
随着 LLM 从简单的文本生成过渡到复杂的推理,强化学习 (RL) 发挥着核心作用。群相对策略优化 (GRPO) 等算法为这种转变提供动力,使推理级模型能够通过迭代反馈不断改进。与标准监督式微调不同,RL 训练循环分为两个不同的高强度阶段:具有严格延迟要求的生成阶段和需要高吞吐量的训练阶段。
为了使这些工作负载可行,研究人员和工程师正在转向 FP8 等低精度数据类型,以提高训练和以吞吐量为导向的生成性能。此外,在某些生成受 GPU 显存带宽限制的情况下,使用低精度参数可以降低每个参数的字节数,从而提高性能。
本文将深入探讨低精度 RL 所面临的系统性挑战,以及 NVIDIA NeMo RL—NVIDIA NeMo 框架中的开源库——如何在保持准确性的同时加速 RL 工作负载。
用于 RL 中线性层的 FP8
我们的 recipe 使用 DeepSeek-V3 技术报告中引入的块级量化 FP8。表 1 详细介绍了线性投影层中的张量格式。
| 张量 | 数据类型 | 量化粒度 | 缩放系数 | 缩放类型 |
| 权重 | FP8 ( E4M3) | [128、128] | FP32 | 块级 |
| 输入激活函数 | FP8 ( E4M3) | [1、128] | FP32 | 块级 |
| 输出梯度 | FP8 ( E4M3) | [1、128] | FP32 | 块级 |
借助此方法,可以使用 FP8 数学运算,其峰值吞吐量是 BF16 数学运算的 2 倍。其他模块,包括 注意力、归一化、非线性函数和输出预测,均使用 BF16 数学运算进行计算。
RL 中数字差异的挑战
