
现代 LLM 服务难以调优,因为每一次部署都是一组相互作用的选择堆栈:模型后端、张量并行形状、prefill/decode 拆分、工作进程数量、调度器设置、路由策略、KV 缓存行为、自动扩缩容阈值以及拓扑结构。这些选择会跨层相互影响,而局部改进可能会把瓶颈转移到别的地方。对于更大的模型,在我们弄清楚这个想法是否值得测试之前,即使一次现实可行的实验也可能需要很多 GPU 或节点。
这就是 DynoSim 的动机:一个 Dynamo 的双生体。
DynoSim 是一种基于工作负载的离散事件仿真系统,用于模拟 NVIDIA Dynamo 服务栈。它将实测的引擎前向传播时序、Mocker 调度器核心、Router 与 Planner 的行为、KV 缓存效应以及工作负载轨迹统一整合到一条虚拟时间线上。其目标并非进行纯理论分析或比特级精确的硬件仿真,而是在前向传播这一基本单元上实现真实可信的服务仿真,并能扩展至完整的推理栈——对我们而言,这就是 Dynamo,对许多人来说亦是如此。
DynoSim 不仅忠实,而且作为完整栈 Rust 实现也快得惊人。在一台 Apple M4 MacBook Air 上,单线程 Rust 离线回放使用八个轮询工作线程以及 512 令牌的轨迹和引擎块,在 2.41 秒的实际时间内模拟了包含 23,608 个请求的完整 Mooncake 轨迹。模拟的服务窗口为 60.1 分钟,速度约为真实时间的 1,500 倍。
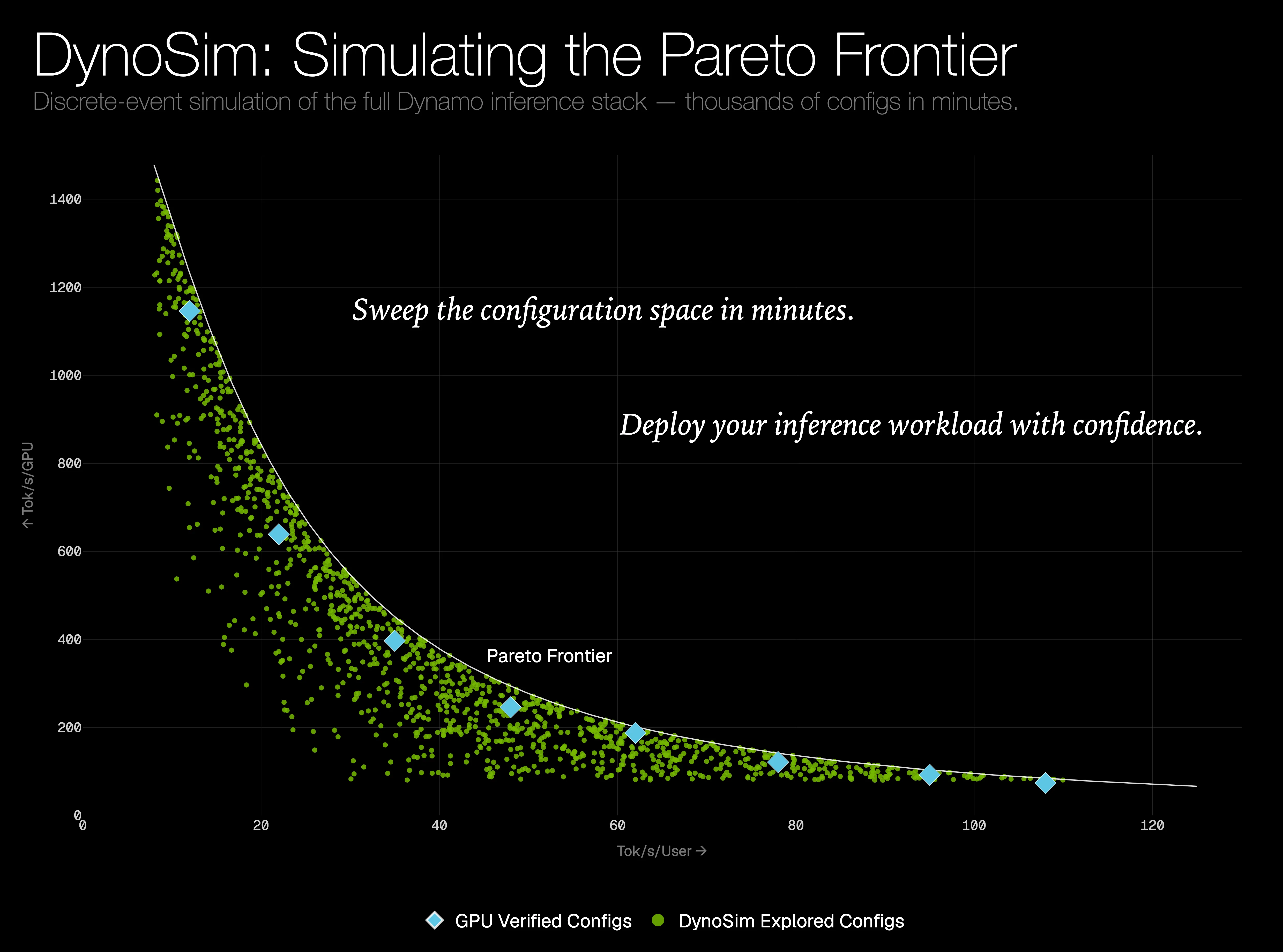
