
对前沿 LLM 进行预训练,可归结为吞吐量。当数千个加速器的训练规模达到数万亿词元时,每一个百分比点的步长时间都会增加数天的训练时间和巨大的计算成本。数值精度是可用的最高利用率旋钮之一,但低位混合精度预训练很难正确。
为了解决这个问题,TransformerEngine 中的 NVFP4 训练方法使用子字节精度进行 JAX 预训练。有关端到端示例,请参阅高性能、可扩展的 LLM 框架库 MaxText 中的 recipe。结果是在 NVIDIA Blackwell 上进行高吞吐量、4 位混合精度预训练,与 FP8 基准相比,没有可测量的准确性损失。
本文将介绍 NVFP4 格式,以及如何在超低精度下实现高性能和高精度。它还展示了如何应用 MaxText NVFP4 预训练方法并收集显示性能提升的性能数据。有关方法的详细信息,请参阅 NVFP4 预训练论文。
NVFP4 格式和优势
这篇 NVFP4 入门博文 解释了其格式,以及二级微缩比如何以比其他微缩比格式更小的误差编码更高的信号。它还解释了 NVIDIA GB300 Grace Blackwell Ultra 超级芯片上 NVFP4 的原生硬件支持如何提供 7 倍于 NVIDIA Hopper 上原生 FP8 精度的 GEMM 吞吐量。这种更高的吞吐量以及 NVFP4 预训练方法可缩短训练步骤时间,而准确性损失可忽略不计。这使得 AI 工厂能够在相同的时间预算内训练越来越大的模型,或者在更短的时间预算内更快地训练模型。
NVFP4 预训练方法
NVFP4 recipe 结合了多个要素,这些要素共同保持收,同时解锁 NVIDIA Blackwell 和 NVIDIA Rubin 平台 NVFP4 吞吐量。为了实现高效的窄精度训练,预训练方法使用了根据性能和准确性选择的几种关键技术。
五个关键要素协同工作,同时保持 4 位预训练所需的准确性:
- 微块缩放使用 16 单元块,而其大小仅为 MXFP4 的 32 单元块的一半,因此单个离群值对共享缩放的影响较小。
- E4M3 块缩放因子使用尾数位,而不是 MXFP4 的双功率 E8M0 缩放,在每张量 FP32 缩放下分层。在 8B 参数、1T 词元实验中,MXFP4 需要增加约 36% 的词元才能匹配 NVFP4 的最终损失。
- 随机阿达玛变换仅适用于 WGRAD GEMM 输入,以对离群值进行高斯化处理。该方法跳过 FPROP 和 DGRAD,因为改变这些路径还需要改变权重,打破 2D 尺度的一致性。
- 2D 权重缩放每 16 × 16 权重块使用一个 FP8 刻度,因此 FPROP 及其转置 DGRAD 使用相同的刻度。激活和梯度保持较低开销的 1 × 16 缩放。
