
随着 AI 模型日益复杂,并且在包括加州 AB-2013 和欧盟《人工智能法案》在内的框架下监管审查不断加强,软件团队面临的挑战已不仅仅是交付优秀代码:他们还需要在模型发布前生成全面、可审计的模型文档。
模型卡用于说明模型的工作原理、预期用途与许可、训练数据、性能表现及局限性。它们有助于提升透明度和问责性,使下游用户——包括客户、监管机构以及受影响的社区——在选择和部署人工智能时能够做出更明智的决策。其受众不仅限于开发者,还包括政策制定者、采购团队和风险评估人员,这些人员依靠模型卡来评估模型的适用性,并在不同供应商之间进行比较。他们通过提升透明度和问责性,使得下游用户能够做出明智的决策。
实际上,手动创建模型卡既繁琐又缓慢。文档更新滞后于开发,而元数据在发布时往往已经过时。随着模型变得越来越复杂,不一致的格式和缺失的必填字段会带来不必要的审计风险,并减缓采用速度。NVIDIA 模型卡生成器(MCG)工具包通过直接读取源数据,在不到一分钟内自动化并标准化 Model Card++ 格式的模型文档。
介绍 NVIDIA MCG 工具包
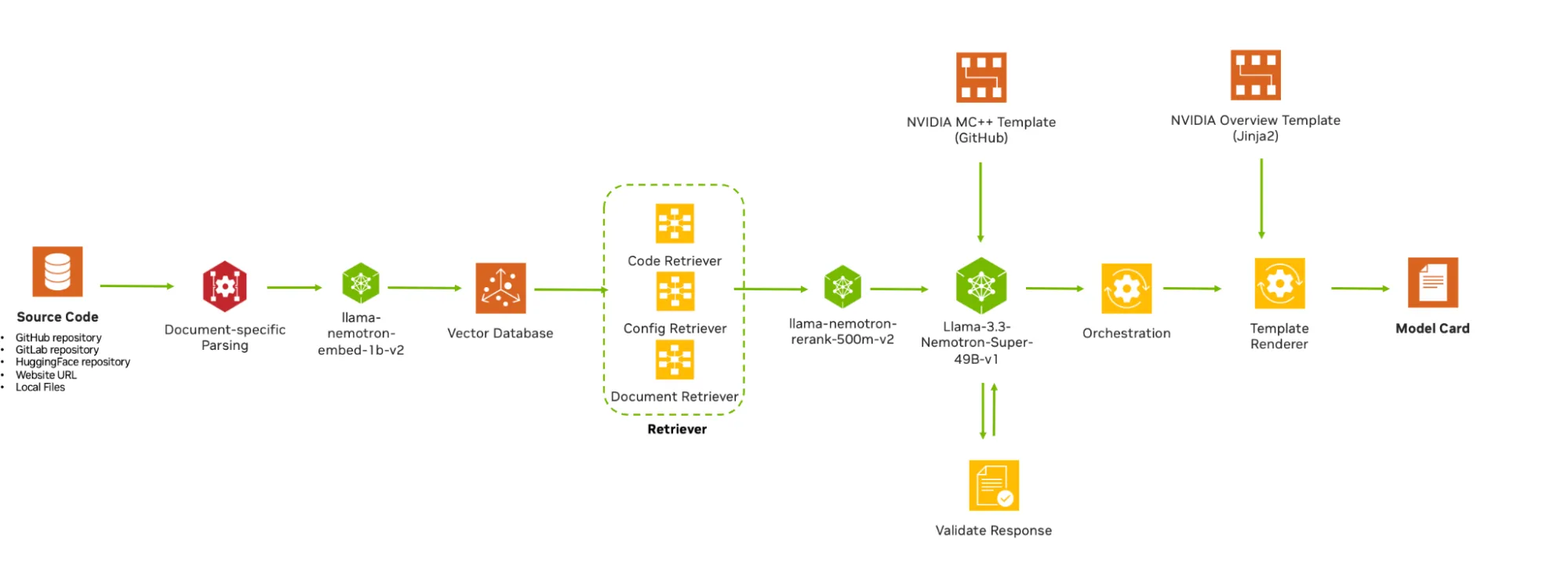
MCG 工具包是一个容器化流水线,它通过读取模型源代码来自动生成模型卡。它遵循模块化的“摄取 → 提取 → 渲染”流水线。一个中央协调器接收你的请求——无论是 URL 还是上传的文件——协调工作流程,并返回完整的模型卡。每个阶段都作为独立服务运行,因此你可以更新或替换单个组件,而不会影响流水线的其余部分。
MCG 工具包的工作原理
工具包提供一个可交互的用户界面,支持输入 URL(GitHub、GitLab、HuggingFace 或任何公开网页)或上传文件(ZIP、PDF、DOCX 或 Markdown)。此外,还提供 REST API 以便进行程序化集成。
从那里,数据流经三个阶段:
- 输入 → 摄取。 系统抓取内容,并将其处理为文档块,按类型分类:文档、配置文件和代码。
- 文档 → 提取。 在提取阶段,已摄取的文档将通过由 NVIDIA 推理微服务(NIM)支持的检索增强生成(RAG)流程进行处理。NVIDIA Nemotron RAG 负责高精度的嵌入(llama-nemotron-embed-1b-v2)和重排序(llama-nemotron-rerank-500m-v2),并为代码、配置文件和文档分别配置独立的检索器,以优先处理信号更强的信息来源。核心提取由 GPT-OSS-120B 执行,该模型读取检索到的段落,并依据专家制定的格式与内容规范——NVIDIA MC++ 模板及字段级风格指南——生成符合要求的结构化合规信息。生成结果需经过验证步骤,在确认无误后方可通过。最终输出为结构化 JSON。概述完成后,相同内容将进入子卡片阶段,生成四张 Model Card++ 子卡片:偏见、可解释性、隐私,以及安全与安全性。 NVIDIA Nemotron RAG
- JSON → 渲染。 通过可配置的模板,将结构化的 JSON 渲染为易于阅读的 Markdown。你可以在界面中编辑内容,并在下载或集成到其他系统前重新渲染。最终生成一份完整的模型卡——包括总览和四个子卡——可直接用于审阅或发布。
灵活设计
你没有被限制在某一种模型、模板或标准上。这个工具包在三个维度上都是可定制的:
1) 模型: 该系统支持为语言模型、嵌入和重排序配置不同的端点。无论是在较小模型上进行原型开发,还是扩展至生产环境,均可灵活指向不同的 NIM 或兼容 API,以满足性能、成本或数据驻留需求。
2)模板:输出格式由 Markdown 模板驱动,组织可基于同一提取逻辑,灵活自定义为 Model Card++、内部标准或新兴监管格式。输出同时符合 CycloneDX 标准。当出现新的披露要求时,只需更新模板,无需修改整个流水线。
3)指南:字段级指导——明确应采集的内容及表述方式,源自可配置的知识库。当法规或行业要求发生变化时,无需修改核心代码即可更新指南。同一流程可适用于不同行业和合规体系。
在你需要的地方运行它