使用 DynoSim,可以通过一次参数扫描为现有硬件上的某个工作负载绘制帕累托前沿;而类 autoresearch 的工作流则可以为我们的组件提出算法层面的改动:更好的 Router 成本函数、Planner 启发式或缓存策略。
架构:将 Dynamo 作为事件来组合
一个关键的设计选择是组合。DynoSim 不是一个单体模型;它是一组运行在同一模拟时间线上的服务组件。回放框架驱动工作负载到达,单引擎模拟对工作线程本地调度和前向传播时序进行建模,而多引擎模拟则加入了只存在于工作线程之间的系统行为:路由、分布式缓存和 Planner 的决策。
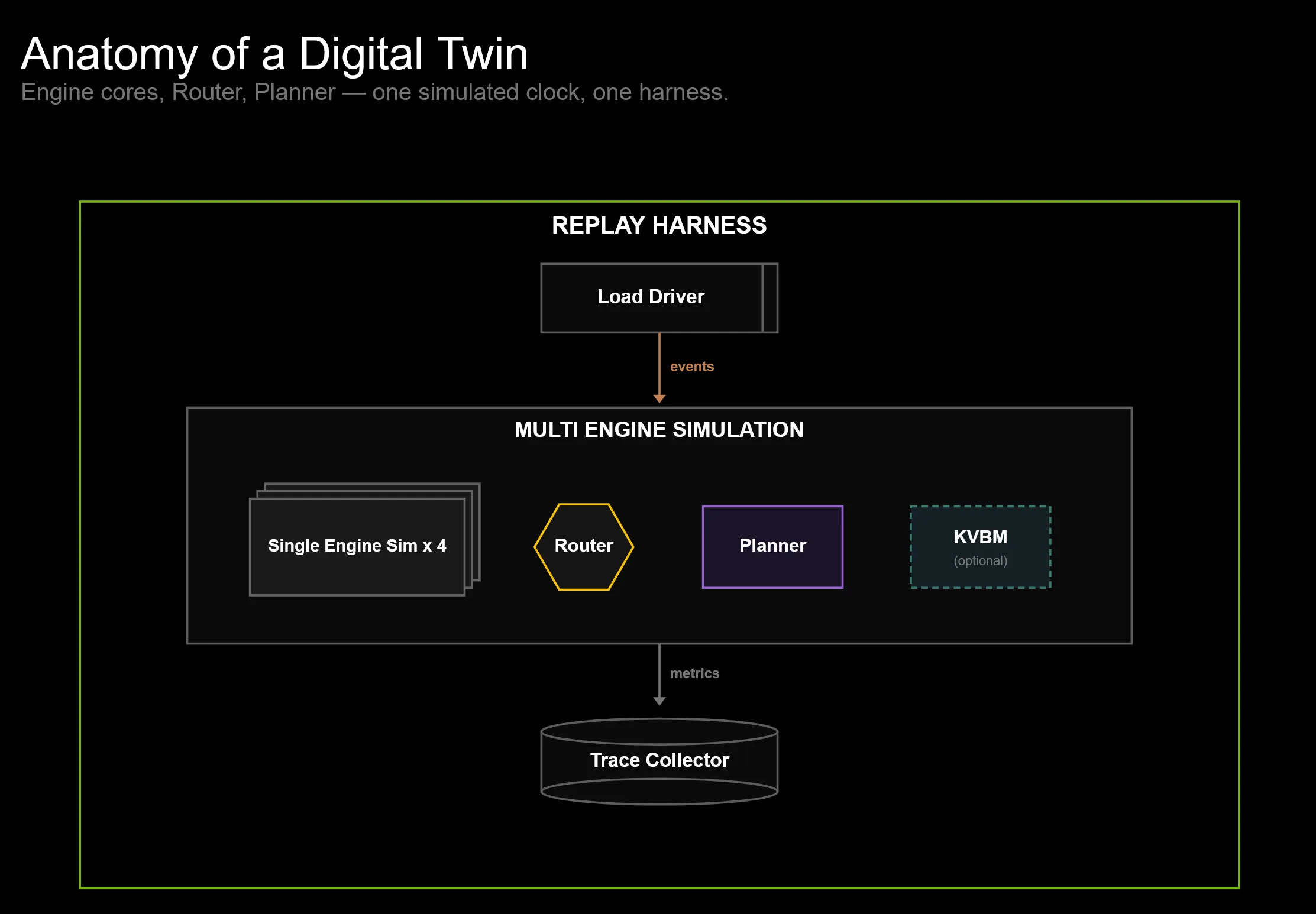
在虚拟时钟上回放
离散事件仿真,或 DES,为 DynoSim 提供了一个虚拟时钟和一个事件队列。组件不会在实时中等待。相反,它们会根据建模的持续时间安排未来事件:请求到达、调度器步骤、前向传递、KV 传输、工作器启动或 Planner 操作。运行时跳转到下一个时间戳,更新系统状态,并让受影响的组件安排更多工作。
一趟请求穿过双胞胎的旅程
- 负载生成器,例如 Dynamo AIPerf,会根据轨迹或合成工作负载发出请求。
- 路由器决定请求应该去哪里,或者是否应该等待。
- 所选引擎调度程序将请求批处理为预填充或解码过程。
- 硬件感知的计时,例如由 AI 配置器(AIC) 支持的计时,会估算该传递过程的持续时间。
- KV 交接、缓存或卸载相关事件可能会被安排在同一条虚拟时间线上。
