
使用 NVIDIA 集合通信库 (NCCL) 运行包含集合运算(例如 AllReduce、AllGather 和 ReduceScatter)的深度学习训练或推理工作负载时,评估 NCCL 在实际运行过程中的表现可能具有挑战性。
本文将介绍用于解决此问题的 NCCL Inspector Profiler 插件,该插件为分布式深度学习的训练与推理工作负载提供了一种全面、低开销、可持续运行的性能可观测性方案。
什么是 NCCL Inspector?
NCCL Inspector 是一款用于分析和评估的工具,可针对每个通信器提供详细的集合操作性能及元数据日志记录。该工具包含两个主要步骤:数据收集与数据分析。
NCCL Inspector 可以帮助解答有关各类主题的问题,包括:
- 作业内集合性能比较:与 Tensor Parallel 域相比,AllReduce、AllGather、ReduceScatter 及其他集合操作在数据并行域中的性能表现如何?
- 作业间集合性能比较:昨日网络拥塞是否导致集合操作性能下降?这是否是计算性能降低的原因?
- 计算与网络性能相关性:若整体计算性能(TFLOPS)下降,是否由网络性能下降所引起?
NCCL Inspector 会定期记录通信器中每个 rank 的集合带宽和持续时间。作业结束后,系统将分析这些性能数据,并将其与整个作业生命周期相关联,进而对多 GPU 作业生命周期内的 NCCL 群集性能进行特征分析。
作为多 GPU 和多节点通信的关键组件,每个采用 NCCL 的框架都能从 NCCL Inspector 提供的详尽可观察性中获益。
NCCL Inspector 利用 NCCL 2.23 中引入的插件接口,为生产工作负载实现始终开启的可观察性,同时尽量减少性能开销。
在数据收集阶段,NCCL Inspector 库会指示 NCCL 应触发的特定集合事件。用户可通过 NCCL_PROFILER_PLUGIN 环境变量加载该库(例如在深度学习框架中)。随后,NCCL Inspector 会监听 NCCL 发出的订阅事件,并为每个事件生成结构化的 JSON 输出,从而深入揭示 NCCL 群集的性能特征。
作业完成后,通过 NCCL 库提供的示例 Python 脚本生成并执行分析和可视化。随后,该 JSON 输出将被输入至分析脚本及各类可观察性平台,以在生产工作负载运行期间深入洞察 NCCL 的性能表现。
NCCL Inspector 的主要特性
NCCL Inspector 的若干关键突出功能使其发挥作用,包括:
- 每通信者追踪: NCCL Inspector 为每个 NCCL 通信者维护独立的追踪记录。这在复杂的分布式应用(如 AI 工作负载)中尤为重要,因为多个通信者可能被用于并行域等不同场景。
- 始终开启的低开销: NCCL Inspector 具备低开销的性能追踪能力,可在生产环境中持续启用,提供对 NCCL 性能的不间断可观测性,同时不会对系统性能造成明显影响。
- 性能指标: NCCL Inspector 计算并报告多项关键性能指标,包括:
- 算法带宽
- 总线带宽
- 执行时间(微秒)
- 消息大小和集合类型
- 与网络技术无关: NCCL Inspector 通过插件接口与 NCCL 集成,兼容 NCCL 所支持的多种网络技术(如 RoCE、IB、EFA 等),不受具体网络类型限制。
数据采集阶段
在数据采集阶段,NCCL Inspector 会通过设置多个环境变量来完成初始化。
必需变量:
NCCL_PROFILER_PLUGIN: Path to the plugin library binary.NCCL_INSPECTOR_ENABLE=1NCCL_INSPECTOR_DUMP_THREAD_INTERVAL_MICROSECONDS: Sets the interval for output writing
可选变量:
NCCL_INSPECTOR_DUMP_DIR: Output directory for logsNCCL_INSPECTOR_DUMP_VERBOSE(Optional): Enables verbose output with event trace information
示例使用 (SLURM)
要启用 NCCL Inspector 并进入数据收集阶段,请在 SLURM 的 SBATCH 脚本中添加以下环境变量设置:
export NCCL_PROFILER_PLUGIN=/path/to/nccl/ext-profiler/inspector/libnccl-profiler-inspector.so
export NCCL_INSPECTOR_ENABLE=1
export NCCL_INSPECTOR_DUMP_THREAD_INTERVAL_MICROSECONDS=500
export NCCL_INSPECTOR_DUMP_DIR=/path/to/logs/${SLURM_JOB_ID}/
srun your_nccl_application
输出格式示例
{
"header": {
"id": "0x7f8c496ae9f661", // communicator id
"rank": 2,
"n_ranks": 8,
"nnodes": 1
},
"metadata": {
"inspector_output_format_version": "v4.0",
"git_rev": "",
"rec_mechanism": "profiler_plugin",
"dump_timestamp_us": 1748030377748202,
"hostname": "hostname",
"pid": 1639453
},
"coll_perf": {
"coll": "AllReduce",
"coll_sn": 1407,
"coll_msg_size_bytes": 17179869184,
"coll_exec_time_us": 61974,
"coll_algobw_gbs": 277.210914,
"coll_busbw_gbs": 485.119099
}
}
详细输出
当启用 NCCL_INSPECTOR_DUMP_VERBOSE=1 的 verbose 模式时,每个内核的输出(SM)性能如下所示:
{
"header": {
"id": "0xe62dedaa97644a", //communicator info
"rank": 4, // communicator id
"n_ranks": 8,
"nnodes": 1
},
"metadata": {
"inspector_output_format_version": "v4.0",
"git_rev": "9019a1912-dirty",
"rec_mechanism": "nccl_profiler_interface",
"dump_timestamp_us": 1752867229276385,
"hostname": "hostname",
"pid": 438776
},
"coll_perf": {
"coll": "ReduceScatter",
"coll_sn": 1231,
