快速里叶变换 (FFT) 广泛应用于科学计算,涵盖分子动力学、信号处理、计算流体动力学 (CFD)、无线多媒体以及机器学习等领域。随着计算问题规模不断扩展至更大范围,研究人员需要能够将 FFT 计算分布在数百或数千个 GPU 上,跨越多个节点进行高效处理。
NVIDIA cuFFTMp 是 cuFFT 的多 GPU、多节点(MGMN)扩展程序,可帮助科学家和工程师在百亿亿级(Exascale)平台上解决具有挑战性的问题。如之前博客所述,NVIDIA cuFFTMp 已在 Volta 和 Ampere 架构的超级计算机上实现成功扩展,基于这一成果,我们将进一步展示该库在新一代 NVIDIA GPU 架构上的强大扩展能力。 as detailed in a previous blog
本博客将展示 MGMN FFT 在先进集群配置中的性能新成果,体现了 cuFFTMp 充分释放现代 MGMN 超级计算机潜能的能力。
cuFFTMp 如何在 NVIDIA Hopper 平台上运行并实现高效扩展
我们在 NVIDIA Eos 超级计算机上对 cuFFTMp 进行了基准测试,并将结果与之前博客中提到的 Selene 超级计算机进行了对比。Eos 采用 NVIDIA DGX H100 系统构建,每个节点配备两个英特尔至强 Platinum 8480C 56 核 CPU 和八块通过 NVLink 4 交换机(900 GB/s,双向)互连的 H100 GPU。