RL 工作流通常使用单独的引擎:用于部署的 vLLM 和用于训练的 NVIDIA Megatron Core。每个内核都使用独特的自定义 NVIDIA CUDA 内核,以更大限度地提高性能。这本身就引入了数值差异,这些差异会因额外的量化和去量化逻辑而在较低精度下累积放大。我们将此数值差异量化为词元乘法概率误差:
t_0
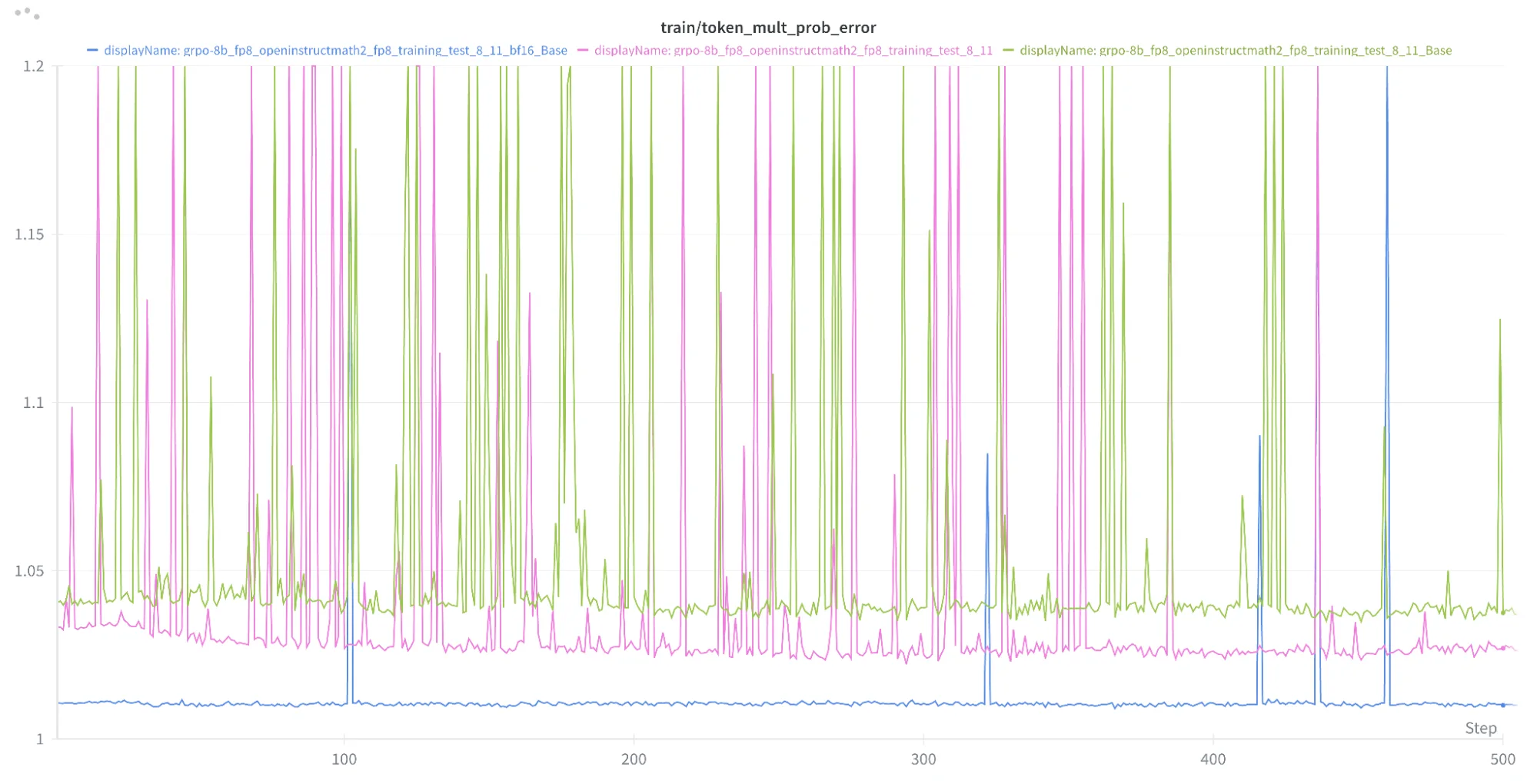
完美对齐可获得 1 分,如果不使用任何其他技术,我们通常会发现“可接受”值为+ 1.03-1.05。
线性层中的端到端 FP8 可减少数值差异
在开发 FP8 recipe 的过程中,我们尝试了三种方法:
- 基准配置: BF16 for both generation and training.
- 配方候选项 1: FP8 仅在生成过程中应用,而策略模型训练则在 BF16 中进行。
- 最终配方:端到端 FP8:我们在生成引擎和训练引擎中都使用 FP8
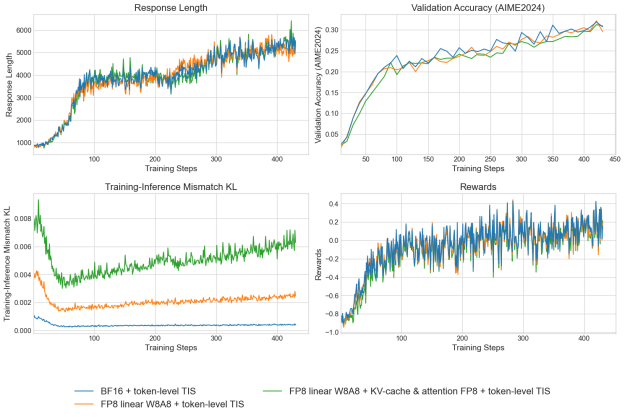
我们观察到,与仅用于生成 FP8 的 recipe 候选 1 相比,最终 recipe 在生成和训练之间始终显示出更低的数值差异。请注意,基准配方始终给出最小的数值差异。图 1 显示了三个方法的词元乘法概率误差指标。
通过重要性采样减少数值差异
重要性采样用于纠正生成数据的模型 (即分布) 与正在训练的模型 (即分布) 之间的分布不匹配。即每词元权重乘以损失。您可以参阅我们的 GRPO 文档,了解重要性采样的详细理论背景。
实验表明:
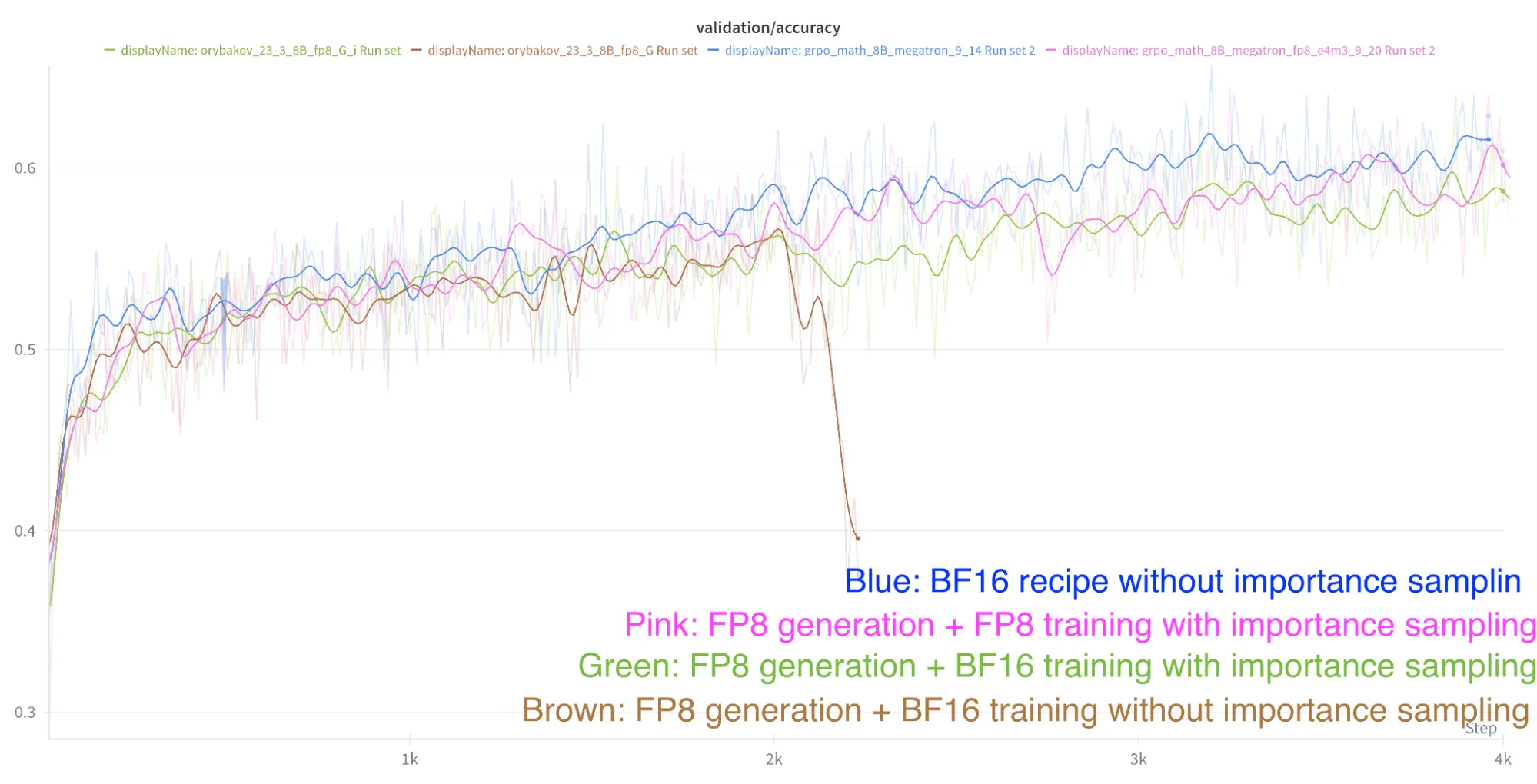
- 对于候选配方 1 ( FP8 生成和 BF16 训练) ,重要性采样可以缩小与 BF16 RL 的准确度差距,但无法缩小差距。
