
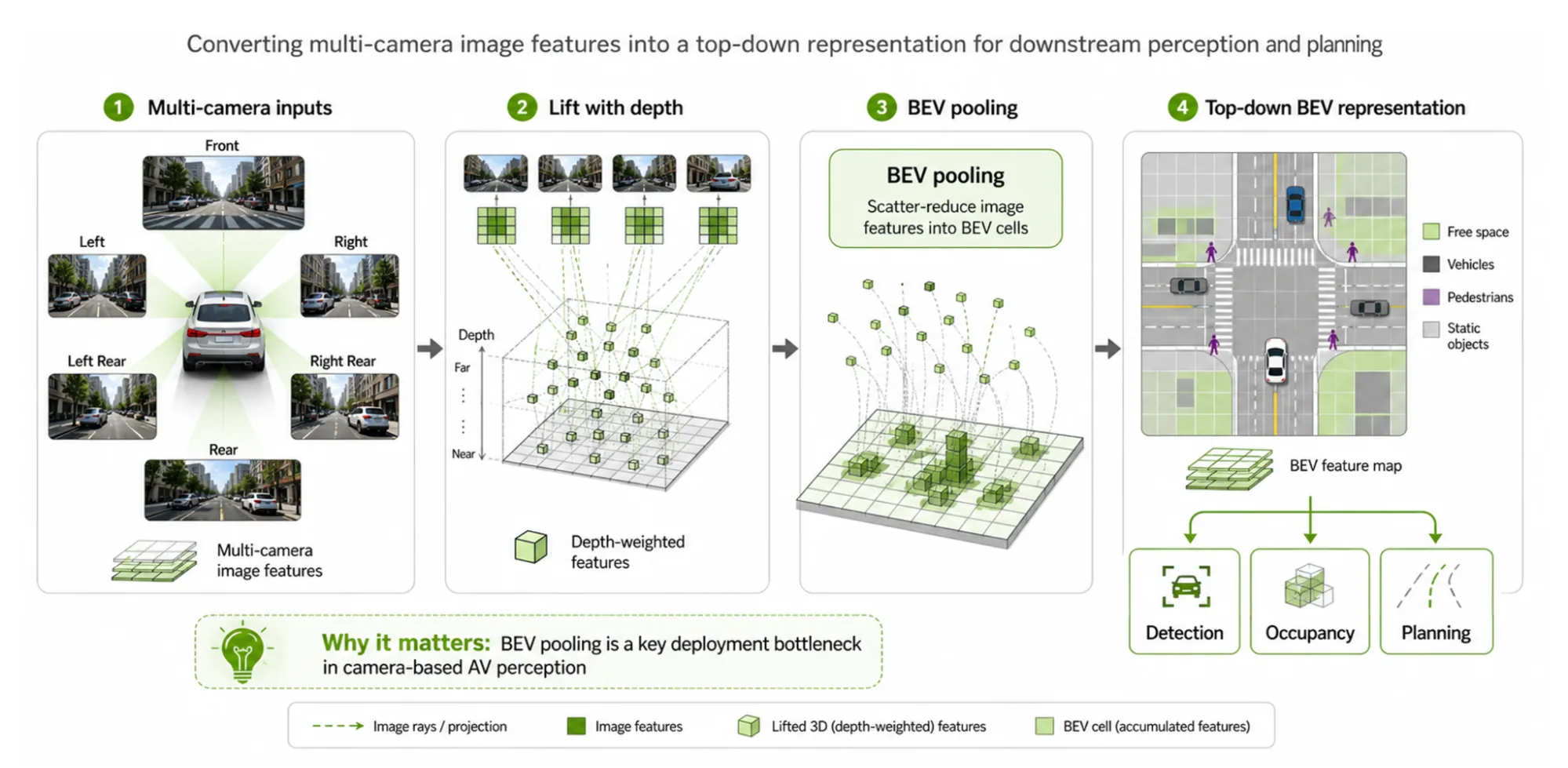
鸟瞰图 (BEV) 感知是智能汽车 (智能汽车) 、机器人和空间 AI 系统日益常见的设计模式。鸟瞰图模型将多摄像头图像特征投射到一个共享的自上而下网格中,为下游感知和规划模块提供通用的空间布局,用于对车道、车辆、行人和自由空间进行推理。
此工作流中的一个关键操作是鸟瞰图池化,该操作可收集图像特征,使用深度信息对其进行加权,然后将其散布至鸟瞰图网格单元中。对于开发者而言,鸟瞰图感知的实际价值在于,它可以将许多特定于摄像头的视图转换为场景的空间一致性表示。下游模块可以在与车辆或机器人周围环境对齐的自上而下的统一特征图上运行,而无需对每个摄像头图像分别进行推理。鸟瞰图池化是使这种表示可实时使用的步骤:它将深度感知的图像特征转换为紧凑型鸟瞰图张量,可以输入检测、占用、轨迹预测、映射和规划工作负载。
从概念上讲,这很简单。然而,在部署中,鸟瞰图池化可能会成为延迟瓶颈,因为它结合了不规则的内存访问、重复的索引读取、散布减少行为和 GPU 特定的缓存效果。
本文以 BEVPoolV3 为案例研究,针对 NVIDIA GPU 优化 BEV 池化和其他收集或散布密集型运算符。它将介绍可应用于工作负载的实际工作流程:对内存机制进行分类、消除冗余散点流量、将内核实现映射到目标 GPU,以及使用 NVIDIA Nsight Compute 验证活动瓶颈。性能结果显示了此工作流程的重要性:根据工作集是否受 DRAM 限制或主要是 L2 驻留,同一 BEV 池化运算符可能需要不同的优化策略。
BEVPoolV3 如何降低 NVIDIA RTX GPU 上的 BEV 池化延迟?
之前的工作已经取得了重要进展。 BEVPoolV2 (本文简称 V2) 为 BEVDet 式模型引入了一种面向部署的高效 BEV 池化公式。 CUDA-BEVFusion 包含 bevpool_half_pack10_kernel,此处称为 V2+DO,它使用外深度遍历来删除 V2 重复的图块外索引加载。
BEVPoolV3 通过其他四项更改延续了这一优化方向:减少重复深度负载、五数组 INT32 散点图、预先计算的消除运行时整数除法的索引,以及区间拥有的输出写入。