所有节点之间通过 NVIDIA Quantum-2 InfiniBand(400 Gb/s/节点,双向)实现互联。
与 Selene 中的网络硬件相比,Eos 的 NVLink 速度在带宽方面提升了 1.5 倍,InfiniBand 速度提升了 2 倍。这一对比尤为有价值,因为这两个系统均代表了连续几代 GPU 的先进配置,有助于量化研究人员在将基础设施从 Ampere 升级到 Hopper 平台时所能预期的实际性能提升。
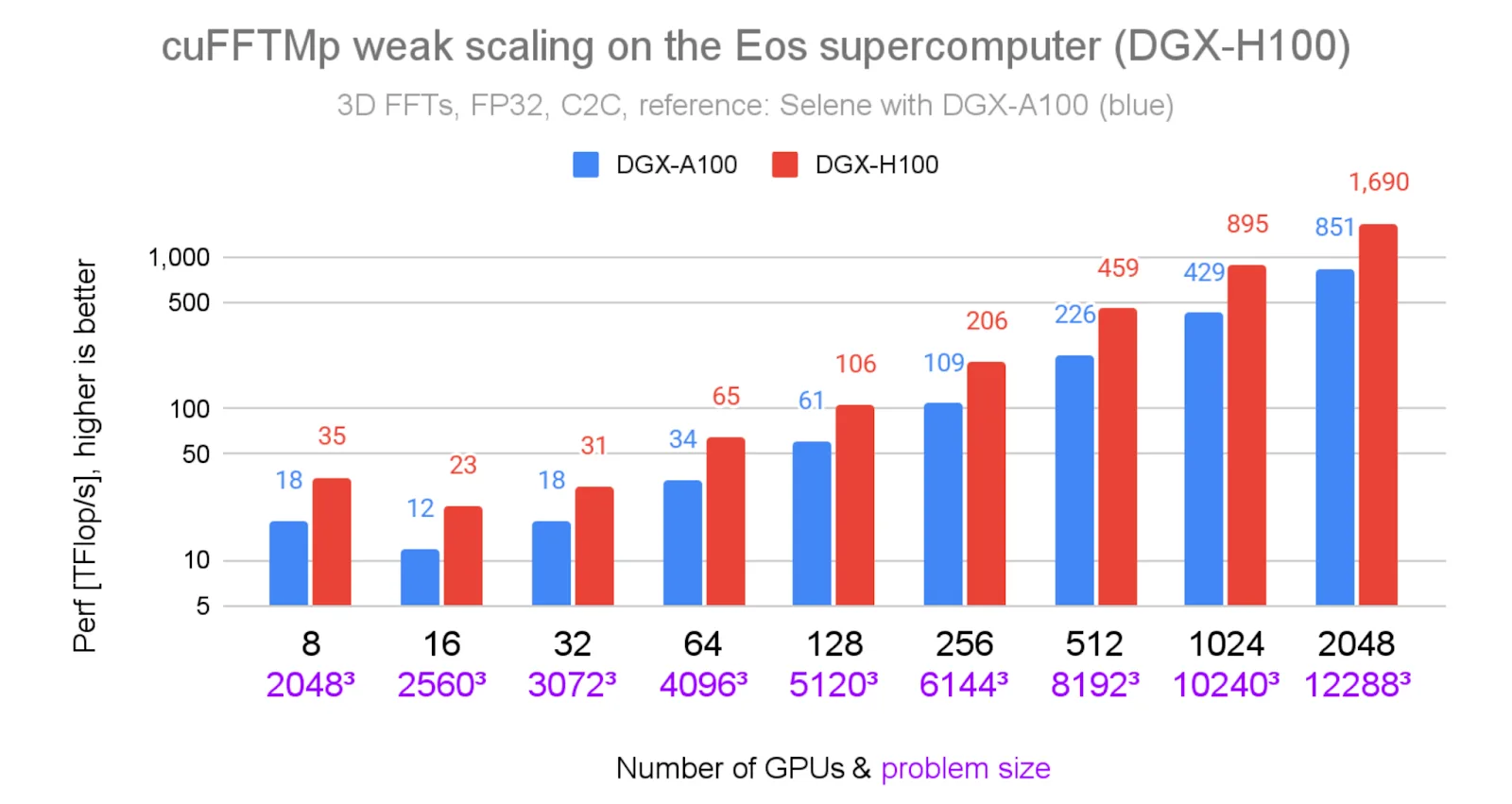
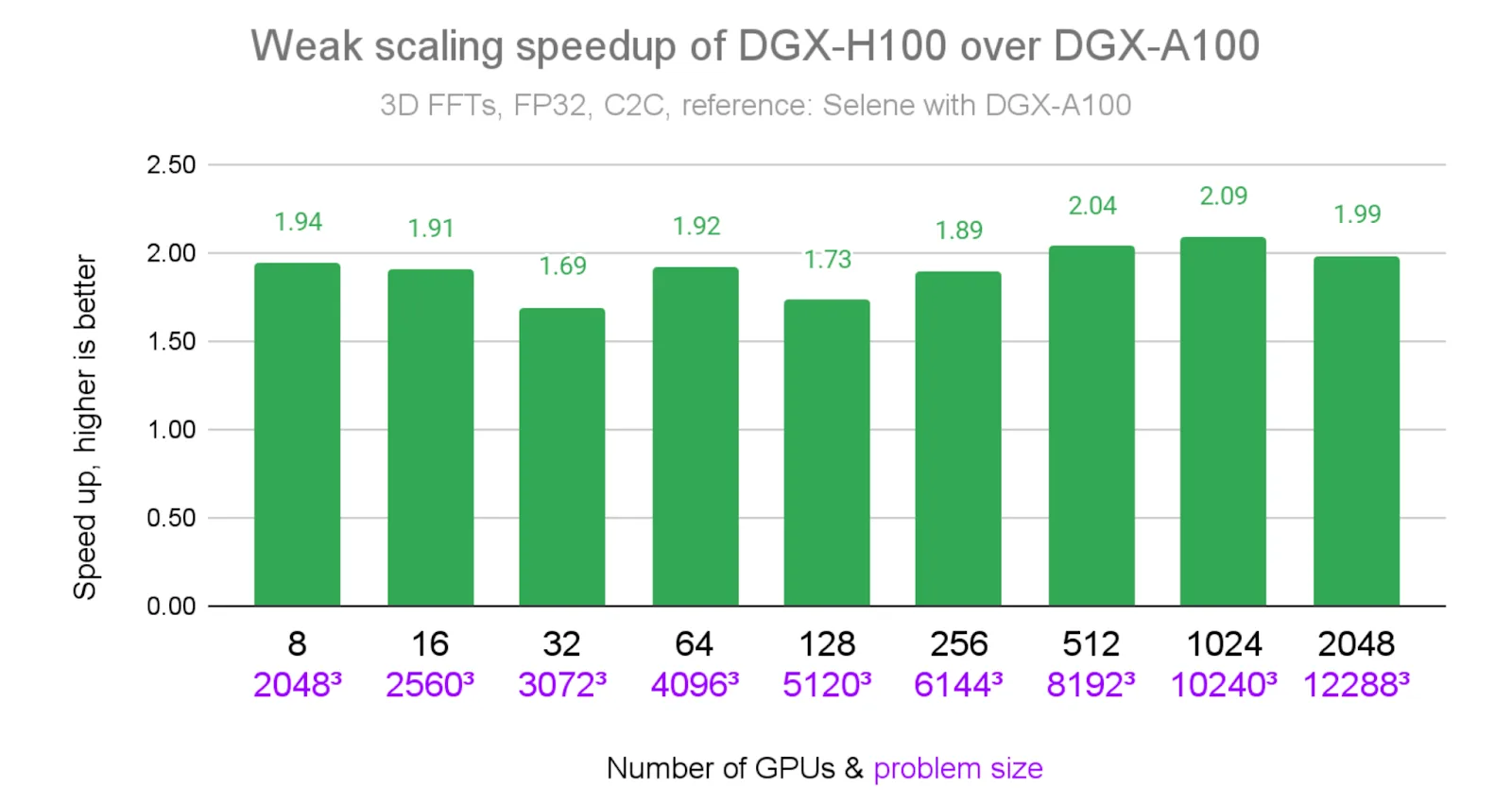
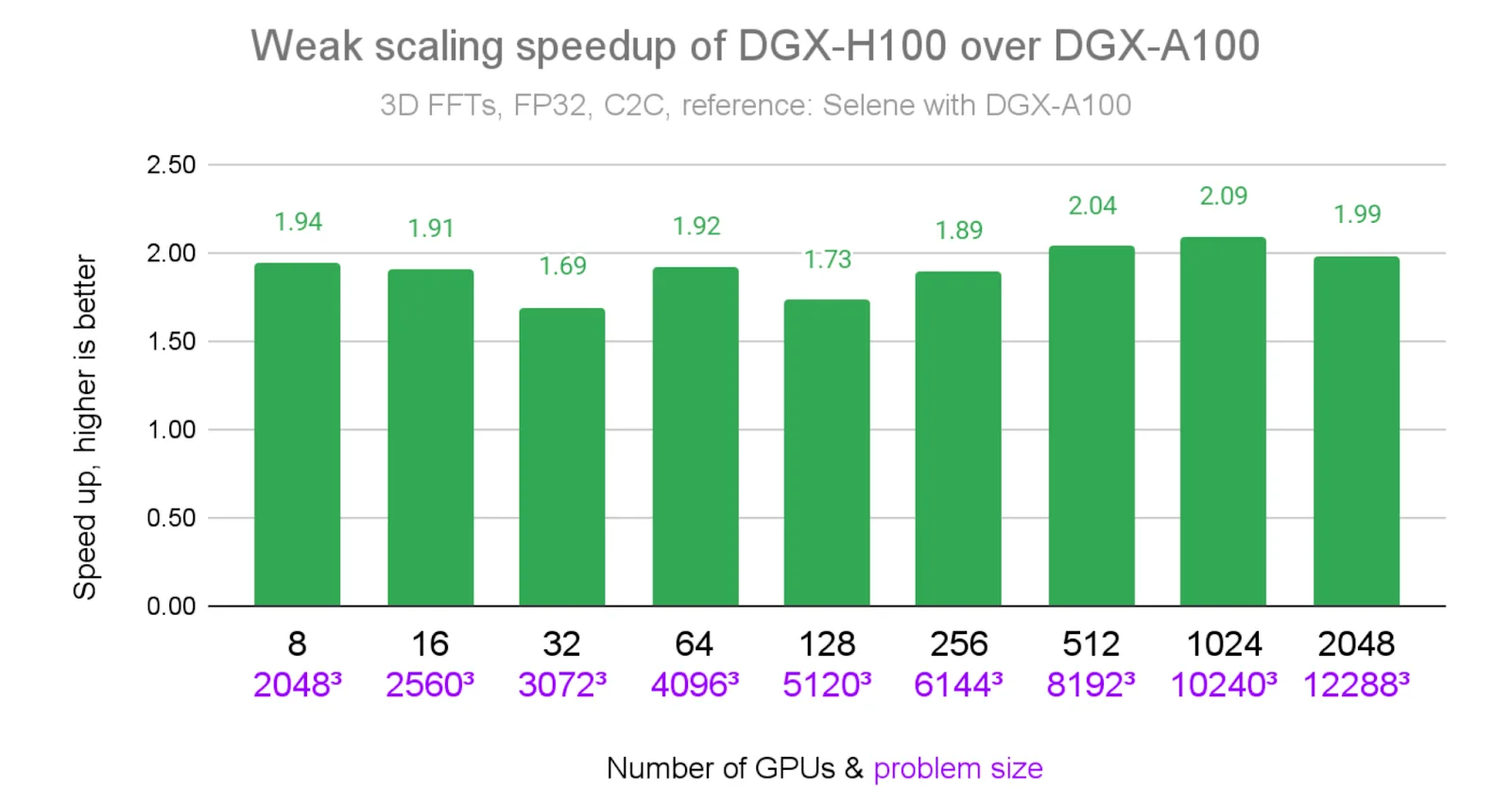
上图 1 展示了 NVIDIA Eos 超级计算机上 cuFFTMp 在不同问题规模下的稳健弱扩展性。下图 2 显示了与 Selene 相比,Eos 上 cuFFTMp 结果的相对加速比。在各个 GPU 数量配置下,cuFFTMp 均可持续实现约 2 倍的加速(最高达 2.09 倍),并在使用 2048 个 GPU 时达到 1.69 PFlop/s 的性能。
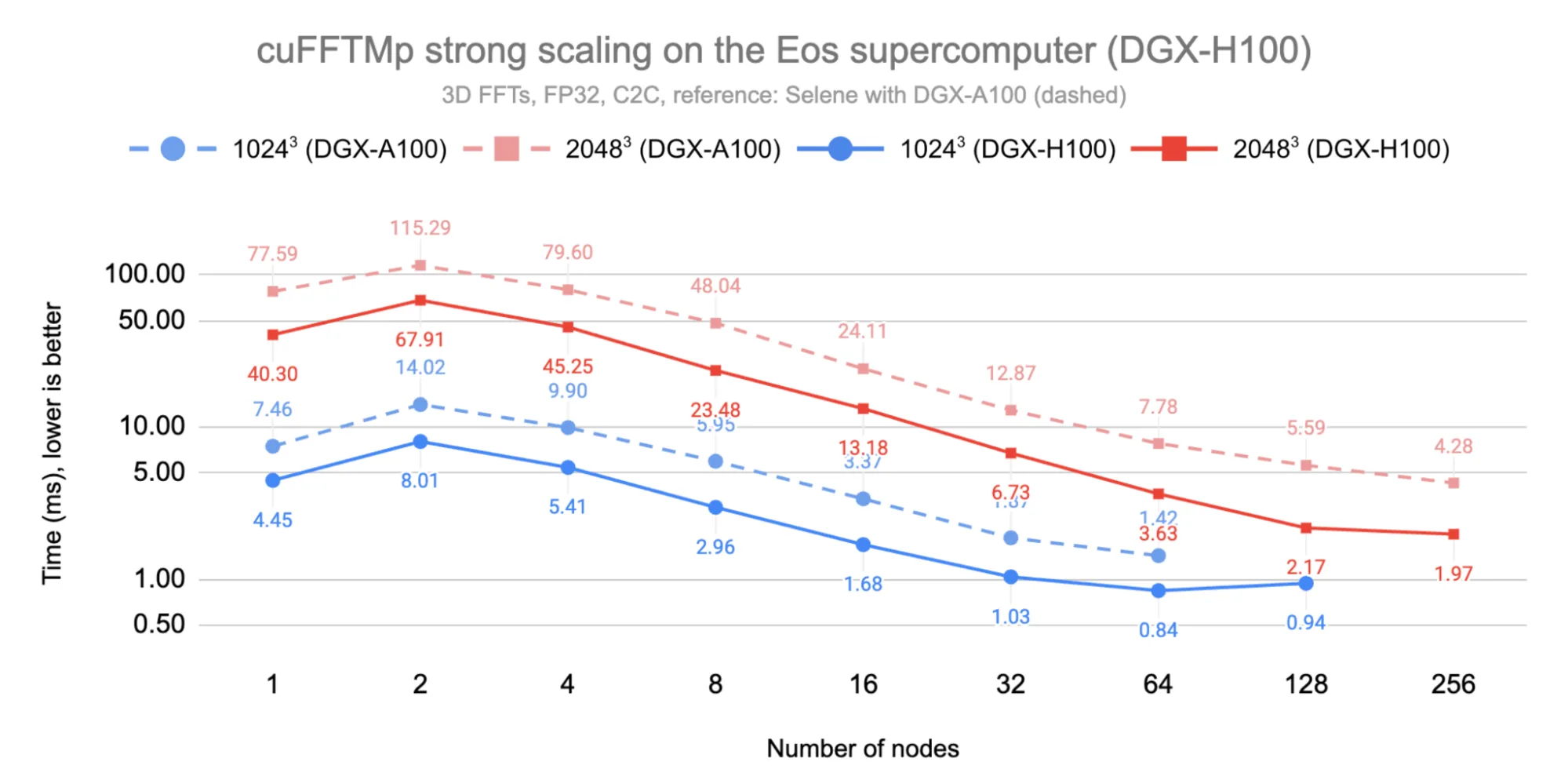
