
代理式系统通常会在单个感知到动作循环中跨屏幕、文档、音频、视频和文本进行推理。但是,它们仍然依赖于碎片化的模型链,即视觉、音频和文本的单独堆栈。这增加了推理跳跃和编排的复杂性,推高了推理成本,同时削弱了跨模态上下文的一致性。
NVIDIA Nemotron 3 Nano Omni,是 Nemotron 3 系列的全新成员,将统一的多模态推理整合到一个高效且开放的单一模型中。该模型旨在取代分散的视觉、语言与音频堆叠方案,作为代理系统中实现多模态感知和上下文理解的智能子单元。
这样,智能体可以在单个共享的感知到动作循环中感知和推理视觉、音频和文本输入,从而提高收性并降低编排复杂性和推理成本。
它在 MMlongbench-Doc 和 OCRBenchV2 等文档智能榜单上表现出色,准确率领先,同时在视频与音频理解、WorldSense、DailyOmni 及 VoiceBench 方面也位居前列。
除了准确性,MediaPerf 作为一个开放的行业基准,用于评估视频理解模型在真实媒体数据和实际生产任务下的质量、成本和吞吐量表现。结果显示,Nemotron 3 Nano Omni 在每项任务中均实现了最高吞吐量,并在视频级标注任务中达到最低推理成本。点击此博文了解详情。
Nemotron 3 Nano Omni 基于 30B+ A3B 混合专家模型 (MoE) 架构构建,可激活每个任务和模式所需的专家,以大规模实现高吞吐量和强大的多模态性能。借助完全开放的权重、数据集和方法,开发者可以在本地、云和企业环境中自定义、部署和集成多模态子智能体。
视频 1. NVIDIA Nemotron 3 Nano Omni 在开放式 MoE 架构中统一了视频、音频、图像和文本
出色的效率和准确性
Nemotron 3 Nano Omni 支持跨多个 GPU 架构 (包括 NVIDIA Ampere、NVIDIA Hopper 和 NVIDIA Blackwell GPU 系列) 以及热门推理引擎 (包括 vLLM 和 NVIDIA TensorRT-LLM) 的硬件感知优化推理。
它支持 FP8 和 NVFP4 量化,高效视频采样,以及 NVIDIA® 优化内核,可实现可预测的低延迟推理。结合基于卷积 3D+ 的时空处理,这些优化能够在从工作站到数据中心和云部署的各类 GPU 上,持续实现多模态感知,并降低计算成本。
