
训练 LLM 需要定期检查点。这些模型权重、优化器状态和梯度的完整快照将保存到存储中,以便在中断后恢复训练。在规模上,这些检查点变得庞大 ( 70B 模型为 782 GB) 且频繁 (每隔 15-30 分钟) ,生成的行项目是训练预算中最大的项目之一。大多数 AI 团队都在追求 GPU 利用率、训练吞吐量和模型质量。几乎没有人知道检查点会对他们造成何种影响。
这是一项代价高昂的疏忽。仅在 128 个 NVIDIA Blackwell GPU 上,405B 模型的同步检查点开销每月就高达 20 万美元。通过引入使用约 30 行 Python 实现的无损压缩步骤,我们可以每月降低 56000 美元的存储成本。混合专家模型 (MoE) 可以节省更多成本。在这篇博客文章中,我们将详细介绍如何进行计算,以及 NVIDIA nvComp 如何提高检查点效率。
在单个检查点内
1000 多个 GPU 规模的硬件中断并不罕见。Meta 报告称,在使用 16384 个 NVIDIA H100 GPU 进行 Llama 3 训练的 54 天中,有 419 次意外中断 (约每 3 小时 1 次) 。这就是大多数团队每 15-30 分钟检查一次的原因;这是负载基础设施,而不是可选的开销。
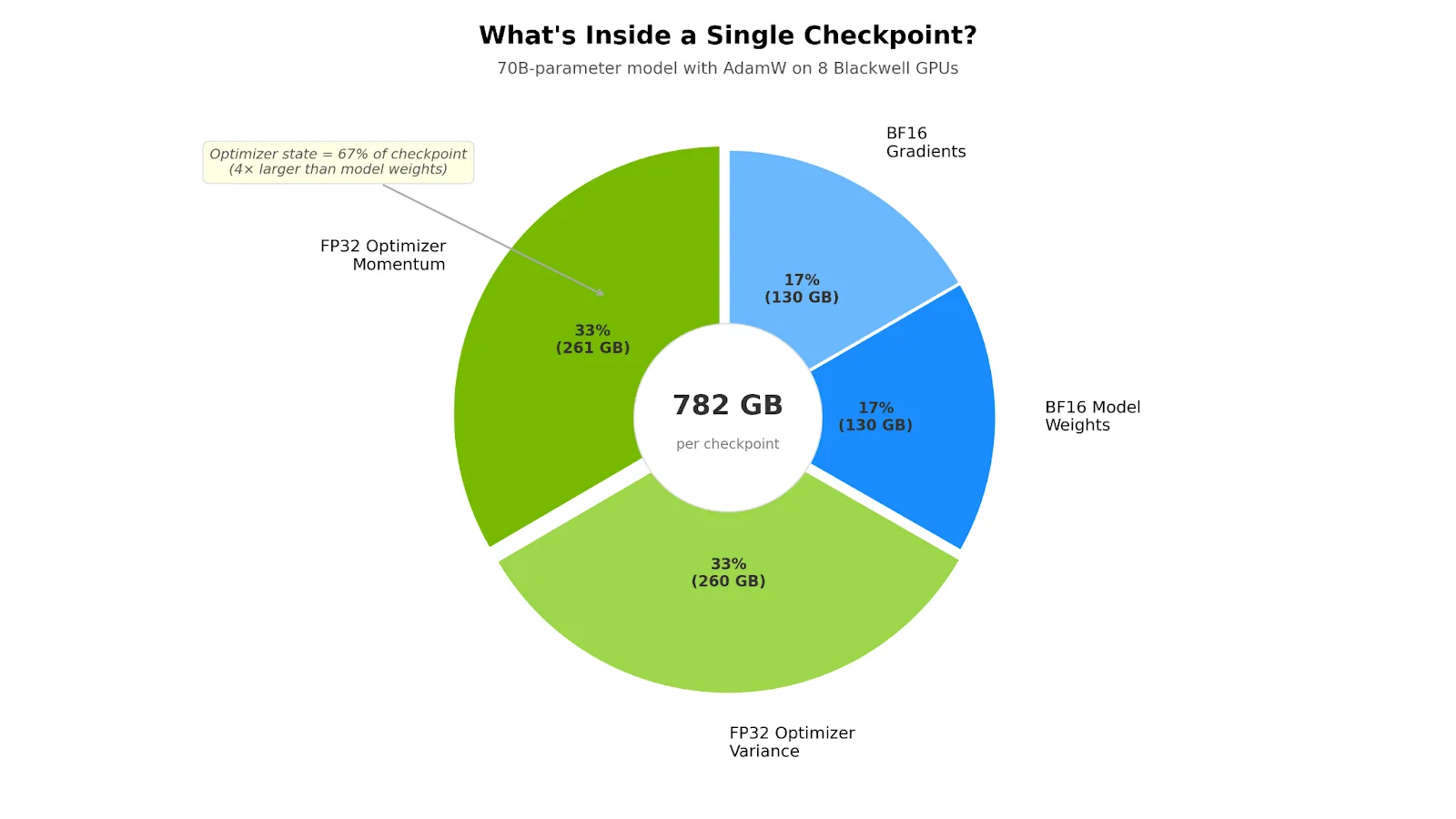
| 组件 | 尺寸 | 目录 |
| 模型权重 (BF16) | 130 GB | 700 亿参数 = 2 个字节 |
| 优化器状态 ( FP32 动量+ 方差) | 521 GB | 70B 参数 = (4 × 4) 字节 |
| 梯度 (BF16) | 130 GB | 与权重相同的形状 |
| 每个检查点总计 | 782 GB |
第一次看到这种故障的人就会大吃一惊。优化器状态 (即 AdamW 的第一和第二时刻估计值,均存储在 FP32 中) 比模型权重大 4 倍。它是每个检查点的主要部分,也是它们比部署的模型大得多的原因。
每 30 分钟设置一次检查点,这是容错的标准做法,即每天 48 个检查点。超过一个月的持续培训:
782 GB × 48/天 × 30 天每月向存储写入 1.13 PB
这是大多数团队所错过的部分。在每个同步检查点写入期间,所有 8 个 GPU 都处于完全空闲状态。没有任何内容与 Checkpoint Save 重叠,训练循环会阻塞,直到最后一个字节到达存储。
以 4.40 美元/ GPU/ 小时 (按需 Blackwell GPU 云定价的代表) 和 5 GB/s 的共享存储吞吐量 (通常用于 Lustre 或 GPFS 而非 InfiniBand) 计算,我们通过数学计算来计算这些等待期间 GPU 空闲的成本:
- 写入每个检查点的时间:782 GB/ 5 GB/ 秒 = 156.4 秒 (约 2.6 分钟)
- 每月总等待时间:156.4 秒 48/ 天 30 天 225216 秒 62.6 小时
- 这些等待期间闲置 GPU 的成本:62.6 小时 8 块 GPU 4.40 美元/ GPU/ 小时*2203 美元/ 月
在计算仓储费之前,同步检查点的等待时间总计高达 2200 美元/ 月。
将其扩展为 64 GPU 集群,每月成本将超过 17500 美元。在使用 128 个 GPU 训练 405B 模型时,空闲成本超过 20 万美元/ 月。空闲 GPU 成本在存储费用中占据了一个数量级的主导地位。
异步检查点可以缓解部分问题。但是,框架支持仍然日趋成熟且未得到广泛采用,而且管理内存水印仍然是一项挑战。一种易于使用的辅助技术是检查点压缩,由于冷启动本质上是串行的,因此它还能减少状态恢复时的冷启动时间。
NVIDIA nvCOMP 引入了 GPU 加速的压缩
核心理念很简单。在检查点离开 GPU 显存之前对其进行压缩。无 CPU 往返。无需额外的数据移动。数据已存储在 GPU 上,因此我们可以将其压缩到 GPU 上。
NVIDIA nvCOMP 是一个 GPU 加速的无损压缩库,可以做到这一点。通过提供一个支持标准算法 (如 ZStandard (ZSTD)) 和高度优化的 GPU 特定格式 (如 GAN) 的单一库,它可以在本地解决设备上的数据瓶颈问题。开发者可以轻松地将高吞吐量压缩直接集成到其 Python 工作流 (例如 PyTorch 或 TensorFlow) 中。
测量的检查点压缩比
我们对两个模型架构 (密集 Transformer 和混合专家模型) 进行了 50 步微调,保存了完整的训练检查点 (权重+ AdamW 优化器状态+ 梯度) ,并在 NVIDIA H200 和 Blackwell GPU 上使用 nvCOMP 压缩了每个组件。压缩比取决于数据,而非硬件,它们在所有 GPU 上都是相同的。
ZSTD 是 Meta 开发的一种广泛采用的通用压缩算法,可在强压缩比与合理速度之间取得平衡。它与 Linux 命令行上 ZSTD 背后的算法相同,广泛用于数据库、文件系统和数据工作流。非对称数字系统 (ANS) 是 nvCOMP 作为 GPU 原生编解码器 (gAN) 实现的一种现代编码技术,该技术已针对原始吞吐量进行了优化。两者都是无损的,并利用 1B/ 2B 词分布 (编码) 中的统计模式,而不仅仅是匹配重复的字节序列。
