
NVIDIA CUDA 核心计算库 (CCCL) 可为 CUDA 开发者提供令人愉悦且高效的 C++ 和 Python 抽象。它具有以下特性:
- 并行算法– 主机启动的算法,包括排序、扫描和减少,无需为常见操作编写自定义内核
- 协作算法 – 设备端算法,例如块级或线程束级归约或扫描,可简化自定义内核开发
- 语言惯用 CUDA 抽象 – 基本抽象,包括内存分配、资源管理和硬件功能
本文将介绍 CCCL 中的一组新功能,为基本的 CUDA 编程模型概念提供现代化的 C++ 抽象,使 CUDA C++ 开发更安全、更方便。
什么是 CCCL 运行时?
NVIDIA CCCL 运行时是一组新的惯用 C++ API,从 CUDA 13.2 开始提供,可实现核心 CUDA 功能:流管理、内存分配、内核启动等。
熟悉的 NVIDIA CUDA 运行时最初是作为基于 CUDA 驱动程序 API 的便利层开发的。新的 CCCL 运行时旨在成为目标相同的替代方案,但更新的设计与现代 C++ 保持一致。下图 1 显示了上述三个 CUDA API 表面之间的关系:
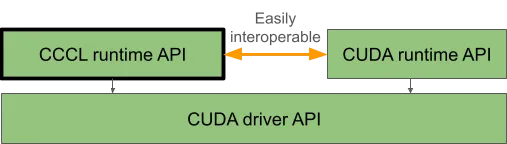
CCCL 运行时是 CCCL 中的报文头 (例如 <cuda/stream>、<cuda/buffer> 和 <cuda/launch>.) 的集合。与传统 CUDA 运行时 API 的 C 源兼容性限制相比,它利用现代 C++ 功能提供更方便、更稳健的抽象。
我们还借此机会将 20 多年来 CUDA 演进的经验教训融入到 API 设计中。即使进行了所有这些更改,CCCL 运行时环境也提供了兼容性助手,让开发者能够逐步采用它,而无需重写使用 CUDA 运行时 API 的周围代码。
随着 CUDA 程序变得越来越复杂,多个库共享设备、流和内存,对 API 的需求也变得越来越迫切。这就是 CCCL 运行时要填补的空间。
代码
这是使用新的 CCCL 运行时 API 实现的经典 vectorAdd 示例。如果您之前编写过 CUDA,则整体结构会很熟悉:专注于不同之处。不要试图一次性理解所有内容,本文的其余部分将介绍此示例,以解释 CCCL 运行时背后的语义和设计选择。
#include <cuda/buffer>
#include <cuda/devices>
#include <cuda/launch>
#include <cuda/memory_pool>
#include <cuda/std/span>
#include <cuda/stream>
struct kernel {
template <typename Config>
__device__ void operator()(Config config,
cuda::std::span<const int> A,
cuda::std::span<const int> B,
cuda::std::span<int> C) {
auto tid = cuda::gpu_thread.rank(cuda::grid, config);
if (tid < A.size())
C[tid] = A[tid] + B[tid];
}
};
int main() {
// 1. Devices and streams
cuda::device_ref device = cuda::devices[0];
cuda::stream stream{device};
// 2. Memory allocation
auto pool = cuda::device_default_memory_pool(device);
int num_elements = 1000;
auto A = cuda::make_buffer<int>(stream, pool, num_elements, 1);
auto B = cuda::make_buffer<int>(stream, pool, num_elements, 2);
auto C = cuda::make_buffer<int>(stream, pool, num_elements, cuda::no_init);
// 3. Kernel launch
constexpr int threads_per_block = 256;
auto config = cuda::distribute<threads_per_block>(num_elements);
cuda::launch(stream, config, kernel{}, A, B, C);
// Make the CPU thread wait for the GPU work to finish.