Nemotron 3 Nano Omni 专为驱动子智能体而设计,可在更大的智能体系统中实现感知、上下文维护和多模态理解。它与执行和规划模型 (例如 NVIDIA Nemotron 3 Super 和 NVIDIA Nemotron 3 Ultra) 完全集成,可保持智能体架构的模块化、高效率和可扩展性。
以下基准测试用于评估固定交互性值下的性能,该值是指每个用户继续体验响应灵敏的实时交互的点。评估并未最大化原始并发性,而是在 x 轴上保持每个用户的吞吐量 (每个用户每秒词元) 常数,并测量在不降低用户体验的情况下可以维持的系统总吞吐量。
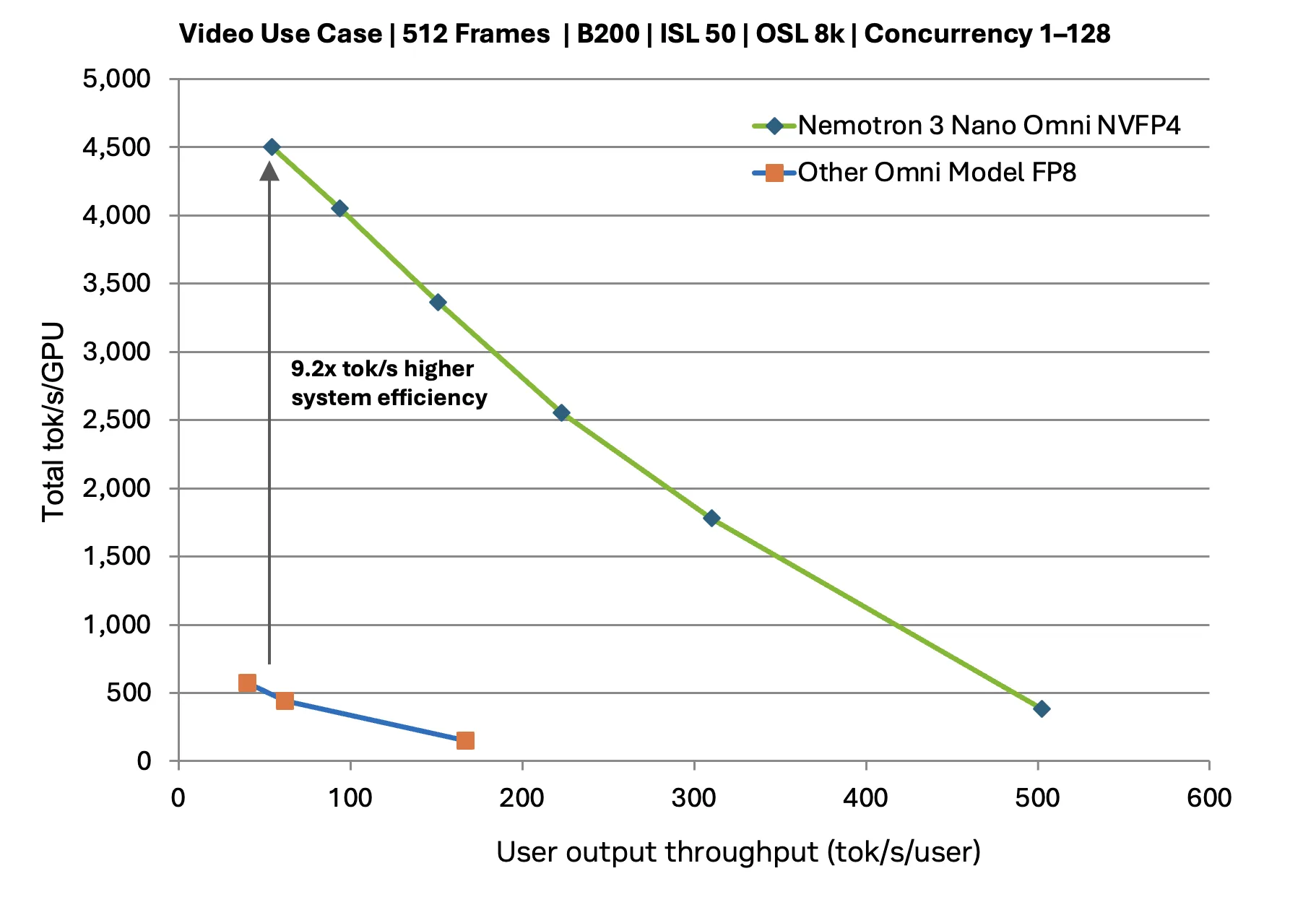
对于相同交互性值下的视频推理,Nemotron 3 Nano Omni 可维持更高的聚合吞吐量,与其他开放 Omni 模型相比,可将有效系统容量提高约 9.2%。
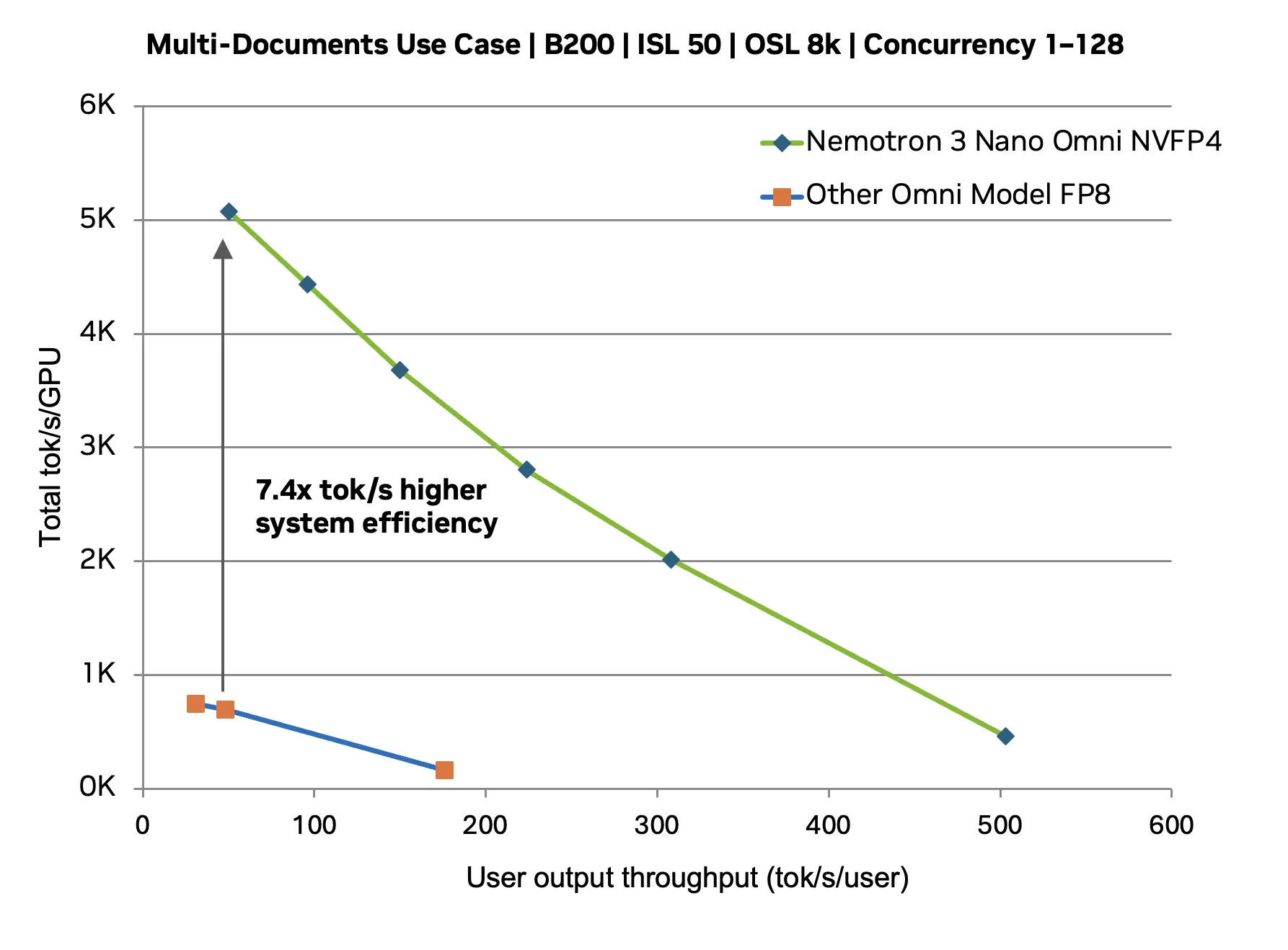
对于相同交互性值下的多文档推理,Nemotron 3 Nano Omni 可维持更高的聚合吞吐量,与其他开放 Omni 模型相比,可将有效系统容量提高约 7.4%。
在 Blackwell GPU 上,采用 NVFP4 量化的 Nemotron 3 Nano Omni 在开放式全模态模型中实现了最高的吞吐量,适用于涉及复杂文档、长视野推理和大型视频批量的企业级工作负载。这些功能使其非常适合金融、医疗健康、科学发现、媒体和娱乐领域的代理式应用,以及大规模处理大量视频和音频内容的广告技术平台。
这种改进并非合成基准测试结果。它反映了在真实代理式工作负载中部署 Nemotron 3 Nano Omni 时的架构效率。通过将多模态感知统一到单个模型循环中,并仅激活每个模态所需的专家,它可以在不牺牲准确性或响应能力的情况下,将原始模型效率转换为更多并发代理、更高的吞吐量和更低的单项任务成本。
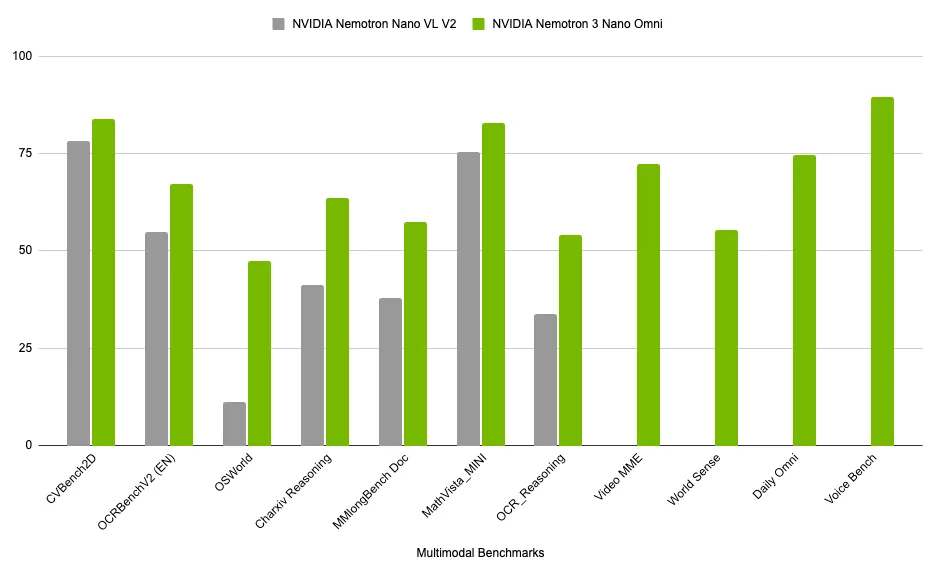
Nemotron 3 Nano Omni 的功能是什么?
