
2026 年 3 月,三个 LLM 智能体生成了超过 60 万行代码,运行了 850 个实验,并帮助确保在 Kaggle Playground 比赛中获得冠军。
在现代机器学习竞赛中取得成功越来越取决于您生成、测试和迭代想法的速度。LLM 代理与 GPU 加速相结合,极大地压缩了这一循环。
从历史上看,以下两个瓶颈限制了这一实验:
- 为新实验编写代码的速度。
- 执行这些实验的速度。
NVIDIA cuDF、NVIDIA cuML、XGBoost 和 PyTorch 等 GPU 和库在很大程度上解决了第二个问题。LLM 智能体现在解决了第一个问题,即解锁快速迭代实验的新规模。
这篇博文介绍了我如何使用 LLM 智能体加速发现性能出色的表格数据预测解决方案。
案例研究:Kaggle Playground 客户流失预测
2026年3月举行的Kaggle Playground竞赛要求参赛者预测电信客户的流失率,模型性能以曲线下面积(AUC)作为评估标准,预测最准确的方案将获得胜利。
首要的解决方案是从 850 个模型中选择一个包含 150 个模型的四层堆栈。
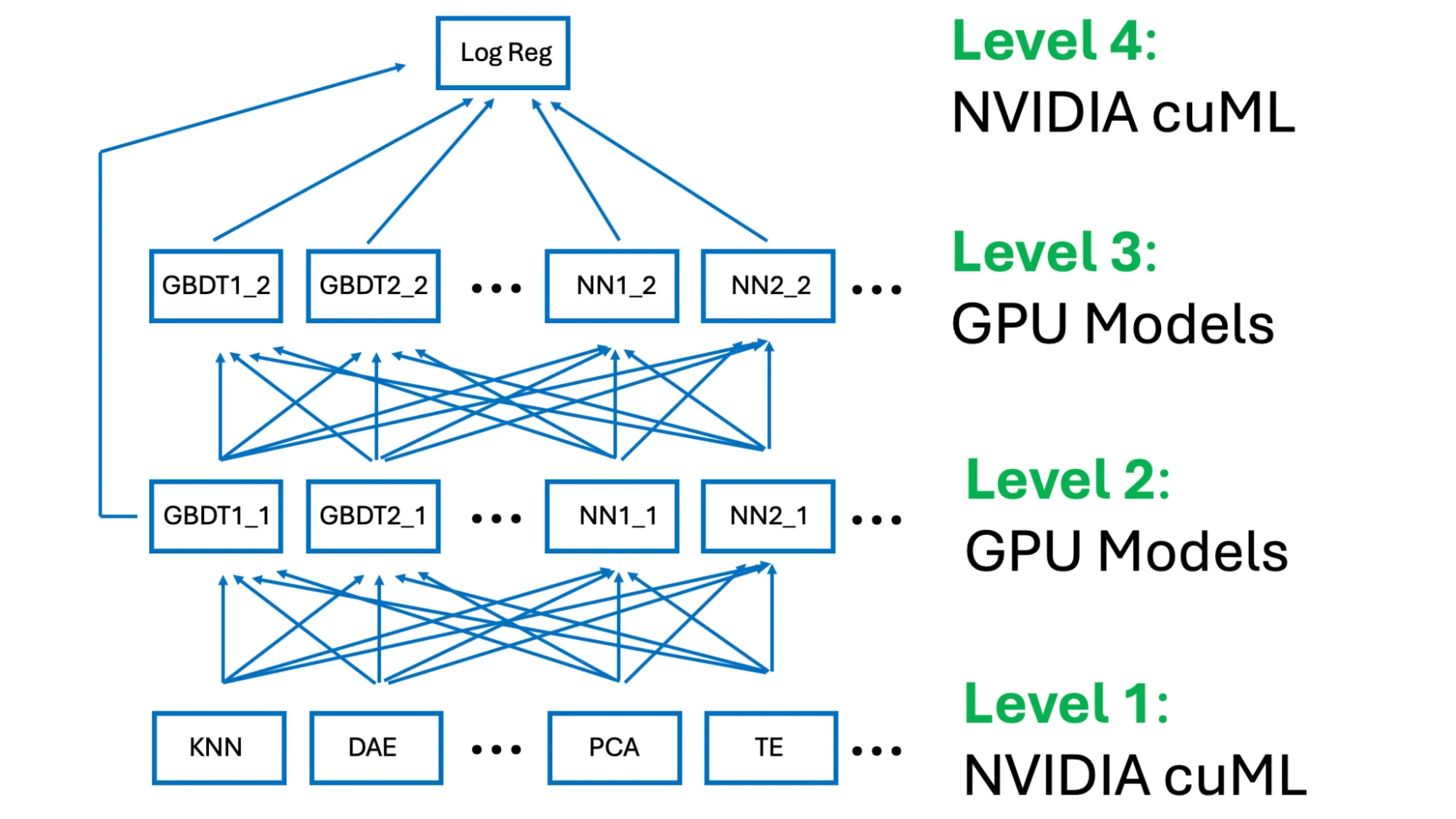
引导式 LLM 智能体工作流
在此表格形式的数据竞赛中,我引导 LLM 代理遵循上一篇博客文章中描述的 Kaggle Grandmaster 剧本。
具体来说,LLM 智能体遵循一个工作流程:从探索性数据分析 (EDA) 开始,然后构建基准,然后进行特征工程,最后通过爬坡和堆叠来组合模型。
该解决方案在一个人在环工作流中使用了多个 LLM 智能体,包括 GPT-5.4 Pro、Gemini 3.1 Pro 和 Claude Opus 4.6。
第 1 步:LLM 代理执行 EDA
在生成完整的工作流之前,LLM 智能体必须了解数据结构。
关键问题包括:
- 训练集和测试集内有多少行和列?