关键的区别在于权衡取舍。ZSTD 压缩率略高 (在我们的基准测试中,比 ANS 高 1-2%) ,但在 Blackwell GPU 上压缩率约为 16-19 GB/s。ANS 以 10 倍的吞吐量 (A1-190GB/s) 实现了几乎相同的比率。如下所示,选择哪种取决于存储的速度。
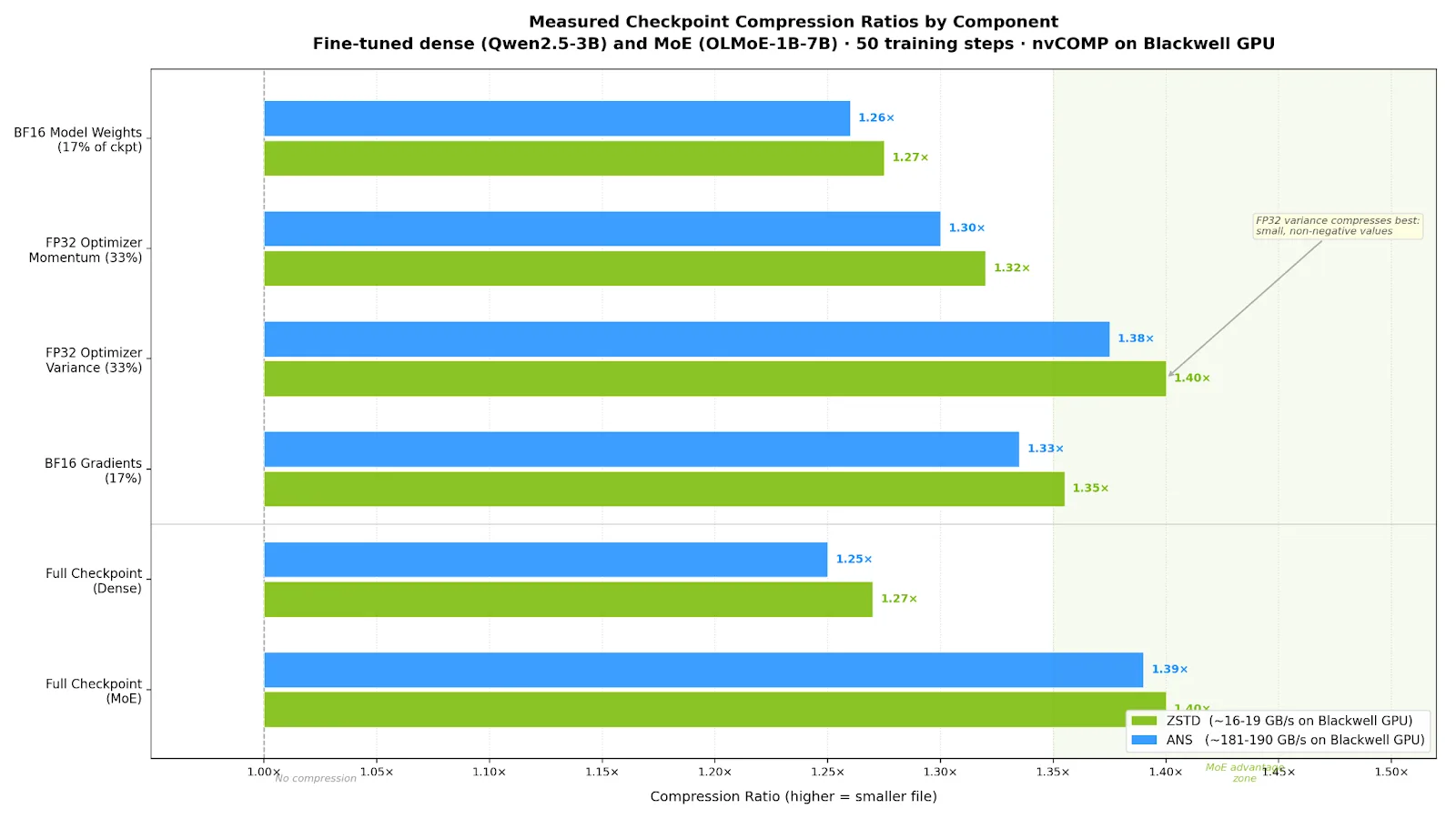
| Checkpoint 组件 | Ckpt 的数量 | ZSTD | GAN | 为什么 |
| BF16 模型权重 | 17% | 1.27-1.28 及以上 | 1.25-1.27+ | 经过高训练的浮点运算 |
| FP32 优化器动量 | 33% | 1.25-1.39% | 1.23-1.37 | 移动平均线中的共享指数字节 |
| FP32 优化器方差 | 33% | 1.32-1.48% | 1.30-1.45 及以上 | 非负、小的值 |
| BF16 梯度 | 17% | 1.25-1.46% | 1.23-1.44% | 依赖于架构的稀疏 |
| 完整检查点 (密集) | 100% | 增加 1.27% | 增加 1.25% | 密集:无自然稀疏 |
| 完整检查点 (MoE) | 100% | 增加 1.40% | 增加 1.39% | MoE:专家路由创建梯度稀疏 |
范围反映了关键发现,即压缩依赖于模型架构而非硬件。并非所有压缩算法都适用于浮点张量。LZ4 和 Bitcomp 等字节级编解码器会寻找重复的字节序列,例如在文档中查找重复的词。但经过训练的神经网络参数在字节级别上看起来本质上是随机的,因此这些编解码器几乎找不到任何可压缩的内容 (在我们的基准测试中,在密集检查点上约为 1.00%) 。
ZSTD 和 ANS 使用编码,该编码利用统计模式来确定某些字节值的出现频率,即使没有精确的序列重复。这就是为什么它们在处理相同数据时可实现 1.25-1.40 倍的性能,而字节级编解码器则毫无效果。在这两者之间,ZSTD 提供的比率略高 (在我们的基准测试中高出 1-2%) ,而 ANS 在 10 倍的压缩吞吐量上与之相当。正如我们将展示的那样,当存储速度加快时,这种权衡至关重要。
- 密集 Transformer 模型( Llama、GPT、Qwen) :所有参数都参与每次向前传递。* 0* 精确零** 1.25* ANS,* 1.27* ZSTD。
- MoE 模型( Mixtral、DeepSeek、OLMoE) :每个词元只有部分专家激活。12-14 精确零 =+ 1.39 ANS,+ 1.40 ZSTD。