Nemotron 3 Nano Omni 是一款轻量级 30B-A3B 模型,专为具有高吞吐量的跨模态推理而设计。
模型设计:Nemotron 3 Nano Omni 架构
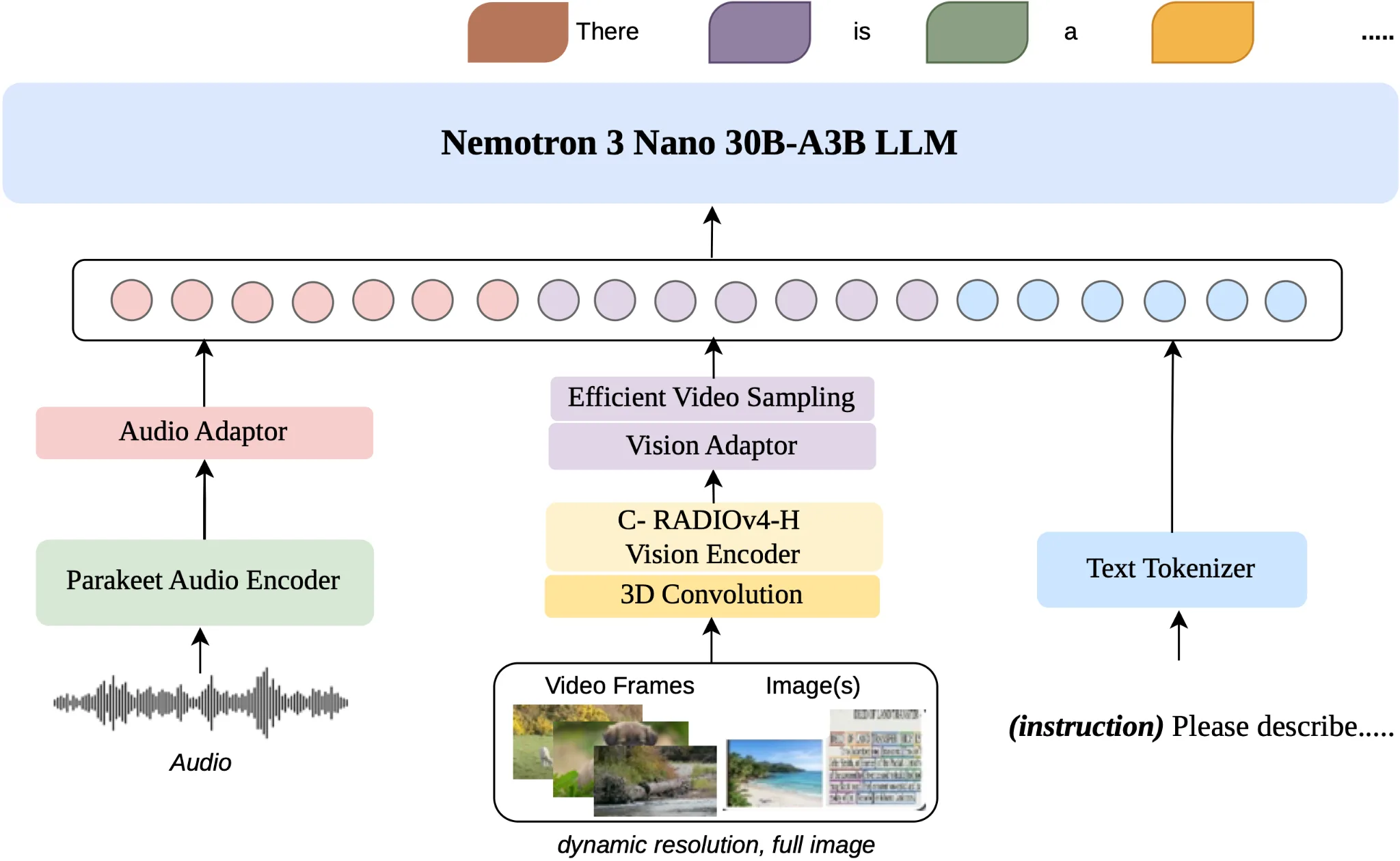
Nemotron 3 Nano Omni 架构将多模态感知和推理引入单个 30B 混合 MoE 模型,原生支持文本、图像、视频和音频输入,同时在智能体循环中维护统一的多模态上下文,无需单独的视觉、语音和语言模型。
- 混合 MoE 核心架构: 结合用于序列处理和内存效率的 Mamba 层,以及用于精确推理的 Transformer 层。该设计可显著提升吞吐量,使内存和计算效率最高提升 4 倍,适用于次级智能体角色。
- 时空视觉处理与高效视频采样:为有效处理视频帧,Nemotron 3 Nano Omni 采用 3D 卷积来捕捉帧间的运动信息。在推理过程中,高效视频采样(EVS)层将来自多帧的高密度视觉词元压缩为一个简洁的集合,避免视觉词元过多导致 LLM 的上下文窗口过载。
- 多模态架构
- 文本: Nemotron 3 Nano Omni 模型采用强大的文本模型作为核心解码器,在保留基础模型语言能力的同时,围绕后文详述的文本训练跨模态桥接器。这种方法降低了多模态训练的不稳定性与成本,同时提升了连续感知任务的效率与准确性。
- 音频: NVIDIA Granary、Music Flamingo 和 Parakeet
音频集成基于 NVIDIA Parakeet 编码器及专用数据集构建,不仅限于简单的语音转录,具备更强的音频理解能力。 - 视觉: 为应对高分辨率图像与动态视频的处理需求,Nemotron 3 Nano Omni 采用分层压缩策略,结合 C-RADIOv4-H 与基于编码器的视频摘要技术。
- C-RADIOv4-H: 采用 C-RADIOv4-H 基础模型处理高分辨率图像。该模型作为高性能视觉编码器,能够在保留高分辨率细节与实现高效计算之间取得良好平衡,并可聚焦于图像的特定区域,从而保持 OCR 的精度。
训练方法:跨模态数据和训练
Nemotron 3 Nano Omni 模型经过跨模态数据和指令微调训练,专为现实世界智能体环境设计。该模型可遵循涵盖图像、视频、音频和文本的指令,在更大型的智能体系统中承担多模态感知与上下文子智能体的功能。所有训练阶段均使用 NVIDIA NeMo Evaluator 库进行评估。
