
C++ 模板库 CUB 提供了高性能 GPU 基元算法,但其将内存估计与分配分离的传统“两阶段”API 可能带来使用上的不便。尽管这种编程模型具备灵活性,却常常导致重复且繁琐的样板代码。
本文介绍了从原有 API 迁移到 CUDA 13.1 中引入的 CUB 单调用 API 的转变,该 API 通过在不牺牲性能的前提下管理内部内存,简化了开发流程。
什么是 CUB?
如果您需要在 GPU 上运行标准算法(例如扫描、直方图或排序),CUB 可能是极为高效的选择。作为 NVIDIA CUDA 核心计算库(CCCL) 的主要组件,CUB 旨在简化手动 CUDA 线程管理的复杂性,同时保持卓越性能。
虽然 Thrust 等库为快速原型设计提供了类似于 C++ 标准模板库 (STL) 的高级“主机端”接口,但 CUB 提供的是一组“设备端”基元,使开发者能够将高度优化的算法直接集成到自定义内核中。要了解如何使用 CUB,可参考 NVIDIA DLI 课程使用现代 CUDA C++ 进行加速计算的基础知识。
现有的 CUB 双阶段 API
广泛推荐使用 CUB 来充分发挥 NVIDIA GPU 的全部计算能力。然而,其使用方式存在一定复杂性,可能让人感到并非易事。本节将回顾这些基础机制。
通常假设为简单的单遍执行流程,对函数基元的一次调用即可执行底层算法并随后获取结果。该函数的副作用(例如修改变量或返回结果)预计会在下一个语句中立即显现。
CUB 执行模型偏离了这种常见的单遍模式。调用 CUB 基元分为两个步骤:第一步是计算所需的设备内存大小(首次调用),第二步是显式分配内存,然后执行核函数(第二次调用)。
以下是常规 CUB 调用:
// FIRST CALL: determine temporary storage size
cub::DeviceScan::ExclusiveSum(nullptr, temp_storage_bytes, d_input, d_output, num_items);
// Allocate the required temporary storage
cudaMalloc(&d_temp_storage, temp_storage_bytes);
// SECOND CALL: run the actual scan
cub::DeviceScan::ExclusiveSum(d_temp_storage, temp_storage_bytes, d_input, d_output, num_items);
CUB 接口带来了实际挑战。必须调用基元两次:第一次用于确定所需的临时内存量,第二次则使用已分配的存储来执行实际算法。
传统两阶段 API 的一个显著缺点是,在估计和执行步骤之间,哪些参数必须保持一致并不明确。以上面的代码片段为参考,由于两个阶段的函数签名相同,编程时无法清晰区分哪些参数会影响内部状态,以及哪些参数可以在调用之间发生变化。例如,d_input 和 d_output 参数实际上仅在第二次调用时被使用。
