
效率在工业制造中至关重要,在工业制造中,即使是微小的收益也会产生重大的财务影响。据美国质量协会称,“许多组织的真正质量相关成本将高达销售收入的 15-20%,有些则高达总运营的 40%.”这些惊人的统计数据揭示了一个严峻的现实:工业应用中的缺陷不仅会损害产品质量,而且会消耗公司收入的很大一部分。
但是,如果公司能够收回这些损失的利润,并将其重新用于创新和扩展呢?这是 AI 潜力的亮点所在。
本文将探讨如何使用 NVIDIA TAO 设计自定义 AI 模型,以找出工业应用中的缺陷,从而提高整体质量。
NVIDIA TAO 工具套件是基于 TensorFlow 和 PyTorch 构建的低代码 AI 工具包。它通过抽象出 AI 模型和深度学习框架的复杂性来简化和加速模型训练过程。借助 TAO 工具套件,开发者可以使用预训练模型,并针对特定用例对其进行微调。
在本文中,我们利用名为 VisualChangeNet 的高级预训练模型进行变化检测,并使用 TAO 工具套件对其进行微调,以检测 MV Tech Anomaly 检测数据集中的缺陷。这个全面的基准测试数据集专为机器视觉中的异常检测而设计,由包含正常和有缺陷样本的各种工业产品组成。
借助 TAO 工具套件,我们使用迁移学习训练模型,该模型在 MVTec Anomaly 数据集的瓶子类上的总体准确度分别为 99.67%、92.3%mIoU、95.8%mF1、97.5 mPrecision 和 94.3%mRecall.图 1 显示了使用经过训练的模型进行的缺陷掩膜预测。

第 1 步:安装前提条件
要遵循帖子并重新创建这些步骤,请执行以下操作。
- 在 NGC 目录中注册帐户,并按照 NGC 提供的步骤生成 API 密钥,详情请参阅用户指南。
- 按照 TAO 快速入门指南设置 TAO 启动器。下载适用于 MVTec 数据集的 VisualChangeNet Segmentation Jupyter Notebook。启动 Jupyter Notebook 并运行此博文中关注的单元。
*请注意,VisualChangeNet 模型仅适用于 5.1 版本。 - 下载并准备 MVTec 异常检测数据集,只需按照下载页面上的提示操作,并复制任意一个 15 个对象类别的下载链接即可。
- 将下载链接粘贴到 Jupyter Notebook 第 2.1 节中的“FIXME”位置,并运行 Notebook 单元。本文重点介绍瓶子对象,但所有 15 个对象都在 Notebook 中运行。图 2 显示了数据集中的样本缺陷图像。
#Download the data
import os
MVTEC_AD_OBJECT_DOWNLOAD_URL = "FIXME"
mvtec_object = MVTEC_AD_OBJECT_DOWNLOAD_URL.split("/")[-1].split(".")[0]
os.environ["URL_DATASET"]=MVTEC_AD_OBJECT_DOWNLOAD_URL
os.environ["MVTEC_OBJECT"]=mvtec_object
!if [ ! -f $HOST_DATA_DIR/$MVTEC_OBJECT.tar.xz ]; then wget $URL_DATASET -O $HOST_DATA_DIR/$MVTEC_OBJECT.tar.xz; else echo "image archive already downloaded"; fi

在 MVTec-AD 中,我们利用 TAO 工具套件,利用 VisualChangeNet 展示工业检测用例的自动光学检测。
Jupyter Notebook 下载数据集后,运行 Notebook 第 2.3 节,将数据集处理为正确的格式,以进行 VisualChangeNet 分割。
import random
import shutil
from PIL import Image
os.environ["HOST_DATA_DIR"] = os.path.join(os.environ["LOCAL_PROJECT_DIR"], "data", "changenet")
formatted_dir = f"formatted_{mvtec_object}_dataset"
DATA_DIR = os.environ["HOST_DATA_DIR"]
os.environ["FORMATTED_DATA_DIR"] = formatted_dir
#setup dataset folders in expected format
formatted_path = os.path.join(DATA_DIR, formatted_dir)
a_dir = os.path.join(formatted_path, "A")
b_dir = os.path.join(formatted_path, "B")
label_dir = os.path.join(formatted_path, "label")
list_dir = os.path.join(formatted_path, "list")
#Create the expected folders
os.makedirs(formatted_path, exist_ok=True)
os.makedirs(a_dir, exist_ok=True)
os.makedirs(b_dir, exist_ok=True)
os.makedirs(label_dir, exist_ok=True)
os.makedirs(list_dir, exist_ok=True)
原始数据集专为异常检测而设计。我们将两者合并以创建包含 283 张图像的组合数据集,然后将其分为 253 张训练集图像和 30 张测试集图像。这两套图像都包含有缺陷的样本。
我们确保测试集包含每个缺陷类别中 30%的缺陷样本,因为`bottle`类主要包含`no-defect`图像,三个缺陷类别中每个类别大约有 20 张图像。

第 2 步:下载 VisualChangeNet 模型
VisualChangeNet 模型是基于 Transformer 的先进变化检测模型。其设计的核心是 Siamese 网络。Siamese 网络是由两个或多个相同的子网络组成的独特的神经网络架构。这些“生”子网络接受不同的输入,但共享相同的参数和权重。在 VisualChangeNet 的上下文中,此架构使模型能够比较当前图像和参考“黄金”图像之间的特征,精确定位变化和变化。这种能力使 Siamese Networks 特别擅长处理图像比较和异常检测等任务。
我们的模型文档提供了更多细节,例如模型架构和训练数据。我们不是从零开始训练模型,而是首先利用在 NV-ImageNet 数据集上进行训练的预训练的 FAN 主干网络。然后,我们使用 TAO 工具套件在 MVTec-AD 数据集上对 Bottle 类进行微调。
