
在 LLM 训练中,超大规模多专家模型 (MoE) 的专家并行 (EP) 通信面临巨大挑战。EP 通信本质上属于多对多模式,然而由于其动态性和稀疏性(每个 AI token 仅激活 topk 个专家,而非所有专家),在实现和优化上存在显著困难。
本文详细介绍了高效的 MoE EP 通信解决方案 Hybrid-EP,及其在 NVIDIA Megatron 系列框架的实践,应用于 NVIDIA Quantum InfiniBand 和 NVIDIA Spectrum-X 以太网平台。同时,深入探讨了 Hybrid-EP 在实际模型训练中的有效性。
超大规模 MoE 模型训练的效率挑战
DeepSeek-V3 是新一代大规模细粒度 MoE 模型的代表性实例。此类模型通过“超参数规模稀疏激活”机制,在计算开销与模型性能之间实现有效平衡,但同时也对现有的大模型训练框架提出了严峻挑战。
- 通信效率瓶颈:MoE 模型依赖于并行专家,需频繁进行多对多通信。随着专家数量增加,EP 通信的负担也随之上升。在 DeepSeek-V3 中,若不加以优化,通信时间可能占总训练时间的 50% 以上。
- 负载不平衡:动态路由机制导致部分“热点专家”接收到的 token 数量远超平均水平,而“冷专家”则未被充分利用,造成设备间计算负载不均,进而引发计算资源浪费。在专家总数和活跃专家数量持续增长的精细场景下,这一问题尤为突出。