尽管现有设计十分复杂,但其基本目的明确:通过将分配与执行分离,用户可分配一个内存块并多次重用,甚至能在不同算法之间实现共享。
虽然此设计对不可忽略的用户子集很重要,但使用该功能的整体用户群体相对有限。正因如此,许多用户会选择对 CUB 调用进行封装,以隐藏每次使用时所需的两步调用过程。PyTorch 便是一个典型例子,它通过宏将 CUB 调用封装为单次调用,并提供自动内存管理。
以下源代码来自 pytorch/pytorch 的 GitHub 仓库:
// handle the temporary storage and 'twice' calls for cub API
#define CUB_WRAPPER(func, ...) do { \
size_t temp_storage_bytes = 0; \
AT_CUDA_CHECK(func(nullptr, temp_storage_bytes, __VA_ARGS__)); \
auto& caching_allocator = *::c10::cuda::CUDACachingAllocator::get(); \
auto temp_storage = caching_allocator.allocate(temp_storage_bytes); \
AT_CUDA_CHECK(func(temp_storage.get(), temp_storage_bytes, __VA_ARGS__));\
} while (false)
宏的使用也有其自身的缺点,因为它们可能使控制流和参数传递变得模糊,导致代码不透明、难以理解,并显著增加调试的难度。
新的单次调用 CUB API
鉴于包装器在众多产品级代码库中的广泛应用,人们意识到有必要通过引入新的单次调用 API 来扩展 CUB:
// SINGLE CALL: allocation and execution on a single step
cub::DeviceScan::ExclusiveSum(d_input, d_output, num_items);
该示例表明,无需进行显式内存分配。需要注意的是,分配过程仍在后台执行。图 1 显示,单次调用接口(包括临时存储估计、内存分配和算法调用)与双阶段 API 相比,未引入额外开销。
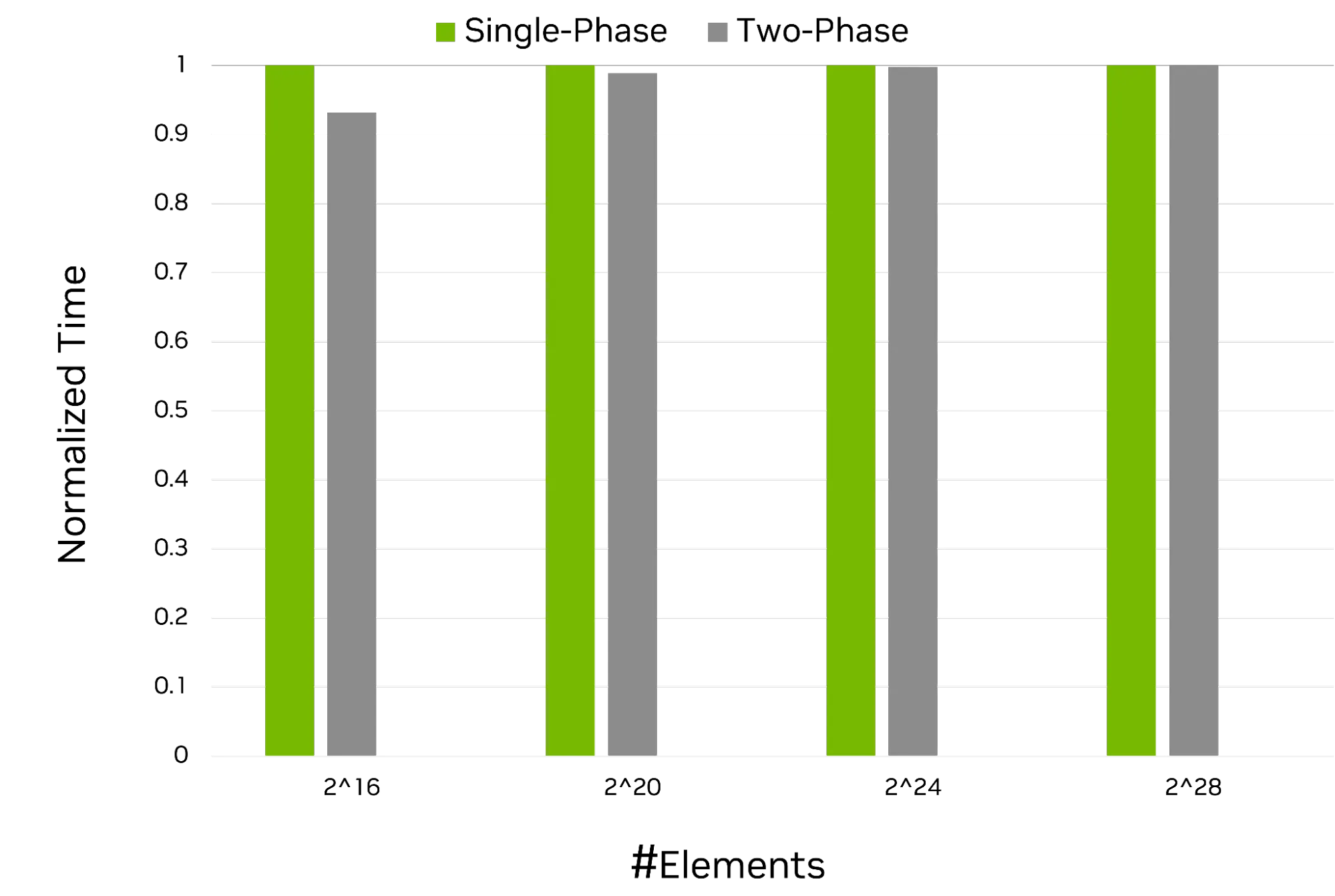
图 1 比较了原始双阶段 ExclusiveSum 调用与新引入的单阶段调用的 GPU 运行时。x 轴表示不同的输入大小,y 轴表示每种调用类型的标准化执行时间。从这些性能数据中可得出两个主要结论:
- 新 API 引入零开销
- 内存分配仍在新 API 下保留;只是转为后台进行
第二点可通过查看新 API 的内部实现来验证:异步分配已嵌入到设备基元中。
cub::DeviceScan::ExclusiveSum(d_input, d_output, num_items, env = {}) {
. . .
