
评估AI模型与评估AI智能体密切相关,但两者回答的问题截然不同。模型基准测试衡量的是基础模型的能力,例如理解语言、遵循指令或解决静态任务的能力;而智能体评估则关注端到端系统的行为,包括规划、调用工具、处理不确定性,以及在动态环境中完成实际工作流程的表现。
本文将解释模型和智能体评估之间的主要区别,并介绍将 AI 智能体作为生产系统进行评估的五个实用技巧。这种评估方法侧重于轨迹、工具和结果,而不仅仅是模型分数。
评估 AI 模型和评估 AI 智能体有什么区别?
虽然模型和智能体评估密不可分,但它们的技术基准和成功指标根本不同。
AI 模型评估:能力基准
独立评估模型主要关注基础模型(如大语言模型LLM或视觉语言模型VLM),通过使用具有预定义输入-输出映射的静态数据集,来衡量模型的原始认知与语言能力。团队通常依赖MMLU等基准测试评估常识推理能力,GSM8K用于数学推理,HumanEval用于评估编程熟练度。
模型评估的最终目标是回答一个问题:“这个引擎是否足够强大,足以理解我的指令并通过事实进行推理?”
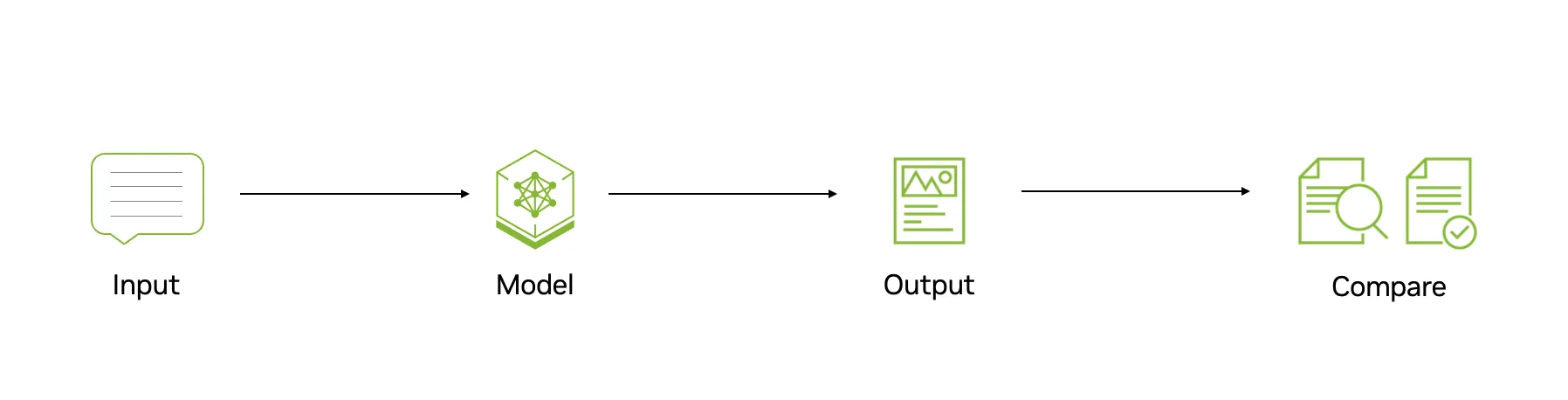
AI 智能体评估:性能轨迹
智能体评估将镜头转向轨迹:端到端推理序列、工具调用和环境观察。智能体可能会使用顶级模型,但却失败了,因为它给 API 的 JSON 模式带来了幻觉,或者在搜索失败后进入了无限循环。
智能体评估进入动态环境,使用用于现实世界辅助的 GAIA 基准测试、用于解决 GitHub 问题的 SWE 基准测试,以及用于基于 Web 的任务执行的 WebArena 测试。从技术上讲,此评估需要跟踪任务成功率 (TSR) 以衡量意图分辨率,跟踪工具调用准确性以确保函数调用的准确性,并跟踪效率以识别冗余步骤。虽然高 MMLU 分数是先决条件,但并不能保证智能体的可靠性。
目标从衡量知识转变为衡量结果。问题是:“此系统能否在非确定性环境中可靠地执行多步骤工作流程?”