- 框架适应性挑战:当前的 MoE 模型对并行策略、低精度计算以及动态资源调度提出了更高且更复杂的要求。同时,还需针对性优化,以充分释放 NVIDIA Blackwell、NVIDIA Quantum InfiniBand 和 NVIDIA Spectrum-X 以太网等新一代硬件架构的性能潜力。
MoE 训练框架的优化与通信方案设计
NVIDIA Megatron Core 是一个开源的大型模型训练库,是训练超大规模 MoE 模型的重要基础。其主要优势包括:
- 多维并行策略支持张量并行 (TP)、序列并行、工作流并行 (PP)、MoE 专家并行 (EP),以及其他可灵活组合的并行方法,以适应各类复杂的训练工作负载。
- 资源效率优化方面,集成 FP8 混合精度训练、激活值卸载、分布式优化器和细粒度重新计算功能,有效降低 GPU 显存消耗,全面支持模型训练。同时,内置多种高效运算符(如 MLA、Attention、MLP 等),并提供丰富的融合优化技术与工作流调度策略,显著提升计算性能。
- 针对 MoE 架构,提供高效且可扩展的训练适配能力,全面支持主流 MoE 模型(例如 DeepSeek、Mixtral 和 Qwen)。
Hybrid-EP 如何成为高效的通信优化方案
Hybrid-EP 是新设计的 MoE EP 通信库。它利用 NVIDIA 平台上的硬件与软件进步,在 RDMA-NVLink 混合网络架构中实现接近硬件极限的通信带宽,并显著减少对 GPU 硬件资源的占用。
它在 MoE EP 通信中实现了两个核心运算符:调度,即将注意力运算符的 tokens 输出路由至相应专家;以及合并,即将专家的 tokens 输出路由回注意力运算符。此外,还引入了路由与信息处理支持,以实现完整的 EP 通信。
