
编程智能体开始大规模编写产品级代码。 Stripe 的智能体每周生成 1300 多个 PR。 Ramp 将 30% 的合并 PR 归因于智能体。 Spotify 每月报告由智能体生成的 PR 超过 650 个。Cloud Code 和 Codex 等工具会在每个编码会话中进行数百次 API 调用,且每次调用都带有完整的对话历史记录。每个工作流程背后都有一个承受巨大 KV 缓存压力的推理堆栈。
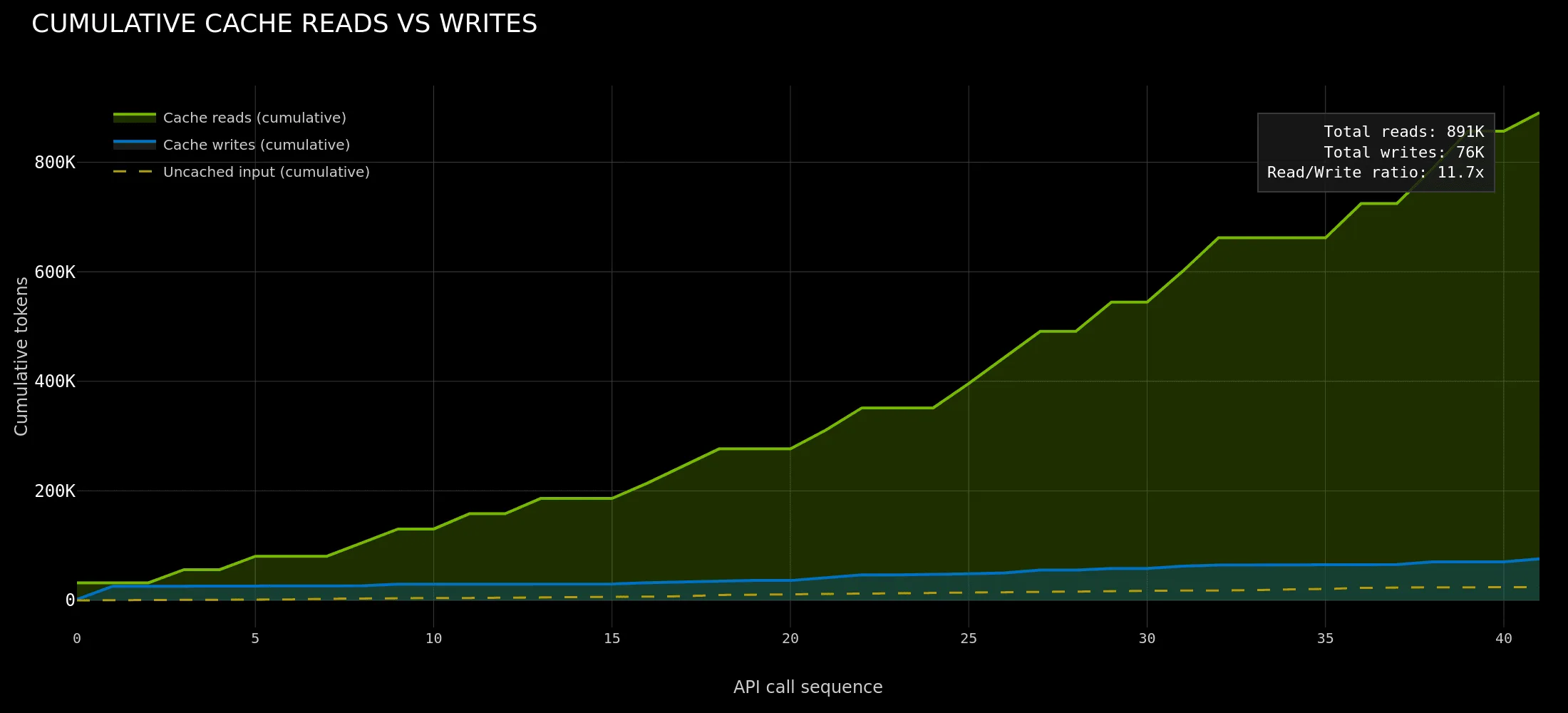
我们以克劳德代码为例。在将对话前缀写入 KV 缓存的首次 API 调用后,对同一工作进程的每次后续调用都会达到 85-97% 的缓存。代理团队 (或蜂群) 进一步推动了这一趋势,4 名 Opus 队友的总缓存命中率为 97.2%。读/ 写比率为 11.7 倍,这意味着系统每次写入词元,就会从缓存中读取近 12 次。这是一种一次写一次读多 (WORM) 访问模式:系统提示和不断增长的对话前缀计算一次,然后在每次后续调用时从缓存中提供。最大限度地提高所有工作节点的缓存重用率,并保持 KV 块的预热和可路由是代理式推理的核心优化目标。
这些数字来自托管 API 基础设施,其中提供商控制前缀匹配、缓存放置和移除。对于在自己的 GPU 上运行开源模型的团队来说,这些都是开箱即用的。我们一直在构建 Dynamo 来弥合这一差距。本文将介绍我们如何在三层实现 Dynamo 代理原生:前端 API、路由器和 KV 缓存管理。
在本文中,我们始终使用三个术语:
- 线束: 驱动工作流程的智能体框架 (克劳德 Code、Codex、OpenClaw、OpenCode 等)
- Orchestrator:Dynamo 的路由、调度和缓存管理层
- 运行时: 执行模型并拥有 KV 缓存管理器 ( SGLang、vLLM、TRT-LLM) 的推理引擎
第 1 层:前端
多协议支持
智能体束越来越多地采用 v1/responses 和 v1/messages 而非 v1/chat/completions,以清晰地处理新模式,包括交错思考和工具调用。这些 API 的主要区别在于结构。在 v1/chat/completions 中,消息内容是一个扁平字符串,工具调用作为一个单独的字段以螺栓形式打开。例如,请注意在 v1/chat/completions 端点后面托管模型时,GLM 和 MiniMax API 如何以不同的方式处理交错思维。v1/responses 和 v1/messages API 使用类型化的内容块,因此单次助手转向可以将思考、工具调用和文本作为不同的对象。这对于推理非常重要,因为编排器可以查看块边界、执行提示优化,并针对每个块类型应用不同的缓存和调度策略。Dynamo 通过通用的内部表示形式服务于所有三个端点,因此单个部署可以作为任何线束的推理后端。我们的团队一直在内部运行 GLM-5 和 MiniMax2.5 的 Dynamo 部署,为我们的 Codex 和 Claude Code 工具提供支持。这使我们能够根据闭源推理对后端实现进行基准测试,实现缓存重用性能的均等。在接下来的几周里,我们将分享部署这两个模型的完整说明和一些优化方案。
我们还投资为各种开源模型提供首发日工具调用和推理解析支持。如果您发现某个模型不受支持,请打开一个问题或使用工具调用解析器生成器技能,使用您选择的工具生成该模型。
智能体提示:线束编排器界面
如今,推理服务器会看到匿名标记化请求。但智能体的线束具有基础设施永远无法看到的全局背景:哪些智能体在工具调用中受到阻碍、刚刚生成的工具调用、会话中保留的轮次,以及当前调用是快速查找还是长合成。使用编码代理时,用户需要等待最终结果,而不是单个词元流,因此编排器可以对跨代理的请求进行重新排序和优先级排序,而不会影响最终用户体验。会话运行时间为几分钟甚至几天,工具调用暂停时间较长。这足以以传统服务无法做到的方式优化推理调度。