下图 3 显示了 cuFFTMp 在 1024³ 和 2048³ 这两种问题规模下的强扩展性。我们观察到,由于 InfiniBand 相较于 NVLink 的峰值带宽较低,因此在从单节点(8 个 GPU)扩展到双节点(16 个 GPU)时出现了性能变化。随后,系统实现了向 256 个节点(2048 个 GPU)的线性扩展。性能分别在超过 64 个和 128 个节点后开始趋于稳定。
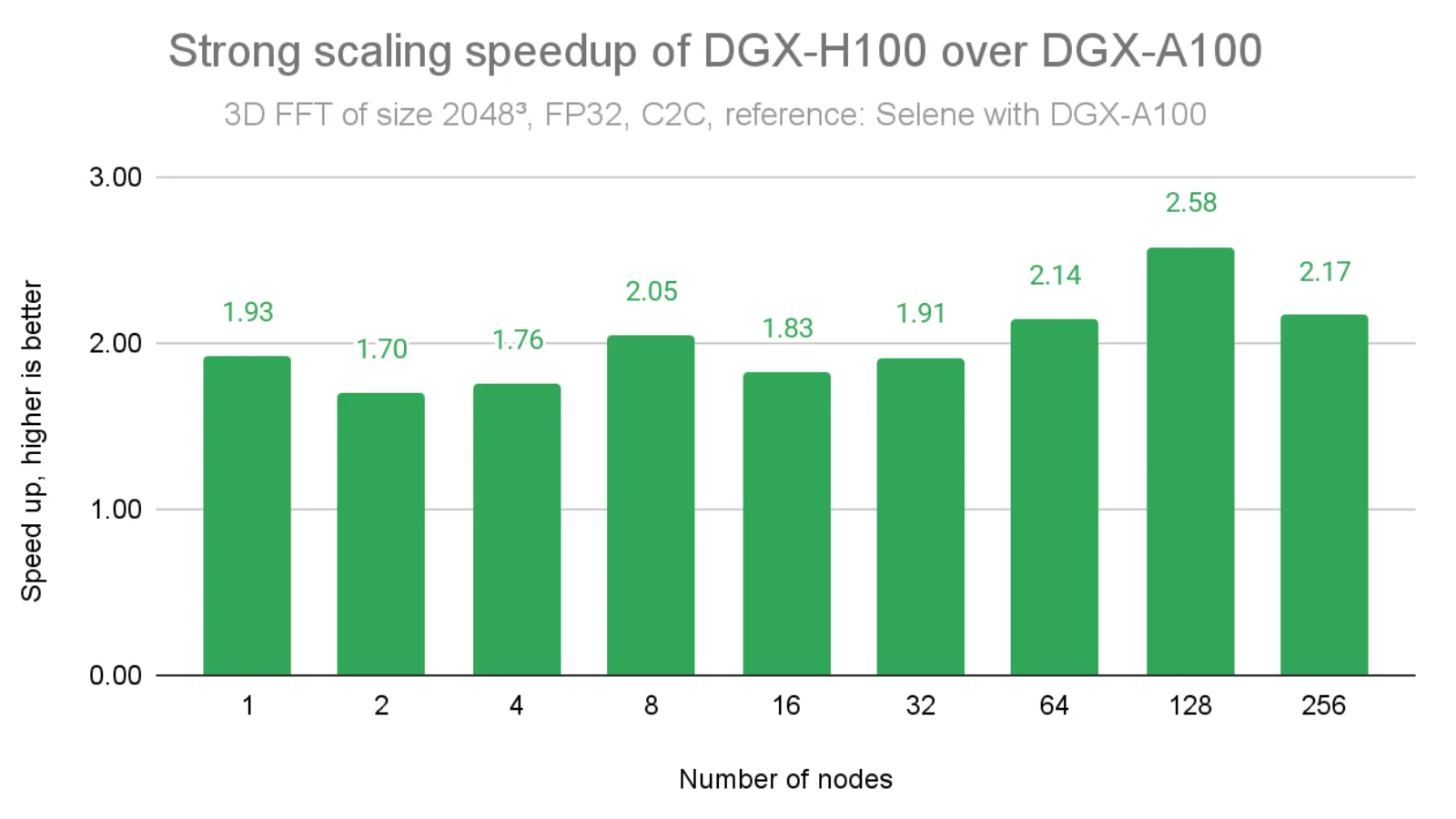
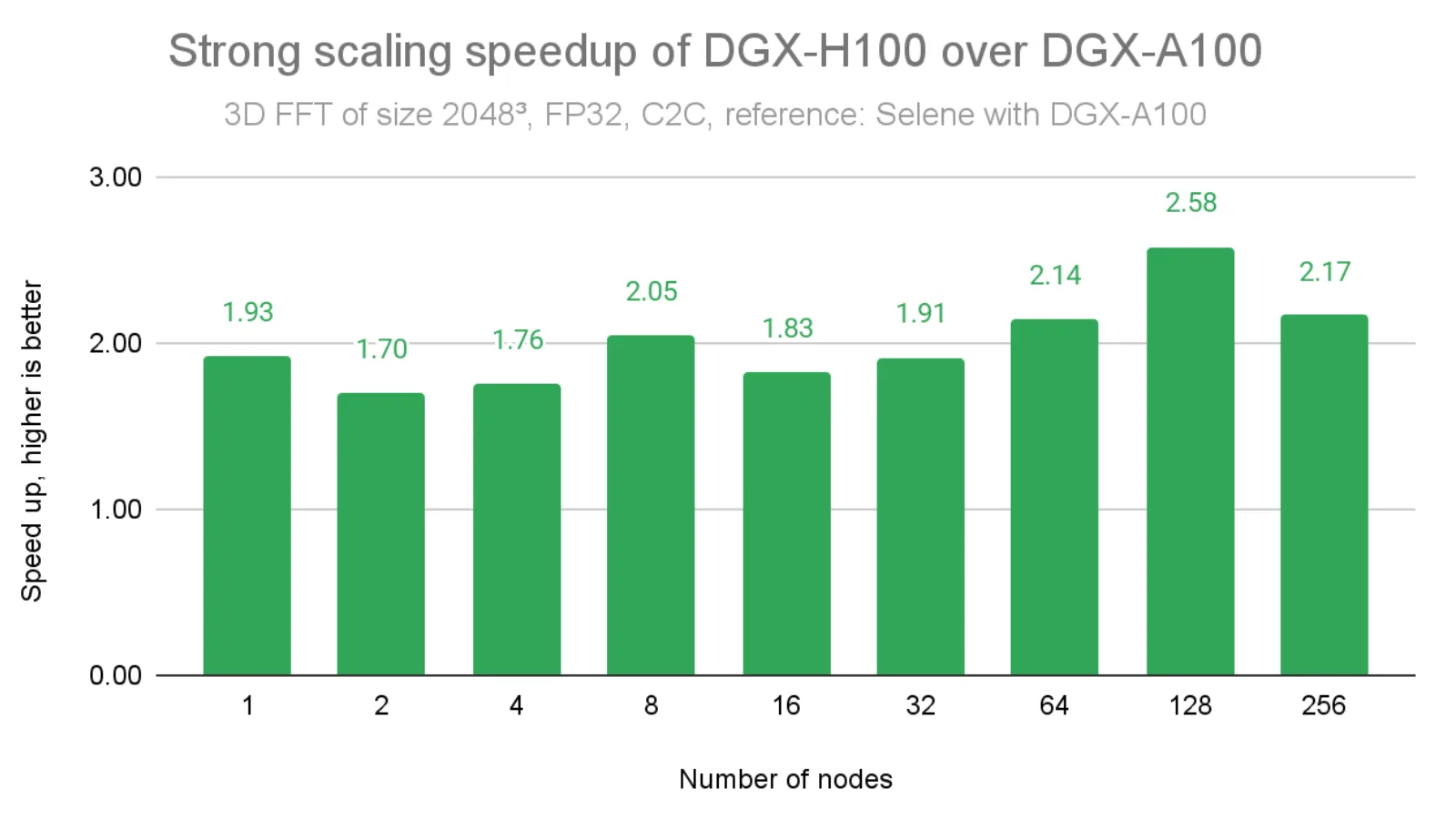
如下图 4 所示,与 DGX A100 在问题规模为 2048³ 时的结果相比,当 InfiniBand 带宽提升 2 倍时,我们获得了约 2 倍的加速。在某些情况下,由于 cuFFTMp 采用了先进的融合内核实现,弥补了此前迭代中存在的性能差距,加速比甚至超过了 2 倍(例如,在 128 个节点时达到 2.58 倍)。
cuFFTMp 如何在 NVIDIA Blackwell 平台上运行并实现高效扩展
NVIDIA 的 Blackwell 架构显著提升了互连带宽。重要的是,Blackwell 引入了多节点 NVLink (MNNVL) 技术,能够跨机架内的多个节点扩展高带宽 NVLink 连接。cuFFTMp 借助底层硬件拓扑与网络特性,实现优异性能。