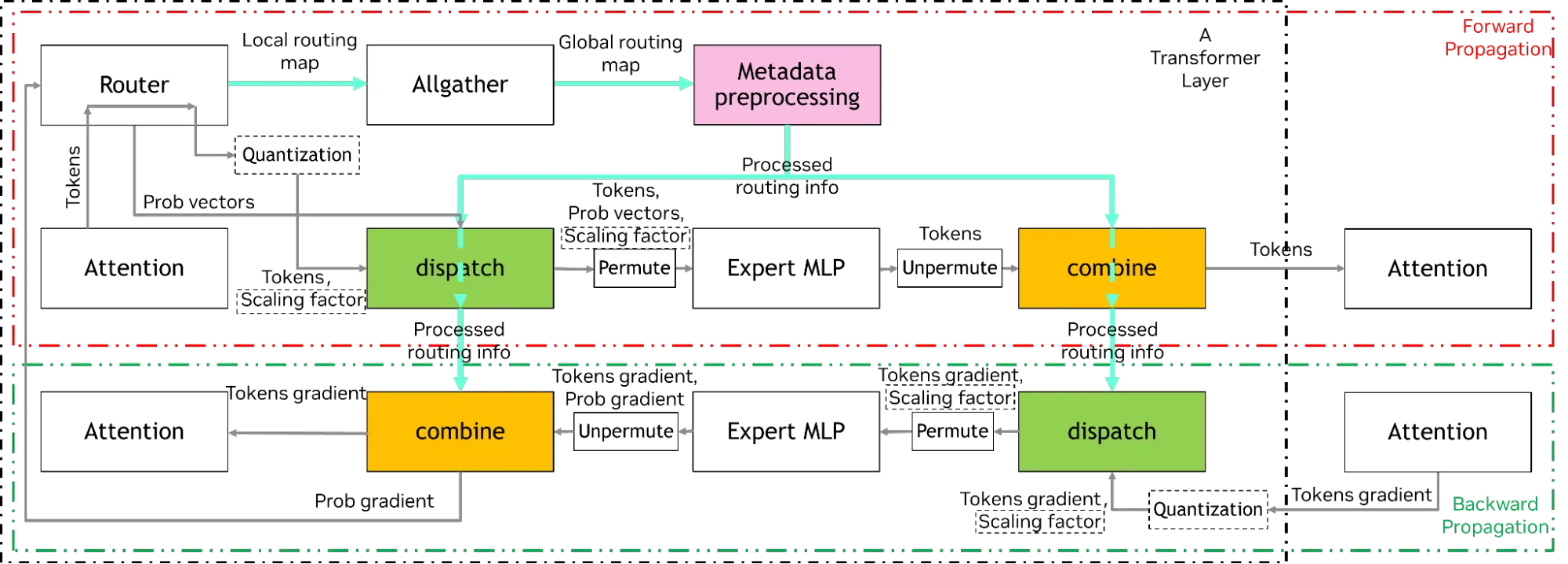
Hybrid-EP 的设计目标和核心优化方向包括利用 NVIDIA 平台上先进的通信技术,例如 NVLink 纵向扩展网络上的数据通信 TMA 命令,以及 RDMA 网络中的底层 IBGDA 网络技术。通过结合节点内的 NVLink 与节点间的 RDMA,实现 RDMA 与 NVLink 的混合网络通信,从而提升算法带宽,最大限度地增强跨域带宽能力。数据工作流将数据划分为细粒度的数据块,并通过多层通信数据流进行流式传输,有效隐藏通信延迟与动态路由开销,使 EP 带宽可媲美高度优化的标准静态多对多通信带宽。
适度减少 GPU 流多处理器 (SM) 使用量,以有效提升通信计算重叠。Hybrid-EP 以较少的 SM 实现峰值通信带宽,从而释放更多 SM 用于计算。为 FP8/ BF16 调度运算符和 BF16 组合运算符提供低精度原生支持。
Hybrid-EP 将每个 CUDA 块设计为独立的数据通道,该通道占用 SM 以执行完整的数据流水线。CUDA 线程块内的不同线程束组可负责不同的工作流阶段。各 CUDA 块并行运行,处理各自的数据块,彼此之间无需同步与通信。
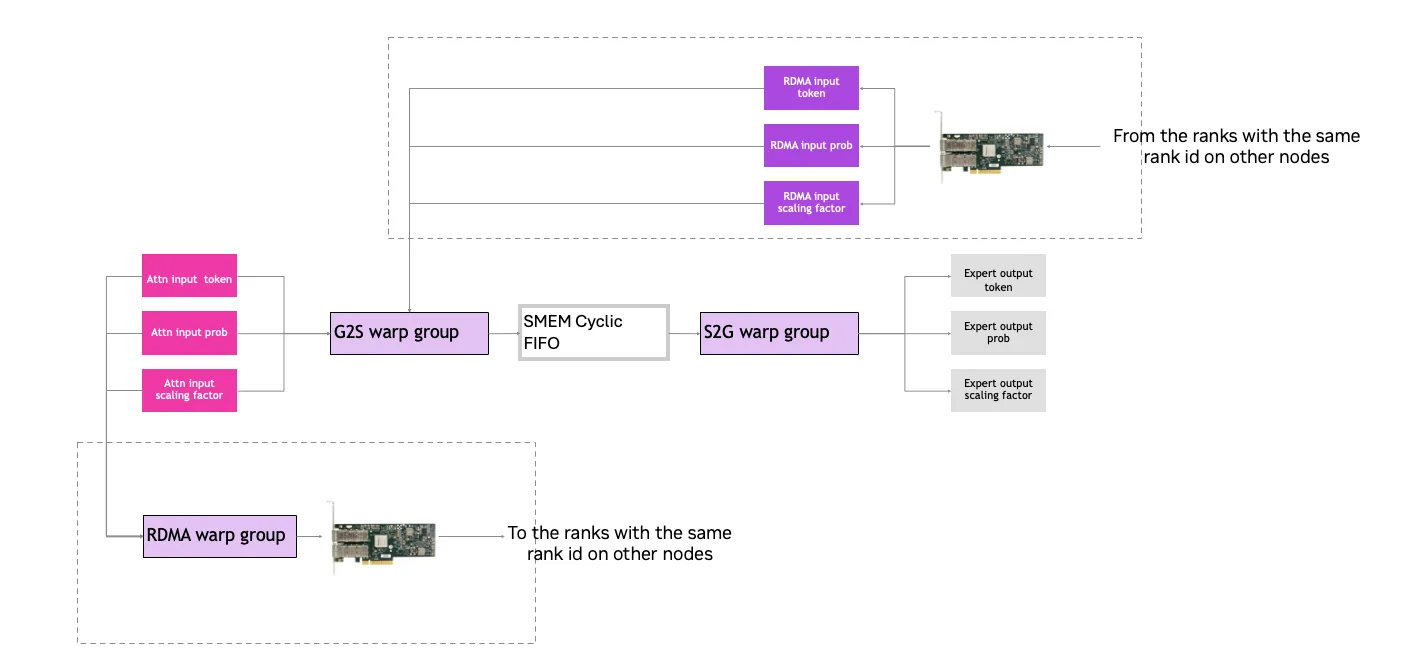