Dynamo 的全新智能体提示扩展程序旨在弥合这一差距。它允许任何工具将结构化提示附加到所有三个 API 端点的请求中,为路由器和运行时提供所需的上下文,以便智能体做出感知调度和缓存决策。这是我们正在积极与社区共同设计的 v1 API,希望构建智能体的团队能够就哪些信号最有用提供反馈。如果您有任何想法或反馈,请与我们联系。
{ "model": "MiniMaxAI/MiniMax-M2.5", "messages": [...], "tools": [...], "nvext": { "agent_hints": { "osl": 256, "speculative_prefill": true, "priority": 10 }, "cache_control": { "type": "ephemeral", "ttl": "1h" } }} |
agent_hints 字段:
priority控制路由器和引擎的调度。值越大意味着在 Dynamo API 级别“更重要”;Dynamo 会将其转换为路由器队列排序和后端特定引擎优先级。osl(输出序列长度) 是线束对该请求将生成的词元数量的估计值。路由器使用此参数来衡量 worker 的占用时间,从而改善负载平衡。线束可以通过跟踪每种工具调用类型的平均输出长度来了解这一点。speculative_prefill指示编排器在完整请求准备就绪之前,开始在可能的工作进程上缓存此请求的前缀。当线束知道工具调用即将返回并希望提前加热缓存时,此选项非常有用。
任何使用过 Anthropic 提示缓存 API 的人都会熟悉 cache_control 字段。它告知编排器将计算出的前缀固定在特定 TTL 的 worker 上,从而保护其在工具调用间隙期间不被逐出。目前,ephemeral 是唯一受支持的类型 (与 Anthropic 的 API 相匹配) 。我们将在下面的缓存保留部分讨论其工作原理。您可以在此处找到有关智能体提示的完整文档。
第 2 层:路由器
编码代理遵循顺序模式:长预填充、工具调用、扩展前缀、重复。多智能体利用简短、独立的上下文,在并行子智能体之间开展工作。默认轮询路由对这两种模式都是盲目的,无法考虑缓存局部性、请求优先级或会话结构。Dynamo 路由器通过三种机制弥补了这一差距:KV 感知放置、优先调度和可扩展路由策略。
KV 感知展示位置
在没有缓存感知路由的情况下,对话的第 2 回合在与第 1 回合相同的工作节点上登陆的几率约为 1/ N。每次漏掉的都是完整的前缀重新计算,这是一个重要的性能瓶颈,对最终用户来说成本极高。Dynamo 的路由器维护一个全局索引,其中包含哪些工作节点上存在 KV 缓存块。 闪存索引器帖子 介绍了将此索引器提升至 1.7 M ops/s (行星级 KV 路由) 的六次迭代。在每个请求中,路由器都会查询每个工作节点的重叠分数索引,并选择可更大限度地减少缓存丢失和当前解码负载的综合成本的工作节点。此代价函数是可调整的,下面我们将展示团队如何在其基础上构建自定义智能体感知路由策略。
优先调度
priority 是面向单个用户的调度旋钮。值越大,就意味着 Dynamo API 级别“越重要”。Dynamo 在这两个层中都使用了这一点:
- 在路由器中,启用
--router-queue-threshold后,优先级较高的请求会在队列中更早地转移。 - 在引擎上,Dynamo 对后端特定的极性进行归一化,并转发队列排序、抢占和 KV 缓存移除的请求。