本文以 BEVPoolV3 为案例研究,介绍如何针对 NVIDIA GPU 优化 BEV 池化以及其他收集或散布密集型运算符。您将学习如何按内存机制对 BEV 池化工作负载进行分类、识别冗余散点流量、将内核实现映射到目标 GPU,以及如何使用 Nsight Compute 验证活动瓶颈。两个 NVIDIA RTX GPU 上的性能结果显示了此工作流程的重要性:同一个 BEV 池化算法可以在一个 GPU 上受 DRAM 限制,而在另一个 GPU 上主要是 L2 居民,因此需要不同的优化选择。
该评估比较了代表不同显存机制的两个 NVIDIA RTX GPU:NVIDIA RTX A6000,一个是具有 6 MB L2 缓存且无原生 FP8 ISA 的 NVIDIA Ampere SM86 GPU,和 NVIDIA RTX PRO 6000 Blackwell Max-Q 工作站 Edition,一个是具有 128 MB L2 缓存且原生支持 FP8 的 NVIDIA Blackwell SM120 GPU。此处使用的标准配置源自真实的 nuScenes 样本,包含约 209K 散点、80 个特征通道和 49 MB 的 BEV 池化工作集。该工作集超过了 RTX A6000 L2 缓存,但适合 RTX PRO 6000 Blackwell Max-Q L2 缓存,使 RTX A6000 DRAM 受限和 RTX PRO 6000 Blackwell Max-Q 在初始填充后在很大程度上成为 L2 居民。
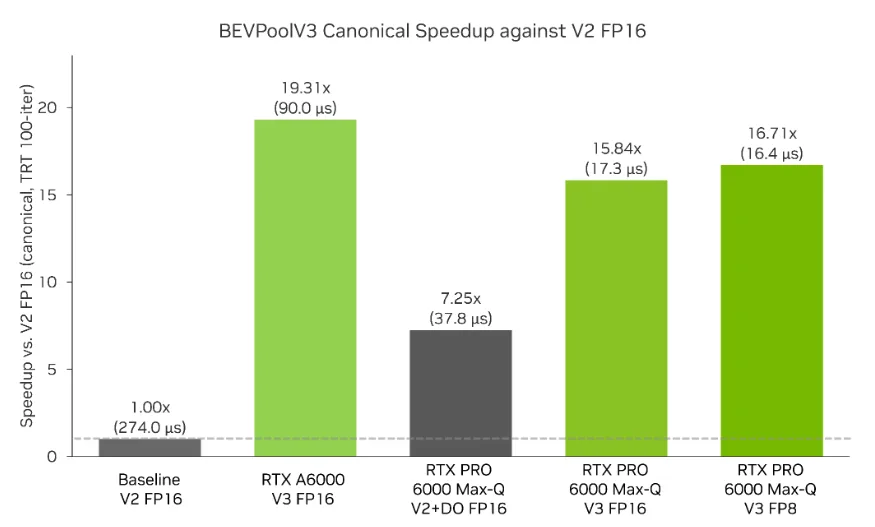
在规范配置中,V2 风格的 NVIDIA TensorRT 插件路径在 RTX PRO Blackwell Max-Q 上需要 174.0 µs。BEVPoolV3 在 FP16 和 FP8 中分别降低至 17.3 µs 和 16.4 µs。在 RTX A6000 上,经 DRAM 调整的 BEVPoolV3 FP16 路径可达到 90.0 µs。除了加速之外,本文还展示了优化散点归约内核的可重复工作流:对工作集进行分类、删除冗余内存流量、将启动形状与目标 GPU 相匹配,并使用 Nsight Compute 验证结果。
