代理式 AI 是一个专业模型协同工作的生态系统,可处理规划、推理、检索和安全护栏。随着这些系统的扩展,开发者需要能够理解现实世界多模态数据、与全球用户自然交谈以及跨语言和模式安全运行的模型。
在 GTC 2026 大会上,NVIDIA 推出了新一代 NVIDIA Nemotron 模型,旨在作为统一的智能体堆栈协同工作:
- NVIDIA Nemotron 3 Super,用于长上下文推理和代理式任务
- NVIDIA Nemotron 3 Ultra (即将推出) ,可在开放前沿模型中实现更高的推理准确性和效率
- NVIDIA Nemotron 3 内容安全 for 多模态、多语言内容审核
- NVIDIA Nemotron 3 VoiceChat (抢先体验版) ,可实现低延迟、自然的全双工语音交互
- 用于企业级多模态理解的 NVIDIA Nemotron 3 Nano Omni (即将推出)
- NVIDIA Nemotron RAG,用于使用 NVIDIA Llama Nemotron Embed VL 为图像和文本模式生成嵌入,以及使用 NVIDIA Llama Nemotron Rerank VL 在相关性取决于视觉内容时对候选图像或文本进行重新排序
Nemotron 系列模型与开放数据、训练方法和 NVIDIA NeMo 工具相结合,提供了一个端到端工具包,用于构建、评估和优化生产级代理式 AI 系统。
本博客将探讨最新的 Nemotron 3 模型、其性能,以及开发者如何使用这些模型构建可扩展的多模态实时 AI 智能体。
借助 NVIDIA Nemotron 3 Super 为多智能体系统提供支持