- 对于最终的 recipe (端到端 FP8) ,重要性采样完全消除了与 BF16 训练的差距。图 2 显示了针对不同配方进行训练期间的验证准确性。
FP8 线性层 E2E 的结果
我们在密集模型和混合专家模型上评估端到端 FP8 配方,根据 BF16 基准测量验证准确性和训练吞吐量。
在密集模型上实现 FP8 端到端:Llama 3.1 8B Instruct
表 2 显示了 Llama 3.1 8B 指令模型和数学数据集训练到 4000 步的 GRPO 训练中 FP8 端到端 recipe 和 BF16 recipe 的准确性。
| 精度 | BF16 | 仅 FP8 代 | FP8 端到端 |
| 验证准确性 | 0.616 | 0.586 | 0.613 |
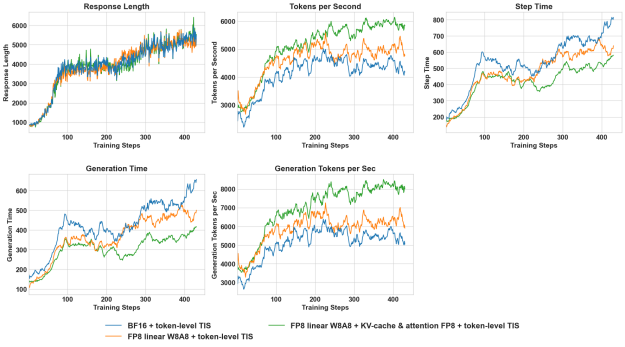
在速度提升方面,与 BF16 相比,FP8 配方实现了超过 15% 吞吐量提升。图 3 是在 1000 个步骤中对两个方法进行的 GRPO 训练 (每个 GPU 每秒词元) 。
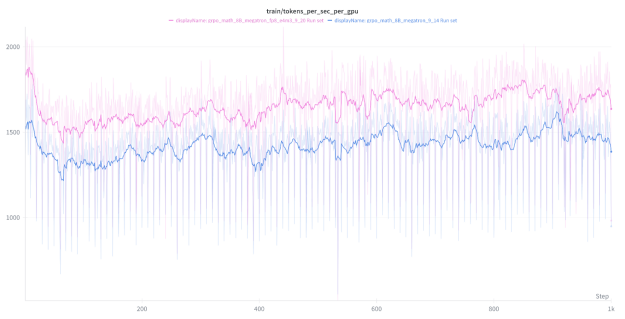
虽然 FP8 的理论速度是 BF16 的 2 倍,但在实践中,其速度较低,因为只有线性层受益于更快的数学吞吐量,而注意力层和元素层保持不变。在线性层之前添加的额外量化内核会产生一些开销。速度提升 15% -25%,与我们对 vLLM 的独立测试相当。通过进一步优化 (例如在 vLLM 中融合量化内核) ,我们预计速度将进一步提升至 1.25 倍。
MoE 模型上的 FP8 端到端:Qwen3-30B
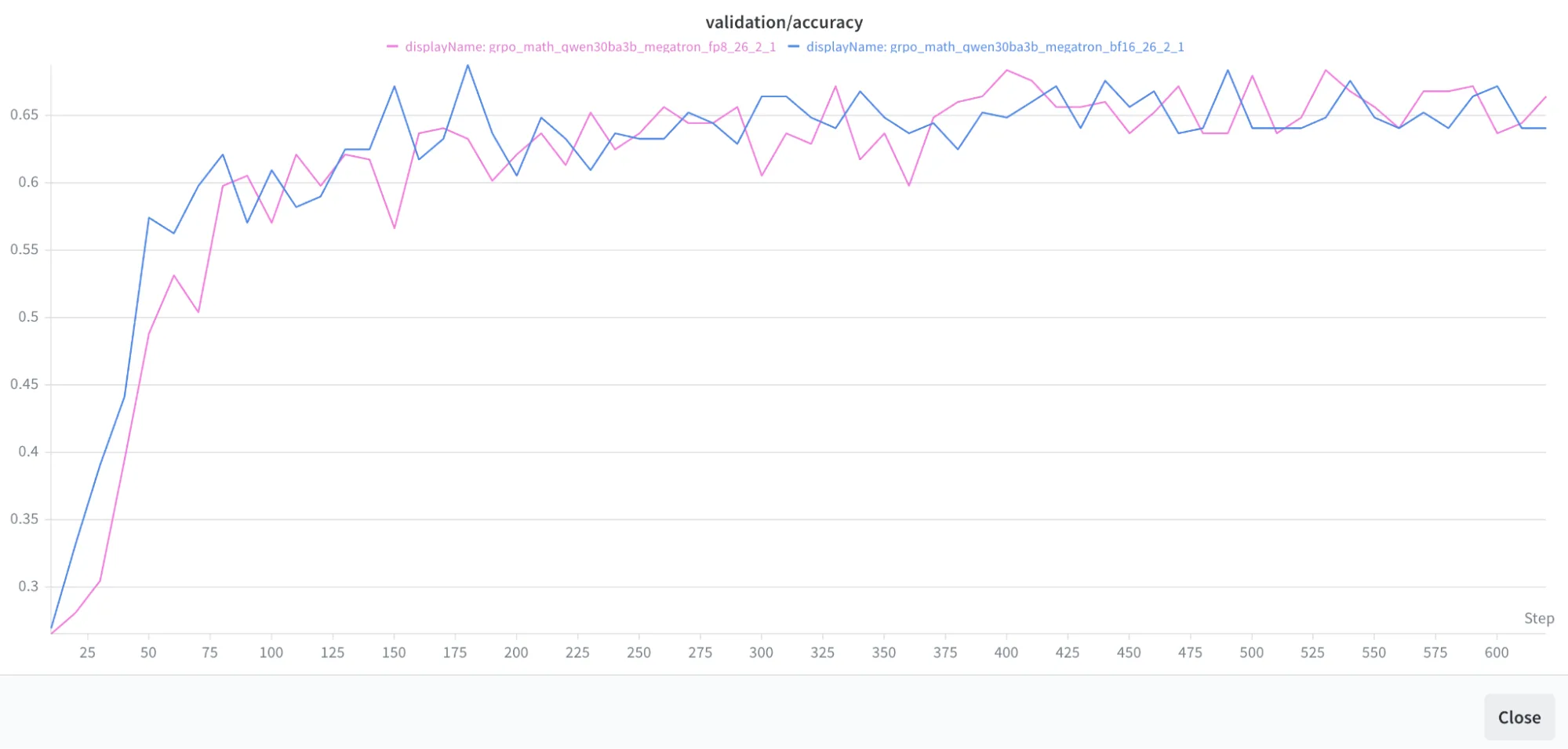