"coll_msg_size_bytes": 2147483648,
"coll_exec_time_us": 41057,
"coll_timing_source": "kernel_gpu",
"coll_algobw_gbs": 418.439467,
"coll_busbw_gbs": 366.134533,
"event_trace_sn": {
"coll_start_sn": 1,
"coll_stop_sn": 2,
"kernel_events": [
{
"channel_id": 0,
"kernel_start_sn": 3,
"kernel_stop_sn": 48,
"kernel_record_sn": 47
}
]
},
"event_trace_ts": {
"coll_start_ts": 1752867229235059,
"coll_stop_ts": 1752867229235064,
"kernel_events": [
{
"channel_id": 0,
"kernel_start_ts": 1752867229235181,
"kernel_stop_ts": 1752867229275811,
"kernel_record_ts": 1752867229275811
}
]
}
}
}
数据分析阶段
NCCL Inspector 包含一个示例性的综合性能分析与可视化工具,能够处理日志文件并生成详细的性能报告。“Performance Summary Exporter”(性能摘要导出器)工具提供丰富的可视化功能,并对集合通信性能进行统计分析。
性能摘要导出工具
这个独立的性能摘要导出工具是一个基于 Python 的分析工具,位于 ext-profiler/inspector/exporter/example/ 中,主要用于执行以下任务:
- 以多种格式(
.log、.log.gz、.jsonl、.jsonl.gz)处理 NCCL Inspector 日志 - 将数据导出为 Parquet 格式,以提升处理效率
- 生成集合运算的统计摘要
- 创建可视化图表,包括散点图、直方图和箱线图
- 对通信模式进行分类
- 单秩
- 仅限 NVLink
- 仅适用于 HCA
- 混合
控制面板集成
NVIDIA 团队已将来自 NCCL Inspector 的数据集成到控制面板中,该控制面板能够根据 SLURM 作业概览 NCCL 性能。

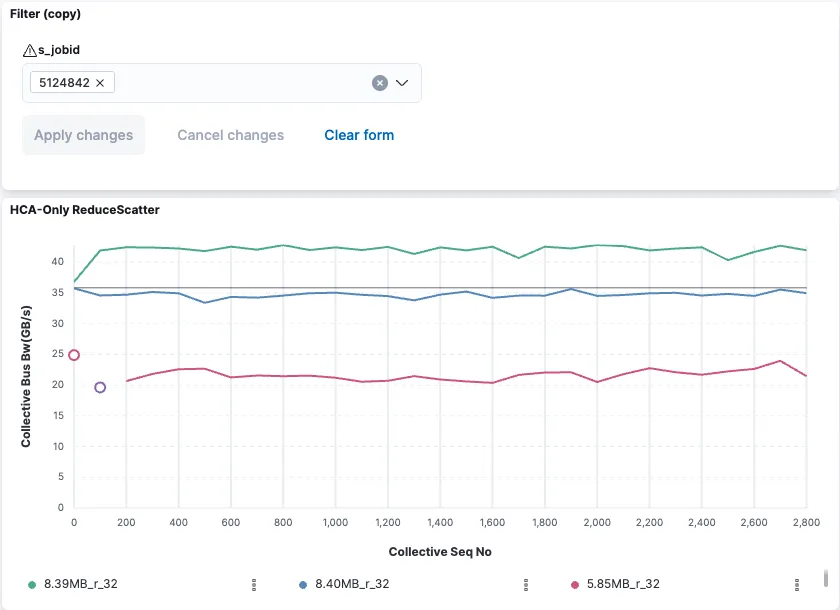

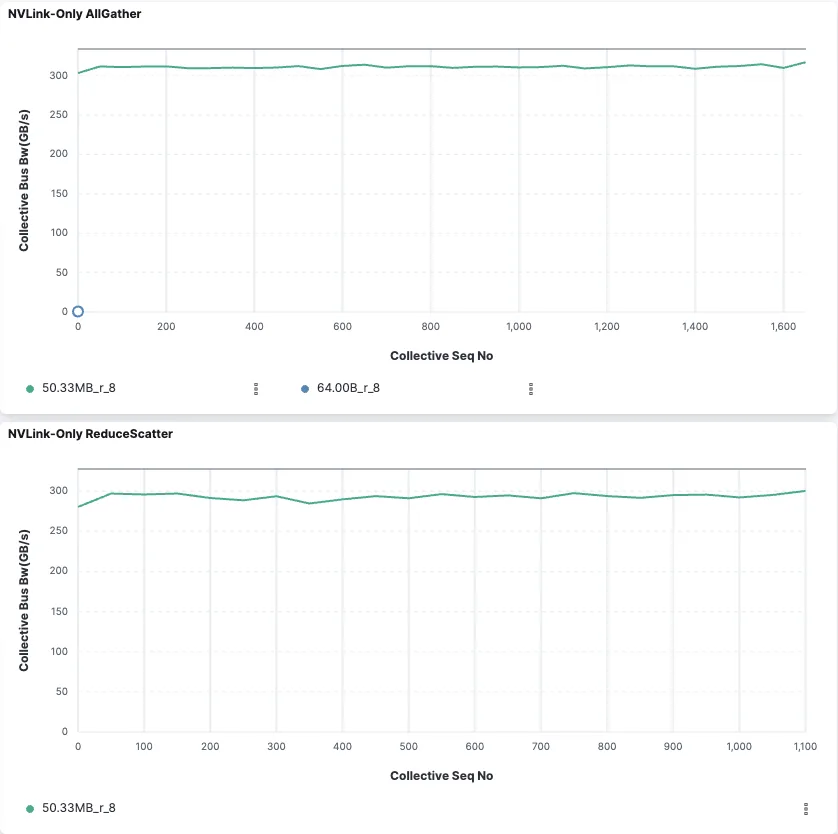
用例和应用
您可以将 NCCL Inspector 应用于多种场景,包括性能分析、研发调试以及生产环境监控。
性能分析
Inspector 可对集合通信性能进行深入分析,有助于识别分布式训练工作负载中的瓶颈并发现优化机会。
研究和开发
研究人员可利用详细的事件追踪与性能指标,开发新型的通信模式与算法。
生产监控
Inspector 具有随时在线的特性,因此适用于持续监控生产工作负载,深入掌握通信性能随时间的变化情况。
开始使用 NCCL Inspector
NCCL Inspector 提供了一个功能强大的工具,可用于深入了解并优化分布式训练工作负载中的集合通信性能。其低开销设计使其适用于生产环境,而详细的事件追踪与性能指标则有助于对通信模式进行深入分析。
要开始使用并深入了解 NCCL 及相关工具,请访问 NVIDIA/nccl NCCL GitHub 资源库,并查阅 NVIDIA Magnum IO 文档。




