
构建智能体不仅仅是“调用 API”,而是需要将检索、语音、安全和推理组件整合在一起,使其像一个统一并互相协同的系统一样运行。每一层都有自己的接口、延迟限制和集成挑战,一旦跨过简单的原型就会开始感受到这些挑战。
在本教程中,您将学习如何使用 2026 年 CES 发布的最新 NVIDIA Nemotron 语音、RAG、安全和推理模型,去构建一个带有护栏的语音驱动 RAG 智能体。最终您将拥有具备如下功能的一个智能体:
- 听取语音输入
- 使用多模态 RAG 将智能体锚定在您的数据之上
- 长上下文推理
- 在响应之前应用护栏规则
- 以音频的形式返回安全答案
您可以在本地 GPU 上进行开发,然后将相同的代码部署到可扩展的 NVIDIA 环境中,无论是托管的 GPU 服务、按需云工作区,还是生产就绪的 API 运行时,都无需更改工作流。
视频 1. 完整的端到端演示,从实时语音输入到真实的并经过安全检查的响应,以及如何在单个工作流中部署智能体。
先决条件
在开始这次教程之前,您需要:
- 用于云托管推理模型的 NVIDIA API 密钥(免费获取)
- 本地部署需要:
- 约 20GB 的磁盘空间
- 至少 24GB 显存的 NVIDIA GPU
- 支持 Bash 的操作系统 (Ubuntu、macOS 或 Windows Subsystem for Linux)
- Python 3.10+ 环境
- 一小时的空闲时间
您将构建的内容
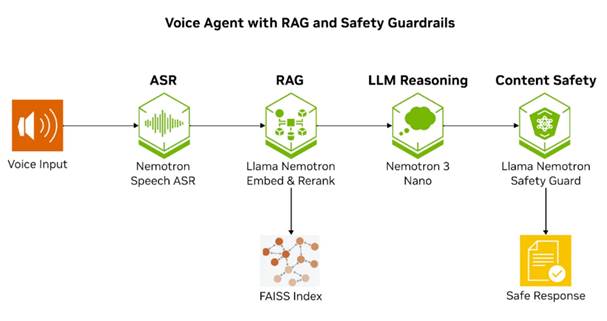
图 1. 带有 RAG 和安全护栏的语音智能体的端到端工作流。
| 组件 | 模型 | 目的 |
| ASR | nemotron-speech-streaming-en-0.6b | 超低延迟语音输入 |
| 嵌入 | llama-nemotron-embed-vl-1b-v2 | 文本和图像的语义搜索 |
| 重排序 | llama-nemotron-rerank-vl-1b-v2 | 将检索准确率提高 6-7% |
| 安全 | llama-3.1-nemotron-safety-guard-8b-v3 | 多语言内容审核 |
| 视觉语言 | nemotron-nano-12b-v2-vl | 根据上下文描述图像 |
| 推理 | nemotron-3-nano-30b-a3b | 1M token 高效推理 |
表 1. 本教程中用于构建语音智能体的 Nemotron 模型概览,包括用于 ASR、嵌入、重排序、视觉语言、长上下文推理和内容安全的模型。
步骤 1:设置环境
要构建语音智能体,您需要同时运行多个 NVIDIA Nemotron 模型(如上所示)。语音、嵌入、重排序和安全模型通过 Transformer 和 NVIDIA NeMo 在本地运行,推理模型则使用 NVIDIA API。
uv sync --all-extras配套的 Notebook 会处理所有的环境配置。设置用于云托管推理模型的 NVIDIA API 密钥,即可开始使用。
步骤 2:使用多模态 RAG 构建智能体基座
检索是可靠智能体的支柱。借助全新的 Llama Nemotron 多模态嵌入和重排序模型,您可以嵌入文本、图像(包括扫描文档),并直接将其存储在向量索引中,无需额外的预处理。这可以检索推理模型所依赖的真实上下文,确保智能体参考的是真实企业数据而非产生幻觉。

图 2. 具有离线索引和在线检索的多模态 RAG 管道。
llama-nemotron-embed-vl-1b-v2 模型支持三种输入模式——纯文本、纯图像和图像与文本的组合,让您能够对从纯文本文档到幻灯片和技术图表的各种内容进行索引。在本教程中,我们将嵌入一个同时包含图像和文本的示例。该嵌入模型通过 Transformers 加载,并启用 flash attention:
from transformers import AutoModel
model = AutoModel.from_pretrained(
"nvidia/llama-nemotron-embed-vl-1b-v2",
trust_remote_code=True,
device_map="auto"
).eval()
# Embed queries and documents
query_embedding = model.encode_queries(["How does AI improve robotics?"])