图 2 中的虚线框表示 RDMA 网络通信所采用的工作流阶段。RDMA 线程束组负责利用 IBGDA 技术将网络流量传输至 RDMA 网络接口卡(NIC),以实现网络通信,并完成同一节点内 GPU 之间以及不同节点间(例如各节点上的第 0 个 GPU)的 token 数据传输。
G2S 线程束组负责将 GPU 本地持有的 token 数据以及来自同一条轨道上其他节点 GPU 传输的 token 数据读取至 SM 内的共享内存“先进先出”(FIFO)队列中。S2G 线程束组则负责将共享内存 FIFO 队列中的 token 数据写入该节点所有 GPU(包括自身 GPU)输出缓冲区的对应位置。
在此过程中,tokens 根据路由表中的信息进行路由与传输,以避免传递不必要的token 数据。每个 CUDA 块均通过此数据管道,按分配的顺序处理对应数据块中的 token 数据。不同的 CUDA 块利用相同的数据管道,处理各自不同的数据块。
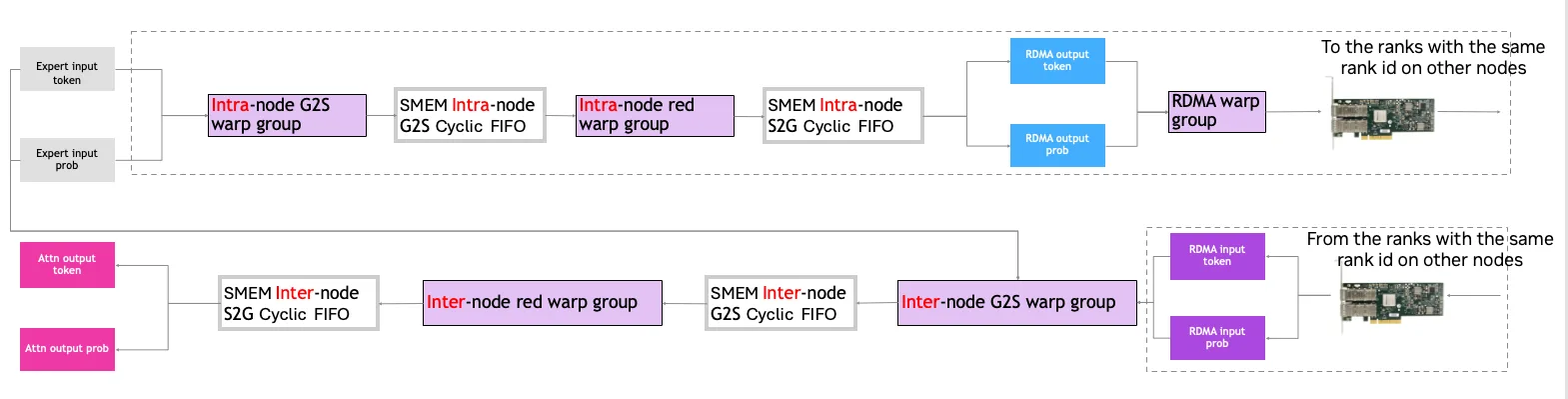
与调度运算符类似,虚帧部分仅用于 RDMA 网络通信。由于组合运算符在 tokens 上执行高精度累积运算,而这些运算目前仅能在 SM 内的 CUDA 核心上完成,因此必须采用分层方式对其进行累积。
在多节点情况下,相关节点内的线程束组首先完成该节点内 token 的部分累加工作,随后 RDMA 线程束组将这些部分累加的 token 发送至节点间同一轨道上的 GPU,最后由节点间相关线程束组完成全局累积,从而获得最终结果。
