
NVIDIA ACE 是一套用于构建游戏 AI 智能体的技术。ACE 为游戏中角色的各个部分(从语音到智能,再到动画)提供可直接集成的云端和设备端 AI 模型。
为了高效地在游戏引擎中运行这些模型,NVIDIA 游戏内推理 (NVIGI) SDK 提供了一组性能库,开发者可将其集成到 C++ 游戏和应用中。
NVIDIA In-Game Inferencing SDK 1.5 引入了一个新的代码代理示例,其中 AI 代理与玩家协作,在 2D 地牢中共同击败怪物。由本地小型语言模型(SLM)驱动的 AI 智能体可能会频繁调用推理任务,从而与图形处理争夺 GPU 资源。本文将探讨如何有效减少推理调用的频率,并提升每次调用的执行效率,以缓解图形渲染与计算任务在 GPU 上的资源冲突。
代码代理:捕获幽灵
Andrej Karpathy 是 OpenAI 的创始成员,他将大语言模型 (LLM) 比作召唤幽灵,这是对LLM代理,尤其是编写代码的代理的贴切比喻。许多自定义智能体仅限于工具调用:定义函数,由LLM决定何时调用,并返回结果。还有一个更有抱负的可能性。与其仅仅调用函数,不如让AI代理创建函数和支持它的代码。这使机器在处理量较少的情况下更强大。
不过,这需要权衡取舍。具备代码执行功能的无限制 LLM 存在安全风险。它可能耗尽内存,导致游戏进程卡顿,甚至如一位不幸的用户所经历的那样,在试图“清除缓存”时意外擦除整个硬盘。
它具备复杂的多步骤推理、动态适应能力,并能有效降低小语言模型(SLM)的使用频率等优势。接下来将深入探讨潜在的编码代理 ghoul 是如何转变为乐于助人的友好幽灵的。<!–
为什么代码代理比工具调用更出色
在讨论 AI 智能体时,常见的用例和方法是工具调用。模型输出结构化 JSON,游戏或应用对其进行解析,进而执行相应的函数。尽管调用函数的能力十分强大,但这只有在模型有充分机会进行推理后才能实现,而推理过程往往成本较高,尤其是在争夺用户 GPU 资源时。
模型发送 JSON 后,会等待响应、重新思考并返回答案,这一过程可能反复循环,从而占用本可用于渲染游戏的宝贵时间。
此外,若函数调用周围涉及复杂的逻辑,系统便不得不依赖较弱的模型能力。该模型本身并不支持循环,仅能生成 tokens。它或许能尝试追踪状态变量,但这种方式并不严谨。当需要处理多个项目时,模型必须准确记住每一项,避免遗漏、重复或产生幻觉性条目。而每处理一个项目,都会带来相应的推理开销。<!–
数值分析带来了另一项挑战。通过工具调用,结果的准确性取决于模型的数学能力,或需编写额外函数以确保正确性。
工具调用可能难以扩展。每次函数调用都需要额外的推理请求,从而竞争 GPU 资源,因此必须采取措施加以缓解。
代码代理的工作方式是利用计算机擅长的能力——运行代码。编程是语言模型新兴的超能力之一。单次推理可一次性生成全部函数调用,而非逐次生成。首次生成后不会影响性能,后续仅标准代码持续运行直至任务完成。
它们具有很高的灵活性。尽管语言模型难以自主实现循环,但代码代理却能轻松编写包含循环、计数器和过滤器的代码。以下是一个假设示例,展示如何通过工具调用来攻击敌人:
工具调用模式:
[
{
"name": "get_enemies_list",
"parameters": {
"properties": {
"position": {"type": "string", "description": "Position to search from"},
"radius": {"type": "number", "description": "Search radius"}
}
}
},
{
"name": "target_enemy",
"parameters": {
"properties": {
"enemy_name": {"type": "string", "description": "Name of the enemy to target"}
},
"required": ["enemy_name"]
}
}
]当用户说“瞄准最近的敌人”时:
- 推理调用 1:SLM 决定调用
get_enemies_list - 工具响应:返回
["goblin_01", "skeleton_archer_01", "orc_chief"](仅返回字符串,否则完整的实体模式会使上下文窗口失效) - 推理调用 2:SLM 看到列表,从中选择一项,调用
target_enemy("goblin_01") - 工具响应:Success
- 推理调用 3:向用户提供函数调用状态的反馈
一次决策需要三次推理。可考虑使用代码代理来执行相同的“目标敌人”操作。
代码代理 API 定义:
get_enemies(position, radius)
--[[
Find enemies near a position.
