
nvmath-python
nvmath-python(Beta)是一个开源库,通过重新构想 Python 面向性能的 API,在 Python 科学计算社区与 NVIDIA CUDA-X™ 数学库 之间架起桥梁。它可与 NumPy、CuPy 和 PyTorch 等现有数组库互操作并形成补充,通过状态化 API、即时(just-in-time)内核融合、自定义回调以及多 GPU 扩展等能力,将性能提升到新的水平。
Python 从业者、库开发者以及 GPU 内核开发者正在将 nvmath-python 作为一种高效工具,以较低的投入推动其科学计算、数据科学和 AI 工作流实现规模化扩展。
其他链接:
主要特性
直观的 Pythonic API
nvmath-python 对数学库 API 进行了重新设计,以支持更复杂的使用场景,这些场景在使用类似 NumPy 的 API 时往往难以实现,或者需要在性能上做出权衡。
Host API 通过可选参数提供开箱即用的简洁性以及丰富的自定义能力,从而可以访问底层 NVIDIA 数学库的各类“调节项”。Host API 分为通用 API 和专用 API。通用 API 旨在在不同内存/执行空间之间提供一致的用户体验,但它们可能不支持某些特定数据类型(这些数据类型依赖具体硬件),也不一定能够充分利用特定设备的能力,因此非常适合编写可移植代码。相比之下,专用 API 的应用范围更窄,可能只适用于特定硬件平台,但能够更充分地发挥硬件能力,其代价是可移植性较低。
Device API 允许在使用 numba-cuda 等 Python 编译器编写的自定义内核中嵌入 nvmath-python 库调用。您不再需要从头开始编写 GEMM 或 FFT 内核。
具有回调功能的 Host API 允许将自定义 Python 代码嵌入到 nvmath-python 调用中。内部 JIT 机制编译自定义代码,并与 nvmath-python 操作融合,实现峰值性能。
Stateful(类形式)API 允许将完整的数学运算拆分为规格定义、规划、自动调优和执行等阶段。将代价高昂的规格定义、规划和自动调优在前期完成一次后,其开销可以在后续多次执行中进行摊销。
与 Python 日志功能的集成,使得在运行时可以深入了解规格定义、规划、自动调优和执行机制的各类细节。
与 Python 生态系统的互操作性
