机器人操控系统在进入动态现实环境时,难以应对持续变化的物体、光照条件及接触动力学。此外,仿真与现实之间的差距,以及未经过优化的抓手或工具,通常限制了机器人在多样化任务中的泛化能力、长视距任务的执行能力,以及实现类人灵巧操作的可靠性。
本期 NVIDIA 机器人研发摘要 (R²D²) 探讨了提升机器人操作技能的新方法。在本博客中,我们将介绍三项研究工作:利用推理大语言模型、仿真与现实协同训练,以及视觉语言模型来设计操作工具。
我们还将介绍如何利用 Cosmos Cookbook 中的数据增强及其他方法来提升机器人操作性能。该指南是一项开源资源,汇集了 NVIDIA Cosmos 在机器人与自动驾驶领域中的实际应用案例。
借助 ThinkAct 提升机器人推理与动作执行能力
在机器人开发中,视觉语言动作(VLA)模型能够根据视觉信息和自然语言等多模态指令生成相应的机器人动作。一个高效的 VLA 模型应具备理解并执行动态环境中复杂多步骤操作的能力。然而,当前的机器人操作方法通常采用端到端的方式训练 VLA,无需显式的推理过程。这种方式使得模型在规划长距离任务时面临挑战,也难以灵活适应多样化的任务和环境。
ThinkAct 通过在双系统框架中整合高级推理与低层动作执行,以缩小这一差距。该“先思考后行动”的框架由强化的视觉潜在规划实现。
首先,多模态大语言模型(MLLM)经过训练,能够生成供机器人遵循的推理计划。这些计划通过强化学习生成,其中视觉奖励机制促使 MLLM 制定出符合物理规律的执行路径,以实现目标任务。为此,ThinkAct 利用人类与机器人操作的视频数据,实现基于视觉观察的推理。这种训练方式确保了机器人所生成的规划不仅在理论上合理,还能根据实际视觉反馈在物理环境中切实可行。这一过程构成了“思考”部分。
现在进入“行动”部分。推理过程中的中间步骤被压缩为一条紧凑的潜在轨迹。该表征包含计划中的核心意图与上下文信息。随后,潜在轨迹引导一个独立的动作模型,使机器人能够在不同环境中执行相应动作。通过这种方式,高层推理得以指导并优化现实场景中的底层机器人行为。


ThinkAct 已通过机器人操作和具身推理基准测试。在具身 AI 任务中,它成功实现了少样本部署、长视距操作以及自校正功能。
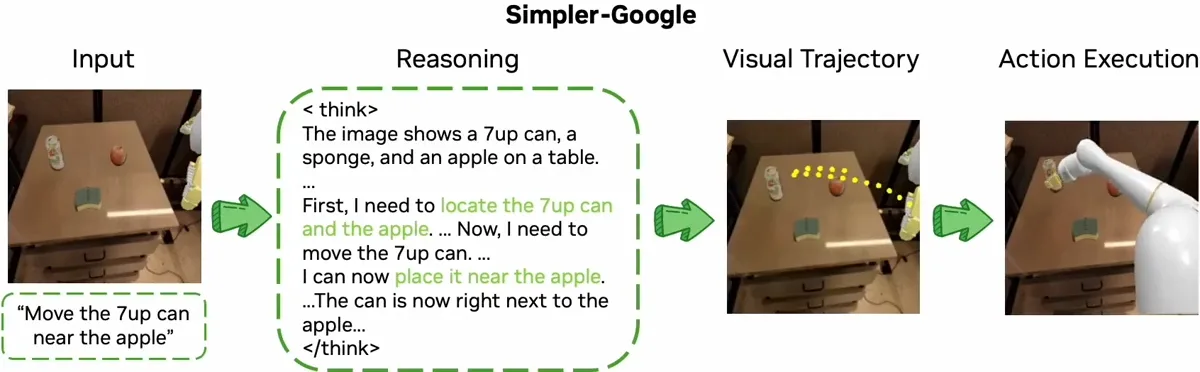