- 解码会产生可见的输出标记。
- 追踪收集器记录请求级和系统级指标。
重点在于,每个组件决策都会改变未来事件。路由器的决策会影响工作线程的队列,Planner 的扩缩容决策会延迟容量,而 KV 迁移决策会改变解码开始的时间。
回放支架:驱动双体
回放框架将工作负载生成连接到模拟组件,然后再连接回指标。对于固定轨迹,到达可以直接根据轨迹进行调度。对于反馈驱动的工作负载,例如多轮或代理型流量,框架可以在发出后续请求之前等待完成。轨迹收集器会从模拟时间线中记录吞吐量、TTFT、TPOT、端到端延迟、前缀缓存复用以及其他请求级或系统级指标。
单引擎模拟:调度器保真度很重要
单个引擎并不只是每秒 token 数的估算。调度器决定哪些请求进入每一轮、prefill 和 decode 如何进行批处理,以及 KV 压力如何影响进度。DynoSim 将这一点保持为后端相关:vLLM 路径模拟带有共享 token 预算以及抢占/重计算的等待/运行调度器,而 SGLang 路径模拟感知 radix 缓存的准入、分块 prefill 预算以及保持前缀的 decode 回撤。
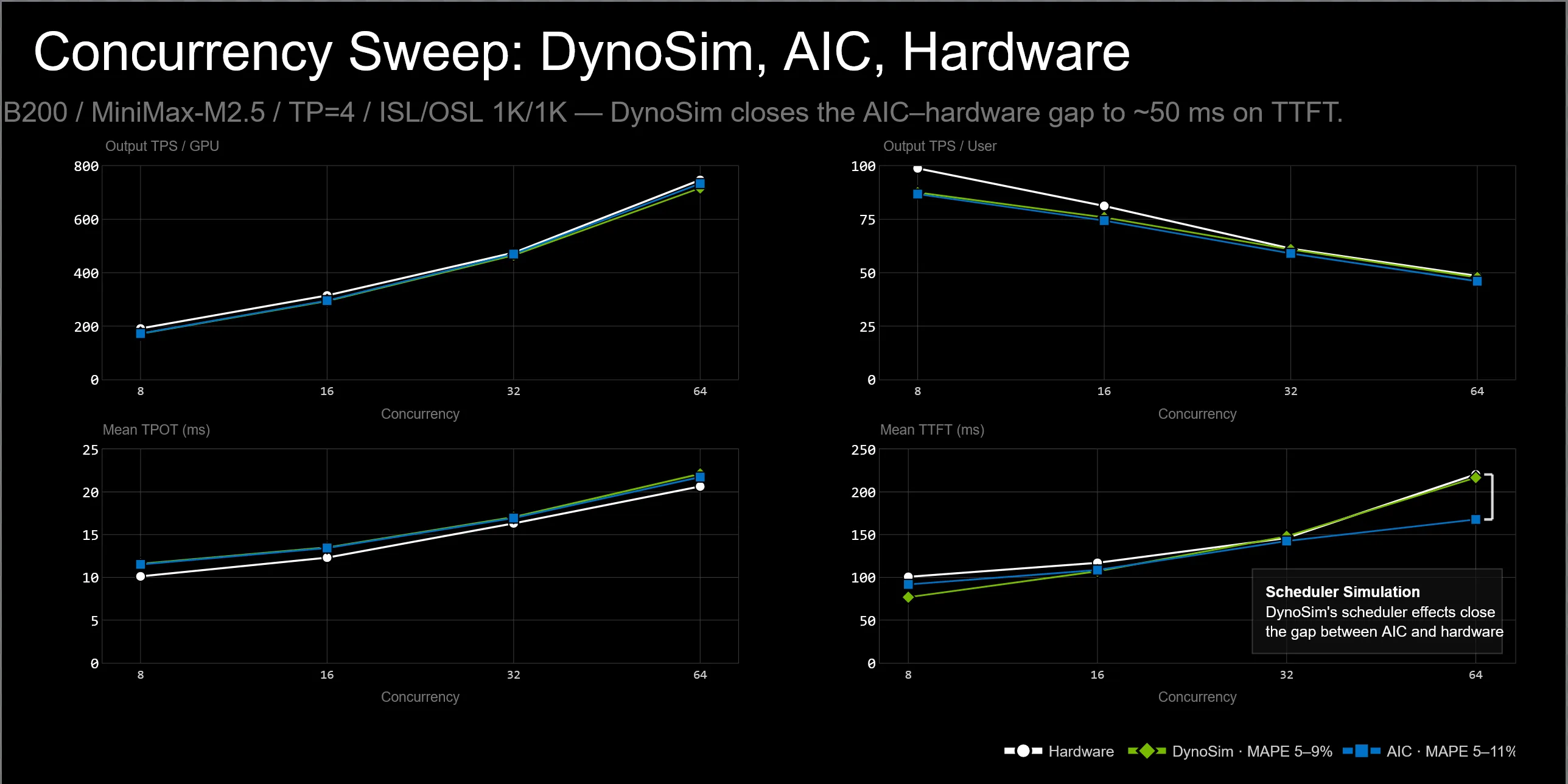
AIConfigurator (AIC) 在此场景中充当引擎端的计时器:在给定模型、后端、系统、张量并行形状和 pass 形状的情况下,估算 prefill 或 decode 任务的预期耗时。调度器的模拟过程决定每个 pass 包含哪些操作,AIC 则负责估算所选 pass 的执行时间。AIC 提供 pass 的运行速度信息,而 mocker/replay 调度器则用于建模 pass 周围的服务行为。