stream.sync();
return 0;
}
该示例可分为以下三个主要部分:
1. )设备和流
考虑使用 CUDA 运行时 API 创建流,如以下代码段所示。
cudaStream_t stream;
cudaStreamCreate(&stream); // associated with whichever device happens to be "current"
请注意,这会创建一个流,但在调用 cudaStreamCreate 时,流会与当前的设备相关联。仅根据此调用,您便无法知道流与哪个设备相关联。
与使用 CCCL 运行时 API 形成对比,如以下代码段所示。
cuda::device_ref device = cuda::devices[0];
cuda::stream stream{device};
上述代码段展示了如何在特定设备上创建流。第一行说明了核心设计原则:CCCL 运行时使用专用类型而非原始标识符。设备是 device_ref,不是普通整数;流是对象,不是不透明指针。跨 API 的强类型有助于在编译时发现错误,而不是在运行时追踪错误。
第二行说明了另一个原则:使依赖项变得明确。在 CCCL 运行时和 CUDA 运行时 API 中,流与设备相关联。区别在于方式。在这里,cuda::stream 构造函数将设备作为显式参数,而使用 CUDA 运行时 API 时,流与创建流时处于活动状态的设备相关联。
显式依赖关系支持局部推理。您可以读取函数并了解其功能,而无需跟踪全局状态。它们还提高了可组合性:当使用多个库时,它们都不需要在调用之间保存和恢复隐式状态,以避免相互影响。
一个相关的后果是,CCCL 运行时不会公开默认流。管理默认流的含义需要跟踪当前的设备,而这正是我们将要放弃的隐式状态。虽然来自 CUDA 运行时 API 的默认流仍然可以封装到 CCCL 运行时类型中,但不鼓励使用它;任何涉及默认流的内容都应直接通过 CUDA 运行时 API 进行处理。由于 API 中没有默认流,“阻塞流”的概念不再适用,因此所有 CCCL 运行时流都创建为无阻塞流。
资源所有权:拥有类型和引用
仿照 std::string 和 std::string_view 的示例,许多 CUDA 对象在 CCCL 运行时中具有两种类型:拥有类型和具有 _ref 后缀的非拥有类型;cuda::stream 拥有底层 cudaStream_t 句柄,并在其析构函数中销毁该句柄。cuda::stream_ref 在不管理其生命周期的情况下保留该句柄,并且可轻松复制。
_ref 类型对于可与现有代码组合至关重要。如果在其他位置管理流句柄的生命周期,则 cudaStream_t 会隐式转换为 cuda::stream_ref,并且可以使用 .get() 检索原始句柄。要转让所有权,cuda::stream::from_native_handle 将原始句柄包装为拥有类型,然后 .release() 放弃所有权。
void stream_type_example(cudaStream_t handle) {
cuda::stream_ref non_owning{handle};
assert(handle == non_owning.get());
cuda::stream owning = cuda::stream::from_native_handle(handle);
assert(handle == owning.get());
assert(handle == owning.release());
}
同样的模式也适用于事件、内存池和其他 CUDA 对象:cuda::device_ref 没有对应的所有者,因为没有设备状态要拥有。
2. )内存分配
auto pool = cuda::device_default_memory_pool(device);
auto A = cuda::make_buffer<int>(stream, pool, num_elements, 1);
auto B = cuda::make_buffer<int>(stream, pool, num_elements, 2);
auto C = cuda::make_buffer<int>(stream, pool, num_elements, cuda::no_init);
下一节将演示异步分配和初始化设备内存。在这里,我们可以看到下一个设计原则:默认情况下,API 是异步的。CCCL 运行时不按名称区分同步和异步变体,而是使用简单的约定:如果 API 以流作为其第一个参数,则按流顺序运行。我们不打算为 CUDA 运行时 API 中同时包含这两种变体的 API 提供同步对应项。
在实践中,内存分配是最重要的环节。自 CUDA 11.2 (在此解释) 开始,便可通过显存池进行流排序显存管理,而 CUDA 13.0 将其扩展到了托管显存和主机显存。在大多数情况下,内存池化和不太频繁的同步点对于实现最高性能至关重要,并且按流排序的内存管理可与异步编程模型的其余部分自然组合。为了传达这些准则,CCCL 运行时将内存池和流顺序分配作为默认设置。在尚未支持较新内存池类型的旧版 CUDA 版本和平台上,我们提供无流排序的分配作为后备,但计划在池支持通用后将其删除。
在上面的代码段中,我们首先查询给定设备的默认内存池,并将其作为显式参数传递,而不是依赖 cudaMallocAsync 的隐式设备选择。此示例使用默认池 (在可能的情况下应首选) ,但 CCCL 运行时还允许在需要不同的池设置时创建单独的池对象。
然后,使用池引用使用新的 cuda::make_buffer. 创建三个缓冲区。它将流作为其第一个参数,以指示按流排序的操作。每个缓冲区向该流提交三项操作:从指定池分配、初始化,以及最终在缓冲区超出范围时取消分配。
初始化是强制性的,除非使用 cuda::no_init 明确选择退出,就像缓冲区 C 一样,它将被内核覆盖。未初始化的设备内存是难以诊断错误的常见来源,因此我们选择了显式选择退出 ( opt-out) ,而不是默认设置。输入缓冲区 A 和 B 的所有元素分别初始化为 1 和 2。缓冲区也支持其他初始化模式,例如来自另一个缓冲区或范围的初始化模式。
缓冲区生命周期和取消分配
传递给 make_buffer 的流存储在缓冲区内,并用于在缓冲区被销毁时取消分配。这意味着缓冲区通常应容纳与其用法对应的流,以便在取消分配的情况下对计算进行正确排序。稍后可以使用 .set_stream() 更改流,也可以使用 .destroy() 手动触发对特定流的破坏,但在普通情况下,默认行为旨在执行正确的操作。
{
auto pool = cuda::device_default_memory_pool(device);
// Equivalent to cudaMallocFromPoolAsync on the stream, possibly along with initialization pushed into the stream as well. Saves the stream for future deallocation
auto buffer = cuda::make_buffer(allocation_stream, pool, /*... */);
// buffer usage...