下图 5 展示了在新一代 NVIDIA Blackwell 系统上 1024+ FFT 的结果。NVIDIA DGX B200 系统由 8 个全互联 B200 GPU 组成,采用第五代 NVLink 和 NVLink Switch 技术,所提供的带宽是上一代产品的 2 倍(1.8 TB/s/ GPU,双向带宽)。NVIDIA GB200 NVL72 系统是全新的 MNNVL 机架级扩展系统,每个节点包含两个 72 核 Grace CPU 和四个 Blackwell GPU,每个机架包含 18 个节点。同一机架中的 GPU 通过 NVLink 5 交换机以峰值带宽互连。对于这两个系统,不同机架之间通过 NVIDIA Quantum-2 InfiniBand(400 Gb/s/ 节点,双向)连接。
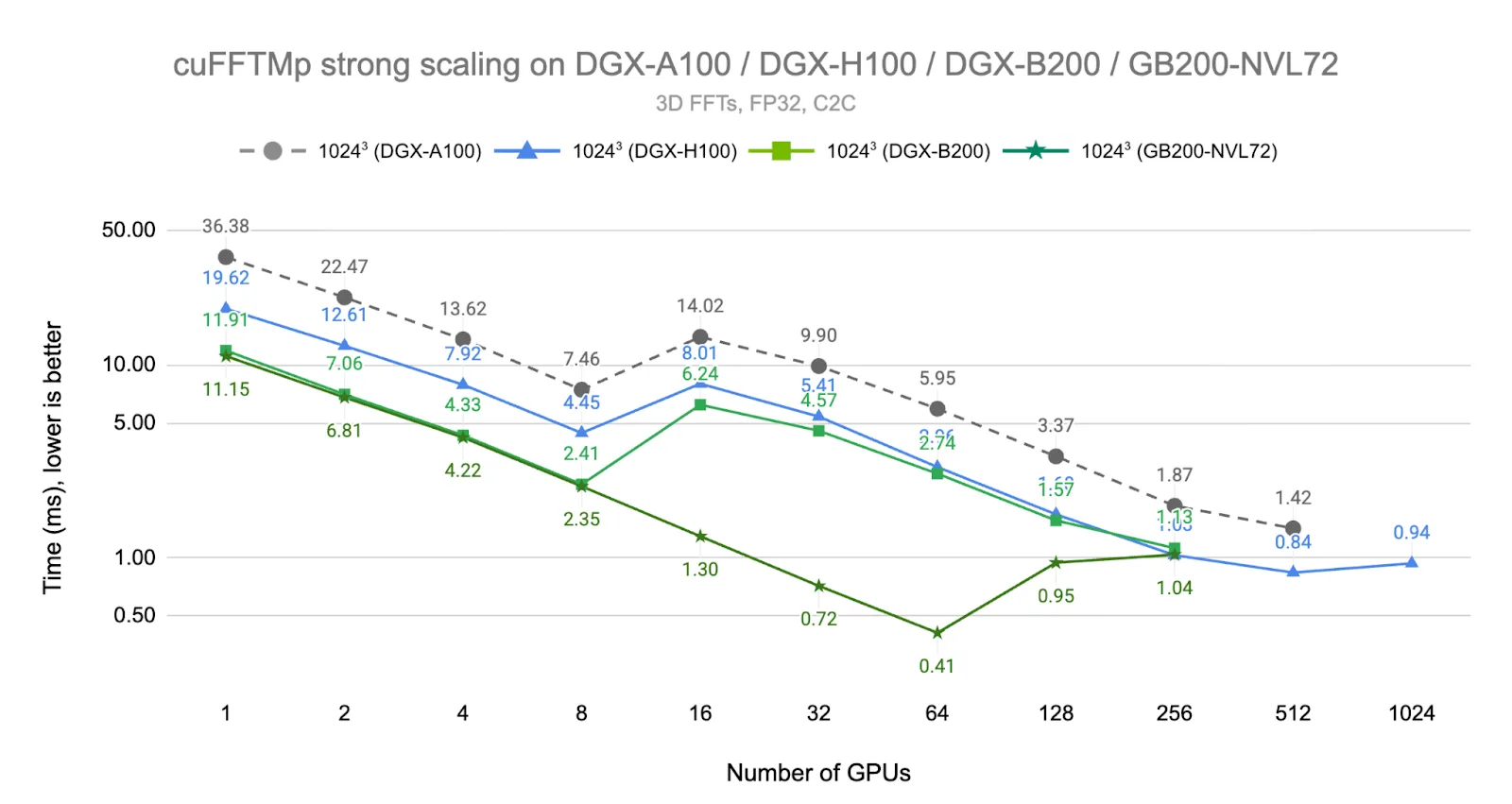
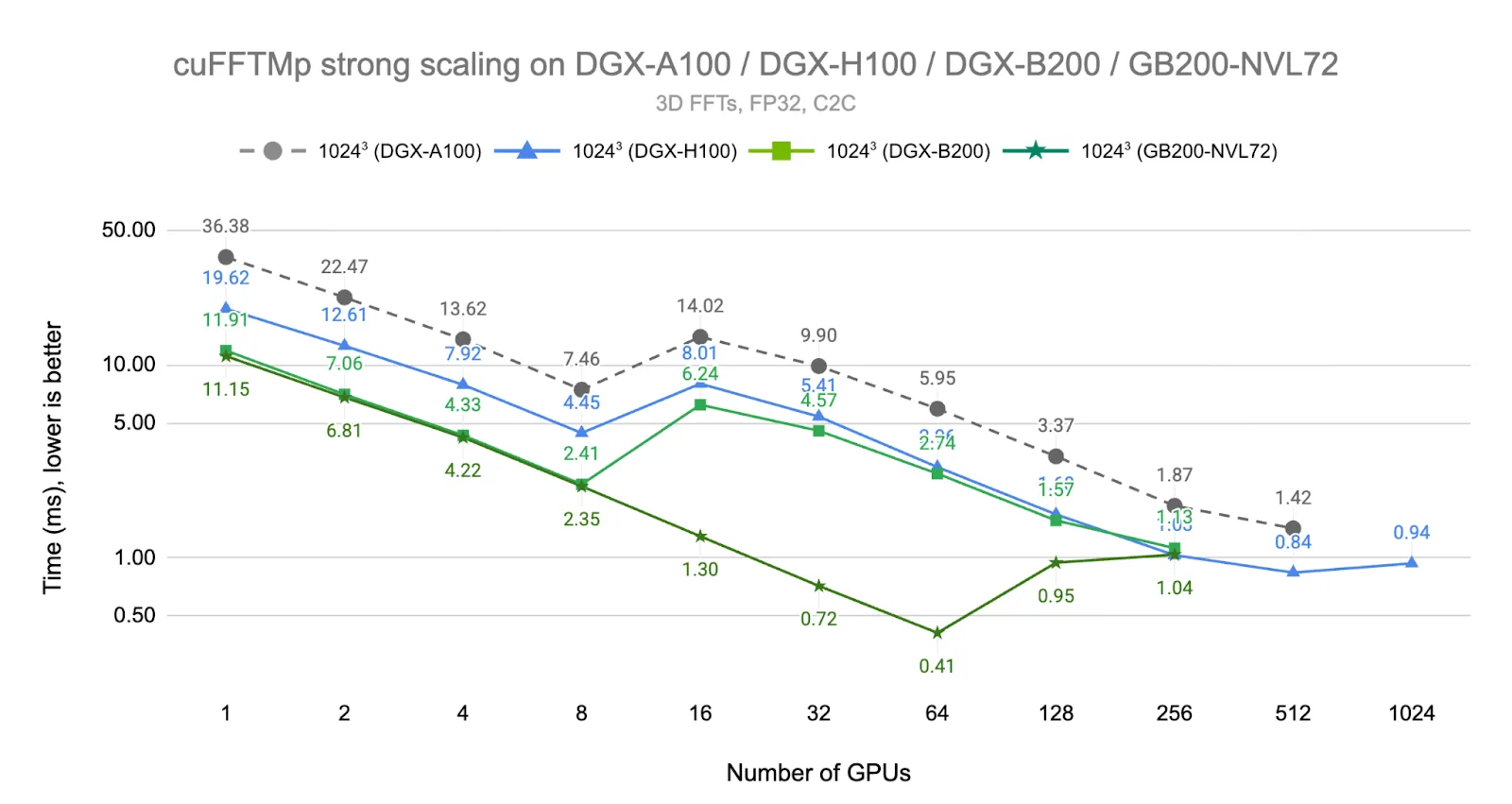
我们首先观察到,在多达 8 个 GPU 的情况下,从 Ampere 到 Blackwell 系统的速度提升了约 3.1 倍(从 Hopper 到 Blackwell 为 1.7 倍)。