多智能体系统受到“上下文爆炸”的困扰,词元的海量历史记录是标准聊天的 15 倍,并且每个决策都有“思维链推理”。NVIDIA Nemotron 3 Super 是一个开放的混合专家 (MoE) 模型,每次只需激活 120 亿个参数,只需一小部分计算即可提供高准确性和效率。
混合架构在 NVIDIA Blackwell GPU 上具有 Mamba 和 Transformer 层、多词元预测和 NVFP4 精度,可提供比上一代高 5 倍的吞吐量,同时减少内存占用和成本。可配置的“思考预算”允许开发者绑定思维链,以保持延迟和支出的可预测性,即使是连续的智能体工作负载也是如此。
凭借 1M-词元上下文窗口和跨 10 多个环境的强化学习,Nemotron 3 Super 在编码、数学、指令遵循和函数调用方面表现出色,非常适合多智能体应用,在 NVFP4 中运行时,可显著提高 Blackwell 的吞吐量。
Nemotron 3 Super 使用潜在 MoE 来调用四位专家专家,而推理成本仅为一位,在词元送达专家之前对其进行压缩。
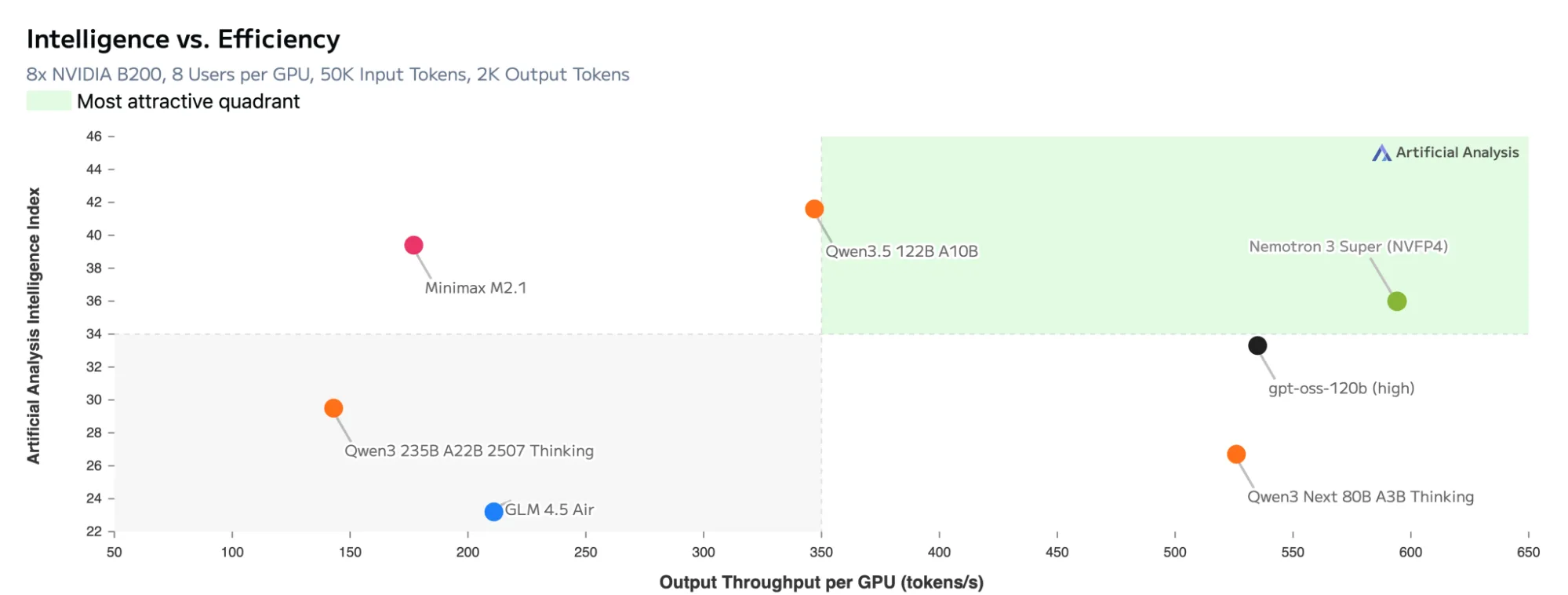
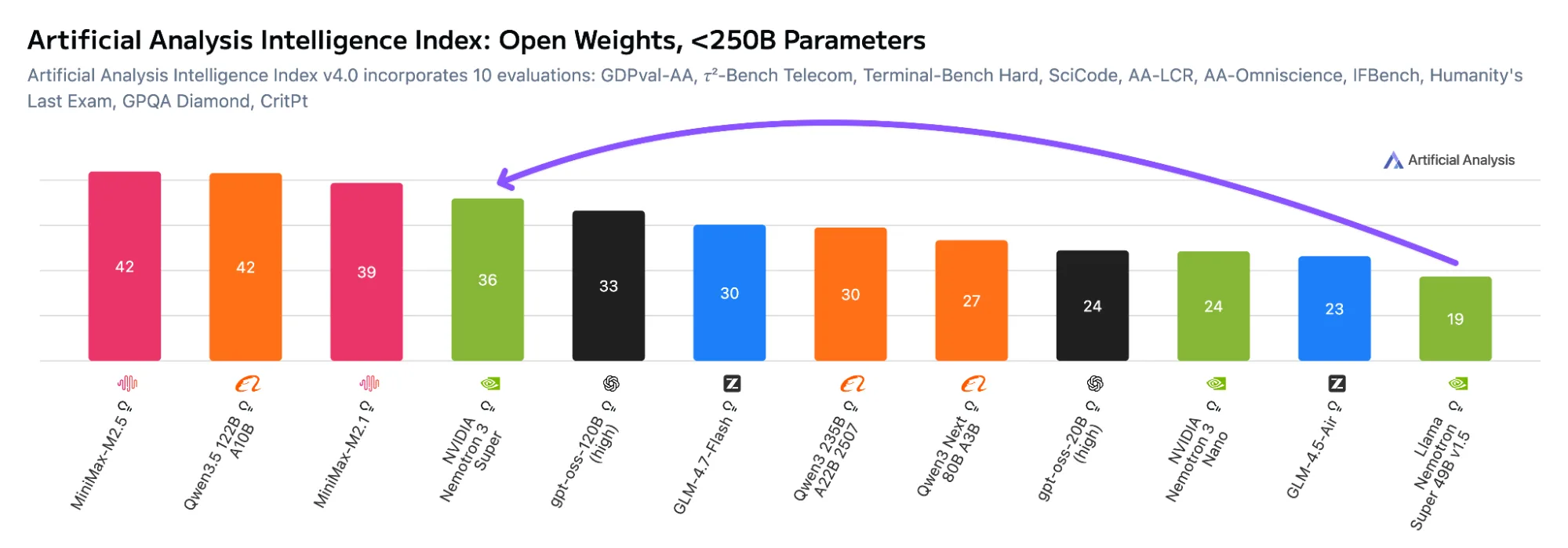
外部评估对此进行了支持。在 2500 亿参数下的开放权重模型的人工智能分析智能指数中,Nemotron 3 Super NVFP4 身顶级模型之列,与领先替代产品的最高智能得分相匹配。
在智能效率对比图中,Nemotron 3 Super 位于最吸引人的右上角象限,将强大的任务性能与每个 GPU 的高输出吞吐量相结合,使其成为成本敏感型生产代理的绝佳选择。
Nemotron 3 Super 具有开放权重、开放训练数据和开放开发方案,是软件开发、深度研究、网络安全和金融服务行业的理想之选。
借助 Nemotron 3 内容安全技术确保智能体安全