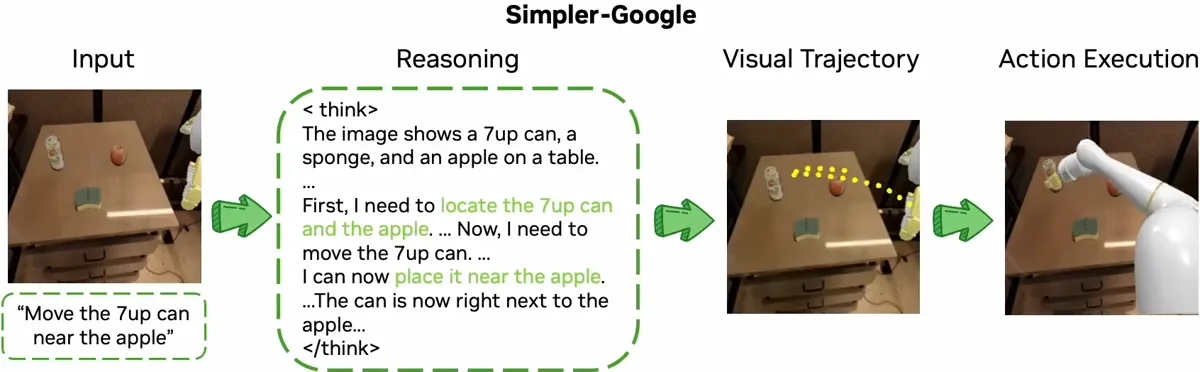
使用 Sim-and-Real 策略进行联合训练
训练机器人执行操作任务需要在不同任务、环境和对象配置之间收集数据。一种常用的方法是行为克隆,即在现实世界中采集专家演示。理论上,这种方法具有可行性,但实际应用中成本较高,难以大规模扩展。现实世界的数据采集依赖人工操作员手动提供演示或监控机器人运行,过程耗时且受限于机器人硬件的可用性。
一种解决方案是在仿真环境中收集演示,这种方式能够实现自动化和并行化,从而高效便捷地获取大量数据。然而,在模拟数据上训练的策略往往难以有效迁移到现实场景中,其根本原因在于仿真与现实之间存在差距:仿真系统无法完全复现真实世界中物理特性、动力学行为、噪声干扰以及反馈机制的复杂性。
仿真和现实策略协同训练通过结合仿真环境与少量真实世界演示,学习通用的操作策略,从而弥合仿真与现实之间的差距。该方法构建了一个统一的仿真与现实协同训练框架,旨在学习一个共享的潜在空间,使仿真观察结果与真实世界数据实现对齐。该框架基于仿真与现实协同训练的相关研究,并采用了更具表达能力的表示空间。这种表示方式不仅提升了对齐效果,还能够捕捉与动作相关的信息。其核心思想是使观察结果与其对应的动作保持一致,从而使策略能够在仿真和真实环境中均有效运行。
这些表征是通过一种称为最优传输 (OT) 的技术来学习的。OT 能帮助策略识别仿真与真实世界数据中的相似模式,确保无论输入来自模拟还是真实环境,用于选择操作的关键信息保持一致。由于模拟数据通常远多于真实数据,因此可通过扩展至非平衡 OT (UOT) 框架来应对这种数据不均衡问题。UOT 采用特定的采样方法,即使在数据集规模差异较大的情况下,也能使训练过程更加高效。
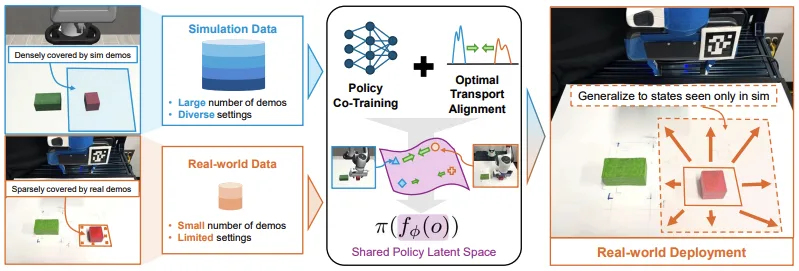
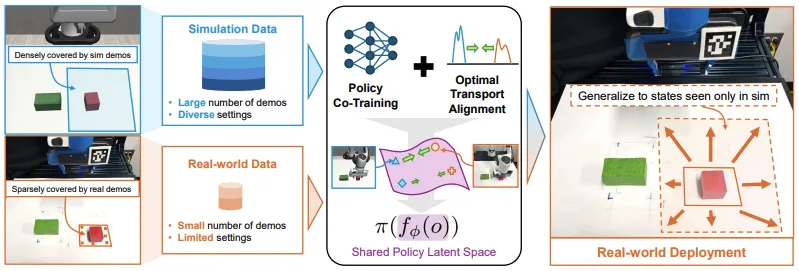
使用此框架训练的策略能够成功泛化至现实场景,即使这些场景仅在训练数据的模拟部分中出现。在提升、堆叠立方体以及将箱子放入垃圾桶等机器人操作任务中,对该方法的仿真到仿真及仿真到现实的迁移能力进行了评估。


使用 RobotSmith 改进机器人工具设计