下图显示了为什么调度器层很重要。AIC 在引擎侧性能上对真实硅片具有很强的保真度,尤其是在吞吐量和 token 时间方面。但是在高并发下,TTFT 对请求如何等待、批处理、分块以及进入预填充阶段非常敏感。
多引擎模拟:从工作线程到系统
Dynamo 的能力来自那些利用系统主动反馈做出在线决策的组件。Router 需要当前的缓存状态和解码负载。Planner 需要流量、工作线程状态和 SLA 信号。KVBM 需要传输压力、分层容量和未来的缓存可用性。多引擎模拟用同一个按时间戳排序的事件队列来建模这些反馈回路。每个组件都会观察当前的模拟状态,并把未来的决策或完成事件重新安排回那个队列。
对于以下具体的 Router 和 KVBM 结果,除非另有说明,均采用相同的基线回放配置:完整的 23,608 条请求 Mooncake FAST25 toolagent 轨迹、NVIDIA HGX B200 上的 MiniMax-M2.5 FP8 模型、AIC 提供的 vLLM 0.14.0 时序、TP=4,以及离线回放。Router 实验包含 8 个聚合工作线程;KVBM 实验使用 1 个工作线程,并切换 G2 主机内存层。
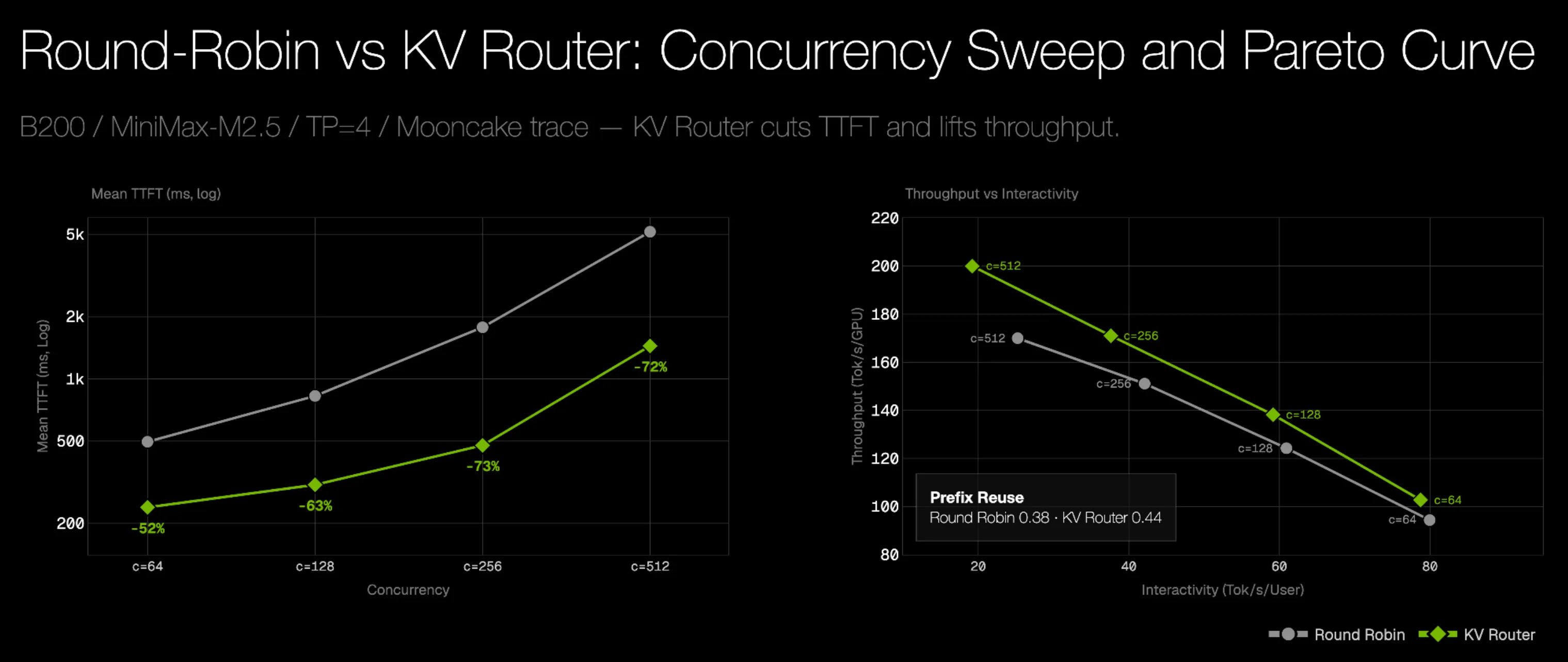
下图比较了轮询路由和 KV 路由器。已禁用 G2 卸载,因此差异来自路由和缓存放置:
KVBM 管理着服务内存层次结构中的 KV 块:本地 HBM、主机内存、SSD,以及分布式或远程缓存。本地较低层级缓存的行为通常可以建模为时序和资源压力:G1(GPU 内存)、G2(主机内存)、传输带宽、层级容量,以及最终的 G3(磁盘)。分布式缓存则让模拟变得更有趣。卸载、上载、远程读取和放置决策会影响路由、调度、排队以及未来的缓存状态,因此它们需要作为事件注册到与其余服务框架相同的时间线上。
下面的 KVBM 示例展示了当启用 G2 主机内存层并将其大小设为 32,768 个块时,模拟器预测的结果:
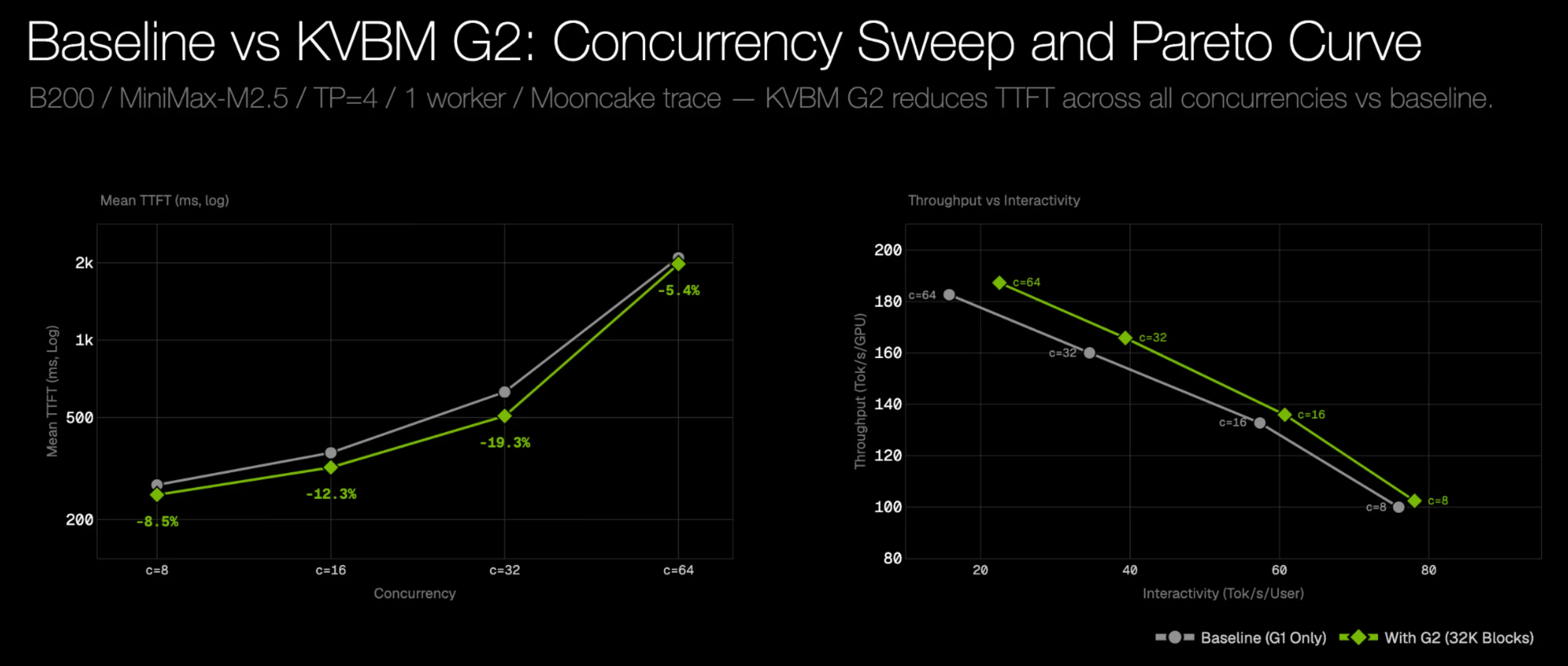
未来,Replay 还可根据真实的分布式缓存目标,驱动 NIXL(NVIDIA 推理传输库) 的读写操作。这些测量数据将用于校准传输成本、放置策略及竞争状况,并反馈至分布式缓存模型中。
DynoSim 的优化与发现
一旦 DynoSim 能通过组合组件运行工作负载,回放就会成为优化和发现的评分函数:提出一种布局或策略,运行工作负载,收集指标,并将结果与目标或假设进行比较。
通过回放进行系统性优化
优化器今天采用了一种粗糙但实用的块坐标下降方法,专门针对部署参数进行优化:首先选定一个 TP 形状,然后为该 TP 形状选择一种工作节点切分方式,最后确定路由器的配置。这种方法之所以有效,是因为当前的搜索空间仍然较小,且局部足够平滑,使得粗粒度的坐标搜索能够找到有价值的候选方案。随着搜索空间的扩大,相同的回放评分循环可以接入更强大的黑盒优化器,例如类似 Hyperopt 的贝叶斯优化、遗传算法或 Vizier。