随着智能体从纯文本扩展到多模态工作流,安全护栏必须在输入、检索和输出之间不断演进。它们还必须适用于企业 copilot 和用户生成内容 (比如约会应用或社交媒体) 等用例,并检测医疗健康等需要自我伤害的代理式系统中的提示注入。
Nemotron 3 Content Safety 是一个紧凑型 4B+ 参数多模态安全模型,可检测文本和图像中的不安全或敏感内容。它基于 Gemma® 3 4B 主干构建,并具有基于适配器的分类头,可在低延迟下提供高精度的安全分类,是生产代理式工作流的理想选择。它融合了视觉和语言特征,通过可选的精细类别标签,做出简单的安全/ 不安全决策。开发者可通过关键字快捷开关在快速二进制分类和完整分类报告之间进行选择,从而支持低延迟路径和更深入的检查。
在一套多模态、多语种安全基准测试中,Nemotron 3 Content Safety 的准确率约为 84%,在相同任务中的表现优于替代安全模型,同时将延迟保持在足够低的水平,以便在生产线中进行在线审核。
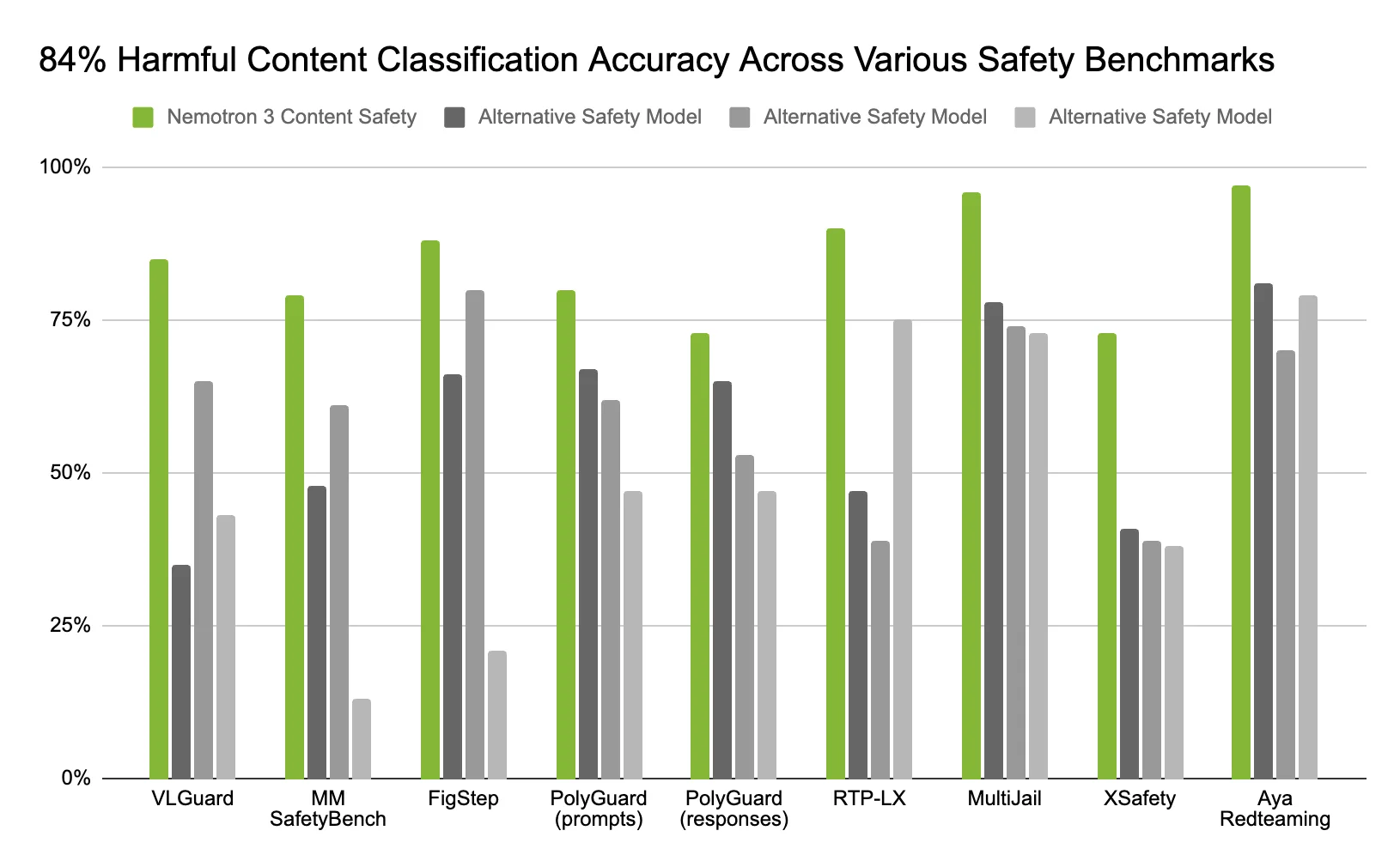
该模型使用与 Aegis 1 – 3 相同的 23% 类别分类,涵盖了诸如仇恨、骚扰、暴力、性内容、窃和未经授权的建议等类别。该模型基于高质量的 Aegis 数据集和经过标注的人类真实图像 (而不是主要基于合成数据) 进行训练,在其 12 种受支持的语言中,该模型在多模态基准测试中表现出色,具有坚实的零样本泛化能力。
使用 Nemotron 3 VoiceChat 进行自然对话
传统的语音 AI 依赖于级联流程、自动语音识别 (ASR) 、大语言模型 (LLM) 和文本转语音 (TTS) ,所有这些都会带来延迟、复杂性和多个故障点。