对于单节点,节点内的累积工作由与节点间相关的线程束组直接完成。在此过程中,相应的 G2S 线程束组会将输入 token 读取至 SM 内的共享内存 G2S FIFO 队列中,随后由对应的归约线程束组在 CUDA 核心中对 tokens 进行累加。计算结果存储于 SM 内的共享内存 S2G FIFO 队列,并交由 TMA 单元写入 GPU 显存。
Hybrid-EP 在多种硬件平台上进行了测试,测试条件如下:
- HIDDEN_DIM 为 8192。
- DATA_TYPE 为 BF16,仅传输 token。
- NUM_OF_ATTN_TOKENS_PER_RANK 为 4096,NUM_OF_EXPERTS_PER_RANK 为 2。
- 路径图根据均匀分布随机生成。
- TOPK 为 8。
- 采用 NVIDIA Quantum InfiniBand 网络。
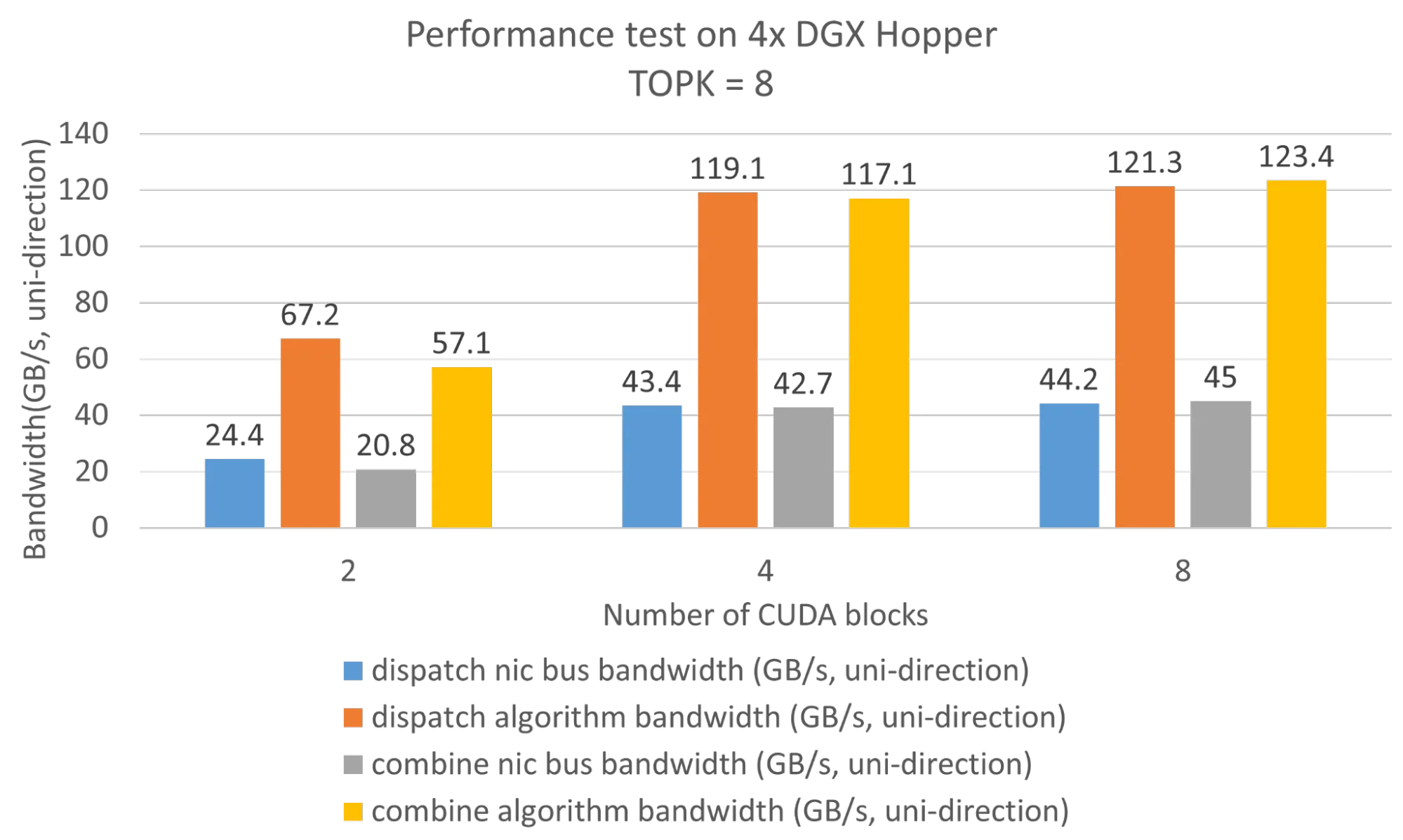
第一次测试在搭载 8 个 H100 GPU 的 NVIDIA DGX Hopper 平台上进行。Hybrid-EP 仅需 8 个 SM 即可占满 NVLink 带宽。
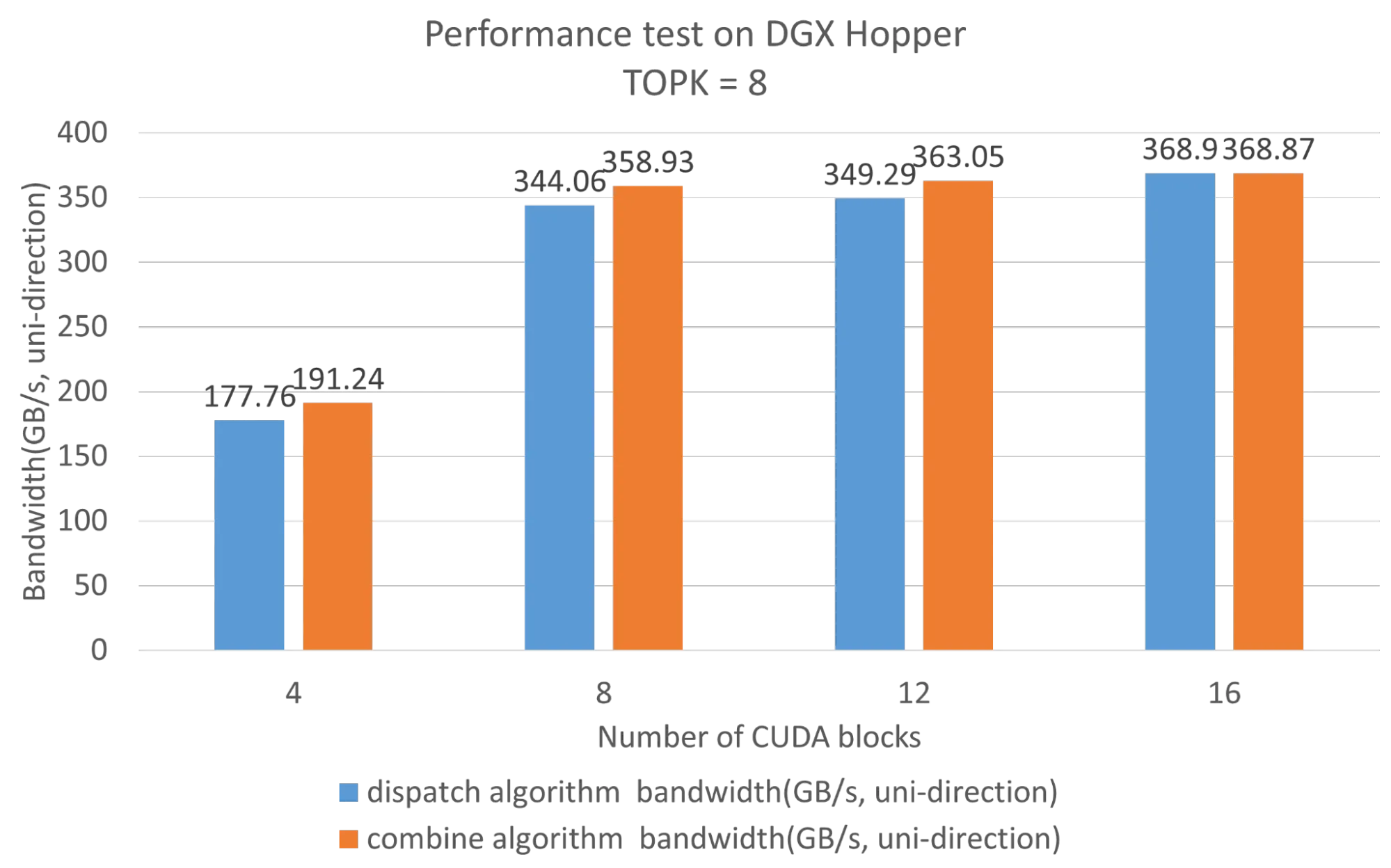
然后,在四个 NVIDIA DGX Hopper 平台上,共对 8 × 4 的 32-GPU 配置进行了测试。每个平台上的四块 DGX H100 GPU 均配备一张 400 Gbps 的 NVIDIA ConnectX-7 网卡,并通过 NVIDIA Quantum InfiniBand 网络互连。
