
自主 AI 智能体 正承担着企业中的各种任务:规划物流车队路线、分类支持工单、生成代码以及编排多步骤工作流。如何让通用模型在您的特定任务中表现出色?通过定制化,为智能体赋予合适的能力。
本文将介绍九种自定义 AI 智能体的技术,以及为您的具体应用场景选择合适技术的标准。如需了解 AI 智能体评估,请参阅《掌握智能体技术:AI 智能体评估》。
为什么需要自定义 AI 智能体?
基础模型 依托其训练数据集,可在多种应用场景和模式中提供广泛的语言理解和推理能力。这类模型能够理解语言并遵循指令,但特定工作流程通常需要更具体、专业或专有的上下文支持。
定制智能体可确定智能体在约束条件下的推理方式、智能体选择的工具、输出结构以及执行领域工作流的可靠性,从而解决这一难题。如需了解更多,请参考AI推理的定义。
智能体定制使用了哪些技术?
智能体定制技术涵盖从简单的提示调整到强化学习(RL)等高级方法,每种技术都在成本、复杂性和能力之间存在权衡。选择最佳方法取决于您是否需要更优质的信息、更明确的指令,或从根本上实现更稳定可靠的行为。下文将介绍主要的定制方法。其中,强化学习(RL)是其中一种关键技术,每种技术都有其成本、复杂性和能力的权衡。最佳方法取决于您是否需要更好的信息、指令或更可靠的行为。以下部分将介绍主要方法。
提示工程和系统提示
提示工程只需要在推理时将提示更改为智能体。这是最容易理解的技术,通常也是用于自定义智能体行为的第一种技术。标准代理可能需要人工调整系统提示。像 OpenClaw 这样的高级、自演进型智能体使用的提示词会由智能体自行更新,随着时间的推移会修改内存和指令,从而生成自我定制的智能体。
工作原理
您编写的系统提示词定义了智能体的角色、可用工具、输出格式和行为约束。该模型利用其现有功能遵循这些指令。
以下是系统提示示例:
You are an expert CLI assistant. Translate user requests into structured JSON tool calls. Respond with ONLY a JSON object. Set unused flags to null. |
何时使用
- 快速迭代智能体行为
- 处理以自然语言清晰描述的自定义任务
- 在进一步投资之前进行原型设计或试验
限制
- 对于复杂的推理链,提示可能会变得脆弱
- 随着指令变得更长、更微妙,性能会降低
- 模型可能无法始终遵循复杂的格式要求
- 不扩展模型的核心功能
- 切换为智能体提供支持的模型需要重新测试提示词
每个智能体项目都需要迭代提示工程和优化。但是,让智能体可靠地生成结构化输出、遵循特定领域逻辑或处理边缘情况可能需要改进。请注意,自我进化的智能体使用工具完善自己的提示词。
检索增强生成
检索增强生成(RAG) 通过从外部知识源(如 向量数据库)动态检索最新相关信息,克服了基础模型的知识局限。当智能体被引入模型上下文时,检索到的内容会作为推理依据,从而显著减少幻觉现象,并能有效回答涉及自定义、专有或快速变化领域的问题,且无需重新训练模型。
工作原理
当用户查询智能体系统时,系统会在向量数据库或文档存储中搜索与查询相关的数据。然后,检索到的内容与用户查询一起发送到模型,对两者进行推理并返回有根据的响应。
何时使用
- 让智能体能够访问最新知识或专有知识
- 根据权威来源的回复减少幻觉
- 使用变化频繁且重新训练的知识库是不切实际的
限制
- 增加检索导致的延迟
- 不会添加新的推理能力,仅添加新的信息
- 上下文窗口限制限制了检索到的信息的使用量
标准 RAG 正逐步演进为代理式 RAG,智能体能够自主判断需要检索哪些文档、重写哪些查询,以及何时已获取足够的信息。如需在浏览器中体验交互式编码,请查看如何构建代理式 RAG 应用学习模块。
智能体工具和技能注入
工具和技能注入通过为智能体提供工具或技能来扩展智能体的能力:
- 工具:与外部软件交互的可调用函数
- 技能:完成任务的特定领域指令
借助这些模块化、可重复使用的组件,您可以轻松地为特定领域定制通用模型,而无需修改其底层权重。
工作原理
Web 搜索、文件 I/ O、shell 执行和 API 调用等工具在智能体的系统提示或上下文中定义。技能 (可能包括指令、脚本和资源) 被加载到智能体的上下文中。