- 适配器和编码器训练: 涵盖文档、屏幕截图、音频和视频的大规模数据,可在企业感知任务中实现强大的泛化。
- 监督式微调(SFT): 采用 NVIDIA Megatron-LM 实现的多阶段工作流,逐步扩展模态覆盖范围,从视觉语言和音频编码器入手,逐步增加上下文长度(16K → 49K → 262K),以构建统一的跨模态指令遵循能力。
- 后SFT强化学习: 基于NVIDIA NeMo Gym和NeMo RL,在25种环境配置下实现多环境强化学习,部署超过230万个环境,显著提升多模态任务与智能体工作流的鲁棒性。
按设计开放:权重、数据和配方
Nemotron 3 Nano Omni 建立在透明的基础之上,提供对权重、数据集和训练方法的完整访问权限。借助这种开源方法,开发者可以在本地自定义模型,在不影响隐私和安全的情况下确保峰值性能。
模型权重
Nemotron 3 Nano Omni 的完整参数检查点可在 Hugging Face 上获取,且该模型也将以 NVIDIA NIM 微服务 的形式提供。NVIDIA Nemotron 开放模型许可证使企业能够灵活掌控数据,并支持在任意位置部署。
端到端训练与评估方案
为 Nemotron 3 Nano Omni 提供了完整的预训练、后训练及评估流程,覆盖从预训练到模型对齐的各个环节。开发者可借此复现训练过程,针对特定领域调整变体配置,或将其作为自定义混合架构研究的起点。
部署指南和方法
查看这些适用于主要推理引擎的即用型指南,其中每个指南都包含配置模板、性能调优指南和参考脚本:
- vLLM Cookbook:适用于 Nemotron 3 Nano Omni 的高吞吐量连续批处理和流式传输。
- SGLang Cookbook:针对多智能体工具调用工作负载优化的快速、轻量级推理。
- NVIDIA TensorRT LLM Cookbook:采用先进的 MoE 内核,全面优化 TensorRT LLM 引擎,实现生产级、低延迟部署。
- Dynamo 部署方案: 支持多模态 Nemotron 3 Nano Omni 的推理服务、智能路由、多层 KV 缓存及自动扩展。