预备知识
本文将讨论 CUDA 内核行为、TensorRT 插件集成以及 BEV 池化环境中的 GPU 分析。实用的预备知识包括:
- CUDA 内核概念,例如线程束调度、原子学、矢量化全局负载和 DRAM/ L2/ L1 缓存行为
- TensorRT 插件集成,尤其是 IPluginV3 接口
- 用于验证内存行为、占用率和指令问题瓶颈的 Nsight 计算分析
- CUDA-BEVFusion 中的 BEV 池化核 作为先前的外深度参考实现
有关相关背景信息,请参阅 CUDA C++ 编程指南、TensorRT 插件文档、TensorRT 示例,和 Nsight 计算性能分析指南。
对内存机制进行分类
第一步是对 BEV 池化工作集是否适合 L2 进行分类。在标准配置中,主数组总计约 49 MB,主要由特征数据和输出组成。这个数字决定了显存机制:它大于 RTX A6000 6 MB L2 缓存,但小于 RTX PRO 6000 Blackwell Max-Q 128 MB L2 缓存。

此拟合/ 不拟合决策会更改优化目标。在 RTX A6000 上,特征收集和输出流量溢出超出 L2,因此 Small-L2 路径优先考虑字节缩减和缓存流输出存储。在 RTX PRO 6000 Blackwell Max-Q 上,标准工作集适合 L2,因此 large-L2 路径会转向指令效率、占用率、预先计算的指数、矢量化负载和 FP8 专用化。
消除冗余的分散流量
BEV 散射归约可总结为:
out[ranks_bev[t], c] += depth[ranks_depth[t]] * feat[ranks_feat[t], c];
BEVPoolV2 会在散布循环外部的通道图块上进行迭代。对于 C 80 和 8 通道图块,相同的散点索引会加载 10 次。对于读取一次后只需要 2.51 MB 的索引,这会产生大约 25.1 MB 的索引流量。深度 – 外圈循环顺序通过先迭代每个 BEV 区间,然后在一次传递中累积该区间的所有通道来解决大部分问题。