}
// Closing bracket will call cudaFreeAsync on allocation_stream, there is also buffer.destroy(which_stream) to keep the behavior explicit
3. )内核启动
struct kernel {
template <typename Config>
__device__ void operator()(Config config,
cuda::std::span<const int> A,
cuda::std::span<const int> B,
cuda::std::span<int> C) {
auto tid = cuda::gpu_thread.rank(cuda::grid, config);
if (tid < A.size())
C[tid] = A[tid] + B[tid];
}
};
// ...
constexpr int threads_per_block = 256;
auto config = cuda::distribute<threads_per_block>(num_elements);
cuda::launch(stream, config, kernel{}, A, B, C);
最后一节演示使用 cuda::launch 在 GPU 上配置和启动核函数。
cuda::launch 接受三组参数:
- 要运行的流
- 对线程层次结构 (线程块和网格大小) 以及其他启动选项进行编码的配置对象。在这里,
cuda::distribute会创建一个配置,用于启动分组为threads_per_block块的至少num_elements线程。这将取代许多 CUDA 开发者熟悉的(N + block_size - 1) / block_size常见模式 - 内核及其参数
编译时配置流
cuda::launch 最新颖的方面是如何通过类型系统将编译时信息从主机启动站点移动到设备代码中。例如,请注意块大小如何作为模板参数提供给 cuda::distribute,这意味着它是以配置对象的类型进行编码的。
当内核接受该配置作为其第一个参数时,cuda::launch 会自动通过该参数。在核函数内部,当我们计算网格内调用线程的 rank 时,可以使用此静态信息:
auto tid = cuda::gpu_thread.rank(cuda::grid, config);
由于块大小在编译时已知,因此秩计算只能使用 x 维度,并完全跳过运行时块大小查询。这是一个简单的示例,但该机制进行了泛化。CCCL 文档还展示了更多使用配置嵌入式信息来专门化设备代码的案例。有时,内核实现会对网格和/ 或块的确切形状做出假设。通过在配置对象中编译时间信息,核函数开发者可以实施检查,确保在这些情况下核函数与调用点保持一致。
template <typename Config>
__global__ void kernel(Config conf) {
// Make sure the block is one dimensional with 256 threads
static_assert(cuda::gpu_thread.static_dims(cuda::block, conf).x == 256);
static_assert(cuda::gpu_thread.static_dims(cuda::block, conf).y == 1);
static_assert(cuda::gpu_thread.static_dims(cuda::block, conf).z == 1);
}
核函子
您可能已经注意到,内核是具有 __device__ operator() 而非 __global__ function 的结构体。虽然 cuda::launch 支持现有的 __global__ 函数,但我们还引入了核函数:具有 __device__- 带标注的调用运算符的类型。实际优势在于,模板参数可自动推理,而与 cuda::launch 一起使用的 __global__ 函数则需要显式实例化。
template <typename T>
__global__ void kernel_function(T input) {
// body ...
}
struct kernel_functor {
template <typename T>
__device__ void operator()(T input) {
// body ...
}
};
// explicit template instantiation is required with a __global__ function
cuda::launch(stream, config, kernel_function<int>, 42);
// deduction from arguments for a functor with __device__ call operator
cuda::launch(stream, config, kernel_functor{}, 42);
这就是编译时配置流的运作方式。config 模板参数是从 cuda::launch 传递的配置对象中推断出的。核函子还涵盖设备 lambda,并具有 CCCL 文档 中所述的其他功能。
自动参数转换
cuda::buffer 拥有其底层分配,但 CUDA 核函数只能接受可轻松复制的参数。将缓冲区传递给 cuda::launch 后,系统会自动将其转换为 cuda::std::span。无需手动构建 span 或提取原始指针。内核签名反映了数据在设备端的实际使用方式。
下一步是什么
本文介绍了 CCCL 运行时背后的核心理念:显式依赖项、强类型、默认异步 API,以及与现有 CUDA 代码的清晰互操作性。但一个示例演示只能展示这么多内容。
CCCL 文档更详细地介绍了每个 API,包括 其他缓冲区初始化模式、事件管理、数据移动,以及高级内核启动功能 (如 动态共享内存 和 其他启动属性)。CCCL 运行时 API 在 CCCL 3.2 及更高版本 (随附 CUDA 工具包 13.2 及更高版本) 中提供。有关每个 API 可用性的详细信息,请参阅 CCCL 文档。我们期待在您试用期间收到您的反馈。