doc_embeddings = model.encode_documents(texts=documents)在初始检索后,llama-nemotron-rerank-vl-1b-v2 模型会结合文本和图像对结果进行重新排序,以确保检索后的准确性更高。在基准测试中,添加重排序可将准确率提高约 6-7%,这在精度要求较高的场景中是一项显著的提升。
步骤 3:使用 Nemotron Speech ASR 添加实时语音功能
锚定完成后,下一步是通过语音实现自然交互。

图 3. 基于 NVIDIA Nemotron Speech ASR 的 ASR 管道
Nemotron Speech ASR 是一个流式模型,基于 Granary 数据集中数万小时的英语音频及多种公开语音语料库进行训练,同时经过优化实现超低延迟的实时解码。开发者将音频流式传输到 ASR 服务,在收到文本结果后,将输出直接输入到 RAG 管道中。
import nemo.collections.asr as nemo_asr
model = nemo_asr.models.ASRModel.from_pretrained(
"nvidia/nemotron-speech-streaming-en-0.6b"
)
transcription = model.transcribe(["audio.wav"])[0]该模型具备可配置的延迟设置,在 80 毫秒的最低延迟设置下,平均字词错误率 (Word Error Rate, WER) 为 8.53%,延迟为 1.1 秒时,WER 进一步降低至 7.16%,这一表现显著低于语音助手、现场工具和免提工作流所要求的一秒关键阈值。
步骤 4:使用 Nemotron 内容安全和 PII 模型强制执行安全措施
跨地区和跨语言运行的 AI 智能体不仅必须理解有害内容,还必须理解文化细微差别和上下文相关的含义。
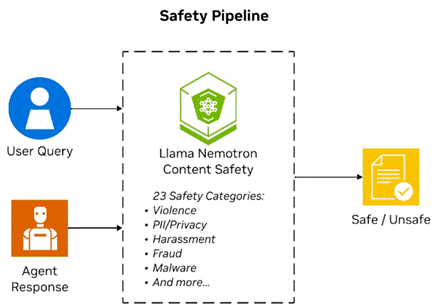
图 4. 使用 NVIDIA Llama Nemotron Safety Guard模型的安全管道,检测安全或不安全内容。
llama-3.1-nemotron-safety-guard-8b-v3 模型可提供 20 多种语言的多语言内容安全,并可对 23 个安全类别进行实时 PII 检测。
该模型通过 NVIDIA API 提供,无需额外托管基础设施,即可轻松添加输入和输出过滤。它可以基于语言、方言和文化背景区分含义不同但表达相似的短语,这在处理可能受到干扰或非正式的实时 ASR 输出时尤为重要。
from langchain_nvidia_ai_endpoints import ChatNVIDIA
safety_guard = ChatNVIDIA(model="nvidia/llama-3.1-nemotron-safety-guard-8b-v3")
result = safety_guard.invoke([
{"role": "user", "content": query},
{"role": "assistant", "content": response}
])步骤 5:使用 Nemotron 3 Nano 添加长上下文推理功能
NVIDIA Nemotron 3 Nano 为智能体提供推理能力,结合了高效的混合专家 (MoE) 机制和混合 Mamba-Transformer 架构,支持 1M token 上下文窗口。这使得模型能够在单个推理请求中合并检索到的文档、用户历史记录和中间步骤。
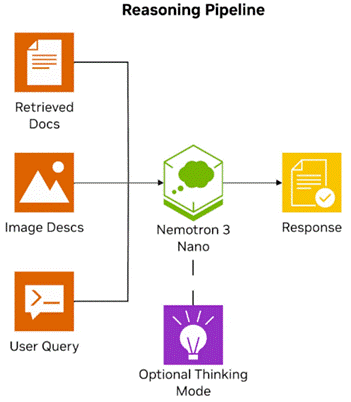
图 5. 使用 NVIDIA Nemotron 3 Nano 的推理管道。
当检索到的文档包含图像时,智能体首先使用 Nemotron Nano VL 来描述这些图像,然后将所有信息传递给 Nemotron 3 Nano 以获得最终的响应。该模型支持可选的思考模式,可用于更复杂的推理任务:
completion = client.chat.completions.create(
model="nvidia/nemotron-3-nano-30b-a3b",
messages=[{"role": "user", "content": prompt}],
extra_body={"chat_template_kwargs": {"enable_thinking": True}}
)输出在返回之前会通过安全过滤器,将您的检索增强型查找转换为具有完整推理能力的智能体。
步骤 6:使用 LangGraph 将所有内容连接起来
LangGraph 将整个工作流编排为一个有向图。每个节点处理一个阶段,即转录、检索、图像描述、生成和安全检查,组件之间有清晰的切换:
Voice Input → ASR → Retrieve → Rerank → Describe Images → Reason → Safety → Response
智能体状态流经每个节点,并在过程中积累上下文。这种结构简化了添加条件逻辑、重试失败步骤或基于内容类型进行分支。配套 Notebook 中的完整实现展示了如何定义每个节点,并将其连接到生产就绪型管道中。
步骤 7:部署智能体
智能体能够在本地机器上稳定运行后,您就可以将其部署到任意位置。在需要分布式摄取、嵌入生成或大规模批量向量索引时,可使用 NVIDIA DGX Spark。Nemotron 模型可以进行优化、打包并作为 NVIDIA NIM 运行(一套预构建的 GPU 加速推理微服务,专为在 NVIDIA 基础设施上部署 AI 模型而设计),并可直接从 Spark 调用以进行可扩展的处理。当您需要按需的 GPU 工作空间且无需系统设置直接运行 Notebook,同时还希望获得可与团队轻松共享的 Spark 集群远程访问时,可以选择使用 NVIDIA Brev。
如果您想查看适用于物理机器人助手的相同部署模式,请查看基于 Nemotron 和 DGX Spark 的 Reachy Mini 个人助理教程。
两个环境都使用相同的代码路径,因此您可以由实验阶段平稳过渡到生产环境,所需的修改极少。
您所构建的内容
现在,您拥有一个由 Nemotron 驱动的智能体核心结构,该结构由四个核心组件组成:用于语音交互的语音 ASR、用于实现信息真实性的多模态 RAG、考虑文化差异的多语言内容安全过滤,以及用于长上下文推理的 Nemotron 3 Nano。相同的代码适用于本地开发到生产级 GPU 集群运行。
| 组件 | 目的 |
| 多模态 RAG | 在真实的企业数据中锚定响应 |
| 语音 ASR | 实现自然语音交互 |
| 安全 | 跨语言和文化背景识别不安全内容 |
| 长上下文 LLM | 通过推理生成准确的响应 |
表 2. 用于构建基于 Nemotron 的语音智能体的四个组件概览——多模态 RAG、语音 ASR、多语言内容安全和长上下文推理。
本教程中的每个部分都与 Notebook 中的相应部分直接对应,因此您可以逐步实施和测试该流程。一旦端到端工作正常,相同的代码即可扩展到生产部署。
准备好构建了吗?打开配套 Notebook 并逐步跟进:
如果您想探索底层组件,以下是一些 Hugging Face 上可用的 Nemotron 模型集合,以及用于编排智能体的工具:
想要了解最新的 NVIDIA Nemotron 动态,请订阅 NVIDIA 新闻。
- 访问我们的 Nemotron 开发者页面,获取入门所需的所有核心资源,体验开放、高计算效率的智能推理模型。
- 在 Hugging Face 上探索全新的开放 Nemotron 模型和数据集,以及在 NVIDIA 官网 上使用 NIM 和 Blueprint。
- 分享您的想法并为功能投票,助力塑造 Nemotron 的未来发展。
- 关注即将到来的 Nemotron 直播,与 NVIDIA 开发者社区通过 Nemotron 开发者论坛进行联系。