考虑到 Hybrid-EP 采用 NVLink RDMA 混合网络实现分层通信,测试期间统计了两组数据:
- 通过 ConnectX-7 网卡传输的数据量和总通信时间(即网卡总线带宽)来计算 ConnectX-7 网卡实现的实际传输速率。
- 全局带宽在算法层面进行计算,用于衡量调度和组合运算符在混合网络中所占用的带宽,即算法带宽。
混合 EP 仅需大约 4 个 SM 即可接近 NIC 的峰值带宽。
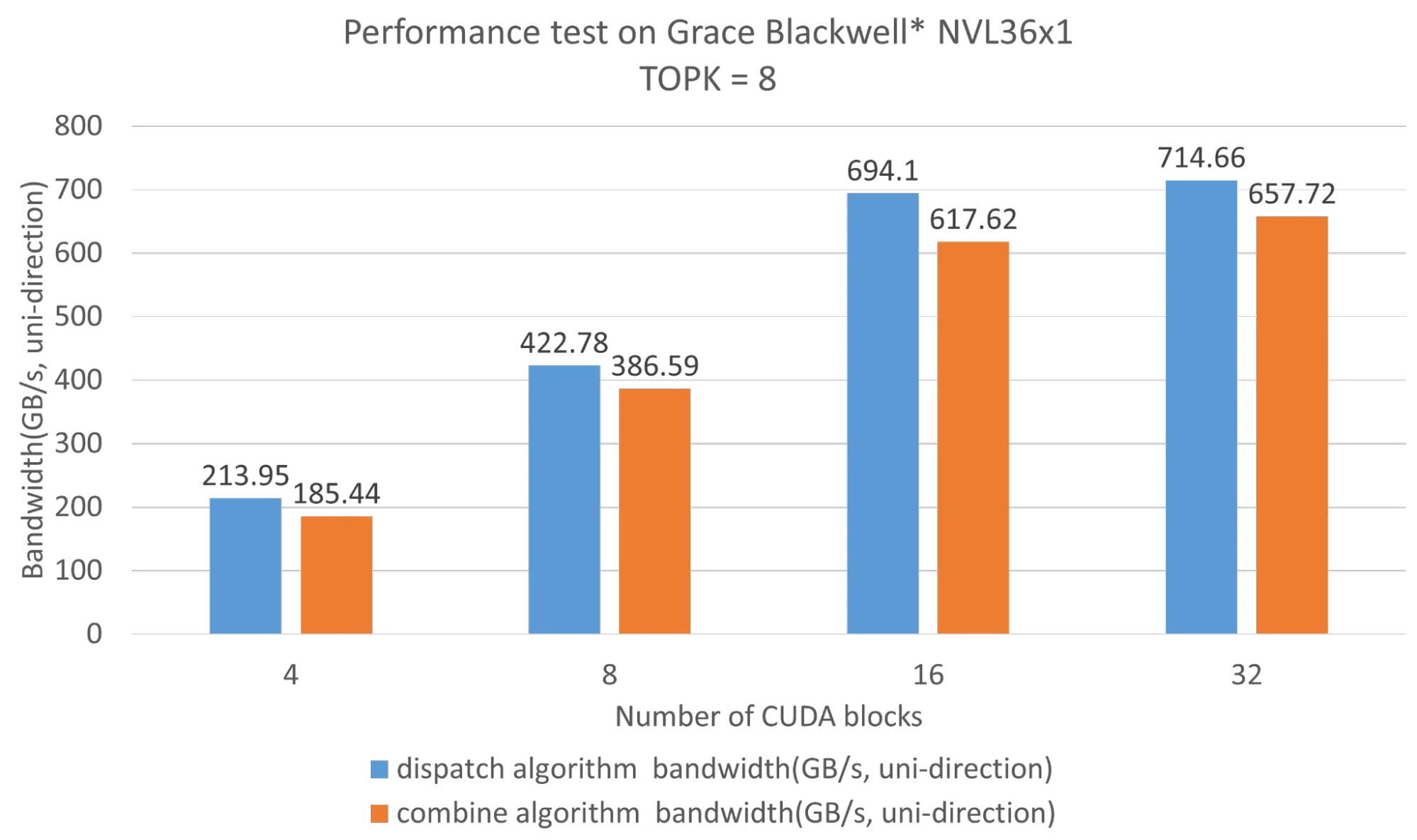
最后,测试了基于 NVIDIA Grace Blackwell 的大规模 NVLink 网络中 Hybrid-EP 的性能。NVLink 域大小采用了 36 个 GPU,即 GB200NVL36。混合 EP 仅需 16 个 SM 即可填满 NVLink 带宽。
实际案例:融合热点模型与硬件落地验证
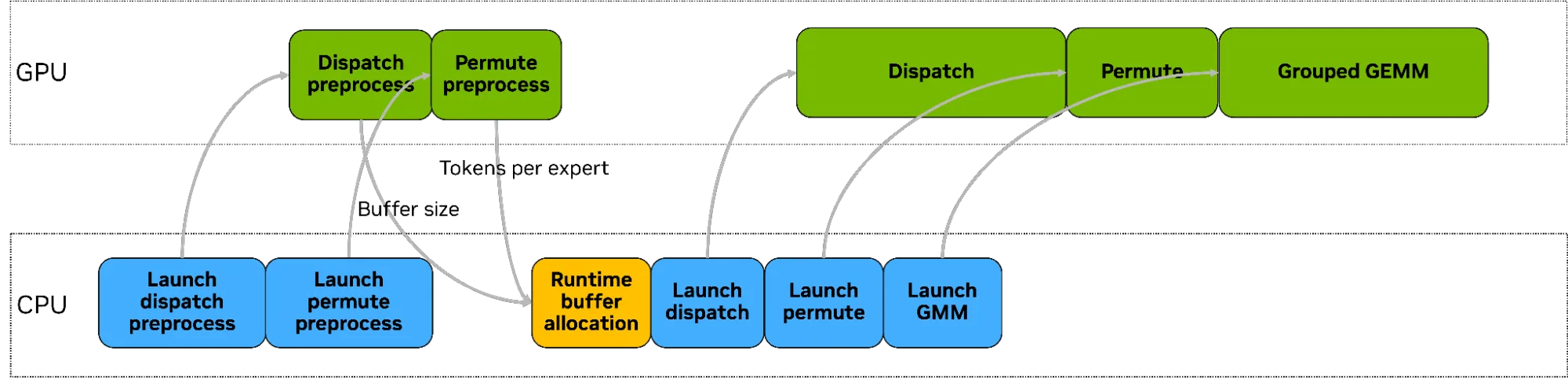
Hybrid-EP 基于包含输入和输出缓冲区地址的模板,并通过 CUDA C 实现。在基于 PyTorch 的 Megatron Core 框架中使用 Hybrid-EP 还需要进行一些额外的集成工作。该功能现已在 DeepEP/Hybrid-EP 分支 中提供,并支持可直接调用的 PyTorch 算子,便于用户快速完成集成与测试。