nvmath-python 与热门 Python 包结合使用。其中包括 CuPy、PyTorch 和 RAPIDS 等基于 GPU 的软件包,以及 NumPy、SciPy 和 scikit-learn 等基于 CPU 的软件包。您可以继续使用熟悉的数据结构和工作流程,同时通过nvmath-python。
nvmath-python 并不能取代 NumPy、CuPy 和 PyTorch 等数组库。它不实现用于数组创建、索引和切片的数组 API。nvmath-python 旨在与这些数组库一起使用。所有这些依赖项都是可选项,您可以自由选择使用哪个数组库 (或多个库)nvmath-python。
nvmath-python 支持 CPU 和 GPU 执行以及内存空间。它简化了 CPU 和 GPU 实施之间的过渡,并允许实施 CPU-GPU 混合工作流程。
与 Python 编译器结合使用,例如 numba-cuda 您可以使用嵌入式技术实现 GPU 自定义内核 nvmath-python 库调用。
可扩展性能
在 CPU 端执行时,nvmath-python 利用 NVPL 库,在 NVIDIA Grace™ CPU 平台上实现出色性能。同时,它还通过使用 MKL 库来支持对 x86 主机的加速。
与 Python 编译器结合使用,例如 numba-cuda,您现在可以编写涉及 GEMM、FFT 和/ 或 RNG 运算的高性能内核。以下是使用 nvmath-python 将“不可能”变为可能的一些示例
nvmath-python 允许扩展到单个 GPU 之外,甚至扩展到单个节点之外,而无需进行大量编码工作。多 GPU 多节点 (MGMN) API 允许从单个 GPU 实现轻松过渡到 MGMN,并无缝扩展到数千个 GPU。该库还提供辅助实用程序,可根据需要重塑数据 (重新分区) ,而无需进行主要编码。
支持的操作
密集线性代数 - 广义矩阵乘法
该库提供一个广义矩阵乘法(GEMM),执行的运算为
𝐃 = 𝐹(ɑ ⋅ 𝐀 ⋅ 𝐁 + β ⋅ 𝐂),其中 𝐀、𝐁、𝐂 是维度与布局兼容的矩阵,ɑ 和 β 是标量,𝐹(𝐗) 是预定义函数(epilog),按元素方式作用在矩阵 𝐗 上。
文档
通用 Host API (即将推出)
分布式 API (即将推出)
教程和示例
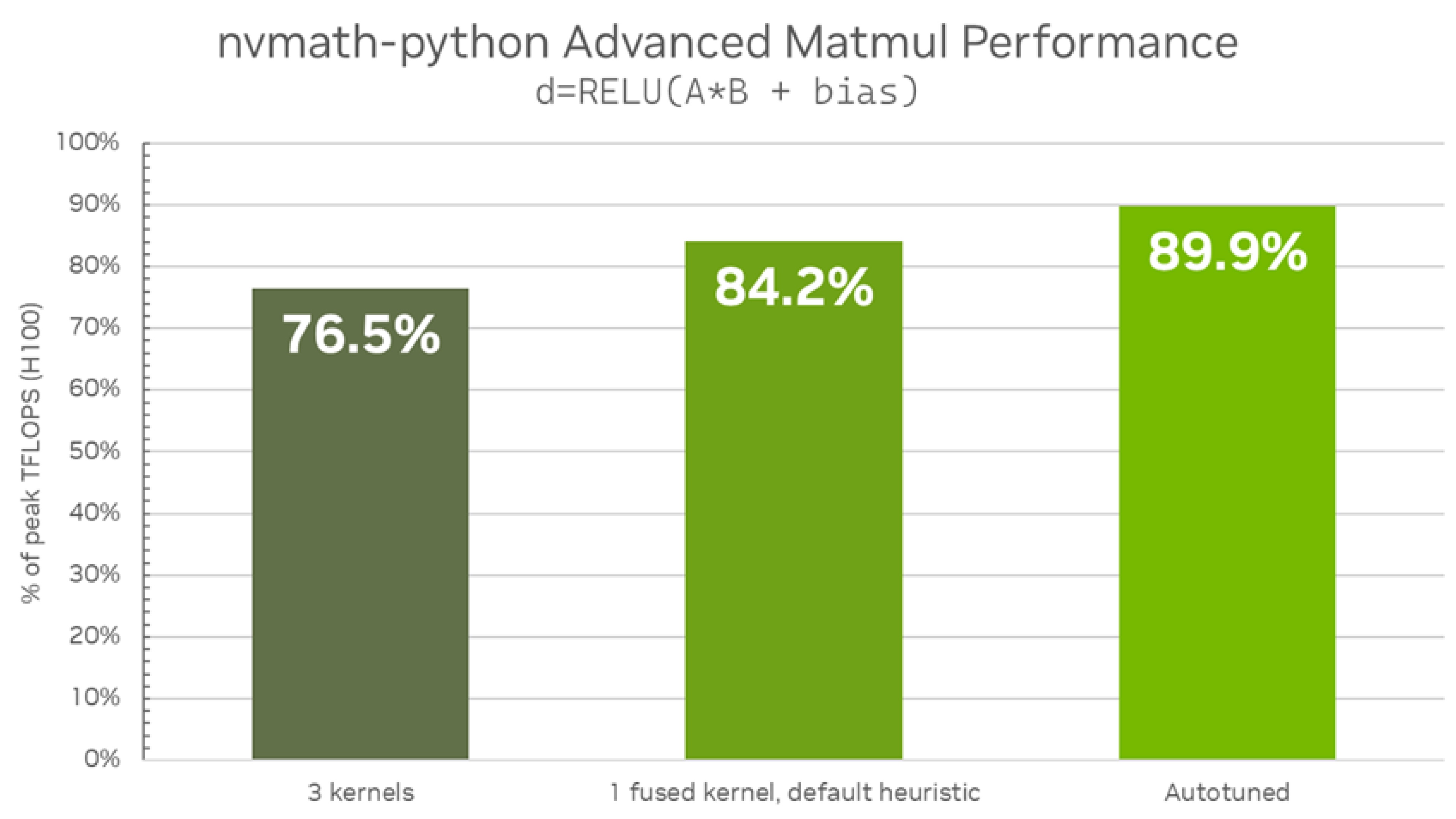