我们的基准测试使用 BF16 权重和 FP32 优化器状态 (AdamW) ,这是当今大多数大规模训练的标准。使用 FP8 训练 (例如,使用 NVIDIA Transformer 引擎) 的团队将看到更低的压缩比,因为降低精度的数据会带来更高的和更少的统计冗余,以便利用无损压缩。在 FP4 (NVFP4) 下,量化已经消除了大部分冗余,无损压缩提供的额外优势可忽略不计 (< 5%) 。然而,无论权重精度如何,优化器状态都保持为 FP32,这正是检查点大小和压缩节省的大部分来源。
数学运算:nvCOMP 如何节省资金
使用经测量的 ZSTD 比率为 1.27%的 70B 密集模型:
- 不使用 nvCOMP:以 5 GB/ 秒的速度将 782 GB 写入磁盘*156 秒GPU 等待
- 使用 nvCOMP ZSTD ( 1.27 倍):以约 16 GB/ 秒 (约 49 秒) 的速度压缩 782 GB,以 5 GB/ 秒 (123 秒) 的速度写入 616 GB约 123 秒GPU 等待
为什么 49 秒的压缩时间消失了?因为压缩和存储写入可以通过流水线进行:当一个数据块写入磁盘时,下一个数据块会在 GPU 上进行压缩。只要编解码器的压缩速度快于存储能够吸收输出的速度,压缩步骤就会完全隐藏在写入之后,仅 GPU 等待时间就等于写入时间。在 5 GB/s 的共享存储下,16 GB/s 的 ZSTD 速度比写入快 3%,因此压缩完全重叠。等待时间从 156 秒缩短到 123 秒,文件数量减少了 21%,每个检查点的等待时间提高了 33 秒。在一个月内:空闲时间减少 48+ 30 = 47520 秒,缩短了 13+ 小时。1.40% 的 MoE 效果更好:体积缩小 29%,速度加快 44 秒,再生时间缩短 17%。
当存储速度加快时,编解码器吞吐量至关重要
您的存储速度取决于基础设施:对于共享网络文件系统 ( Lustre、GPFS、NFS) ,2-10 GB/s;对于使用本地 NVMe 的 GPUDirect Storage (GDS) ,15-50+ GB/s。
在更快的存储中,编解码器吞吐量决定了压缩是否有助于:
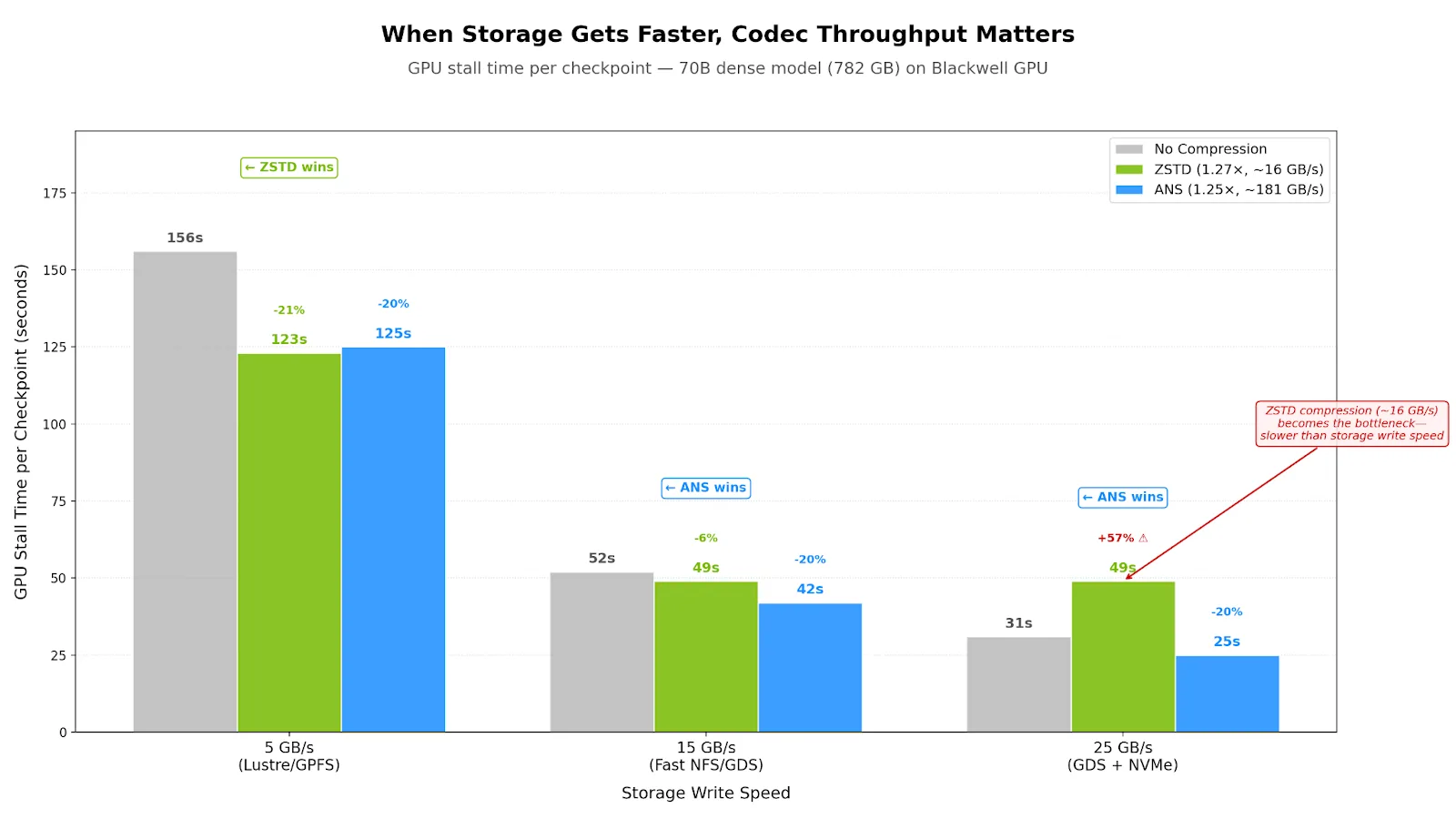
| 存储速度 | 无压缩 | ZSTD ( 1.27+,约 16 GB/ 秒) | ANS ( 1.25%,约 8.1 GB/ 秒) | 获胜者 |
| 5 GB/ 秒 | 156 秒 | 123 秒 (约 21%) | 125 秒 (约 20%) | ZSTD |
| 15 GB/ 秒 | 52 秒 | 49 秒 (小于 6%) | 42 秒 (约 20%) | ANS |
| 25 GB/ 秒 | 31 秒 | 49 秒 (+ 57%) ** | 25 秒 (< 20%) | ANS |