工具包以容器化服务形式发布,支持一条命令完成设置。协调器、摄取、提取和子卡片各阶段都作为独立容器运行,并包含基础设施(数据库和任务队列)。没有专有云锁定:MCG 可在本地部署或运行于您自己的云中,并支持 Kubernetes,帮助您在自己的基础设施上快速启动。
性能结果
我们对公共模型仓库中的工具包进行了标准化测试,以衡量完成率、生成时间和准确率。每个字段都根据源文档进行了评分。准确率的计算方式是:正确字段数除以非占位符字段数。下表 1 显示了结果。
| 模型 | 生成时间 | 完成率 | 准确性 |
|---|---|---|---|
| NVIDIA Nemotron Nano 8B | 56s | 97% | 92% |
| NVIDIA Cosmos Reason 2 | 86s | 94% | 82% |
| NVIDIA 松鸦鸭 | 65 秒 | 92% | 87% |
| NVIDIA Proteina | 52 秒 | 94% | 82% |
| 第三方模型(DeepSeek-V3、Evo2、Gemma、Llama) | 约 80 秒平均 | ~89% | ~80% |
该工具包可在一分钟内为大多数代码库生成完整的模型卡(概述加上四个子卡)。总体完成率达到 91%(第三方基线),在标准化测试集上的准确率为 76%。完成率和准确率因模型和代码库而异;README 和配置文件更丰富的代码库会取得更高的结果。
该工具包在有支持性文档且代码库结构良好的情况下表现最佳,并尽可能使用代码分析进行补充。当文档稀少或缺失时,填充的字段会更少;系统不会猜测,而是显示“未找到”或“无可用信息”,以标记出需要人工审查的缺口。
我们还测试了在完全移除文档时会发生什么。我们使用与标准测试集相同的代码库,删除了所有 .pdf、.md 和 .txt 文件,然后仅针对代码重新运行了该工具包。在五个模型中,平均完成率从 91% 降至 61%,而严格准确率(仅针对可验证字段衡量)降至 28%,相比之下,在标准测试中,仅对已完成字段评分的准确率为 76%。
61% 的完成率表明,该工具包仍然仅凭代码、配置文件和仓库结构就能提取出有意义的信号;准确率下降反映了文档在帮助这些字段填写正确方面贡献有多大。
关键的是,这个工具不会靠猜测来弥补。如果它无法有把握地填充字段,这些字段就会显示为“未找到”或“信息不可用”,这使它既适合作为文档仍在编写中的团队的缺口发现工具,也适合作为文档已完善的团队的生成工具。
早期采用者和行业合作伙伴
Oracle 是最早将 MCG 工具包集成到生产基础设施中的合作伙伴之一。作为其 OCI AI 服务的一部分,Oracle 提供了从 A10 到 GB200 NVL72 的多种 GPU 配置,部署了 OCI 容器引擎与 AI 服务工具包 的组合方案。该方案在标准 VCN 架构内运行 MCG Pod 和 NIM Pod,并为 NIM 模型提供由对象存储支持的后端服务。
在实际部署中,系统采用 Llama-3.3-Nemotron-Super-49B-v1 作为核心抽取模型,由 Nemotron RAG 负责嵌入和重排序任务。GPT-OSS-120B 模型既在配备两张 H100 显卡的专用 AI 集群上完成托管与测试,也通过按需服务模式进行了验证。
随着 OCI 不断增强 GPU 基础设施以支持大规模 AI 训练与推理,对一致且可审计的模型文档的需求也在持续上升。OCI 专用 AI 集群(DAC)是 OCI 内部一个私有、全托管的生成式 AI 环境,具备独立的 GPU 资源、端点和服务安全边界。MCG 工具包不仅将 AI 透明性能力直接集成到这一工作流中,免去客户自行构建的负担,还能帮助客户识别在 OCI 专用 AI 集群及裸金属 GPU 基础设施上运行模型时的最佳 GPU 配置。
入门
如果您想成为早期采用者,请联系 Trustworthy AI 团队。我们很乐意讨论合作。
还没有准备好使用完全自动化工具包吗?Trustworthy AI GitHub 库提供开源的 Model Card++ 模板,以及用于蓝图、数据集、容器和系统的 AI 透明度卡,你现在就可以使用。
文档应与您发布的模型保持同步。无论您使用 MCG 工具包,还是基于我们的开源模板开始,NVIDIA 的可信 AI 计划都致力于让这一过程更加简便。