在路由器上,传入请求按有效到达时间顺序输入 BinaryHeap<QueueEntry>。priority 越高,请求看起来就像更早到达一样,优先于优先级较低的工作。只有当所有工作者超过可配置的负载值时,请求才会进入队列。在该值之下,它们可以完全绕过队列,直接选择工作节点。当容量释放 (预填充完成或请求完成) 时,队列会首先耗尽优先级最高的条目。
调度完成后,SGLang、vLLM 和 TRT-LLM 可能会以不同方式解释引擎优先级,因此 Dynamo 会对每个后端面向引擎的值进行标准化。SGLang 等引擎还可以使用基于优先级的 radix 缓存驱逐,在内存压力下首先驱逐低优先级块。

代理式工作负载路由策略
具有 20 万个上下文窗口的研究智能体需要具有足够可用 KV 容量的工作者来保持其完整状态。路由器的默认代价函数 (重叠分数+ 解码加载) 可处理常见情况,但具有特定领域工作负载的团队可以使用路由器的 Python 绑定来实现自定义路由策略。核心 KvRouter 类提供 best_worker() 用于查询路由决策,get_potential_loads() 用于每个工人的负载检查,generate() 用于一次调用中的路由+ 调度。自定义路由器在与默认组件相同的服务网格上注册,并且可以覆盖每个请求的路由配置:
# Query per-worker load and overlap for custom routing logicloads = await router.get_potential_loads(token_ids)# Override routing config based on request properties# Long contexts benefit from heavier overlap weightingconfig = {"overlap_score_weight": 2.0} if len(token_ids) > 8192 else {}worker_id, dp_rank, overlap = await router.best_worker( token_ids, request_id="req-123", update_indexer=True, router_config_override=config)# Or bypass the default selector entirely when the harness# has its own worker selection logic (e.g., session affinity)stream = await router.generate( token_ids, model=model, worker_id=chosen_worker) |
NeMo Agent Toolkit (NAT) 团队使用这些 API 构建了自定义的在线学习代理式路由器。他们的路由器会从 nvext 标注中提取会话元数据,并将其馈送至 Thompson Sampling Bandit 样式的 cost 函数,该函数可学习哪些工作节点在加载时最适合哪种前缀模式。与 Dynamo 的默认路由相比,他们测量到每秒可将 p50 TTFT 降低 4 倍,将 p50 词元提升 1.5 倍。在中等内存压力下,延迟敏感型请求的优先级标记可将 TTFT 降低高达 63% p50。有关实现详情,请参阅 NAT Dynamo 集成示例。我们很快会在 Dynamo 中将其作为路由策略提供。
第 3 层:KV 缓存管理
代理式工作负载产生的块具有截然不同的重用值 (系统提示词每次都重复使用,推理是词元永远不会重复使用) ,但默认的 LRU 驱逐对所有块的处理方式相同。2-30 秒的工具调用暂停会耗尽智能体的整个前缀,在恢复时强制完全重新计算。缓存需要了解块值,支持跨工作节点共享,并尊重智能体生命周期边界。