Nemotron 3 VoiceChat 是一个 120B 参数的端到端语音模型,适用于全双工实时对话式 AI,目前处于抢先体验阶段。与层叠式堆栈不同,VoiceChat 在统一的流式传输 LLM 架构中直接分析音频输入并生成音频输出。使用此单一模型可消除多模型编排。VoiceChat 基于 Nemotron Nano v2 LLM 主干以及 Nemotron 语音 (Parakeet 编码器) 和 TTS 解码器构建,可提供自然、可中断、低延迟的对话。
该模型处于抢先体验阶段,已进入人工分析语音转语音排行榜最吸引人的右上角象限。下图绘制了对话动态与语音推理性能的对比,其中 Nemotron 3 VoiceChat 位于突出显示的右上角象限,以及 NVIDIA PersonaPlex (一个全双工、7B 参数的研究模型) 。这意味着开发者不仅能快速响应转变行为,而且还能对音频进行强有力的推理;这两者对于必须听起来自然并坚持任务的助手来说都至关重要。
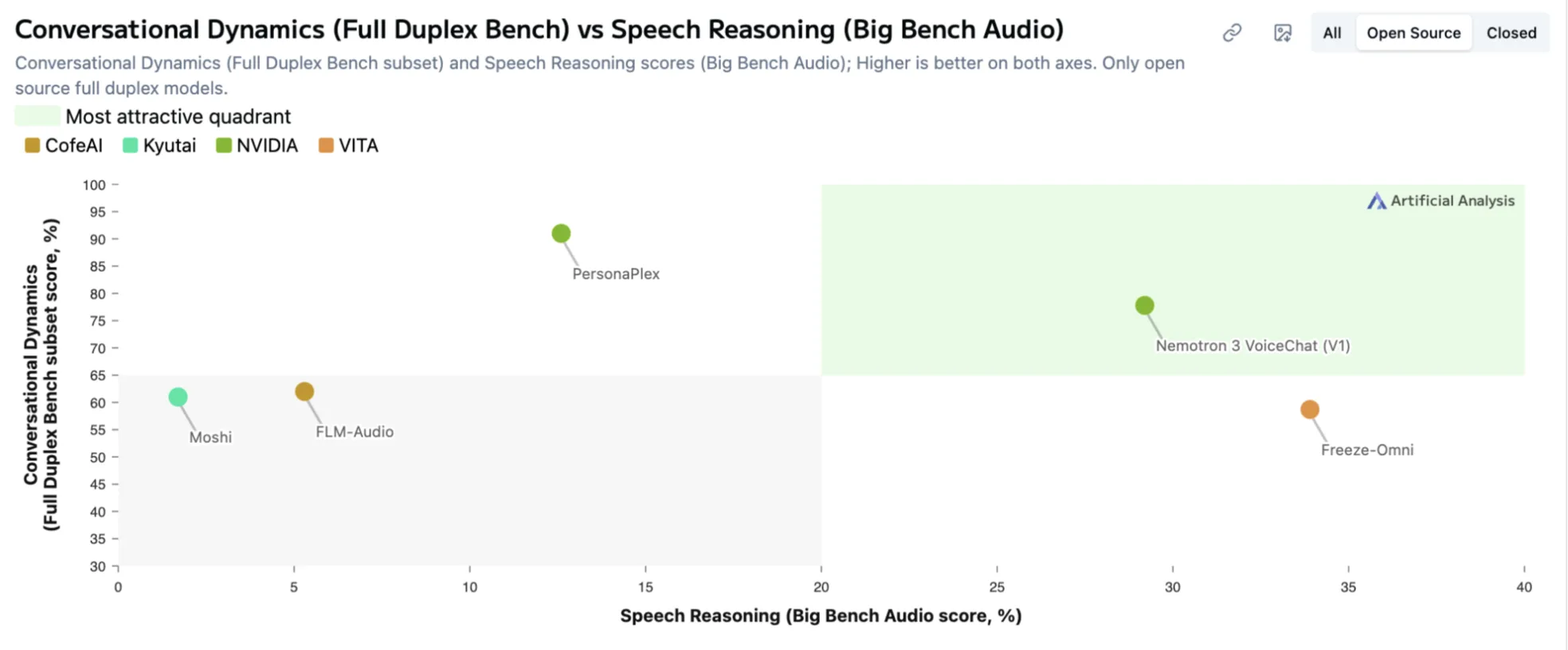
借助精简的端到端流程,VoiceChat 的目标是实现低于 300 毫秒的端到端延迟,比实时音频块的处理速度快 80 毫秒。对于医疗健康、金融服务、电信、游戏等行业的对话式智能体而言,单一模型意味着故障点更少,技术欠款更少,部署更轻松。
使用 NVIDIA Nemotron 3 Omni 了解世界
代理式系统越来越需要理解不同格式的现实世界数据,包括视频、音频、文档、用户界面屏幕和各种模式的推理。现有解决方案要么是闭源解决方案,要么在全球企业部署中面临合规性挑战。