可能会在以下示例文件目录中找到用于事件分类的技能:
skills/ incident-triage/ SKILL.md README.md scripts/ collect_logs.sh parse_logs.py summarize_findings.py templates/ triage_report.md examples/ sample_incident.json |
The SKILL.md might look like the following:
SKILL.md 可能如下所示:
# Skill: Incident Triage (Log Collection + Summary)## PurposeCollect diagnostic logs for a given service, extract key error signals, and produce a shorttriage report with:- suspected root cause(s)- top error signatures- timeline highlights- immediate next steps## When to UseUse this skill when the user asks to:- investigate an outage / regression- summarize logs for a service between two timestamps- produce a quick incident report## Inputs (Required)- service_name: string (e.g., "payments-api")- start_time: ISO8601 string (e.g., "2026-03-05T10:00:00Z")- end_time: ISO8601 string (e.g., "2026-03-05T11:00:00Z")## Inputs (Optional)- environment: string (default "prod")- log_source: string (default "journald") # could be "file", "cloud", etc.- output_dir: string (default "./out")- redact: boolean (default true)## Outputs- {output_dir}/raw_logs.txt- {output_dir}/events.jsonl- {output_dir}/summary.md## Workflow1) Collect logs: - Run `scripts/collect_logs.sh` to fetch raw logs for the time window2) Parse logs into structured events: - Run `scripts/parse_logs.py` to emit JSONL events (timestamp, level, message, signature)3) Summarize: - Run `scripts/summarize_findings.py` to produce a markdown report using `templates/triage_report.md`## Commands (How to Call)### Step 1: Collect```bashbash scripts/collect_logs.sh \ --service payments-api \ --start "2026-03-05T10:00:00Z" \ --end "2026-03-05T11:00:00Z" \ --env prod \ --out ./out/raw_logs.txt``` |
何时使用
- 扩展智能体的功能,而非其推理方式
- 将智能体系统连接到外部软件、API 或其他第三方组件
- 为智能体提供模块化、可组合的功能
限制
- 模型需要调用工具作为基础能力
- 复杂的工具编排可能需要对可靠性进行微调
- 技能定义会占用上下文窗口空间