为说明问题,我们比较了 Blackwell GPU 上 70B 密集型模型 (782 GB) 的检查点写入时间、三种存储速度。由于压缩和写入是管道化的 (一个块进行压缩,而上一个块写入磁盘) ,GPU 的总等待时间等于哪个阶段较慢的时间:管道化等待 = 最大 (压缩时间,写入时间) 。
在 Blackwell GPU 上表 3 ( 16 GB/s) 中,ZSTD 的压缩步长成为瓶颈,等待时间 增加。ANS 的传输速率为 181-190 GB/s,永远不会撞到这道墙。在采用 64 个 Blackwell GPU 时,以 25 GB/s 的速度运行时,ANS 网络 = ~$2,800/ 月,而 ZSTD 网络仅 = ~$240/ 月。对于共享文件系统 ( 5-10 GB/s) ,ZSTD 仍然是正确的默认设置。对于速度超过 15 GB/s 的 GDS/ 高性能存储,ANS 是明显的赢家。
图 4 中测量的节省量假设 GPU 等待时间减少 = 存储为 0.14 美元/ GB/ 月、96 个保留检查点和 5 GB/s 共享存储:
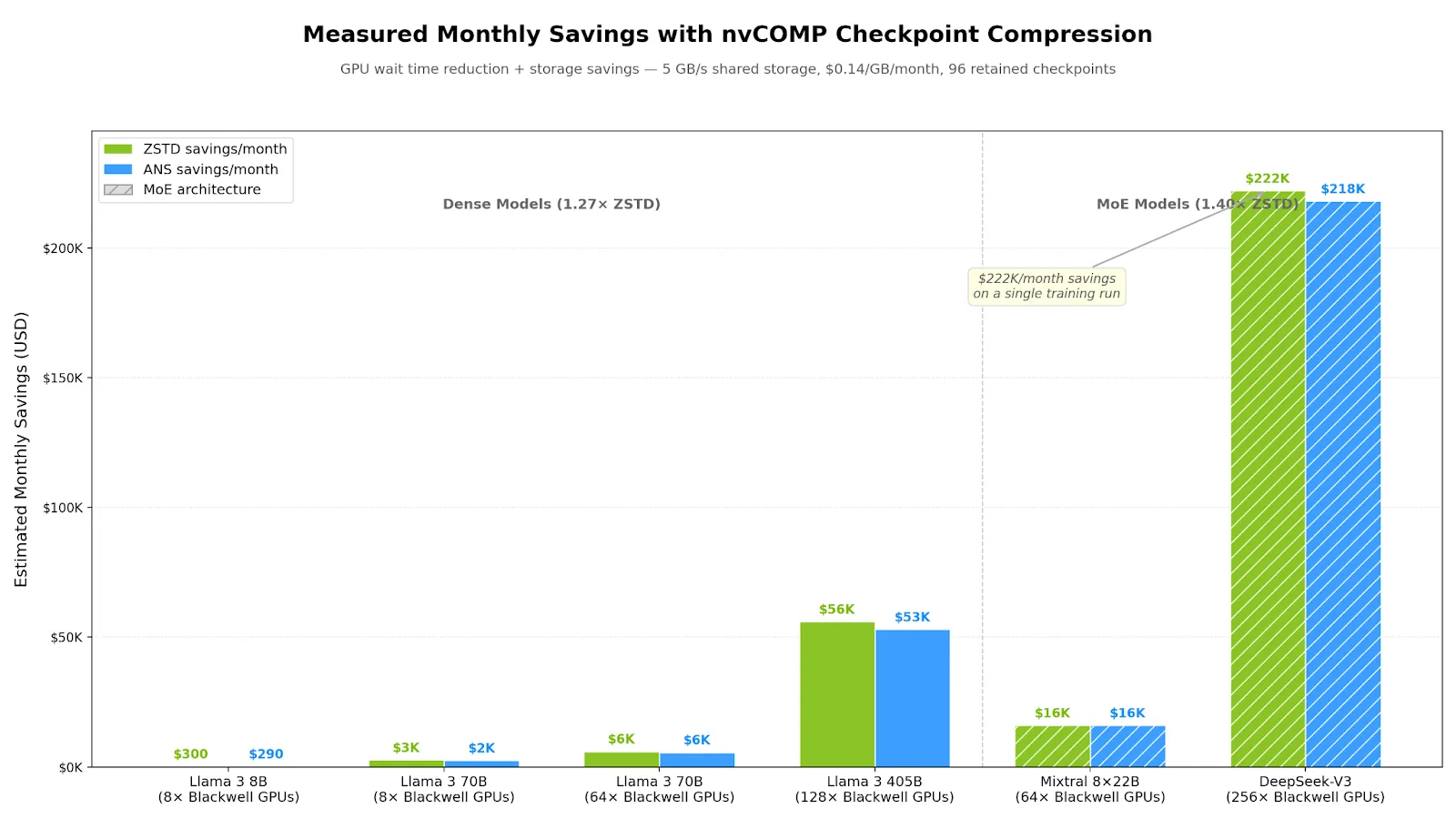
密集模型 (在 Qwen2.5-3B 上测量) :
| 模型 | GPU | Ckpt | ZSTD ( 1.27%) | ANS ( 1.25%) |
| Llama 3 8B | 8 块以上 Blackwell GPU | 89 GB | 70 GB/ 约 300 美元/ 月 | 71 GB/ 约 290 美元/ 月 |
| Llama 3 70B | 8 块以上 Blackwell GPU | 782 GB | 616 GB/+ 2700 美元/ 月 | 626 GB/ 约 2500 美元/ 月 |
| Llama 3 70B | 64 个以上 Blackwell GPU | 782 GB | 616 GB/ 6000 美元/ 月 | 626 GB/ 约 5600 美元/ 月 |
| Llama 3 405B | 128 多个 Blackwell GPU | 4529 GB | 3566 GB/ 56000 美元/ 月 | 3623 GB/ 53000 美元/ 月 |
MoE 模型 (在 OLMoE-1B-7B 上测量) :
| 模型 | GPU | Ckpt | ZSTD ( 1.40%) | ANS ( 1.39%) |
| Mixtral 8x22B ( 141B) | 64 个以上 Blackwell GPU | 1575 GB | 1125 GB/+ 16000 美元/mo | 1133 GB/+ 16000 美元/mo |