Parameters:
position (table): Center point as {row, col}
radius (number): Search radius
Returns:
table: Array of enemy entities (with .name, .position, .health, etc.)
Example:
local nearby = get_enemies(ally.position, 10)
]]
set_target(ally, enemy)
--[[
Set an ally's attack target.
Parameters:
ally (entity): The ally to command
enemy (entity): The enemy to target
Example:
set_target(warrior, nearby[1])
]]小语言模型生成的“瞄准最近的敌人”代码:
local enemies = get_enemies(ally.position, 10)
local closest = nil
local min_dist = math.huge
for _, enemy in ipairs(enemies) do
local dx = enemy.position[1] - ally.position[1]
local dy = enemy.position[2] - ally.position[2]
local dist = math.abs(dx) + math.abs(dy)
if dist < min_dist then
min_dist = dist
closest = enemy
end
end
if closest then
set_target(ally, closest)
end通过一次推理调用,SLM 会循环攻击敌人,访问其位置,计算距离,然后选择较近的位置。代码代理获取丰富的实体对象(而不仅仅是字符串),并合成出工具设计者未曾设想的逻辑。
请注意其灵活性。相同的 get_enemies 函数适用于玩家附近、盟友附近或点附近的敌人。在 SLM 获取敌人列表后,它能够编写各种选择逻辑,例如瞄准弱于箭头的敌人、瞄准距离最近的敌人或瞄准生命值较少的敌人。通过工具调用,适应新需求意味着需要更多工具、更多推理调用以及更高复杂性。而借助代码代理,SLM 能在运行时基于相同的简单基元构建新策略。<!–
Code 智能体示例地牢
IGI SDK 与 ghoulish 主题保持一致,包含一个 ASCII 地牢爬虫来演示代码代理。地牢包含大型游戏的核心要素,但采用的是最简化的游戏形式之一。玩家可以自由移动、收集物品并与怪物战斗。在冒险过程中,他们还拥有一位强大的盟友——AI 智能体。这是一种可按需激活的情报助手,能够协助战斗、执行危险任务或提供关于潜在威胁的预警信息。
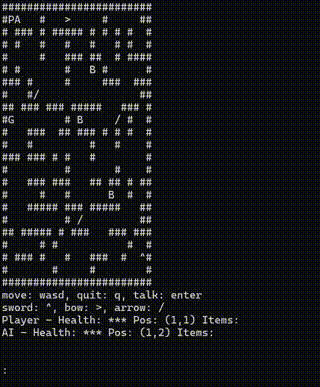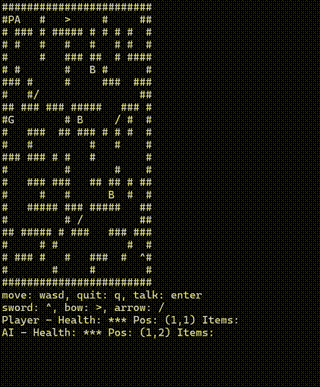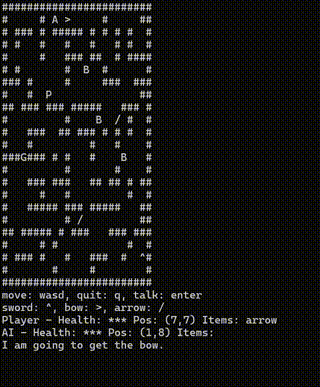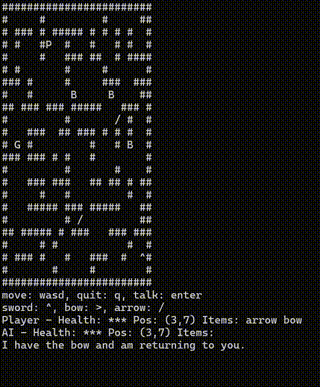
一旦给出指令,代码就会被写入;在收到新指令之前,程序不会再次访问 SLM。工具调用链可能产生相同的结果,但重复的推理调用会占用分配的帧时间切片,从而带来额外开销。
代码智能体的威胁模型
使用 SLM 生成在主机上运行的代码会带来显著的安全风险,包括:
- 危险的功能访问。 SLM 可能生成
os.execute("rm -rf /")或require("socket"),导致代码代理意外删除文件或开启网络连接。 - 未经授权的文件访问。 SLM 可能发现关键文件或 API 密钥,进而进行过滤或删除操作。