监督式微调
监督式微调 (SFT) 用于使用标记数据集调整模型权重,从而修改预训练模型的行为。与以前在推理时自定义智能体行为的技术不同,SFT 是在训练时执行的,用于修改底层模型的行为。
工作原理
您需要组装一个示例数据集,每个示例都包含输入 (自然语言请求) 和理想输出 (例如结构化 JSON 工具调用) 。该模型基于这些示例进行训练,并学习复制已演示的行为。
合成数据生成(SDG) 工具如 NVIDIA NeMo Data Designer 可显著加快这一过程,尤其适用于人工标注样本稀缺的低资源领域。团队无需手动编写每个训练样本,而是可以定义数据模式,并利用 大语言模型(LLM) 生成多样化且高质量的训练数据对。随后,可借助 NVIDIA NeMo 框架 等先进的微调工具,使用生成的数据集进行监督微调(SFT)。
何时使用
- 使用输出示例处理可访问的数据,以执行定义明确的任务
- 针对标记示例有限的低资源领域自定义模型,并生成高质量合成数据来引导微调数据集
- 要求模型可靠地生成特定的输出格式 ( JSON 模式、工具调用、结构化数据)
限制
- 质量完全取决于训练数据的质量;模型会学习模仿数据的质量,无论数据的质量如何
- 如果数据不够多样化,可能会过拟合到训练分布 (灾难性的遗忘)
- 需要训练所需的计算资源
SFT 通常是智能体定制流程中基于训练的第一步。它建立了下游比对方法可以完善的基准行为。
参数高效微调
完全微调 (例如 90 亿参数模型) 需要大量 GPU 资源来调整所有权重。低秩自适应 (LoRA) 和量化低秩自适应 (QLoRA) 等参数高效微调 (PEFT) 方法描述了一种可与 SFT 一起使用的更新机制,可在仅修改一小部分参数的情况下冻结大多数模型权重。
这种方法在保留完整训练大部分优势的同时,显著降低了多个专用AI模型的存储开销。PEFT是现在的智能体微调的实际标准,类似于专用AI模型。
工作原理
LoRA 将小型可训练矩阵注入模型的注意力层和前馈层,使您只需训练少量参数,而无需更新大型模型的全部参数。例如,NVIDIA Nemotron 3 Nano 共有 300 亿个参数,每次前向传播约有 35 亿个活跃参数。使用 LoRA 时,大型基础模型保持不变,您可以根据不同任务、领域或客户需求灵活更换相应的适配器。
QLoRA 通过将基础模型量化为 4 位精度来扩展这一点,从而对超出可用 GPU 显存的模型进行微调。在实践中,选择使用 LoRA 的 SFT 是实现实用自定义的捷径,而无需承担微调的全部成本。
需要多个高端 GPU 进行完全微调的模型通常可以在单个 GPU 上进行 LoRA 调优。如此一来,无需庞大计算预算的团队便可实现定制化。
何时使用
- 使用有限的 GPU 资源
- 维护基础模型的多个专用版本
- 需要快速迭代和快速训练周期
限制
- 重新训练模型权重的某个子部分会限制可能的更改程度 (质量上限)
直接偏好优化
虽然 SFT 模仿的是很好的示例,但直接偏好优化 (DPO) 基于成对偏好比较来训练模型。偏好信号可以来自人工标注器、LLM 评委、基于规则的验证器或合成生成的偏好数据,因为 DPO 与偏好信号源无关。与基于人类反馈的强化学习 (RLHF) 不同,偏好信号消除了对单独奖励模型的需求,使 DPO 在 SFT 基准存在后作为优化步骤变得有效。
工作原理
您为相同的输入收集或生成响应对:一个首选,一个拒绝。这些数据对可以手动生成、根据真实用户交互进行精选,也可以通过合成数据生成工作流生成。
例如,在低资源领域中,LLM 可以根据授权、模式或验证器生成候选响应和偏好标签,然后人类可以对结果进行质量评审或抽样审核。DPO 算法使用成对对比损失将更高的概率分配给首选响应,从而更大限度地提高首选响应相对于被拒绝响应的相对对数概率。
何时使用
- 使用主观回复质量 (语气、风格、实用性、安全性)
- 使用多个有效输出,但有些输出明显优于其他输出
- 需要根据偏好进行调整,而无需全 RLHF 的复杂性
- 执行 SFT 后进一步优化输出质量
限制
- 需要高质量的偏好对,无论是人工编写还是人工合成
- 如果未经验证,合成偏好数据可以对判断偏差、弱项或不切实际的示例进行编码
- 对于具有严格可验证的正确答案的任务,效率较低
强化学习