微调指南和食谱
还提供适用于不同训练阶段的指南,每个指南都包含配置模板、性能调优指南和参考脚本:
- 使用 Nemotron 3 Nano Omni 的端到端多模态文档智能指南 指南。
- 使用 NVIDIA NeMo Megatron-Bridge 在 Nemotron 3 Nano Omni 上运行 LoRA SFT。
- 使用 NVIDIA NeMo Automodel 在 Nemotron 3 Nano Omni 上运行 LoRA SFT。
- 使用 NeMo RL recipe 和 cookbook 在 Nemotron 3 Nano Omni 上运行 GRPO/MPO。
NVIDIA 推出了一个全面的开放数据堆栈
依托 Nemotron 3 Nano 和 Nemotron 3 Super,专为基于文本的代理式 AI 设计,包含超过 10 万亿的预训练词元、4000 多万个后训练样本、20 多种强化学习环境配置,以及完整的训练方法,全部内容均已公开。
Nemotron 3 Nano Omni 将这一承诺从文本扩展到多模态,为文本、音频、图像和视频提供同等程度的开放性。
- 适配器和编码器的训练规模: 1270亿词元,涵盖文本+图像、文本+视频、文本+音频,以及文本+视频+音频的混合模式,真实反映现实世界中多模态与单模态数据的交互。
- 现实世界任务的后训练: 约 1.24 亿个精选样本,涵盖多种多模态组合(文本+音频、文本+图像、文本+视频,以及文本+视频+音频),结构化设计用于支持文档推理、计算机操作和长周期工作流程。
- 用于智能体训练的强化学习环境:包含20个RL数据集,覆盖25个环境中的5项新多模态任务——视觉定位、图表与文档理解、视觉导向的STEM问题、视频理解及自动语音识别,将Nemotron的强化学习工作流从文本拓展至视觉与音频领域。
NVIDIA NeMo Data Designer 合成数据生成
此外,还提供了基于 NVIDIA NeMo Data Designer 构建的合成数据生成(SDG) 工作流,用于在复杂的长文档理解任务中对 Nemotron 3 Nano Omni 进行后训练。通过迭代式的工作流开发、训练和故障分析,最终将一系列生成约 1140 万个合成视觉问答对(450 亿词元)的工作流整合到 Nemotron 3 Nano Omni 的训练数据混合中。