NVIDIA Nemotron 3 Nano Omni 是首款开放、生产就绪的原生全理解基础模型,可通过音频转录增强高上下文视频推理。Nano Omni 由 NVIDIA Nemotron 语音 (Parakeet 编码器) 、采用 Nemotron 3 Nano 语言主干的先进光学字符识别 (OCR) 推理,以及 NVIDIA 首款用于真实代理式应用的 GUI 训练系统提供支持。
该架构使用 3D 卷积层 (Conv3D) 高效处理视频中的时间空间数据,而高效视频采样 (EVS) 通过识别和剪枝时间静态块,以相同的计算成本处理更长的视频。请持续关注此模型的版本更新。
借助 Llama Nemotron Embed VL 和 Rerank VL 优化多模态搜索
代理式 RAG 工作流依赖于从检索到生成的证据,而不仅仅是提示。但是,企业数据存在于包含图表、扫描合同、表格和幻灯片的 PDF 中,而纯文本检索完全忽略了这些格式。
Llama Nemotron Embed VL 和 Llama Nemotron Rerank VL 是紧凑的多模态模型,可实现准确的视觉文档检索,同时与标准向量数据库兼容。在 ViDoRe V3/MTEB Pareto 曲线上,Llama Nemotron Embed VL 占据了 Pareto 前沿阵地,该曲线绘制了检索准确性与在单个 NVIDIA H100 GPU 上每秒处理的词元的对比情况。与开放和商用替代方案相比,它能够在高吞吐量下提供有竞争力或更高的准确性。
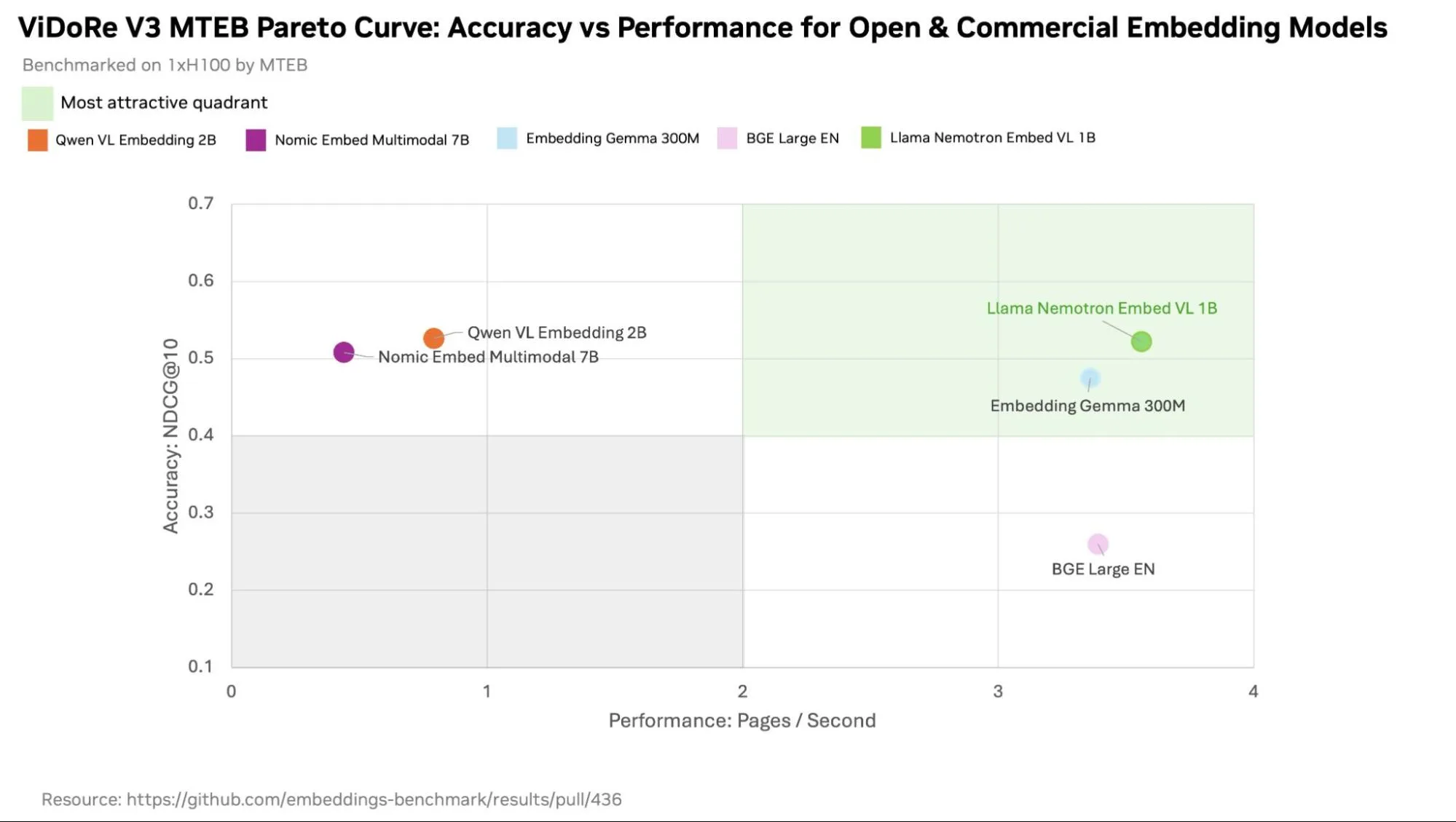
Llama Nemotron Embed VL 是一个 17 亿参数密集嵌入模型,可将页面图像和文本编码为单维向量,并支持 Matryoshka 嵌入。该模型基于 NVIDIA Eagle (一种具有 Llama 3.2 1B 主干和 SigLip2 400M 视觉编码器的前沿视觉语言模型) 构建,它使用对比学习实现查询文档相似性,并使用标准向量数据库实现毫秒延迟搜索。