多数机器人操作任务涉及使用不同的工具和物体。使用工具是机器人与环境交互并执行复杂操作的关键功能。然而,为人类设计的工具因具有多样且复杂的外形尺寸,导致机器人难以有效操作。当前的机器人工具设计方法通常依赖不可定制的预定义模板,或采用未针对此目的优化的3D生成技术。
RobotSmith 通过提供一种利用视觉语言模型(VLM)的自动工具设计框架来应对这一挑战。VLM 擅长推理 3D 空间与物理交互,同时能够理解在包含不同对象的环境中机器人可执行的动作。这些关键能力使其在高效的工具设计中发挥重要作用。
RobotSmith 将视觉语言模型(VLM)中的先验知识与仿真环境中的联合优化过程相结合,以生成面向特定任务的工具。其三大核心组件为:
- Critic Tool Designer:两个 VLM 智能体协作生成候选工具几何图形。
- 工具使用规划器:依据设计的工具与场景生成操作轨迹,并在模拟中执行和评估候选轨迹及抓取效果。
- “Joint Optimizer” (联合优化器):在仿真中联合微调工具几何图形与轨迹参数,以尽可能提升性能。此过程对剔除可能导致任务失败的次优工具与轨迹组合至关重要。
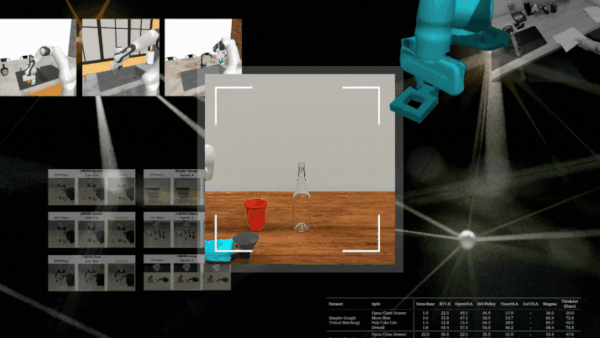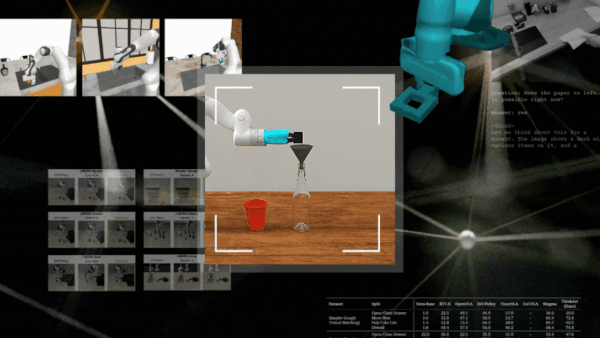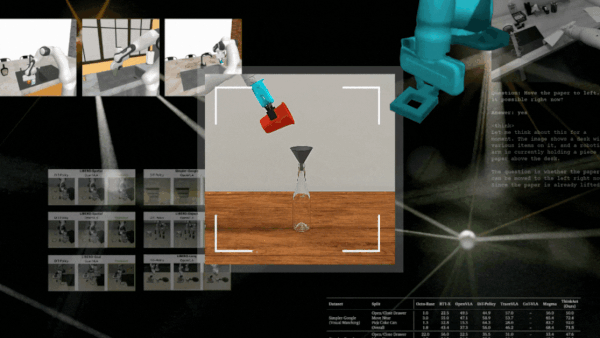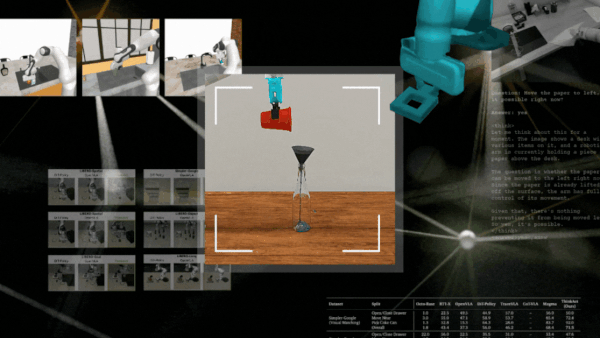
RobotSmith 以这种方式为推送、扫描或封闭等任务生成不同的工具设计方案。


在仿真环境和现实世界任务中对 RobotSmith 进行了评估,完整的实验与结果详见论文。制作煎饼作为一项实际测试任务,框架针对每个步骤(例如压平和抹面)设计并使用了不同的工具,表明该框架能够成功执行长距离任务。


通过 NVIDIA Cosmos Cookbook 缩小仿真与现实之间的差距
在本博客前面,我们探讨了仿真与现实之间的差距,并介绍了如何利用合成数据训练机器人策略。逼真且多样化的合成数据集能够生成可靠的策略,使其更好地适应现实世界。NVIDIA Cosmos 开放世界基础模型(WFM),特别是其中的 Cosmos Transfer,能够通过单次模拟生成逼真且多样化数据,从而扩展合成数据集。完整的流程可在Robotics Domain Adaption Gallery(机器人领域自适应图库)的示例中找到。