对于 DGX B200 系统,由于已达到 InfiniBand 的峰值带宽,因此在 16 个 GPU 上呈现出与 DGX H100 系统相似的性能表现。然而,GB200 NVL72 能够在多达 64 个 GPU 上实现一致的线性扩展,因为所有 64 个 GPU 均位于同一 NVLink 域内,并享有峰值 NVLink 带宽。
值得注意的是,由于累积的通信延迟开销,NVIDIA GB200 NVL72 在 64 个 GPU 上的执行时间表现,即便在 1024 个 H100 GPU 上也难以超越,这表明 MNNVL 在延迟敏感型工作负载方面具备根本性的架构优势。在 128 个 GPU 规模下,性能表现取决于 NVIDIA GB200 NVL72 不同机架间 InfiniBand 连接的状况。在所有基准测试中,尽管 GPU 数量存在差异,InfiniBand 横向扩展连接机制中的性能仍趋于收敛,原因是所有 InfiniBand 连接共享相同的带宽特性。
GROMACS 如何利用 cuFFTMp 进行生物分子模拟
GROMACS,广泛用于模拟生物分子系统的科学软件包,在理解对疾病预防和治疗至关重要的生物过程方面发挥着关键作用。在之前的博客中,我们介绍了如何将 cuFFTMp 集成到 GROMACS 中,从而显著提升其可扩展性。现在,我们展示了在全新的 Grace-Blackwell MNNVL 架构上运行该软件所取得的进一步突破。