在混合专家模型 (MoE) 上也进行了类似的实验,Qwen3-30B 的结果显示了匹配的精度曲线。FP8 的精度与 BF16 相当。正在研究速度增益。
扩展用于 KV 缓存和注意力的 FP8
使用 Transformer 模型时,线性层并不是唯一的瓶颈。在具有长输出序列长度 (OSL) 的 RL 工作流中,KV 缓存增长和注意力计算通常在端到端推出时间中占据主导地位,同时还使内存带宽饱和,并降低词元生成速度。这促使我们在 RL 循环中探索用于 KV 缓存和注意力的 FP8。使用按张量缩放 FP8。
在 RL 设置中对 KV 缓存实施 FP8 具有独特的挑战性,因为策略权重在每个步骤都会发生变化。与只进行一次校准的静态推理不同,RL 需要对量化尺度进行动态处理。
NeMo RL 采用以下方法解决此问题:
- 重新校准: 在每个训练步骤结束时,训练器使用更新的策略权重重新校准查询、键值 (QKV) 比例。
- 数据选择: 使用训练数据 (提示和生成的响应) 执行此校准,以确保刻度反映当前分布。
- 同步: 然后,新计算的比例会同步到推理引擎 (vLLM) ,以供后续推出阶段使用。
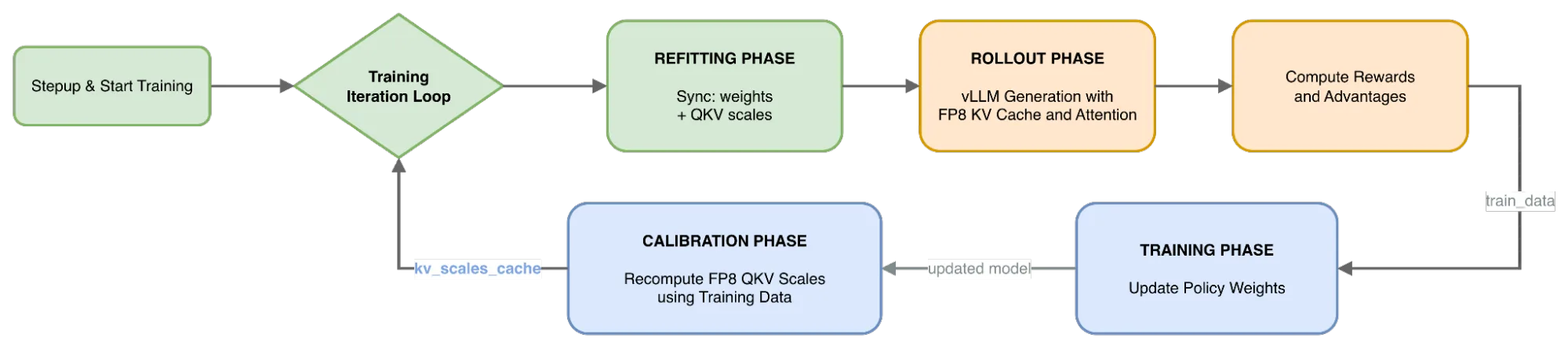
这种设计可确保部署引擎始终使用根据最新策略状态衍生的最佳量化比例,从而最大限度地减少准确性下降。校正用度极小,消耗的时间约为总步骤时间的 2-3%。
| 张量 | 数据类型 | 缩放系数 | 缩放类型 |
| QKV 注意力激活 | FP8 ( E4M3) | FP32 | 张量级 |
| 存储的 KV 缓存 | FP8 ( E4M3) | FP32 | 张量级 |
KV 缓存上 FP8 的结果摘要和注意力