运行 Notebook 的第 3 节以安装 NGC 命令行工具,并从 NGC 下载预训练的骨干网络。
# Installing NGC CLI on the local machine.
## Download and install
import os
%env CLI=ngccli_cat_linux.zip
!mkdir -p $HOST_RESULTS_DIR/ngccli
# # Remove any previously existing CLI installations
!rm -rf $HOST_RESULTS_DIR/ngccli/*
!wget "https://ngc.nvidia.com/downloads/$CLI" -P $HOST_RESULTS_DIR/ngccli
!unzip -u "$HOST_RESULTS_DIR/ngccli/$CLI" -d $HOST_RESULTS_DIR/ngccli/
!rm $HOST_RESULTS_DIR/ngccli/*.zip
os.environ["PATH"]="{}/ngccli/ngc-cli:{}".format(os.getenv("HOST_RESULTS_DIR", ""), os.getenv("PATH", ""))
!mkdir -p $HOST_RESULTS_DIR/pretrained
!ngc registry model list nvidia/tao/pretrained_fan_classification_nvimagenet*
!ngc registry model download-version "nvidia/tao/pretrained_fan_classification_nvimagenet:fan_base_hybrid_nvimagenet" --dest $HOST_RESULTS_DIR/pretrained
第 3 步:使用 TAO 工具套件训练模型
在本节中,我们将详细介绍如何使用 TAO 工具套件训练 VisualChangeNet 模型。您可以在工具套件中找到 Visual ChangeNet 模型的详细信息以及受支持的预训练权重 模型卡。您还可以使用预训练的 FAN 主干权重作为微调 VisualChangeNet 的起点,这是我们在 MVTec-AD 数据集上进行微调的起点。
如图 4 所示,训练算法会同时更新所有子网络中的参数。在 TAO 中,Visual ChangeNet 支持将两个图像作为输入 – 一个黄金样本和一个测试样本。目标是检测“黄金或参考”图像与“测试”图像之间的变化。TAO 支持 FAN 作为可视化 ChangeNet 架构的骨干网络。
TAO 支持两种类型的变化检测网络:Visual ChangeNet-Segmentation 和 Visual ChangeNet-Classification.在本文中,我们利用 Visual ChangeNet – Segmentation 模型,通过在 MVTec-AD 数据集中的两个输入图像之间分割更改的像素来演示变化检测。
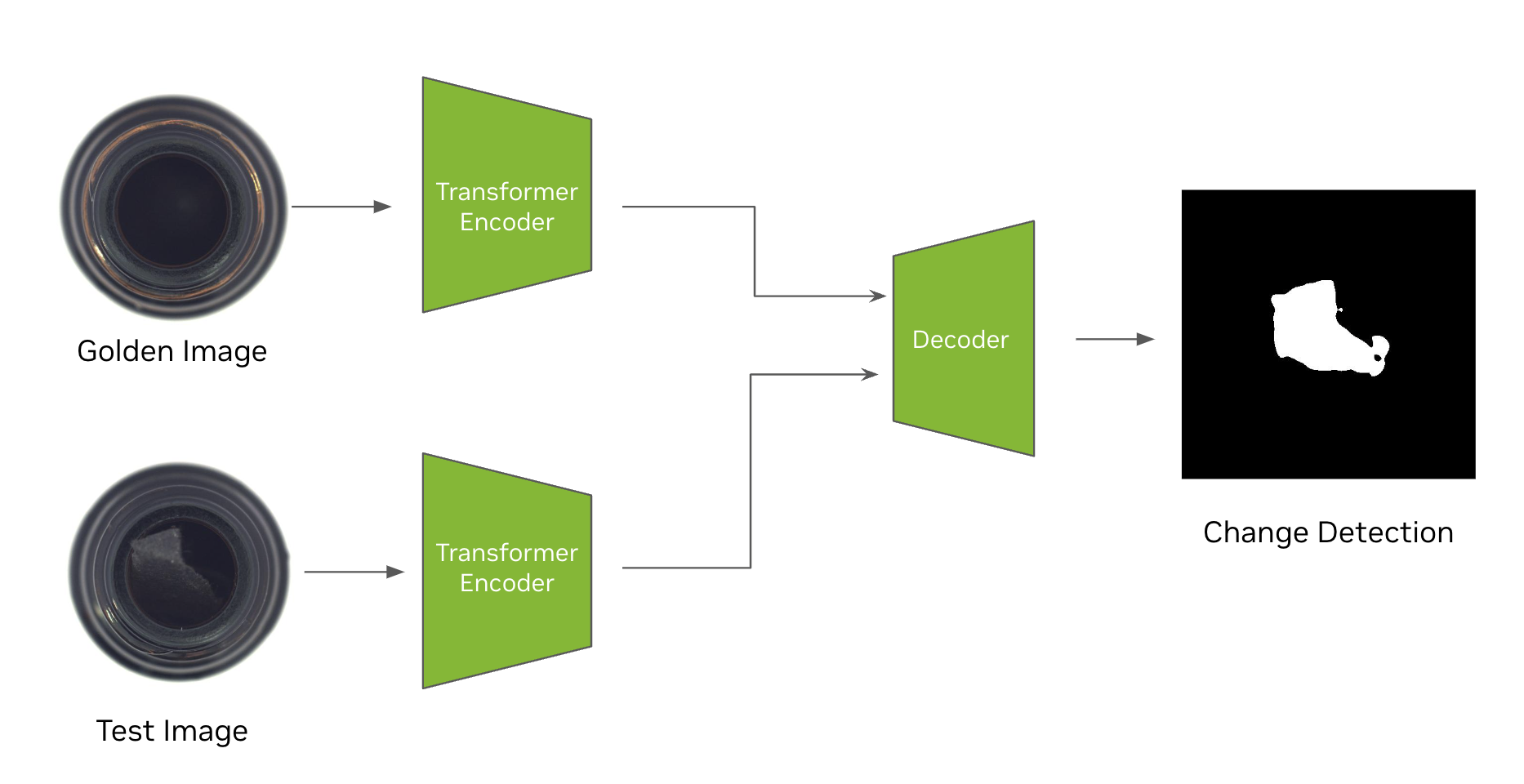
使用 TAO 工具套件可以轻松微调 VisualChangeNet 模型,并且无需任何编码经验。只需在 TAO 工具套件中加载数据,设置实验配置,然后运行 train 命令。
实验配置文件定义了 VisualChangeNet 模型架构、训练和评估的超参数。在 Jupyter Notebook 中,您可以在训练模型之前查看和编辑配置文件。