我们对包含 590 万个原子的“PRS2”测试用例进行了基准测试,该系统在突触囊泡融合模拟的新研究中具有重要意义:这些测试揭示了参与神经递质释放的关键蛋白质如何促使神经递质中的关键结构与细胞膜融合,这是神经细胞通信中的一个关键步骤。此外,我们还纳入了更大的包含 1240 万个原子的“benchPEP-h”案例,以便与之前的博客内容进行直接比较。
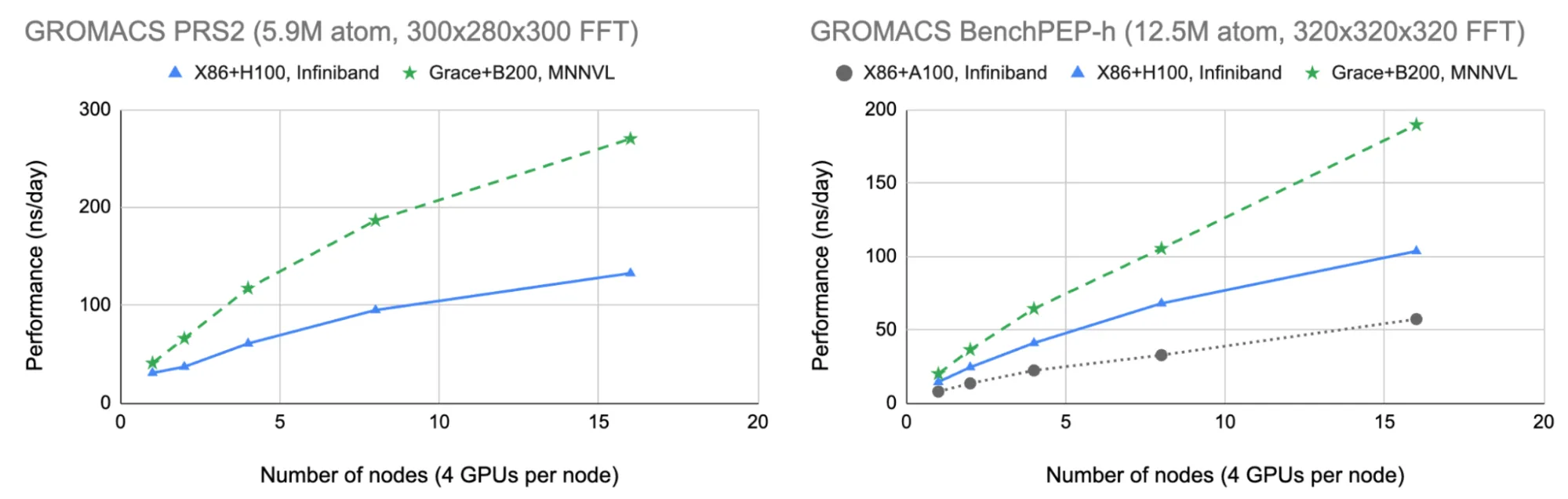
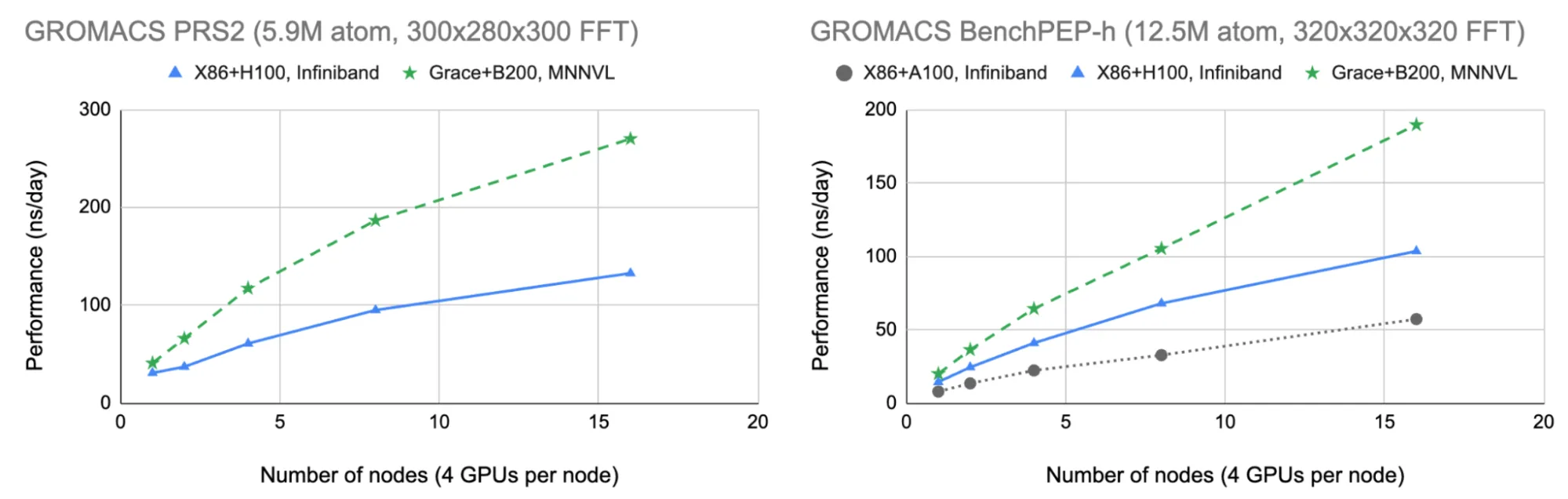
在图 6 的右图中,我们可以看到,NVIDIA Grace Blackwell 与 MNNVL 的结合使更大的 benchPEP-h 案例能够扩展到近 200 纳秒/天(每天计算执行的模拟速度为纳秒),相比 x86 + Hopper/InfiniBand 的结果提升了近 2 倍,相比上一篇博客中报告的同等 x86 + Ampere/InfiniBand 结果则提升了 3 倍以上。
在图 6 的左图中,我们可以看到较小的 PRS2 系统(相较于 benchPEP-h 对通信成本更敏感)展现出更显著的扩展性和性能优势。这表明,新的 Grace Blackwell MNNVL 架构不仅对扩展现代 AI 至关重要,而且非常适用于分子动力学:高带宽与低延迟的多节点通信使研究人员能够比以往更高效地获得模拟结果。