统一驱逐的问题
| 块类型 | 重用模式 | 价值 |
|---|---|---|
| 系统提示+ 工具定义 | 每次回合 | 最高 |
| 对话历史记录 | 后续轮次,单调增长 | 高 |
| 思考/ 推理词元 | 通常情况下,推理循环结束后,零重复使用 (输出的很大一部分) | 接近零 |
| Subagent KV | 多次转弯,代理死亡。无需保留 | 接近零 |
LRU 只看到最近性。在高流量环境中,等待所调用工具的完成 ( 2-30 秒,而智能体等待外部 API) 可能会导致智能体的块过时,当智能体恢复时,必须重新计算整个前缀。为解决此问题,我们需要提供 Orchestrator API 来控制应保留的块、应保留的位置以及保留时长。
将 KV 缓存用作共享资源
如今,KV 缓存被视为每个工作进程上的本地临时资源。智能体的 32K-词元系统提示和工具定义独立于每个服务其请求的工作者进行计算。当一个主代理生成 4 个子代理 (每个子代理都有重叠的工具定义) 时,如果子代理落在不同的 worker 上,则该共享前缀将被重新计算 4 次。在对克劳德代码团队会话的分析中,我们直接测量了这一点:队友的平均缓存命中率为 79.4%,而首席智能体的探索子代理的平均缓存命中率为 91.3% (读取/ 写入率是 5.0 倍,读取/ 写入率是 11.7 倍) ,差距几乎完全由每个队友的首次调用时的冷启动写入造成。目标是为集群中的所有工作者提供高价值的 KV 缓存块。从本质上讲,它们在冷启动期间写入一次,然后由任何工作人员随时读取。
SGLang 的 HiCache 和 Dynamo 的 KV Block Manager (KVBM) 等解决方案正朝着 4 层内存层次结构构建:

块遵循直写路径:当工作节点为前缀计算 KV 时,块会自动从 GPU 流向 CPU 和磁盘。在全局注册表中按序列哈希对每个块进行去重。注册块后,任何能够到达存储层的工作者都可以对其进行不可变和寻址。
这直接解决了子代理冷启动问题。当主代理定义计算工具和系统提示时,这些块将写入共享存储。当子代理 1 在不同的 worker 上生成时,路由器会查询 Flash Indexer,在共享存储中找到块,然后 worker 通过 NIXL ( RDMA 读取) 加载它们,而不是从头开始重新计算。Subagent 2 也是如此。四个冗余预填充计算变成一个计算和三个负载。该机制还解决了解预填充 – 解码服务中的缓存一致性问题。在 disg 模式下,预填充工作进程计算 KV,并通过 NIXL 将其传输给解码工作进程。解码工作进程生成词元,生成新的 KV 状态。在接下来的回合中,预填充工作进程需要原始前缀和从第 1 回合生成的词元,但它们仅存在于解码工作进程中。通过共享存储,decode worker 会将其新块写入公共层,任何预填充 worker 都可以在下一轮获取这些块。
多层存储解决了共享和持久性问题,但只有在请求到达工作节点后,GPU 才会收到块。代理式系统缺少的部分是预取:线束可以使用历史定时数据来预测智能体的工具调用可能会返回的时间,这意味着它知道将需要哪些块以及何时需要。我们正在构建预取 Hook,以便线束可以发出“在下一个请求之前将这些块从存储区引入 GPU”的信号。与下方的保留 API 相结合,这可实现线束的完整生命周期控制:用于防止拆迁的针脚块、用于控制拆迁命令的优先级设置,以及在需要之前主动预取块。

选择性缓存保留
在全球范围内提供块可以解决共享问题,但并不能解决驱逐问题。SGLang 和 vLLM 均支持通过优先级堆进行基于优先级的驱逐,其中线束为每个请求分配数字优先级,并首先驱逐低优先级块。TensorRT-LLM 通过 TokenRangeRetentionConfig (由 Dynamo 团队成员@jthomson04) 进一步推动了这一点,允许在单个请求中按区域进行控制。