BEVPoolV3 扩展了 CUDA-BEVFusion bevpool_half_pack10_kernel 中使用的外部深度优化方向,此处称为 V2+ DO。V2+ DO 是一个有用的基准,因为它已经删除了 BEVPoolV2 中重复的平铺外索引负载,并展示了基于区间的遍历值。BEVPoolV3 保持这一方向,并添加了四项实现变更,以提高跨 GPU 显存机制的可移植性和性能:减少每个区间内的重复深度负载;五数组 INT32 散点图,其中包含 ranks_depth、ranks_feat、ranks_bev、interval_starts 和 interval_lengths;预先计算的显式索引,用于消除运行时整数除法;以及区间拥有的输出写入
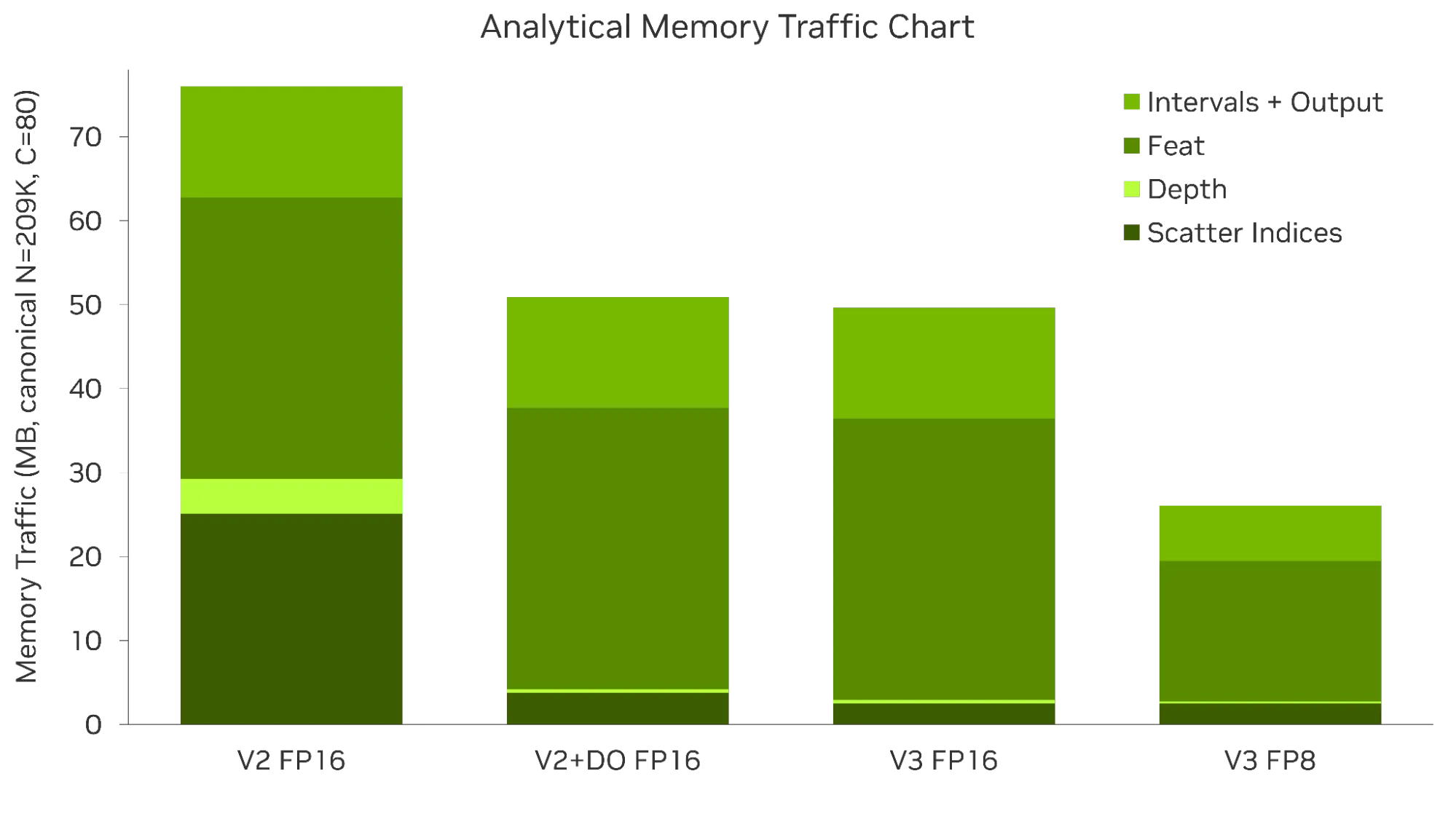
五数组散点图对于大型 L2 GPU 尤为重要。将 (ranks_depth, ranks_feat, ranks_bev) 打包到 int3 数组中,可以得到 12 字节的记录。这种布局不便于对齐内存事务,并且无法清晰地映射到 16 字节的 LDG.128 负载。独立的 INT32 数组可让相邻线程合并对齐的负载,并避免现场合。总逻辑字节可能看起来相似,但指令流要干净得多。
实现区间拥有的散点归约
在生产环境中,BEVPoolV3 使用多个专用内核,但核心实现理念更容易理解为一个小的逻辑草图。提前准备好散点图,将每个 BEV 区间分配给一位所有者,所有者在该区间内行走点,累积相关特征通道,并写入一次输出。
此结构消除了将散点图打包到单个记录时出现的内环解码工作。核函数不是在运行时重建索引,而是读取显式数组,例如 ranks_depth、ranks_feat、ranks_bev、interval_starts 和 interval_lengths。
// 1. Use five precomputed scatter arrays.
// 2. Read explicit indices directly, with no runtime index division.
// 3. Let one interval owner accumulate the output cell.