d_temp_storage = mr.allocate(stream, bytes);
mr.deallocate(stream, d_temp_storage, bytes);
. . .
}
两阶段 API 尚未删除,这些 API 仍然是现有 CUB API 的有效调用。相反,单阶段调用将被添加到现有 API 之上。预计多数用户会使用这些工具。
环境和内存资源
除了解决前述问题之外,新的单次调用 CUB API 还拓展了调用基元的执行配置功能。它引入了一个环境参数,可用于根据内存资源自定义内存分配,或仅提供待执行的流(例如双阶段 API)。
内存资源是一种用于分配和释放内存的新型内存实用程序。在调用 API 时,可通过环境参数选择性地包含内存资源。若未通过环境参数提供内存资源,API 将使用 CCCL 提供的默认内存资源。此外,您也可选择传递代码库中提供的非默认 CCCL 内存资源,或传入自定义的内存资源。
// Use CCCL-provided memory resource type
cuda::device_memory_pool mr{cuda::devices[0]};
cub::DeviceScan::ExclusiveSum(d_input, d_output, num_items, mr);
// Create and use your custom MR
my_memory_resource my_mr{cuda::experimental::devices[0]};
// Use it with CUB
cub::DeviceScan::ExclusiveSum(d_input, d_output, num_items, my_mr);
使用新 API 时,CUDA 流处理并未被消除,而是被封装在新的 env 变量中。当然,您仍可像以往一样显式传递流,即使温度分配处理已被移除。CUB 现在还提供类型安全的 cuda::stream_ref,应优先采用。此外,您也可以传入持有底层执行流的 cuda::stream。
结合执行选项
单次调用 API 支持的不仅限于将内存资源或流作为最后一个参数。未来,环境参数将成为所有与执行相关控制选项的集中位置,包括确定性要求、保障机制、用户自定义调优等。
随着单通道 API 的推出,CUB 解锁了大量执行配置功能。面对众多新增的执行功能,如何将它们有效组合,成为了一个关键问题。
解决方案在于新的 env 参数。通过利用 cuda::std::execution,CUB 提供了一个中心端点,充当算法的灵活“控制面板”。与严格定义的函数参数不同,该环境允许您自由组合所需的各种特征。无论您是想将自定义流与特定内存池配对,还是将严格的确定性要求与自定义调优策略相结合,env 参数都能在单个类型安全的对象中统一处理。
cuda::stream custom_stream{cuda::device_ref{0}};
auto memory_prop = cuda::std::execution::prop{cuda::mr::get_memory_resource,
cuda::device_default_memory_pool(cuda::device_ref{0})};
auto env = cuda::std::execution::env{custom_stream.get(), memory_prop};
DeviceScan::ExclusiveSum(d_input, d_output, num_items, env);
CUB 目前提供以下支持环境接口的算法,后续还将持续增加更多算法:
- cub::DeviceReduce::Reduce
- cub::DeviceReduce::Sum
- cub::DeviceReduce::Min/ Max/ ArgMin/ ArgMax
- cub::DeviceScan::ExclusiveSum
- cub::DeviceScan::ExclusiveScan
有关基于新环境的过载的最新动态,请参阅 CUB 设备基元的跟踪问题 on the NVIDIA/cccl GitHub 仓库。
开始使用 CUB
通过将冗长的两阶段模式替换为简洁的单次调用接口,CUB 提供了一个现代化的 API,能够在不增加使用复杂度的前提下有效消除冗余代码。借助可扩展的环境参数,您可以获得统一的控制面板,无缝整合内存资源、流及其他功能组件。建议采用这一新标准,以简化代码库并充分释放 GPU 的计算潜力。请下载 CUDA 13.1 或更高版本,立即开始使用这些单次调用 API。