一个请求执行零条或多条指令。无指令的块遵循默认 LRU 路径,且零开销。驱逐器变为双结构系统:用于未优先处理块的 LRU 无列表 ( O (1) ,不变) 和用于标注块的优先级队列。该工具可以表示“系统提示块在最后被逐出 (优先级:100) ;对话上下文在 30 秒的工具调用后继续存在 (时长:45 秒) ;首先解码词元 (优先级:1) ”,而引擎无需理解原因。
Anthropic 的提示缓存可让您在其基础架构上将前缀标记为可缓存。Dynamo 的 cache_control API 为自托管推理带来了相同的语义。当请求包含 cache_control: { type: "ephemeral", ttl: "1h" } 时,路由器会将工作节点树中匹配的前缀节点固定为该 TTL,从而保护它们在工作节点的 L2 存储中免遭驱逐。
下一步是将保留与分布式缓存连接起来。如今,保留指令适用于单个工作进程的本地缓存。当线程块固定在工作节点 A 上,但下一个请求路由到工作节点 B 时,引脚不会跟随。将保留语义扩展到整个 HiCache/ KVBM 的共享存储层意味着线束可以固定一次块,并使其在工作节点中存活:优先级和 TTL 元数据通过写入路径随块传输,任何从共享存储加载块的工作节点都会继承保留策略。结合上述预取 Hook,可在整个内存层次结构中实现线束端到端生命周期控制。
智能体生命周期感知
以典型的克劳德代码会话为例。主代理运行 20 余轮,累积不断增长的对话前缀。在此过程中,它会生成探索每个运行 1-3 个回合并终止的子代理。它可能会催生一个由 4 名专家组成的团队,这些专家并行处理不同的子任务,然后终止。中途,智能体达到上下文限制并总结其历史记录,将约 175K 词元压缩到约 40K。每个事件都会产生短暂的 KV:永远不会被再次引用的块。子代理终止、上下文总结和闭合推理循环都会生成短暂的 KV,其占用的内存与系统提示符等高值块相同。推理模型放大了这一点:<think>...</think> 块约占生成的词元的 40%,但在推理循环关闭时就会变成短暂的。如果没有生命周期感知,缓存会对所有这些块进行相同的处理。

上述保留基元 (优先级、TTL、词元范围) 为我们提供了构建块。缺少的是将它们与会话关联的能力。如果线束可以将子代理的请求标记为属于会话,并将该会话的 KV 标记为短暂的,则驱逐者可以先锁定这些块,然后跳过将它们完全写入共享存储。当子智能体终止时,其会话块是第一个回收的块。同样的机制也适用于词元的思考:引擎可以在生成过程中检测 <think> 边界,并在插入时将这些块标记为短暂的,因此它们会跳过 L2 回写,并在没有任何外部信号的情况下将其逐出正常块之前。设计领域十分广泛:线束驱动的会话标记、引擎原生语义检测,以及将两者相结合的混合方法。我们正在积极探索多个方向,并期望正确答案因工作负载和框架而异。
缩小差距
代理式推理中最大的优化面是线束已知内容与基础架构可见内容之间的差距。哪些代理被阻止,哪些即将恢复,哪些 KV 值得保留,哪些可以丢弃 – 所有这些上下文都存在于线束层,但从未跨越 API 边界。nvext.agent_hints 是我们弥合这一差距的第一步:少量结构化信号可让编排器做出明智的路由、调度和缓存管理决策,而不是将每个请求视为匿名词元。这是 v1 API,我们正在积极改进。如果您要构建智能体工具、运行面向智能体工作负载的开源模型,或考虑使用缓存感知推理,我们希望了解哪些信号对您的用例最重要。您可以在 GitHub 上联系我们,也可以在 X 上给我们添加标签: @0xishand、 @KranenKyle、 @flowpow123。