更有意思的是,这种回放循环并不仅限于结构化参数。按照 Karpathy 的 autoresearch 风格,通过一个代理式框架,可以提出具有实质意义的代码修改,重建 Dynamo,重新运行同一条 trace,并仅保留那些能够优化目标的改动。这样一来,回放就演变为一个有边界的探索循环,可用于改进路由器的代价函数、Planner 的启发式方法以及缓存策略——这些内容往往难以通过简单的参数网格搜索来有效表达。
发现示例:超越当前优化器
同一个模拟循环不仅可以用于配置搜索,也可以用于研究。一些实验会调整暴露的参数,另一些则会改变算法本身。
这里我们将通过 Planner 的示例进行深入探讨。DynoSim 之所以适用于自动扩缩容,主要有两个原因。首先,有趣的行为体现在宏观层面:它源于持续数分钟的流量变化、worker 启动延迟、容量波动,以及扩缩决策、队列和路由之间的反馈循环——这些复杂交互无法通过简单的单元测试充分验证。其次,另一种评估方式——在完整的 Kubernetes 环境中进行测试——每次策略调整都会带来高昂成本,无论是消耗的 GPU 资源还是工程师的时间。DynoSim 使我们能够在构建完整环境之前,全面探索这些因素的影响:比较静态与动态配置、调整 Planner 参数,并在决定是否投入工程资源以实现更快启动、预测性扩缩容或预热容量之前,量化 worker 启动时间的实际重要性。