// 4. Load each depth value once per scatter point in the owner loop.
for each interval iv in parallel:
start = interval_starts[iv]
length = interval_lengths[iv]
bev = ranks_bev[start]
acc[channel_tile] = 0
for offset in 0 .. length - 1:
t = start + offset
d = depth[ranks_depth[t]]
feat_row = ranks_feat[t]
for c in channel_tile:
acc += d * feat[feat_row, c]
out[bev, channel_tile] = acc
此代码草图捕获了常见的 BEVPoolV3 结构:散点图是显式的,运行时索引解码被删除,深度加载在区间所有者循环中,并且在局部累积后写入每个输出单元一次。
生产内核专门为目标内存机制设计这种结构。在 RTX A6000 等小型 L2 GPU 上,该实施优先考虑字节归约、FP16 half2 累加和缓存流输出存储,因此输出张量不会从 L2 中移除有用的索引数据。在大型 L2 GPU (例如 RTX PRO Blackwell Max-Q) 上,该实现首先匹配高占用率启动包络,然后通过预先计算的索引、矢量化索引负载和 FP8 专用内循环 (工作集为 L2 居民) 减少指令开销。
算法不变变量保持不变:拥有区间、避免运行时索引解码、在本地累加,然后写入一次。特定于架构的工作会改变常量的实现方式,而非 BEV 池化运算符的计算方式。
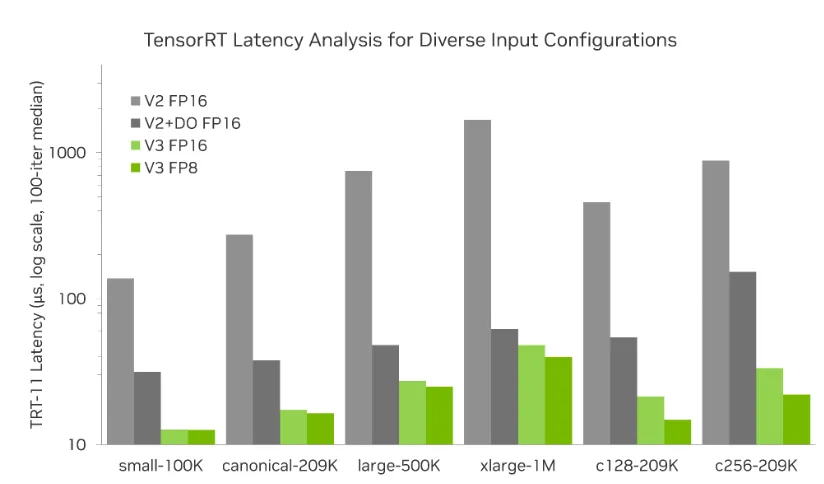
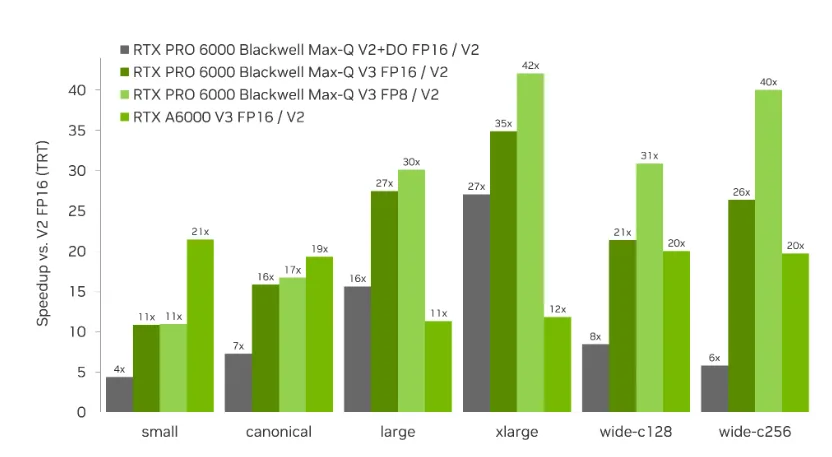