Llama Nemotron Rerank VL 是一个 17B 参数的交叉编码器重排序器,可对查询页面相关性进行评分。与 Llama Nemotron Embed VL 模型搭配使用时,它通过重新排序检索到的文本块和图像来进一步提高准确性。
使用 NVIDIA NeMo 进行评估和优化
构建生产智能体不仅需要强大的模型,还需要可靠的评估和优化工具。 NVIDIA NeMo 提供用于评估、比较和调整代理式系统的工具:
- NVIDIA NeMo Evaluator, 支持智能体评估,可实现稳健、可重现的基准测试。通过提供标准化的评估设置,开发者可以在一致的条件下对性能进行基准测试、验证输出并比较模型。
- NVIDIA NeMo Agent Toolkit 是一个开源框架,用于端到端分析和优化代理式系统。从 LangChain、AutoGen、AWS Strands 或其他框架中引入智能体,无需更改代码,并了解延迟瓶颈、词元成本和编排开销,以便大规模交付高性能智能体。
开始使用 Nemotron 构建
代理式 AI 是从能够对行动系统做出响应的系统转变。它是一个由模型、工具、内存和护栏组成的协调堆栈,可以规划、执行、评判和适应。如果只是同一个聊天窗口中的一个更大的模型,则不是代理式模型。
Nemotron 系列模型在 NVIDIA 开放模型许可下发布,专为这种多模型现实而构建。Nemotron 3 Super 为长上下文推理和规划提供支持。Nemotron 3 Content Safety 会监控每一步,对多模态输入、检索到的内容和输出进行调节。Nemotron 3 VoiceChat 将这种智能转化为全双工实时对话。Nemotron 3 Nano Omni (即将推出) 为智能体提供涵盖视频、音频、文档、图表和 GUI 的视觉和听觉体验。NeMo 工具为其添加了检索、工具调用、评估和模型评判功能,以便智能体对自己的工作进行评分和改进。