强化学习 (RL) 技术是机器学习的一个子类。下面介绍的技术是可专门用于自定义智能体的 RL 变体,以及为其提供支持的 LLM。
根据人类反馈进行强化学习
RLHF 是一种功能强大且资源密集型的技术,可根据人类偏好调整语言模型。它采用两个阶段的过程:首先,训练奖励模型 (一个单独的神经网络) 来预测人类偏好,然后使用该模型作为自动判断器,在 RL 训练期间对输出进行评分。这有助于捕捉细微的质量标准,如语气、实用性和安全性。
工作原理
人工标注器按质量对模型输出进行排序。这些排名训练的奖励模型可以预测人类偏好。然后,使用 RL 算法对智能体进行训练,以更大限度地提高奖励模型的分数,同时保持接近其原始行为。
何时使用
- 协调无法通过简单指标捕获的复杂比对目标
- 使用大量人工标注资源
- 需要细致入微的行为塑造 (安全性、实用性、伤害避免)
限制
- 复杂的实现 – 需要同时管理多个模型 (例如。策略、引用、奖励、评论家)
- 计算成本高昂且容易出现训练不稳定性
- 奖励模型可能会博或错误指定 (奖励黑客行为)
具有可验证奖励的强化学习
RLHF 式的方法依赖于习得的奖励模型,这些模型的训练成本高昂,可能不精确或可进行游戏。设计奖励模型的流程和系统非常广泛。对于答案正确/ 错误的任务 (如有效的 JSON、正确的 API 调用或通过测试) ,具有可验证奖励 (RLVR) 的强化学习可以从可靠的验证器中提供可审计、可重复的奖励信号,从而减少从这些学习到的奖励模型中产生的一些模糊性。
工作原理
RLVR 不是根据人类偏好训练奖励模型,而是使用确定性验证函数,以客观和透明的方式评估输出的正确性。
假设有一个经过训练的智能体,可以将自然语言转换为 CLI 命令。验证函数会解析模型的 JSON 输出,检查命令是否正确,将每个标志与预期值进行比较,并计算精确的奖励分数:
- 精确匹配:奖励 = +1.0
- 正确的命令,部分标志:奖励与标志的准确性成正比
- 命令错误或 JSON 无效:奖励 = -1.0
NVIDIA NeMo Gym 使用这种方法,提供验证端点,在训练期间根据真实情况对模型输出进行评分。
何时使用
- 处理具有可客观验证的正确输出 (结构化数据、CLI 命令、代码、数学推理、工具调用) 的任务
- 需要透明、可审计的奖励信号
- 需要提高推理质量,超越表面级别的回答能力
限制
- 仅适用于具有确定性正确性标准的任务
- 不适合创作、主观或开放生成
- 需要构建验证基础设施 (尽管 NeMo Gym 等框架简化了这一点)
RLVR 是 DeepSeek-R1 实现突破性推理能力的关键技术,表明可验证的奖励能够教会模型复杂的解题策略,有时甚至无需以监督微调作为起点。NVIDIA NeMo RL 和 NeMo Gym 等开源库可帮助开发者实现大规模训练。NVIDIA NeMo RL 和 NeMo Gym 等开放库可帮助开发者进行大规模训练。
组相对策略优化
组相对策略优化 (GRPO) 是一种高效的策略优化算法,可与 RLVR 自然搭配。它为每个提示生成多个补全,并将 PPO 的评论家网络替换为与组相关的基准,以指导改进。这样可以减少计算开销,保持训练的稳定性和有效性。
工作原理
对于每个训练提示词,GRPO 会根据当前策略生成多个完成值 (通常为 4 到 64) 。每个完成的分数由奖励函数打分。GRPO 不是使用评论家网络来估计基准 (就像 PPO 那样) ,而是根据组均值和标准差对其奖励进行归一化,以此计算每次完成的优势。高于平均值优势的完成值得到强化;低于平均值的完成值被抑制。
何时使用
- 应用 RLVR 并需要高效的优化算法
- 处理受限的计算资源
- 需要稳定的 RL 训练,而无需像 PPO 评论家那样复杂
限制
- 每个提示需要生成多个完成,与监督式方法相比,增加了每步的训练计算量
- 对于小组规模,基于组的基准可能存在噪声,因此需要对组规模超参数进行额外调整
- 有效性取决于精心设计的奖励函数;奖励定义不当会导致策略更新不佳
GRPO 是为 DeepSeek-R1 训练提供支持的优化算法。它正日益成为基于 RL 的智能体自定义的默认选择,尤其是在与可验证的奖励搭配使用时。
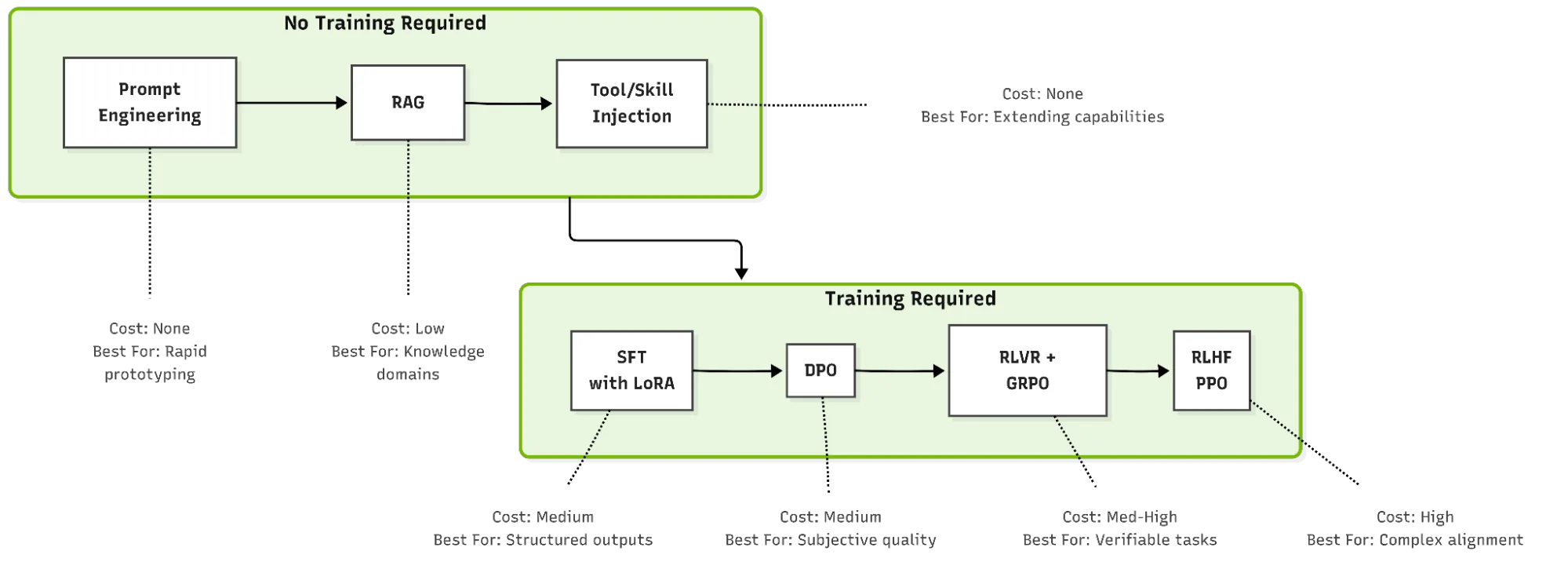
什么是用于定制 AI 智能体的多阶段工作流?