- 随机四舍五入使用无偏差四舍五入来防止微小的更新被压缩到零。权重和激活函数保持四舍五入到最接近的水平,SR 会放大误差。这两种模式都是 Blackwell FP4 转换指令的原生模式。
图 1 显示了一个线性层内的 NVFP4 数据流。
三个 GEMM:FPROP (前向) 、DGRAD (激活梯度) 和 WGRAD (权重梯度) 仅针对 Transformer 的 MLP (前馈) 层量化为 NVFP4;注意力块内的 GEMM ( QKV 投影、注意力输出投影和分数/ 上下文矩阵) 保持更高的精度。
NVFP4 首先应用于 MLP 层,因为注意力的 softmax 会指数级放大 QK+ T 分数上的量化噪声。注意力激活函数还会执行 4 位精度无法很好表示的集中异常值。由于 MLP 占训练 FLOP 的大部分,因此 MLP 可在不影响收的情况下实现大部分加速。
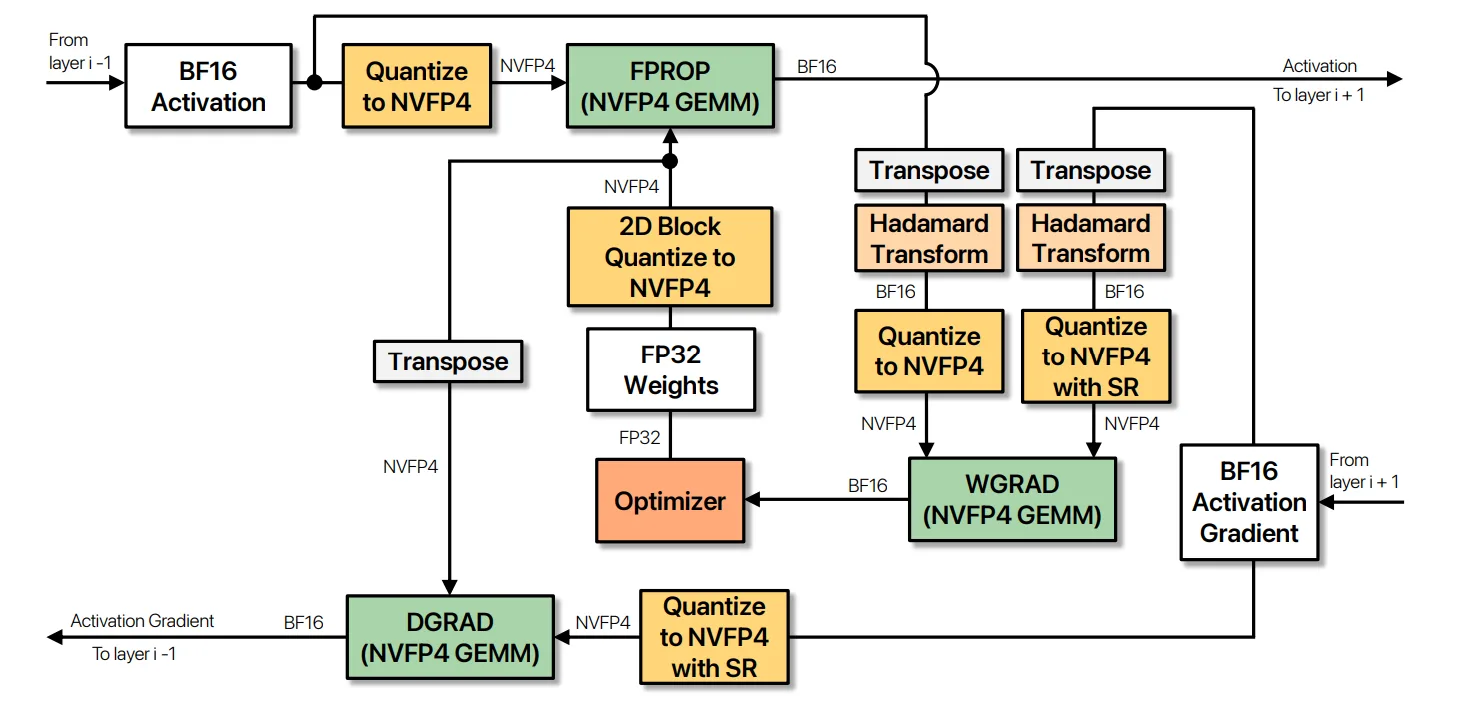
三个 MLP GEMM 均使用 NVFP4 输入并发出 BF16 输出,这些输出最终会在优化器步骤折叠成 FP32 主权重。相同的路径使 recipe 的收和保留选择可见:权重的 2D 块量化 (在转置中一致的 FPROP/ DGRAD 值) ,WGRAD 输入上的随机 Hadamard 变换 (在 4 位量化之前将离群值压平) ,以及梯度量化器上的随机舍入 (保持小的更新无偏) 。
在 MaxText 中启用 NVFP4
MaxText NVFP4 recipe 可在 JAX-Toolbox GitHub 资源库中获取。该启动脚本使用 NVFP4 在 Blackwell 上训练 Llama 3 8B。要启用该功能,请在 MaxText 中设置量化标志,以切换到 NVFP4 路径。显示两种模式:
- quantization=te_nvfp4:采用随机阿达玛变换的 NVFP4。当 te_nvfp4_no_rht 下的收不令人满意时,推荐使用。
- quantization=te_nvfp4_no_rht:无 RHT 的 NVFP4。开销最低,但可能会降低收质量。
在已安装 JAX、NVIDIA Transformer 引擎和所需的 NVIDIA CUDA/cuDNN 库的容器内运行 MaxText 库根中的示例脚本。推荐使用公共 NVIDIA MaxText 容器 ghcr.io/nvidia/jax:maxtext。
以下是 Llama3 8B MaxText NVFP4 训练脚本的部分示例,该脚本通过 Transformer 引擎声明了 nvfp4 参数:
RUN_SETTINGS="-m maxtext.trainers.pre_train.train maxtext/configs/base.yml run_name=debug_run base_output_directory=./debug_logs hardware=gpu dataset_type=synthetic model_name=llama3-8b remat_policy='minimal_with_context_and_quantization' scan_layers=False attention='cudnn_flash_te' steps=50 dtype=bfloat16 max_target_length=8192 per_device_batch_size=4 ici_data_parallelism=${ici_DP} dcn_data_parallelism=${dcn_DP} ici_fsdp_parallelism=${ici_FSDP} dcn_fsdp_parallelism=${dcn_FSDP} profiler=nsys enable_checkpointing=false override_model_config=True gradient_accumulation_steps=1 quantization=te_nvfp4_no_rht max_segments_per_seq=32" |
启动后,MaxText 会打印步长时间、TFLOP/s/device 和词元/s/device。将 NVIDIA Nsight Systems 追踪写入 base_output_directory 进行检查。要生成以下比较中使用的 FP8 基准,请使用 quantization=te_fp8_delayedscaling 运行相同的脚本。
性能结果
该基准测试在 FSDP = 4 的 Llama 3 8B 上使用 MaxText 预训练,序列长度为 8192,每个设备的批量大小为 4,在公共 ghcr.io/nvidia/jax:maxtext 容器内执行 50 步。
表 1 总结了适用于 Llama 3 8B 和 Llama 3.1 405B 的 NVIDIA GB200 Grace Blackwell 超级芯片和 NVIDIA GB300 Grace Blackwell Ultra 超级芯片的 MaxText 预训练性能,并在相同硬件、并行性和全局批量大小下将 NVFP4 配置与 FP8 基准进行了比较。数字以序列长度 8192 测量。
| 模型 | 硬件 | * GPU | FSDP | MBS | GBS | 测序 |