效率是确保生产可行的隐藏要求。真实的智能体会对每个任务进行数十次或数百次模型调用,因此 Nemotron 模型大小合适,并针对吞吐量、延迟和成本进行了优化。此外,由于它们是开放和可定制的,因此团队可以调整行为、调整自己的数据,并将其部署到安全和合规性团队需要的地方。
借助 Nemotron 和 NVIDIA NeMo,您可以为生产代理式系统构建可信、可重复和可扩展的数字助手。
立即开始使用:
- 从 Hugging Face下载 Nemotron 模型和数据集。
- 单击此处预览并访问 Nemotron Super here.
- 在此处访问 Nemotron 3 内容安全 here.
- 单击此处预览并申请抢先体验 Nemotron 3 VoiceChat here.
- 使用 NVIDIA NeMo Evaluator 进行评估
- 使用 NeMo Agent Toolkit 进行优化。
- 在 build.nvidia.com和 OpenRouter上评估 NVIDIA 托管的 API 端点。
通过订阅NVIDIA 新闻并在LinkedIn、X、Discord和YouTube上关注 NVIDIA AI,随时了解NVIDIA Nemotron的最新动态。
访问 Nemotron 开发者页面,获取入门资源。探索开放 Nemotron 模型和数据集,访问 Hugging Face 和 Blueprints,在 build.nvidia.com 上。
在 Nemotron 直播、教程,以及在 NVIDIA 论坛 和 Discord 上与开发者社区互动。