我们使用此配置来微调 Visual ChangeNet 模型。在配置中,让我们使用预训练的 FAN-Hybrid-Base 主干(即基准模型)定义一个 Visual ChangeNet 模型。让我们使用批量大小为 8 的 30 次迭代来训练模型。下一节演示了部分实验配置,其中显示了一些关键参数。完整的实验配置可在 Jupyter Notebook 中查看。
encryption_key: tlt_encode
task: segment
train:
resume_training_checkpoint_path: null
pretrained_model_path: null
segment:
loss: "ce"
weights: [0.5, 0.5, 0.5, 0.8, 1.0]
num_epochs: 30
num_nodes: 1
val_interval: 1
checkpoint_interval: 1
optim:
lr: 0.0002
optim: "adamw"
policy: "linear"
momentum: 0.9
weight_decay: 0.01
results_dir: "/results"
model:
backbone:
type: "fan_base_16_p4_hybrid"
pretrained_backbone_path: /results/pretrained/pretrained_fan_classification_nvimagenet_vfan_base_hybrid_nvimagenet/fan_base_hybrid_nvimagenet.pth
您可以修改一些常用参数以调整模型的性能,包括训练次数、学习率 (lr)、优化器和预训练的主干网络。若要从头开始训练,可以将 pretrained_backbone_path 设置为 null,但这可能会增加所需的训练次数和实现高准确度所需的数据量。有关实验配置文件中参数的更多信息,请参阅VisualChangeNet 用户指南。
现在,数据集和实验配置已准备就绪,我们开始在 TAO 工具套件中进行训练。运行第 5.1 节中的代码块,使用单个 GPU 启动 Visual ChangeNet 训练。
print("Train model")
!tao model visual_changenet train \
-e $SPECS_DIR/experiment.yaml \
train.num_epochs=$NUM_EPOCHS \
dataset.segment.root_dir=$DATA_DIR \
model.backbone.pretrained_backbone_path=$BACKBONE_PATH
此单元将开始在 MVTec 数据集上训练 Visual ChangeNet Segmentation 模型。在训练期间,该模型将学习如何识别缺陷对象并输出显示缺陷区域的分割掩膜。训练日志(包括验证数据集的准确性、训练损失、学习率和经过训练的模型)保存在实验配置中设置的结果目录中。
第 4 步:评估模型
训练完成后,我们可以使用 TAO 评估验证数据集上的模型。对于 Visual ChangeNet Segmentation,输出是 2 个给定输入图像的分割更改图,表示像素级缺陷。Notebook 的第 6 节将运行该命令来评估模型的性能。
!tao model visual_changenet evaluate \
-e $SPECS_DIR/experiment.yaml \
evaluate.checkpoint=$RESULTS_DIR/train/changenet.pth \
dataset.segment.root_dir=$DATA_DIR
TAO 中的 evaluate 命令将返回验证集上的多个 KPI,例如准确性、精度、召回率、F1 分数和缺陷类(缺陷像素)的 IoU.