| DeepSeek-V3 ( 671B) | 256 多个 Blackwell GPU | 7490 GB | 5350 GB/ 222000 美元/ 月 | 5389 GB/+ 218000 美元/ 月 |
节省的资源会随着模型大小 (检查点越大,压缩次数就越多) 和 GPU 数量的增加而增加 (等待时间中的 GPU 空闲时间越多,等待时间每秒产生的成本就越高) 。第二个因素是这种大规模部署尤为残酷的原因 – 256 个空闲的 Blackwell GPU 每小时的成本为 1126 美元。每一秒你掉一个检查点都能省钱。
该行业正在转向 MoE 架构 (如 DeepSeek-V3、Mixtral 和 Grok) ,这些架构可生成更大、更可压缩的检查点。压缩不再是一种好方法,添加几行 Python 代码可以节省成本。
集成:约 30 行 Python 代码
集成工作量微乎其微。以下是 torch.save/torch.load 的直接替代品:
# CUDA 13.x (Blackwell):pip install nvidia-nvcomp-cu13 cupy-cuda13x# CUDA 12.x (Hopper):pip install nvidia-nvcomp-cu12 cupy-cuda12x |
import torchimport cupy as cpfrom nvidia import nvcompcodec = nvcomp.Codec(algorithm="Zstd") # or "ANS" for near-ZSTD ratios at 10× throughputdef _compress_state(obj): """Recursively compress GPU tensors in a state dict tree.""" if isinstance(obj, torch.Tensor) and obj.is_cuda: flat = obj.contiguous().reshape(-1).view(torch.uint8) # torch → cupy (zero-copy) → nvcomp (zero-copy) → GPU compress compressed = codec.encode(nvcomp.as_array(cp.from_dlpack(flat))) # .cpu() → bytes(): official nvcomp pattern (Cell 15 of nvcomp_basic) return {"__nvcomp__": True, "data": bytes(compressed.cpu()), "shape": list(obj.shape), "dtype": str(obj.dtype)} if isinstance(obj, dict): return {k: _compress_state(v) for k, v in obj.items()} if isinstance(obj, (list, tuple)): return type(obj)(_compress_state(v) for v in obj) return objdef _decompress_state(obj, device): """Recursively decompress nvCOMP tensors back to GPU.""" if isinstance(obj, dict) and obj.get("__nvcomp__"): # codec.decode(bytes): official nvcomp pattern (Cell 27 of nvcomp_basic) decompressed = codec.decode(obj["data"]) # nvcomp → cupy (zero-copy) → torch (zero-copy), stays on GPU dtype = getattr(torch, obj["dtype"].replace("torch.", "")) return torch.from_dlpack(cp.asarray(decompressed)).view(dtype).reshape(obj["shape"]) if isinstance(obj, torch.Tensor): return obj.to(device) if isinstance(obj, dict): return {k: _decompress_state(v, device) for k, v in obj.items()} if isinstance(obj, (list, tuple)): return type(obj)(_decompress_state(v, device) for v in obj) return objdef save_compressed_checkpoint(model, optimizer, path): state = {"model": model.state_dict(), "optimizer": optimizer.state_dict()} torch.save(_compress_state(state), path)def load_compressed_checkpoint(path, device="cuda"): return _decompress_state( torch.load(path, map_location="cpu", weights_only=True), device) |