- 目标列是什么,它是如何格式化的?
- 是任务分类还是回归?
- 有哪些可用功能?如何对其进行格式化?
- 哪些特征是分类特征或数字特征?
- 是否存在数据缺失?
这些信息可以预先提供,也可以通过 EDA 自动推理。
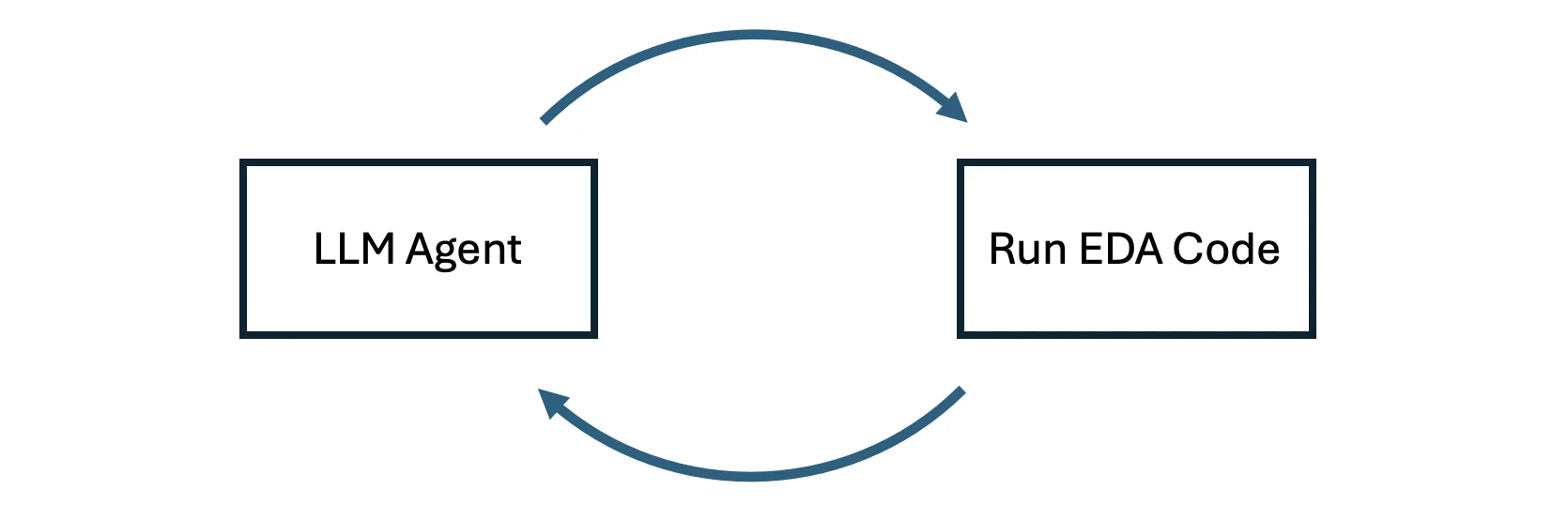
如果在聊天窗口中使用 LLM,请使用以下提示:
“Please write EDA code to explore the CSV file train.csv and test.csv. I will run the code and share the plots and text back with you.” |
如果使用大语言模型 (如克劳德代码) 执行代码,您可以要求大语言模型编写并运行自己的代码来理解数据。
“Please write and run EDA code to understand the CSV files train.csv and test.csv” |
第 2 步:LLM 智能体构建基准
一旦 LLM 理解了数据,尤其是特征列和目标列,就需要编写第一个完整的工作流,通过向 LLM 请求特定模型来训练 kfold 模型。
“Please write full code pipeline to read train.csv and test.csv and train a kfold XGBoost model. Save the OOF (out of fold predictions) and the Test PREDS to disk as Numpy files. Display the metric score each fold and overall.” |
将输出代码复制并粘贴到代码库中。使用命令行或 IDE 代理时,请其直接创建 Python 或 Jupyter Notebook。
运行代码以获取您的第一个 CV 指标分数、OOF 和 Test PRED 文件。
您可以要求 LLM 构建各种基准,包括 GBDT、NN 和 ML 模型。每个实验都会报告一个 CV 分数,并将预测结果另存为:“train_oof_[MODEL]_[VERSION].npy”和“test_preds_[MODEL]_[VERSION].npy”。
这些文件很重要,我们稍后会使用它们。
第 3 步:LLM 智能体执行特征工程
我们现在拥有一系列不同的模型,并且知道它们的基准 CV 指标分数。我们可以通过特征工程和/ 或模型调整/ 改进来改进每个模型。特征工程侧重于转换数据,以便我们的模型可以提取更多信号。模型调优/ 改进侧重于修改模型以提取更多信号。LLM 智能体在这两项任务中表现出色。
通过迭代运行实验并保留所有改进模型的想法,可以获得更好的模型。对于每个实验,无论好是坏,始终将 OOF 和测试预测保存到磁盘中。
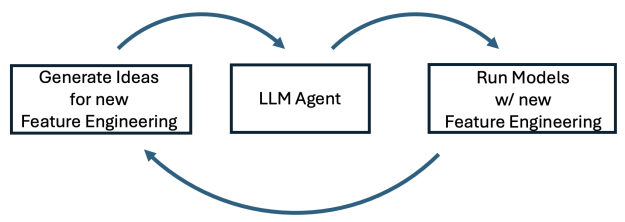
LLM 智能体可以尽可能快地编写代码。为加速周期,我们始终使用 GPU 和 GPU 库 (例如 cuDF、cuML、梯度提升决策树 GPU 和 PyTorch GPU) 来尽可能快地运行每个实验。
为了产生新的想法,我们可以提出建议,也可以让 LLM 生成这些想法。有许多有效的方法可以鼓励 LLM 产生想法,例如:
- 让 LLM 查找并阅读关于该主题的研究论文。
- 让 LLM 阅读有关该主题的论坛和公开分享的代码。
- 让 LLM 执行 EDA,以确定特征工程的特征和目标之间的关系。
- 向 LLM 询问基于当前知识库的想法。
- 让人类与 LLM 进行头脑风暴,共同创造想法。
根据我们的其中一个想法,我们可以让 LLM 智能体根据旧代码创建新代码:
“Please write me a complete replacement code for the code below that uses XYZ instead of ABC”. |
我们现在有一个新的实验要运行!
第 4 步:LLM 智能体组合模型
此时,我们获得了大量实验结果,每个结果都有自己的模型和不同的特征工程,并保存在 Python 脚本或 Jupyter Notebook 中。LLM 智能体擅长将所有这些模型和想法相结合,可以帮助我们以各种方式使用和管理所有模型,例如:
- 总结所有模型类型和特征工程。
- 整合来自不同模型和特征工程的创意,构建更强大的全新单一模型。
- 使用不同模型构建集成。
- 将模型堆叠在其他模型之上。
- 使用一些模型将伪标记/ 知识蒸馏转换为新的、更强的单一模型。
我首先想做的最有用的事情之一是让 LLM 智能体总结我们所有的实验。我们可以将文件拖放到聊天窗口中,也可以使用 LLM 命令行代理 (如克劳德代码) 读取和聚合多个文件中的结果。这有助于我们更好地理解数据和问题,向我们展示可行的方法。
一种强大的技术是让 LLM 智能体将多个想法/ 模型组合成一个模型。
“Can you read all these IPYNB files and use all these ideas to write full code to train a new single XGBoost model which is stronger than all of these models?” |
另一种方法是将部分或全部模型中的知识迁移到单个模型中。我们使用 OOF 和测试预测 (本质上是伪标记) 将知识传输到一个新的、更强大的单一模型中。
“Can you please train a new single NN or GBDT using knowledge distillation from all our OOF and Test PREDs and make a new high performing single model?” |
上述两种技术都会生成新的实验、新的 OOF 和测试预测文件。每个基准模型和采用新特征工程和/ 或模型改进的实验都有一个关联的 OOF 和测试预测文件。通常会有数百个文件。现在,我们可以要求 LLM 结合使用爬山和/ 或堆叠。
“Can you please try combining all our OOF and Test PREDs using various meta models? Please try Hill Climbing, Ridge/Logistic regression, NN, and GBDT stackers. Thanks” |
结果
按照上述四个步骤,我们创建了一组多样化的模型。然后提升每个模型的性能。最后,我们将所有内容整合到一个强大的解决方案中。其优势在于通过 GPU 加速的模型执行和 LLM 代理快速探索许多想法,从而更快地编写代码。在为其表格数据预测任务寻找性能出色的解决方案时,每个人都可以使用这些技术。
开始使用
准备好加速您的结果了吗?开始探索适用于数据科学的 cuDF 和 cuML 库以及 CUDA-X for data science。
如需深入了解,请参加关于特征工程的 DLI 研讨会,进一步提升您的技能。同时,可参考博文《The Kaggle Grandmasters Playbook:7 Battle-Tested Modeling Techniques for Tabular Data》(Kaggle Grandmasters 剧本:适用于表格数据的 7 种经过实战测试的建模技术),了解专业建模策略。