
MiniMax M2.7 的发布为流行的 MiniMax M2.7 模型增加了增强功能,该模型专为代理式线束以及推理、ML 研究工作流程、软件、工程和办公室工作等领域的其他复杂用例而构建。MiniMax M2.7 的开源权重版本现已通过 NVIDIA 和整个开源推理生态系统提供。
MiniMax M2 系列是稀疏混合专家 (MoE) 模型系列,专为提高效率和功能而设计。MoE 设计可保持较低的推理成本,同时保留 230B 参数模型的全部容量。它使用通过旋转位置嵌入 (RoPE) 和 Query-Key 根均方归一化 (QK RMSNorm) 增强的多头因果自注意力,实现大规模稳定训练。top-k 专家路由机制可确保只有最相关的专家才能为任何给定的输入激活,即使模型的总参数数量很大,也能保持较低的推理成本。因此,经过调优的架构能够出色应对编码挑战和复杂的代理式任务。
| MiniMax M2.7 | |
| 模式 | 语言 |
| 总参数 | 2300 亿 |
| 活动参数 | 100 亿 |
| 激活率 | 4.3% |
| 输入上下文长度 | 20 万 |
| 其他配置信息 | |
| 专家 | 256 名本地专家 |
| 根据词元激活专家 | 8 |
| 图层 | 62 |
使用 NVIDIA NemoClaw 构建长期运行的智能体
NVIDIA NemoClaw 是一个开源参考堆栈,只需一条命令,即可更安全地简化运行 OpenClaw 始终开启的助手。它安装 NVIDIA OpenShell 运行时,这是一个安全的环境,用于运行具有端点或开放模型 (如 M2.7) 的自主代理。开发者可以立即开始使用此 一键式启动程序 ,在 NVIDIA Brev 云 AI GPU 平台上使用 OpenClaw 和 OpenShell 置备环境。
使用开源框架优化推理
为了更大限度地提高 MiniMax M2 系列模型的性能,NVIDIA 与开源社区合作,将高性能内核集成到 vLLM 和 SGLang 中。这些优化专门针对大规模 MoE 模型的架构需求:
- QK RMS Norm 内核:此优化将计算和通信操作融合到单个内核中,以将查询和密钥归一化。内核可以更好地重叠计算和通信,减少内核启动和内存读取/ 写入用度,并提高推理性能。
- FP8 MoE:集成 NVIDIA TensorRT-LLM FP8 MoE 模块化内核。这个经过良好优化的内核专门针对 MoE 模型,提高了整体端到端性能。
以下是使用 1K/ 1K ISL/ OSL 数据集设置 NVIDIA Blackwell Ultra GPU 时的 vLLM 结果。这两项优化在 1 个月内将吞吐量提高了 2.5 倍。
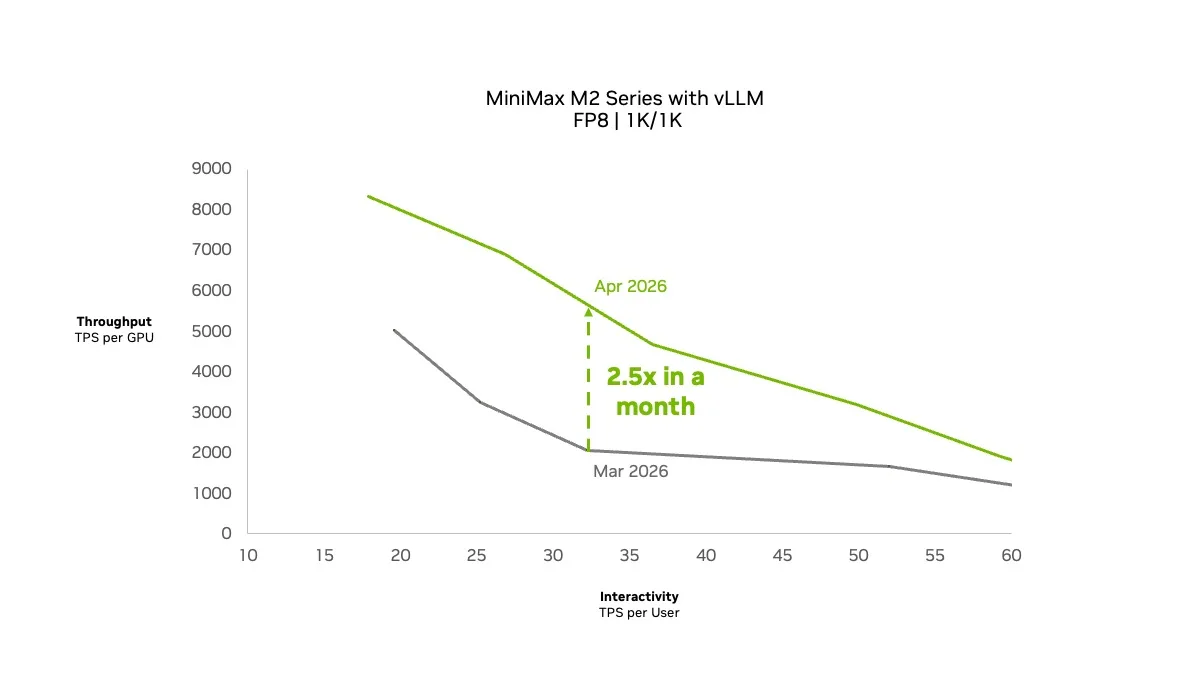
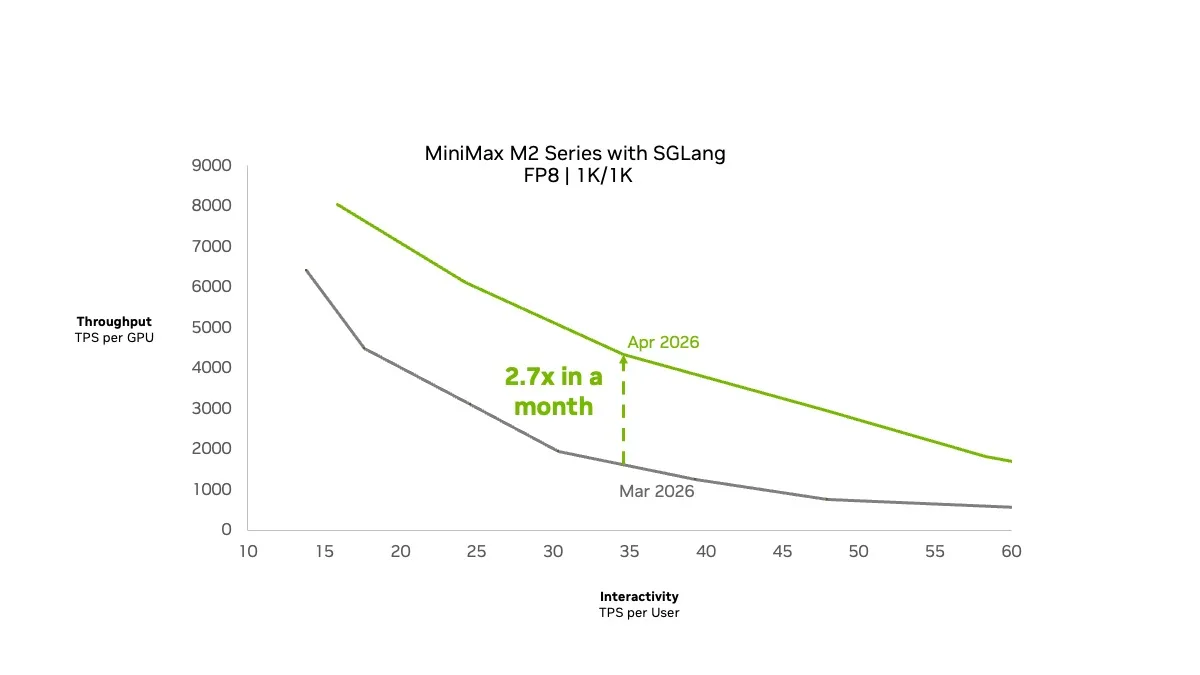
图 2 显示了 NVIDIA Blackwell Ultra GPU 上使用 1K/ 1K ISL/ OSL 数据集得出的 SGLang 结果。这两项优化在 1 个月内将吞吐量提高了 2.7 倍。
使用 vLLM 进行部署