以下三个实验复用了前文介绍的 Mooncake FAST25 toolagent 轨迹,但将模拟的引擎配置改为在 H200-SXM 上、TP=2 的 Qwen3-32B。
实验1 设置权衡:我们比较了使用聚合引擎的静态部署与配备规划器的动态部署。通过扫描不同数量的静态副本(无规划器;固定部署下引擎副本数量不同),并叠加一次规划器运行,将 SLA 设定为 TTFT=1500 毫秒和 ITL=50 毫秒。
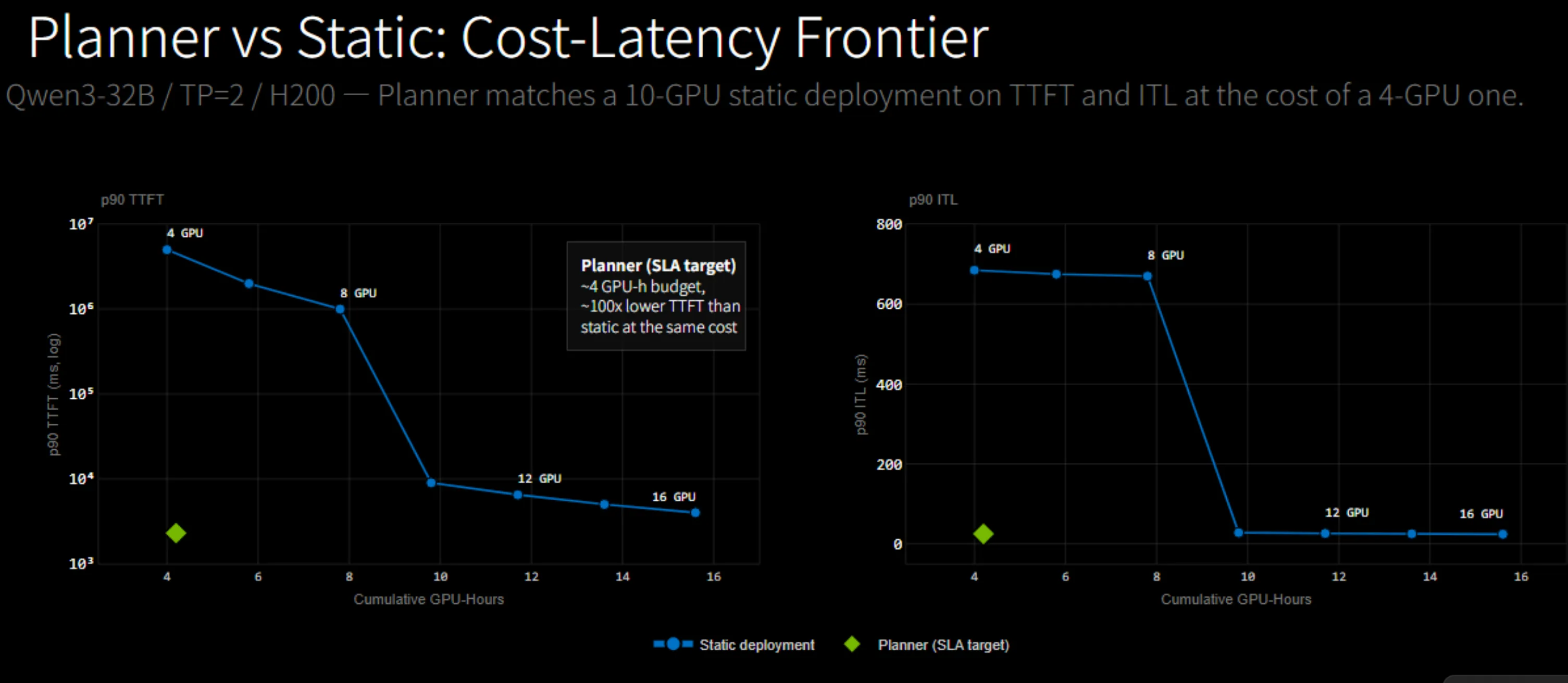
带有规划器的动态部署达到了更好的成本-延迟平衡:在使用更少 GPU 小时的同时,它的 p90 TTFT 和 ITL 都远低于任何静态部署。
实验2 扩缩容间隔:我们将扩缩容间隔从1秒调整至300秒,并将引擎启动设为即时,以观察快速响应流量变化与扩缩容过于频繁之间的权衡。
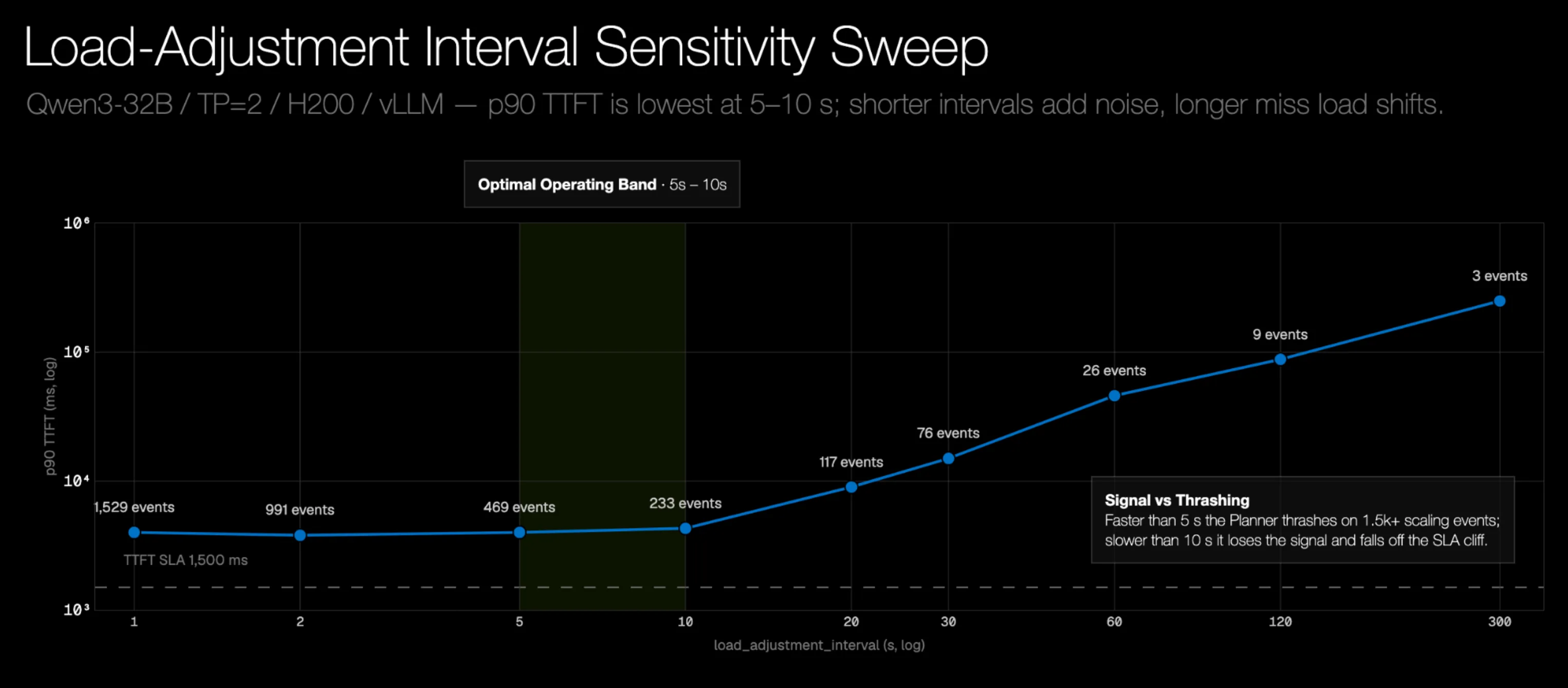
P90 TTFT 在 1 到 10 秒的间隔内大致保持不变,但扩缩容事件从 1,529 次骤降到 233 次。大约 30 秒后,Planner 对突发流量的反应太慢。GPU 小时数在整个扫描范围内大致保持稳定,所以极短的间隔不会显著增加 GPU 时间,但会造成不必要的扩缩容抖动。最佳范围大约是 5 到 10 秒。
实验3 冷启动时间:在真实集群中,扩容需要一定时间,因为新的引擎Pod在能够处理流量前,通常需要几秒到几分钟才能就绪。在模拟中,我们对这一延迟进行了建模,并评估了Planner对其的应对效果。