开始使用 cuFFTMp
对于希望利用这些性能改进的研究人员和开发者,cuFFTMp 现已作为独立软件包或 NVIDIA HPC SDK 堆栈的一部分,提供于 NVIDIA 开发者领地供下载。有关代码示例和 API 的使用方法,请参阅 cuFFTMp 文档。
cuFFTMp 依赖于 NVIDIA NVSHMEM 进行 GPU 启动通信,在过去几个版本中,其与 NVSHMEM 的兼容性已显著提升。自 cuFFTMp 11.2.6 起,主流 NVSHMEM 版本支持主机库与设备库之间的 NVSHMEM ABI 向后兼容性,从而允许在主要版本中独立更新 NVSHMEM,而无需同步更新 cuFFTMp。
Python 用户可以通过多种方式访问 cuFFTMp 功能。对于追求纯正 Python 体验的用户,可以使用 nvmath-python 库 将分布式 FFT 扩展到数千个 GPU,该库能够提供与原生 CUDA 实现相当的性能。此外,该库还提供用于低级集成的 Python 绑定。以下是使用带有 cuFFTMp 后端的 nvmath-python 计算分布式 FFT 的简短示例 示例。
import numpy as np
import cuda.core.experimental
import nvmath.distributed
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
nranks = comm.Get_size()
device_id = rank % cuda.core.experimental.system.num_devices
nvmath.distributed.initialize(device_id, comm, backends=["nvshmem"])
shape = 64, 256 // nranks, 128
a = np.random.rand(*shape) + 1j * np.random.rand(*shape)
b = nvmath.distributed.fft.fft(a, distribution=nvmath.distributed.distribution.Slab.Y)
偏好纯 cuFFTMp 二进制文件的用户可以从 PyPI 或 conda-forge 下载这些文件。
优秀的开发成果源自您的反馈,因此请通过以下网址与我们联系并提供您的建议:mathlibs-feedback@nvidia.com。
Leopold Cambier、Miguel Ferrer Avila 和 Lukasz Ligowski 为本博客中提及的工作做出了贡献。