将 torch.save 替换为 save_compressed_checkpoint,将 torch.load 替换为 load_compressed_checkpoint。
就是这样。无需更改训练循环、模型代码或优化器配置。
如果您使用的是带有自定义 Checkpoint Hook ( DeepSpeed、Megatron) 的训练框架,同样的模式也适用。浏览状态 dict,压缩 GPU 张量,然后序列化。
对于使用 NVIDIA GPUDirect Storage (GDS) 的团队来说,这是一条更快的路径。nvCOMP 可以直接压缩到 GDS 缓冲区,将压缩数据直接从 GPU 显存写入 NVMe 存储。零 CPU 占用。
NVIDIA Blackwell 解压缩引擎
NVIDIA Blackwell GPU 包含专用的 Blackwell 解压缩引擎 (DE) ,可在零 SM 开销的情况下,以高达 280 GB/s 的速度解压缩 LZ4、Snappy 和 Deflate。但是,字节级编解码器在浮点张量上的性能约为 1.00 倍。对于检查点压缩,SM 上基于的编解码器 ( ANS 和 ZSTD) 可节省大量成本。在恢复期间,GPU 处于空闲状态,等待数据恢复训练。SM 可用性不受限制,SM 上的 ANS 可提供相当的吞吐量 (247-264 GB/s) ,同时生成更小的文件。
开始使用
检查点压缩是您可以添加到训练流程中的高投资回报率优化之一,也是最简单的优化之一:
- 安装 nvCOMP:
pip install nvidia-nvcomp-cu13( Blackwell) 或 pip install nvidia-nvcomp-cu12( Hopper) - 立即试用:将此博文中的
save_compressed_checkpoint / load_compressed_checkpoint函数放入训练循环中。无需其他更改。 - 探索代码:示例和基准测试GitHub。
- 阅读文档:nvCOMP 文档
- 深入了解:对于使用 GPUDirect Storage 的团队,nvCOMP 可以直接压缩为 GPU 缓冲区,由 GDS 写入 NVMe,且无需 CPU 占用。有关详情,请参阅:
检查点文件是训练工作流中最大的文件。压缩它们。