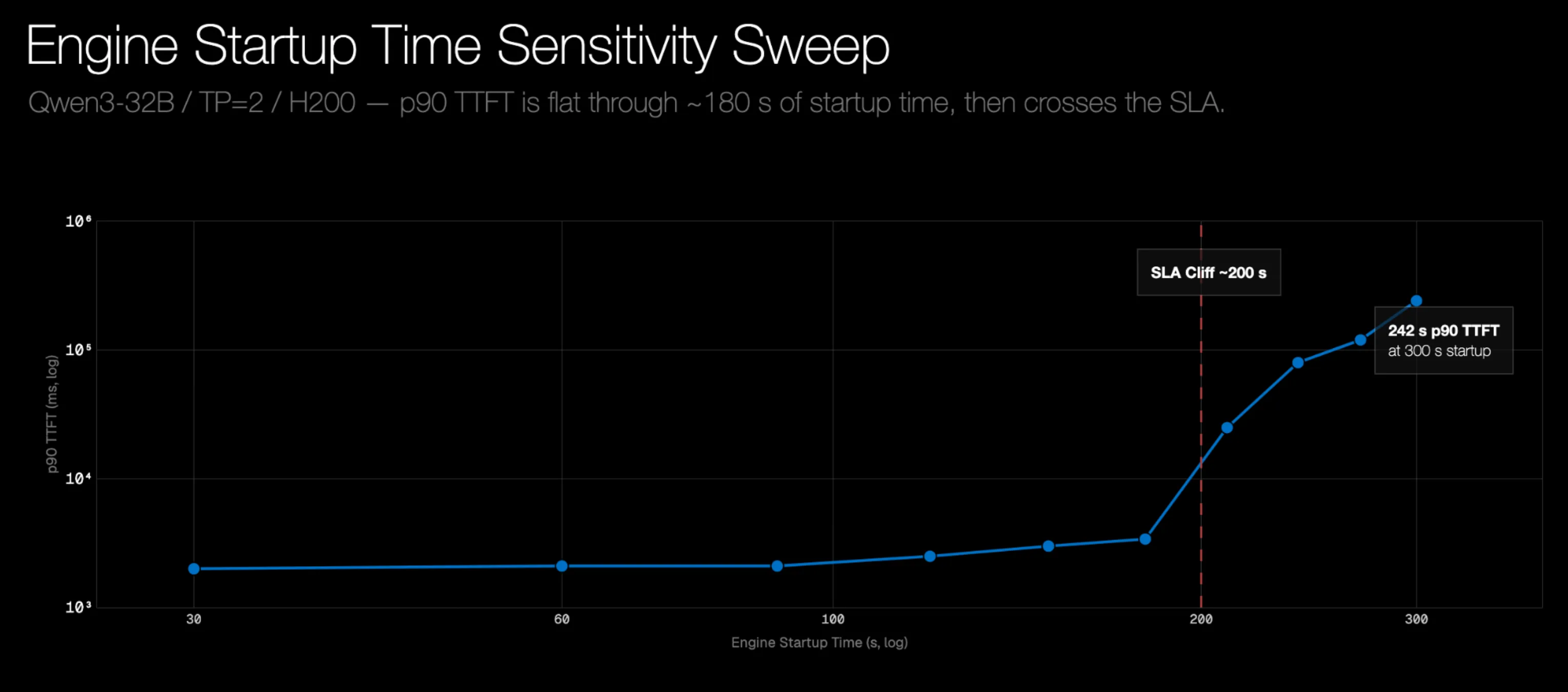
对于 Qwen3-32B 在 TP=2 的情况下,Planner 会一直满足 SLA,直到启动延迟达到约 180 秒。大约在 200 秒时,性能会急剧下降,而到 300 秒时,系统会被流量突发卡住,p90 TTFT 达到 242 秒。这表明用户应将冷启动时间优化到低于 200 秒,以获得最佳性能。
这三个实验说明了如何以低成本探索设计空间。
模拟作为内循环
目标不是取代真实集群验证。目标是让那种验证更有针对性。
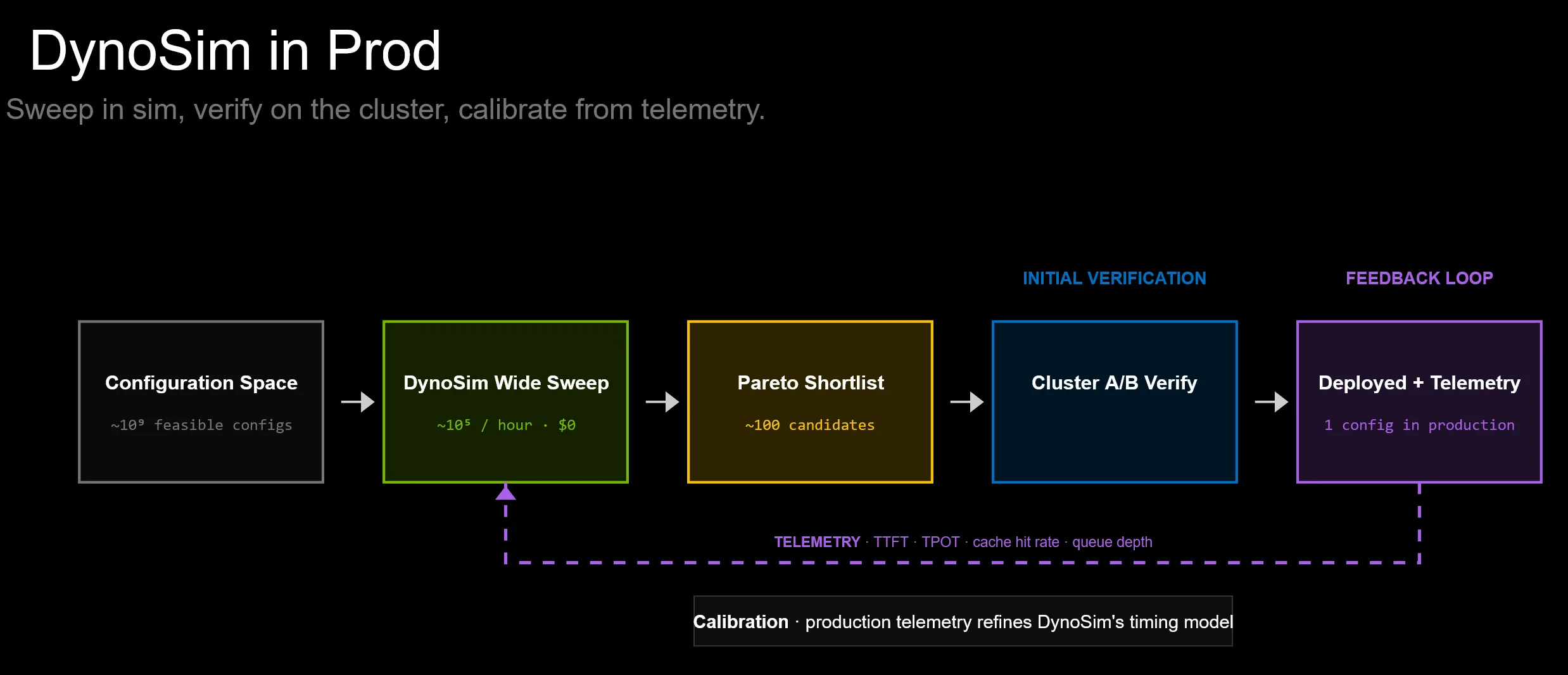
模拟成为设计探索的内循环。真实集群仍然是验证的外循环。在这两个循环之间,Dynamo 可以将服务算法作为一个系统进行测试:调度器行为、路由策略、Planner 控制、KV/缓存迁移、工作负载形态,以及测得的引擎时序。
展望未来,我们也计划在生产环境中完成这一闭环。基于 DynoSim 构建的智能扫参算法将定期针对最近记录的生产流量运行,在当前工作负载分布下搜索配置空间,并在发现明显更优的部署时建议(或直接应用)重新配置。由于流量形态会在数小时和数天内发生漂移——例如不同的提示词混合、ISL/OSL 分布或突发模式——上周正确的 TP 形态、prefill/decode 切分、路由策略和 Planner 设置,今天可能已经不再是最优。由 DynoSim 驱动的持续扫参可以让线上部署跟踪当前最优解,而不是依赖一次性的上线决策。