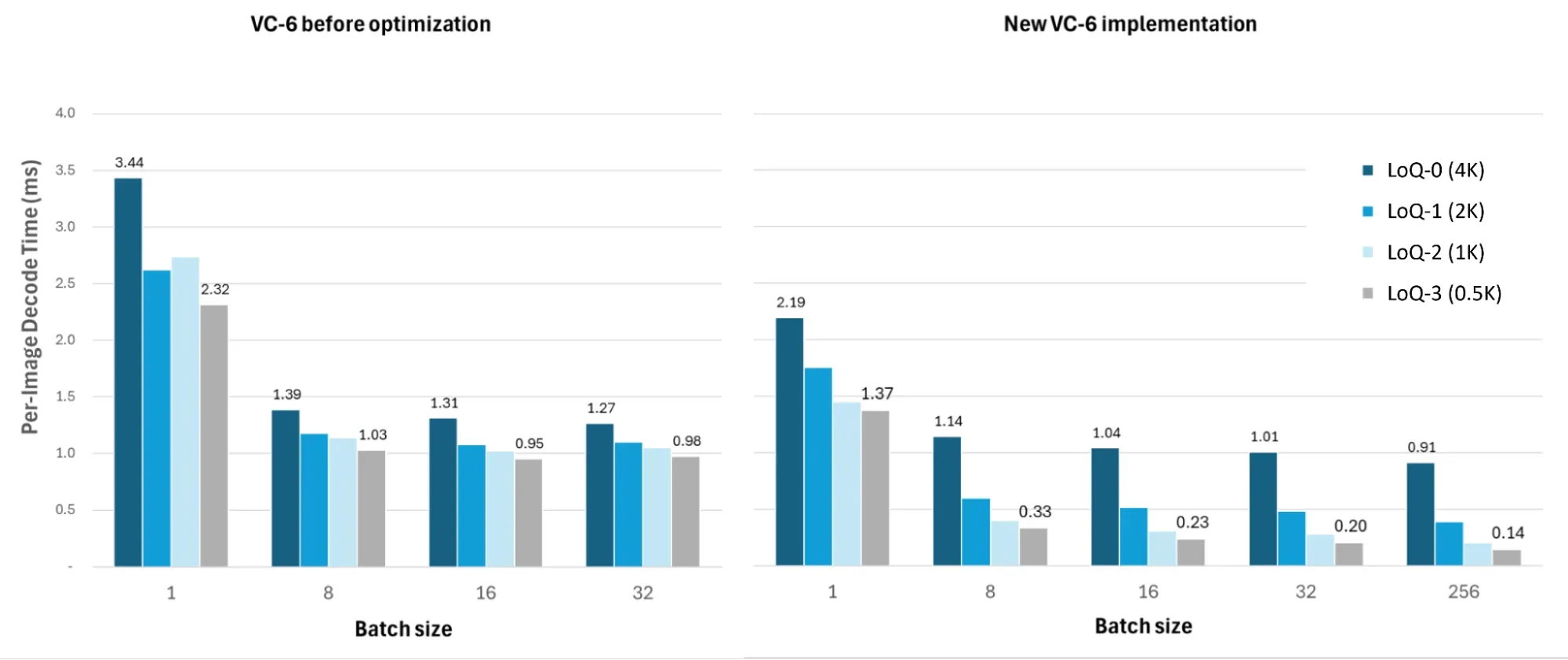
出现了两种不同的缩放行为:
- 之前的实现不再局限于小批量 (大约 1 – 16 个) 。额外的图像无法进一步转化为每张图像的收益。相比之下,优化的 CUDA 实现会随着批量大小的增加而不断改进。例如,在大批量下,LoQ-0 (约 4K) 解码时间降至每张图像 1 毫秒以下。
- 在较低的 LoQ 下,相对改进会增加。每个图像的工作负载越小,可以聚合的独立工作就越多,从而提高 GPU 利用率。在较高的批量大小下,LoQ-2 解码可达到每张图像约 0.2 毫秒,LoQ-3 约 0.14 毫秒。
衡量的改进包括:
- 批量大小为 1 (LoQ-0) 时,每张图像的解码时间减少 36%
- 对于 LoQ-2 和 LoQ-3,批量大小为 16 – 32 时,每张图像的解码时间减少了约 70 – 80%
- 批量大小为 256 时,每张图像的解码时间最多可降低 85%
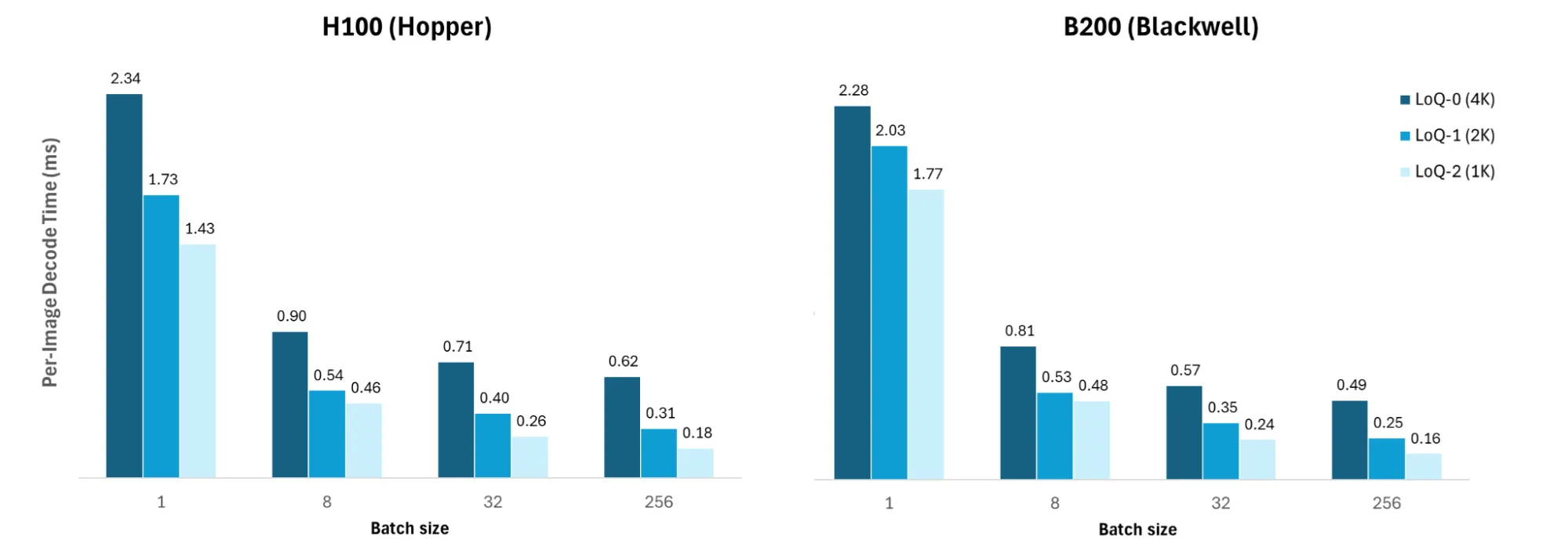
图 9 显示了在 NVIDIA H100 (Hopper),和 NVIDIA B200 (Blackwell) GPU 上重新设计的实现在批量大小上的性能。结果表明,性能提升并不局限于芯片,而是源于改进的批量模式。这有效地使足够的并行工作满足现代 GPU 架构的需求。
适用于视觉 AI 工作流的 VC-6
利用 VC-6 随机访问的内部解码、LoQ 解码以及选择性兴趣区域或颜色通道访问,实现智能且量身定制的解码,有助于训练、推理和视频摘要工作流程。这是未来工作的途径。
开始使用 VC-6 解码
扩展 VC-6 解码需要的不仅仅是内核调整。Nsight 分析可揭示启动节奏、占用率、线程差异和内存行为方面的结构限制。通过重新设计 CUDA 执行模型以显示更多独立工作并跨批量分摊用度,新实现可将每张图像的解码时间最多降低 85%,批量中 LoQ-0 (约 4K) 的解码时间可达到亚毫秒,LoQ 较低的解码时间可达到约 0.2 毫秒,且输出质量相同。,达到亚毫秒解码时间
随着视觉 AI 工作负载的不断扩展,包括解码和预处理阶段在内的每个步骤都决定了整体工作流效率。
要开始使用,请查看以下资源:
- VC-6 样本
- VC-6 编码和选择性解码示例
- 使用 Hugging Face 数据集重现结果的基准测试套件
- VC-6 AI Blueprint
- 演示展示了视觉 AI 工作流中的 VC-6 选择性解码
- 适用于多个用例的参考集成模式