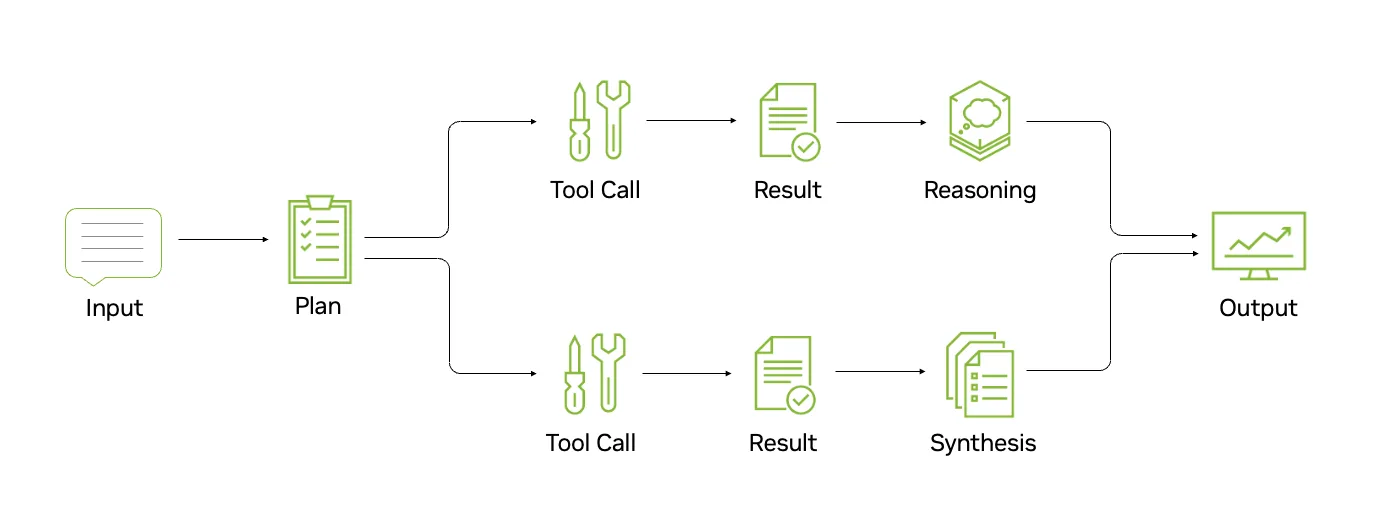
如何评估 AI 智能体
本节介绍用于评估 AI 智能体的五个实用技巧。
小贴士# 1:衡量任务成功与否,而不仅仅是准确性
MMLU、GSM8K 和 HumanEval 等模型基准测试表明智能体的基础模型是否具备能力,而非智能体是否能够完成堆栈中的实际任务。
对于智能体评估,优先考虑 TSR:
- 将任务定义为意图和约束条件;例如:“在两次工具调用中通过此 API 更新此记录。”
- 只有当智能体在这些限制条件下完全解决了意图时,才能衡量成功与否。
- 跟踪每个场景中的 TSR (正常、降级的工具、模糊的指令) ,以揭示其易损性。
在 TSR 下,最终答案的传统准确性成为二级诊断。
小贴士# 2:评估完整轨迹,而不仅仅是最终答案
两个智能体可以提供相同的答案,但行为方式却截然不同:例如,一个智能体使用三次精确的工具调用,而另一个智能体则在数十个不相关的步骤中执行不同的操作。最终答案分级将智能体视为相同的,但生成行为并非如此。
让智能体记录完整轨迹:
- 计划和子目标
- 所有工具调用、参数和响应
- * 可行时的中间推理步骤
- 最终答案和副作用 (写入、更新)
然后计算轨迹效率 ( 每成功的 steps/tokens) 、工具调用准确性和故障模式分布 (计划、工具、环境) 等指标。
小贴士# 3:让工具的使用成为第一信号
大多数生产智能体的成败取决于其使用工具 ( API、数据库、搜索) 的方式,而不是措辞。
* 对于每个评估任务,指定预期的工具行为:
- 允许或需要使用哪些工具
- 每个工具的最大调用次数
- 每次调用的预期模式
・测量以下指标,以揭示各种模式,例如 API 模式的幻觉或过度使用速度缓慢、成本高昂的工具:
- 工具选择精度和召回率: 是否可以避免选择正确的工具和错误的工具?
- 架构合规性: 参数是否与预期结构相匹配而不进行重试?
小贴士# 4:评分推理质量和效率
推理失败或步骤过多的正确答案需要耗费大量计算资源。以下技术有助于将推理和效率结合起来:
- 捕捉推理痕迹 (计划或理由字段) ,并定期将其标记为声音、部分缺陷或错误。
- 检查推理是否使用检索到的证据,而不是忽略它。
- 跟踪每个成功任务的词元、工具调用和端到端延迟。
* 当您调整提示词、路由或重试策略时,请使用显式预算 (例如,“N 词元和 M 工具调用下 95% 的任务”) 作为约束条件。
小贴士# 5:从一开始就构建透明、可定制的评估
与其改进可观察性,不如将评估视为智能体设计的一部分。*
以下是使用第一个原型时的一些操作方法:
- 使用稳定 ID 记录每个计划、工具调用和关键推理步骤,以便轻松重建轨迹。
- 为轨迹附加标签 (成功/ 失败、错误类型、人工评分) 。
- 支持全局指标 ( TSR、轨迹效率、工具调用准确性) 和特定用例指标 (例如研究的引用范围) 。
・这种方法将评估转变为日常开发工具,以便尽早发现改进或漏洞。
| 维度 | 测量内容 | 为何如此重要 |
| 任务成功或准确性 | 每个场景的任务成功率 | 直接映射到“智能体能否在此处完成真正的工作?” |
| 轨迹可见性 | 已记录的步骤、计划、工具调用、故障模式 | 打开黑子,使调试和可解释性成为目标。 |
| 工具使用率 | 工具选择、模式合规性、重试 | 获取超越模型分数的真实集成质量。 |
| 推理和效率 | 合理推理、词元、步长、每项任务的延迟 | 在正确性与成本和性能之间取得平衡。 |
| 自定义指标 | 特定用例的 KPI (语气、安全性、引文、风险) | 将评估与业务和合规性目标保持一致。 |
开始评估 AI 智能体
可靠的代理式系统将评估从静态模型基准转变为动态、轨迹感知的指标,以反映智能体在真实环境中的行为方式。您可以同时跟踪结果、工具使用情况、推理和成本,然后从一开始就将这些信号连接到您的开发循环中。
NVIDIA NeMo Agent Toolkit 旨在集成到现有的智能体框架中,无需完全重构即可添加评估、优化和可观测性功能。它能帮助您采集前述指标(任务结果、执行轨迹和工具调用),从而支持基于评估的迭代开发。
如需了解更多信息,请点播观看相关的 GTC 2026 会议和培训实验室:
- 评估驱动型开发:构建可靠智能体的最佳实践 (GTC 会议)
- 使用评估驱动的设计开发生产智能体 (GTC 培训实验室)