- 资源枯竭。 小语言模型(SLM)可能编写持续分配内存的循环,造成系统资源耗尽。
- 堆栈溢出。 SLM 可能编写缺乏正确终止条件的递归函数,引发堆栈溢出。
- 无限循环。 SLM 可能写入
while true do end,但始终无法返回,导致程序陷入无限循环。 - 逃离沙盒。 小语言模型(SLM)可能操纵内部结构,突破其运行环境的限制。
- 状态破坏。 小语言模型可能扰乱游戏或应用程序的正常运行状态。
选择目标语言
在选择目标语言时,应考虑执行时间、整体性能、集成与调试的复杂程度,以及所生成代码的质量和安全性。
运行游戏时,推理调用仅占用总帧时间的一小部分。渲染管线中频繁出现的高延迟是不可接受的。尽管每帧可生成多个 tokens 以实现推理过程的平滑化,但编译型语言无法提供这种灵活性。这使得 C++ 或 C# 等编译语言不再适用,而需要采用解释型语言。
例如,两种编程语言:Python 和 Lua。
Python 显然是首选。小型语言模型能够流畅地生成 Python 代码,其生态系统也十分庞大。然而,Python 并未针对嵌入或沙盒环境进行设计。全局解释器锁(GIL)使得多线程宿主环境变得复杂,而实现隔离通常需要依赖子进程或子解释器,这进一步增加了系统复杂性。此外,Python 缺乏限制内存使用或执行时间的内置机制。尽管 Python 可以在沙盒中运行,但这相当于与语言本身的设计全面对抗。
Lua 的设计初衷是在恶劣环境中实现嵌入。整个运行时大小约为 200 kB,启动时间为亚毫秒级。此外,针对每个已识别的威胁,均已记录相应的缓解措施,包括:
- 危险函数:选择性加载库。若不加载
io或os,则它们不存在。 - 内存耗竭:自定义分配器 hook。追踪每次内存分配,实施上限控制。
- 栈溢出:函数调用时的调试 hook。统计调用深度,检测溢出错误。
- 无限循环:指令计数时的调试 hook。执行 N 条指令后触发错误。
- 可元操作:从全局变量中移除
getmetatable/setmetatable。 - 状态损坏:自定义
_ _newindex元方法,用于阻止写入受保护字段。
因此,Lua 符合此 IGI 示例的所有要求,但仍需进行硬化处理。使用 Lua 时,可将危险或不需要的函数设为 nil (lua_pushnil(L); lua_setglobal(L,”funcname”) 模式。内存增长通过默认分配器的封装和分配跟踪加以限制。程序员可设置 Hook (lua_sethook),以确保程序不会耗尽调用堆栈或无限期挂起。同样,可通过锁定自定义元方法来限制元访问,从而保护游戏状态。
以下仅为锁定此样本的部分步骤。根据每个特定游戏或用例的不同,可能还需补充其他内容,但这些提示应有助于引导读者查看代码。
为了提高安全性,可将 Lua 嵌入到 Web 程序集运行时中。有关如何保护代理行为的更多信息,请参阅博客文章使用 WebAssembly 技术实现沙盒代理式 AI 工作流和沙盒代理式工作流和管理执行风险实用安全指南。
安全性是核心问题,而非事后补救。选择编程语言是一种安全抉择,而非单纯出于便利的考量。基于这一前提,深入理解需要防范的各类攻击向量,便能让“幽灵”化为机器中的伙伴。
开始使用 NVIDIA 游戏内推理 SDK
使用 NVIDIA 游戏内推理 SDK 尝试该示例。进行构建、实验,并探索其在游戏、应用及其他项目中的应用方式。
加入我们的 GDC
探索 NVIDIA RTX 神经网络渲染与 AI 如何塑造下一个游戏时代。携手 NVIDIA 开发者与性能技术副总裁 John Spitzer,揭示路径追踪与生成式 AI 工作流中的全新突破,一窥游戏开发的未来图景。
与 NVIDIA 应用深度学习研究副总裁 Bryan Catanzaro 一起参加“Ask Me Anything”互动会议,深入了解 AI 的前沿趋势。