由于 Hybrid-EP 内核仅接受指针参数且不负责内存管理,因此有必要设计合理的缓冲区管理与分配机制。根据使用场景,混合 EP 缓冲区大致可分为两类:
- 注册缓冲区: 指可由其他 rank 上的内核访问的、经过特殊注册的 GPU 显存。它是唯一的全局静态缓冲区。注册方式取决于具体场景:在跨节点通信中,GPU 内存会被注册为通信内存区域;而在非跨节点通信中,则通过驱动 API 句柄实现,该句柄可被其他 rank 解析。
- 普通缓冲区: 指通过 cudaMalloc 分配的 GPU 显存,可由 PyTorch 的分配器进行管理,通常不具备全局唯一性。
由于缓冲区应用和注册操作非常耗时,理想情况下,这些操作仅在 Python Hybrid-EP 初始化阶段完成。然而,MoE 模型具有动态特性,当前秩在每次迭代中接收到的 tokens 数量各不相同,导致所需的缓冲区大小也随之变化。为此,采用基于极端情况的预分配策略,在较高限度上配置较大的缓冲区,以确保所有 tokens 都能被同一秩接收。由于该缓冲区在全局范围内唯一,GPU 显存的整体使用仍保持可控。



PyTorch 环境 Hybrid-EP 的工作流程如图 10 所示。预处理完成后,Torch 需要 GPU 端的结果以确定后续张量的大小,而 Hybrid-EP 需要在预处理内核中计算缓冲区大小,因此需要进行同步。若主机端预先分配足够大的缓冲区,则可避免此类同步。
Grace Blackwell 的优化实践
Megatron Core 已在 Grace Blackwell 平台上集成 Hybrid-EP,可针对不同类型的 MoE 模型进行优化。