深入了解迭代式 SDG 方法、成功与否,以及整套工作流方案。SDG 工作流也可作为数据设计师的参考方案提供 参考方案。
图像训练数据已通过许可方式发布在 huggingface.co/datasets/nvidia/Nemotron-Image-Training-v3。借助底层图像数据和模型,开发者可对多模态训练流程进行检查、调整和扩展。对于过去长期将视觉、语音和文档数据堆栈彼此隔离的企业,Omni 将这些数据整合到一个统一的、可用于生产的平台,显著降低了跨模态部署代理式 AI 的门槛。
由 Nemotron 3 Nano Omni 提供支持的 Claws
当与 NVIDIA OpenShell 运行时和各种智能体结合使用时,Nemotron 3 Nano Omni 可以改变与视频内容的交互:
- 原生视频理解: 与依赖转录且容易产生幻觉的传统系统不同,Nemotron 3 Nano Omni 采用原生视觉-时间流技术(结合 3D 卷积和高效视频采样),直接分析屏幕上的内容。这实现了近乎实时的高保真转录与摘要,能够捕捉纯音频模型所忽略的视觉信息(如图表或屏幕文字)。
- 注重隐私的 Claw 智能体: 通过 NemoClaw 运行该系统,用户视频数据始终保留在本地基础设施中,不会外泄。 NVIDIA NemoClaw 在 NVIDIA OpenShell 沙盒环境中,经由隐私路由器部署 OpenClaw 代理,确保敏感信息的安全;同时,由 Nemotron 3 Nano Omni 驱动的子代理负责执行多模态理解等专业任务。
- 精准问答: 借助先进的多模态推理能力,用户可针对视频内容提出复杂且开放性的问题。该智能体利用 Nemotron 3 Nano Omni 的长上下文窗口,在不丢失关键信息的前提下,提供有依据的准确回答。
请参阅以下指南,详细了解如何在 NemoClaw 沙盒中使用 OpenClaw 运行 Nemotron 3 Nano Omni,以及使用 OpenShell 运行 Hermes Agent。从本地部署到现实世界的视频推理,全面掌握实际操作流程。
开始使用 Nemotron 3 Nano Omni