除了此工作流之外,NVIDIA Cosmos Cookbook 还提供了分步指导和后训练脚本,帮助快速构建、定制和部署适用于机器人、自主系统及代理式系统的 Cosmos WFM。内容深入探讨了以下示例与概念:
- 快速启动推理示例以实现快速部署与运行。
- 高级后训练工作流程,支持特定领域的精细微调。
- 经过验证的可扩展、生产就绪的部署方案。
- 涵盖基础主题、核心技术、架构模式及工具文档的核心概念。
Cosmos Cookbook 是物理 AI 社区分享 Cosmos WFM 实践知识的资源平台。我们欢迎各方通过 GitHub 贡献内容,包括工作流、方法、优秀实践以及针对特定领域的调整方案。
入门指南
在本博客中,我们探讨了提升机器人操作能力的新工作流程。我们展示了 ThinkAct 如何通过“先思考后行动”的框架,对机器人动作进行推理与执行。接着,我们讨论了如何在通用操作策略的训练中结合使用模拟与真实数据。我们还分享了 RobotSmith 如何生成机器人工具设计,以优化完成复杂任务时的工具使用效率。最后,我们介绍了 Cosmos Cookbook 如何借助 Cosmos 模型,为物理 AI项目提供示例和共享空间。
查看以下资源,深入了解本博客中讨论的工作:
NVIDIA 研究团队在 NeurIPS 2025 上发表了多篇论文,涵盖 ThinkAct、Generalizable Domain Adaptation 和 RobotSmith 等研究方向。
本文是 NVIDIA 机器人研发摘要 (R2D2) 的一部分,旨在帮助开发者深入了解 NVIDIA Research 在物理 AI 与机器人应用领域的最新突破。
致谢
感谢 Ajay Mandlekar、Bohan Wang、Caelan Garrett、Chi-Pin Huang、Chuang Gan、Chunru Lin、Danfei Xu、Dieter Fox、Fu-En Yang、Haotian Yuan、Liqian Ma、Min-Hung Chen、Minghao Guo、Shuo Cheng、Tsun-Hsuan Wang、Xiaowen Qiu、Yashraj Narang、Yian Wang、Yu-Chiang Frank Wang、Yueh-Hua Wu 和 Zhenyang Chen 为本文所述研究做出的贡献。