| 模型 | Precision | Dispatcher | TFLOPS/GPU | Speedup |
| DeepSeek-V3 | MXFP8 | Hybrid-EP | 943 | 1.14x |
| MXFP8 | Hybrid-EP | 943 | 1.14x | |
| DeepSeek-V3-FSDP | MXFP8 | A2A | 597 | 1x |
| MXFP8 | Hybrid-EP | 645 | 1.08x | |
| Qwen 3 235B | BF16 | A2A | 665 | 1x |
| BF18 | Hybrid-EP | 698 | 1.05x | |
| MXFP8 | A2A | 728 | 1x | |
| MXFP8 | Hybrid-EP | 800 | 1.10x |
结果包括:
- DeepSeek-V3 在 256 位专家、topk-8 场景下,采用混合 EP 可在不引入 MTP 的情况下实现相较 DeepEP 约 14% 的性能提升。
- 结合 Megatron-FSDP 与混合 EP,仍可进一步实现约 8% 的性能提升
- 在 Qwen 3 235B 场景中,BF16 下性能提升 5.5%,MXFP8 下性能提升约 9.9%。
- 结合 Megatron-FSDP 与混合 EP,仍可进一步实现约 8% 的性能提升
详细了解 NVIDIA 如何实现 10 倍性能提升与十分之一成本的 MoE 模型部署。