| Llama3 8B | GB200 | 4 | 4 | 4 | 16 | 8,192 |
| Llama3 8B | GB300 | 4 | 4 | 4 | 16 | 8,192 |
| Llama 3.1 405B | GB200 | 128 | 128 | 1 | 128 | 8,192 |
| Llama 3.1 405B | GB300 | 128 | 128 | 1 | 128 | 8,192 |
| 模型 | 硬件 | 每 GPU FP8 TFLOPS | 每个 GPU 的 NVFP4 TFLOPS | 与 FP8 的对比 |
| Llama 3 8B | GB200 | 1497 | 2017 | 1.35% |
| Llama 3 8B | GB300 | 1759 | 2301 | 1.31% |
| Llama 3.1 405B | GB200 | 1557 | 2241 | 1.44% |
| Llama 3.1 405B | GB300 | 2103 | 3633 | 1.73% |
图 2 显示了四种基准配置中 GPU 持续 TFLOP/s 的百分比。NVFP4 可为每个 GPU 的每种配置额外提供 500 – 700 TF/s 的性能。在保持模型、超参数、并行性和全局批量大小相同的同时,更改 GEMM 精度可将 FP8 基准的速度提高 1.31 到 1.73 倍。
最大的相对收益来自 405B 配置 ( GB200 是 1.44 倍,GB300 是 1.73 倍) ,其中每步 GEMM 质量主导了 FSDP 集合开销,而精度+ 级加速直接转化为壁钟节省。
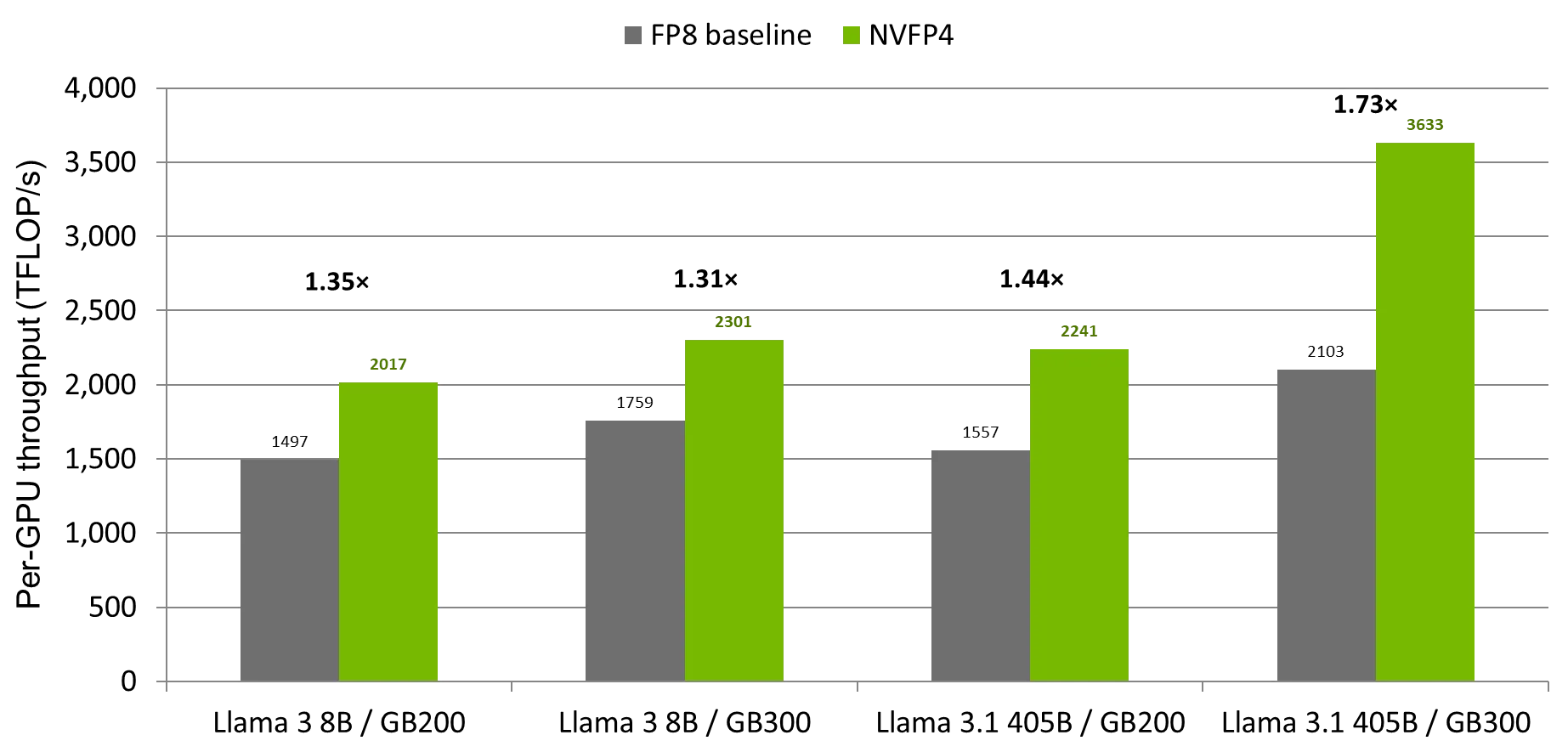
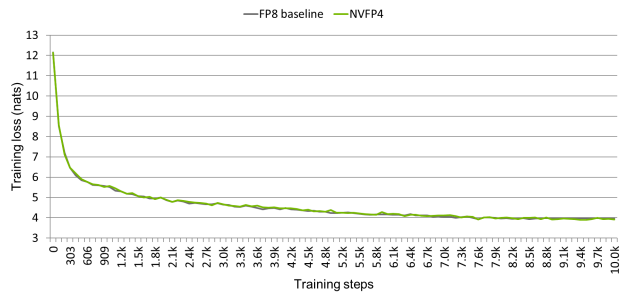
图 3 覆盖了 Llama 3 8B 在 10000 个预训练步骤中的 FP8 基准和 NVFP4 训练损失,其他超参数相同。这两条曲线均从+ 12.2 纳特下降到+ 3.9 纳特,收后的均值差距仅为+ 0.026 纳特,完全位于步长到的噪声范围内。图 2 中的 NVFP4 加速没有可测量的准确性成本。
开始使用
拉取 MaxText 容器,在 Blackwell 上运行 nvfp4_example.sh 即可开始。
致谢
感谢 Jaroslav Sevcik、Ilia Sergachev、Johannes Reifferscheid、Phuong Nguyen 和 Jeremy Berchtold 为 JAX、XLA 和 TE 中的 NVFP4 支持做出的贡献。