我们使用 GRPO 算法在 Qwen3-8B-Base 模型上运行结果,在部署中应用 FP8,在训练中应用 BF16。虽然对复合错误引起的 KV 缓存和注意力进行量化时,不匹配 KL 差异稍高一些,但我们的方法可以减轻不稳定性。通过启用词元-level 截断重要性采样,用于线性* KV 缓存* 注意力的 FP8 可实现与 BF16 基准和线性层 (W8A8) 的 FP8 的验证准确性对齐。
与线性 W8A8 配置相比,为 KV 缓存和注意力运算启用 FP8 可在部署阶段额外获得约 30% 加速,与 BF16 基准相比,总体加速约 48% 加速。在响应长度较长的情况下,注意力计算在整个工作负载中所占的比例较大时,这些收益尤为明显。QKV 刻度重新校准过程大约消耗总步长时间的 2-3%,相对于实现的大幅加速而言,成本较低。
试用使用 NVIDIA NeMo RL 的端到端 FP8
为了在生成和训练后端为线性层启用 FP8,以下配置图显示了如何将每个调整参数传递到训练和生成后端。

要为 KV 缓存和注意力启用 FP8,需要在 vllm_cfg 中为策略配置 kv_cache_dtype 参数,该参数会自动处理训练器侧的 QKV 规模重新校准以及与 vLLM 后端的同步。
policy: generation: vllm_cfg: precision: fp8 # Enable FP8 for linear layers kv_cache_dtype: fp8 # Enable FP8 for KV-cache |
用于生成和训练的高级 FP8 配置选项
到目前为止,我们已经为线性层和 KV 缓存+ 注意力层引入了 FP8 的实现。高级用户可以尝试不同的食谱。以下是部分功能示例:
- 在生成过程中,在 BF16 中保留第一个 N 和/ 或最后一个 M transformer 层 ( N、M 是整数)
policy: generation: vllm_cfg: num_first_layers_in_bf16: N # replace N with an integer num_last_layers_in_bf16: M # replace M with an integer |
- 将生成和/ 或训练配置为使用“Power-of-2 Scaling Factor” (扩展因子) 类型而非 FP32
policy: generation: vllm_cfg: pow2_weight_scaling_factors: true pow2_activation_scaling_factors: true megatron_cfg: env_vars: NVTE_FP8_BLOCK_SCALING_FP32_SCALES: "0" |
- 开发者可以使用为 Megatron Core 后端预定义的 FP8 recipe 变体,而不是默认的块级量化 FP8 recipe,如表 1 所示。详情请参阅 参数 docstring。
policy: megatron_cfg: fp8_cfg: fp8: "e4m3" fp8_recipe: "blockwise" |
开始使用
首先,用户可以参考 llama-3.1-8b 和 moonlight-16b 说明在 NeMo RL GitHub 中。
致谢
这项工作是跨团队协作的成果。我们要感谢 Jimmy Zhang、Victor Cui、Zhiyu Li 和 Lark Zhang 在 FP8 配方开发、实验和集成到 NeMo RL 方面所做的工作。