OA=更改/不更改像素的总体准确性(输入维度 – 256*256)
MVTec-AD 二进制 CD(Bottle 类)
| 模型 | 骨干网络 | 米精度 | mRecall | mF1 | mIOU | OA |
| VisualChangeNet | FAN-Hybrid-B (预训练) | 97.5% | 94.3% | 95.8 | 92.3 | 99.67% |
第 5 步:部署模型
您可以使用此微调模型,并利用 NVIDIA DeepStream 或 NVIDIA Triton 将其导出为 .onnx 格式。notebook 的第 8 节将介绍如何运行 TAO 导出命令。
!tao model visual_changenet export \
-e $SPECS_DIR/experiment.yaml \
export.checkpoint=$RESULTS_DIR/train/changenet.pth \
export.onnx_file=$RESULTS_DIR/export/changenet.onnx
输出的 .onnx 模型与经过训练的 .pth 模型保存在同一目录中。要部署到 Triton,请查看 tao-toolkit-triton GitHub 上的存储库。此项目提供参考实现,以将许多 TAO 模型(包括 Visual ChangeNet Segmentation)部署到 Triton 推理服务器。
实时推理性能
在提供的未删减模型上以 FP16 精度运行推理。在嵌入式 Jetson Orin GPU 和数据中心 GPU 上使用 trtexec 运行推理性能。Jetson 设备以 Max-N 配置运行,以实现最大 GPU 频率。
运行以下命令以运行 trtexec:
/usr/src/tensorrt/bin/trtexec --onnx=<ONNX path> --minShapes=input0:1x3x512x512,input1:1x3x512x512 --maxShapes=input0:8x3x512x512,input1:8x3x512x512 --optShapes=input0:4x3x512x512,input1:4x3x512x512
--saveEngine=<engine path>
此处显示的性能是纯推理性能。流式传输视频数据的端到端性能可能会因硬件和软件中的其他瓶颈而有所不同。
| 平台 | 批量大小 | FPS |
|---|---|---|
| NVIDIA Jetson Orin Nano 8GB | 16 | 15.19 |
| NVIDIA Jetson Orin NX 16 GB | 16 | 21.92% |
| NVIDIA Jetson AGX Orin 64 GB | 16 | 55.07 |
| NVIDIA A2 Tensor Core GPU | 16 | 36.02 |
| NVIDIA T4 Tensor Core GPU | 16 | 59.7 |
| NVIDIA L4 Tensor Core GPU | 8 | 131.48 |
| NVIDIA A30 Tensor Core GPU | 16 | 204.12 |
| NVIDIA L40 GPU | 8 | 364 |
| NVIDIA A100 Tensor Core GPU | 32 | 435.18 |
| NVIDIA H100 Tensor Core GPU | 32 | 841.68 |
总结
在本文中,我们学习了如何使用 TAO 工具套件微调 VisualChangeNet 模型,并将其用于分割 MVTech 数据集中的缺陷,总体准确率达到 99.67%。
现在,您还可以利用 NVIDIA TAO 检测制造工作流程中的缺陷。
要开始使用,请执行以下操作:
- 从 NVIDIA NGC 目录中下载 VisualChangeNet 模型。
- 按照 TAO 快速入门指南 来设置并启动 TAO 工具包。
- 从以下网址下载 Visual ChangeNet 分割笔记本:GitHub
通过以下链接详细了解 NVIDIA TAO 工具套件:NVIDIA 文档。