使用 vLLM 服务框架部署模型时,请按照以下说明操作。如需了解更多信息,请参阅 vLLM 指南。
$ vllm serve MiniMaxAI/MiniMax-M2.7 \ --tensor-parallel-size 4 \ --tool-call-parser minimax_m2 \ --reasoning-parser minimax_m2_append_think \ --enable-auto-tool-choice \ --trust-remote-code \ --enable-expert-parallel |
使用 SGLang 进行部署
使用 SGLang 服务框架部署模型的用户可以使用以下说明。有关更多信息和配置选项,请参阅 SGLang 文档。
$ sglang serve \ --model-path MiniMaxAI/MiniMax-M2.7 \ --tp-size 4 \ --trust-remote-code \ --disable-radix-cache \ --max-running-requests 512 \ --mem-fraction-static 0.85 \ --cuda-graph-max-bs 512 \ --kv-cache-dtype fp8_e4m3 \ --quantization fp8 \ --stream-interval 10 \ --reasoning-parser=minimax-append-think \ --dtype bfloat16 \ --moe-runner-backend flashinfer_trtllm_routed \ --fp8-gemm-backend flashinfer_trtllm \ --enable-flashinfer-allreduce-fusion \ --scheduler-recv-interval 10 |
使用 NVIDIA 端点进行构建
通过托管在 NVIDIA GPU 上的免费 GPU+ 加速端点,开始使用 MiniMax M2.7 进行构建 。在 build.nvidia.com 上的浏览器中快速测试提示词,并使用您自己的数据评估性能。使用 NVIDIA NIM 扩展到生产 – 经过优化的容器化推理微服务,可在本地、云端或混合环境中部署。
使用 NVIDIA NeMo 框架进行后训练
要微调 MiniMax M2.7,请使用开源 NVIDIA NeMo AutoModel 库 ( NVIDIA NeMo 框架的一部分) 、M2.7 recipe 和 Hugging Face 上提供的最新检查点文档。用户可以使用自己选择的数据和 NeMo RL 库,以及样本方法 (8k 序列、16k 序列) 和参考 精度验证曲线,在 MiniMax M2.7 上执行强化学习。
开始使用 MiniMax M2.7
从 NVIDIA Blackwell 上的数据中心部署到完全托管的企业 NVIDIA NIM 微服务,再到微调,NVIDIA 为您提供集成 MiniMax M2.7 的解决方案。首先,请查看 Hugging Face 或 build.nvidia.com 上的 MiniMax M2.7 页面。