Host API 提供了一个位于 nvmath.linalg.advanced 子模块中的专用 API,其底层由 cuBLASLt 库驱动。此 API 仅支持 GPU 执行空间。该库的关键显著特点是能够将矩阵运算和后记融合到 单个融合内核。该库还提供执行其他操作的设施自动调整允许为特定硬件和特定问题大小选择最佳融合内核。两者兼有有状态以及无状态提供 API。通用 API 将在未来版本中实施。
Device API 位于 nvmath.device 子模块中,底层由 cuBLASDx 库提供支持。它们可以在 numba-cuda kernel 中使用。
分布式 API 将在未来的版本中实现。
快速里叶变换
该库为复杂到复杂 (C2C) 、复杂到现实 (C2R) 和真实到复杂 (R2C) 的离散里叶变换提供正向和反向 FFT。
文档
教程和示例
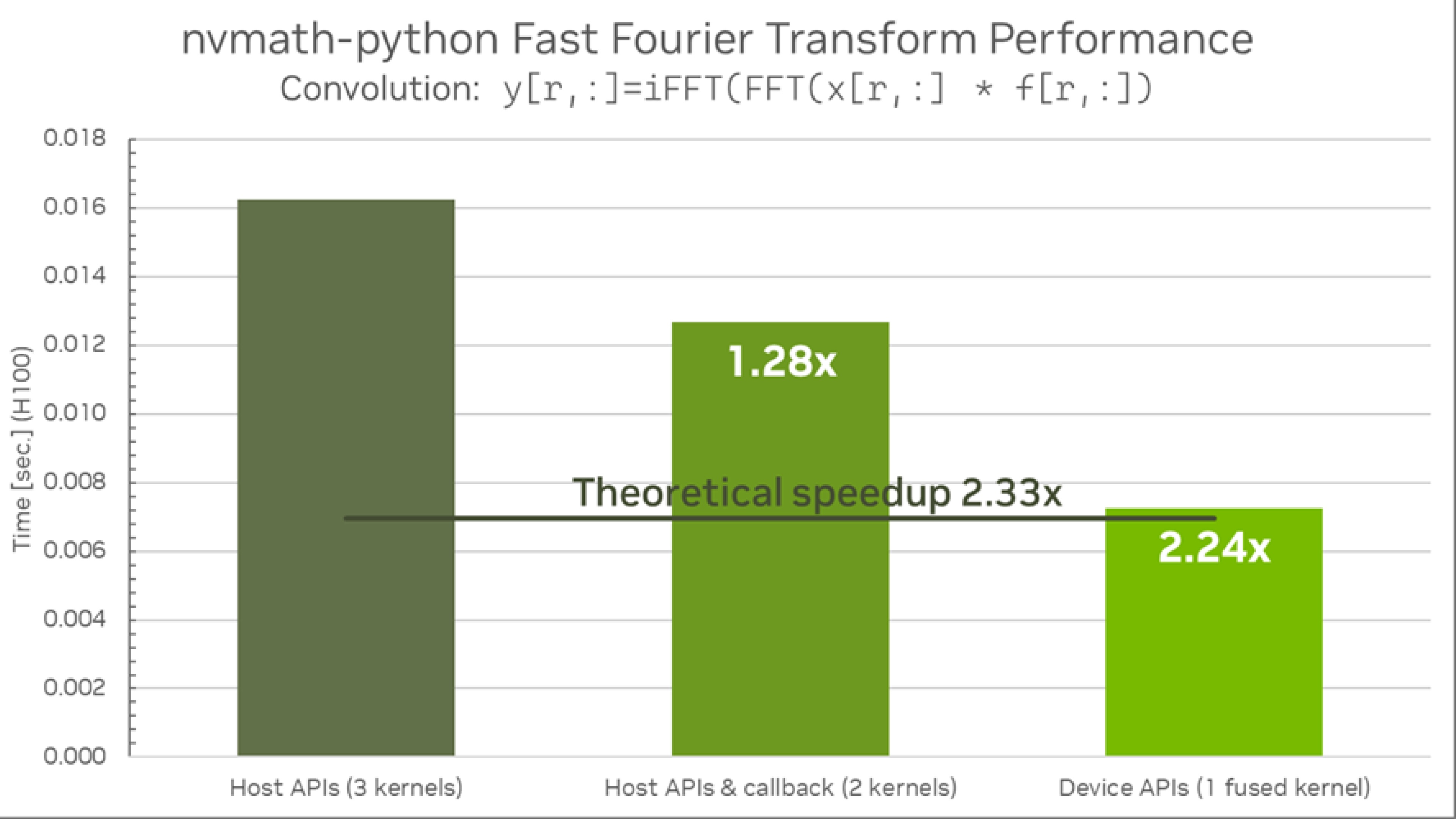
Device API 位于nvmath.device子模块由 cuFFTDx 库提供。可以从内部使用 numba-cuda 内核。
随机数生成
该库提供了 device API,可用于在使用 numba-cuda 编写的 GPU kernel 内部执行随机数生成。它提供了一系列伪随机数和准随机数位生成器,以及从热门概率分布中进行采样。
文档
教程和示例
Device API 位于 nvmath.device 子模块中,底层由 cuRAND 库提供支持。它们可在 numba-cuda kernel 内使用,用于在 GPU 上高效执行蒙特卡洛模拟。需要注意的是,该库不提供对应的 host API,而是建议使用各自数组库(如 NumPy 和 CuPy)所提供的随机数生成功能。
位 RNG:
MRG32k3a
MTGP 梅森旋转算法 (Merseinne Twister)
XORWOW
Sobol 准随机数生成器
分布式 RNG:
均匀分布
正态分布
对数正态分布
泊松分布
稀疏线性代数 - 直接求解器
该库提供专用 API,用于支持稀疏线性代数计算。当前,该库提供了用于求解线性方程组
𝐀 ⋅ 𝐗 = 𝐁 的专用直接求解器 API,其中 𝐀 是已知的左端(LHS)稀疏矩阵,𝐁 是已知的右端(RHS)向量或形状兼容的矩阵,𝐗 为由求解器给出的未知解。
文档
通用 Host API (未来)
Device API (未来)
分布式 API (即将推出)
教程和示例

资源
开始使用 nvmath-python