Nemotron 3 Nano Omni 现已推出,这是一种开放、高效的多模态模型,专为智能体工作负载中的子智能体提供支持而构建。您可以通过以下方式访问:
- Hugging Face 和 OpenRouter。
- 借助 SGLang 和 vLLM 进行推理。
- 本地运行时和工具(如 Ollama、llama.cpp、推理快照、LM Studio 和 Unsloth)可用于在设备上运行 GGUF 检查点。
- 主要云服务提供商,包括 Amazon Web Services 和 Oracle Cloud Infrastructure。即将登陆 Microsoft Foundry。您可浏览模型目录,并在 Azure 环境 中直接使用 Nemotron 模型。
- Baseten、Baseten、Canonical、Clarifai、DeepInfra、Eigen AI、fal.AI、FriendliAI 和 Fireworks AI 等推理服务提供商。
- NVIDIA 云合作伙伴,包括 BitDeer AI, Crusoe, DigitalOcean, GMI Cloud, Lightning AI, Nebius, Together AI, 和 Vultr.
- 适用于本地和混合企业部署的 Dell Technologies。
- NVIDIA NIM 提供经 NVIDIA® 优化的体验,可轻松从 NVIDIA 官网 build.nvidia.com 启动优化后的可移植推理,并在工作站、云端等任意环境中运行推理。
- NeMo Curator,用于使用此 recipe 创建视频字幕工作流。
- Jetson AI 实验室 为开发者提供教程和模型性能测试,帮助运行经过优化的 Nemotron 模型,用于构建机器人和边缘 AI 应用。
如需深入了解模型架构和设计,请参阅 Nemotron 3 Nano Omni 技术报告。
访问 Nemotron 开发者页面以获取入门资源。在 Hugging Face 上探索开放 Nemotron 模型与数据集,以及 Blueprints 在 build.nvidia.com。
在 Nemotron 直播、教程,以及在 NVIDIA 论坛 上与开发者社区互动。