在实践中,最有效的智能体定制按顺序结合了多种技术。代表性工作流的各个阶段概述如下。
第 1 阶段:提示工程、工具和技能以及 RAG
从系统提示、工具和技能定义以及检索开始,建立基准行为。
第 2 阶段:SDG
对于仅凭提示词、工具和向量数据库无法实现的自定义功能,请生成数据以通过训练自定义智能体。
第 3 阶段:SFT
SFT 会教授模型自定义任务的基本词汇、格式和结构。
第 4 阶段:RLVR/ GRPO 或 DPO
使用基于偏好或 RL 来改进 SFT 模型,以提高模仿学习所能达到的质量。选择和排序取决于任务:
- DPO 通常成本更低、更稳定,在存在偏好对(由人类、大语言模型评审或基于规则的验证器提供)但缺乏可靠标量奖励时表现良好。
- 当输出可以客观验证时,采用 GRPO 的 RLVR 是合适的工具,并且需要提高推理质量,而不仅仅是偏好学习。
这些并不是严格的替代方案。常见的模式是 SFT+ DPO+ RLVR。DPO 首先用于在 SFT 策略的基础上合理地调整格式和风格,然后 RLVR 在存在可验证奖励的情况下推动更困难的推理收益。顺序是设计选择,而不是固定的配方。
第 5 阶段:评估和迭代
衡量任务成功率、工具调用准确性和任何其他所需指标。使用结果在自定义阶段进行迭代,直到实现所需的性能。
此工作流反映了该领域正在融合的原则:从轻量级开始,严格测量,并仅在数据显示需要时增加复杂性。
如何选择合适的智能体自定义方法
影响定制方法的因素有三个:任务特征、可用资源和项目成熟度。
任务特征
如果智能体的输出能够得到客观验证 (正确的 JSON、通过测试、有效的 API 调用) ,那么使用 GRPO 的 RLVR 可能是您利用效率最高的技术。如果质量主观,DPO 更合适。如果任务定义明确,但模型只需要示例来模仿,则 SFT 可能就足够了。
可用资源
完整的 RLHF 需要大量的计算和人工标注预算。基于 LoRA 的 SFT 可以在单个 GPU 上运行。提示工程不需要计算。将您的技术与基础架构相匹配。
项目成熟度
早期项目应投资于提示工程、评估基础设施和工具定义。一旦您拥有清晰的指标、已识别的故障模式和足够的数据来解决这些问题,基于训练的自定义功能就能为您带来最大的价值。
开始使用 AI 智能体定制
智能体定制包含一系列方法,如果经过周密应用,这些方法的有效性会更高。最成功的团队从轻量级方法开始,在早期评估中进行投资,并在基于训练的技术层中进行测量,这表明他们需要这些技术。
定制和评估协同工作,以推动实现更好的结果。无法改善无法衡量的东西。每个定制决策 (从提示调整到 GRPO 训练运行) 都应由明确的指标驱动,并根据实际性能进行验证。
准备好自定义智能体了吗?借助 NVIDIA NeMo 加速开发,它提供了一个集成工具包,涵盖:
- 使用 NeMo Data Designer 生成合成数据
- 使用 NeMo Automodel、NeMo Megatron-Bridge 和 NeMo RL 自定义模型
- 使用 NeMo Gym 的可验证奖励基础设施
- 使用 NeMo Agent Toolkit 进行智能体编排和评估
这些工具旨在与现有的智能体框架集成,无需从头开始重建即可添加自定义、评估和优化功能。