RTX PRO Blackwell Max-Q 的绝对延迟结果显示了 large-L2 路径在不同的点计数和通道宽度下的表现。在 RTX A6000 DRAM 受限路径上,当测量为 V2 FP16 基准加速时,相同的优化模式也同样适用。在 RTX A6000 上,经 DRAM 调整的 V3 FP16 路径在测试配置中的速度比 V2 快 11 到 22 倍。在 RTX PRO 6000 Blackwell Max-Q 上,V3 FP8 的速度比 V2 提高了 11 倍到 42 倍,在更大的点数和更宽的通道配置下,性能提升最大。
部署和验证 TensorRT 插件
BEVPoolV3 作为 TensorRT IPluginV3 运算符公开。该插件接受五数组散点图以及深度和 feat,然后为 GPU 类和 dtype 分配适当的内核。基准测试路径使用 ONNX 到 TensorRT 构建,并使用 trtexec 进行 CUDA 图形回放。
如需验证,请与 FP64 参考或现有可信 V2 路径进行比较。经 RTX A6000 DRAM 调整的内核在 atol=1e-2 下通过了六种配置中所有经过测试的输出元素,最大观察误差为 0.0065。在 RTX PRO 6000 Blackwell Max-Q 上,V2 和 V3 为测试配置生成了相同的输出,这表明经过优化的散点图和启动更改保留了参考路径的数值行为。
将算法映射到硬件上
四个 BEVPoolV3 算法更改是可移植的,但产品级内核必须匹配活动 GPU 瓶颈。关键的决定因素是 BEV 池化工作集是否适合 L2。
在 RTX A6000 上,标准工作集超过 L2,因此内核受到随机收集 DRAM 流量的限制。因此,FP16 路径优先考虑字节归约和缓存保留。将 TILE_C 从 8 增加到 16,可将 C 80 图块从 10 个减少到 5 个,从而减少循环开销和重复标量工作。将 __half2 累加与 __hfma2 结合使用,可避免不必要的 FP16 到 FP32 扩展和打包。缓存流输出存储可防止 12.8 MB 输出张量逐出较小的 L2 – Resident 索引数组。进行这些更改后,在标准配置中,RTX A6000 路径达到 90.0 s,而 V2 FP16 则为 1738.0 s。
在 RTX PRO 6000 Blackwell Max-Q 上,标准工作集适合 L2,因此限制因素转向指令问题、占用和依赖延迟。生产核函数首先匹配高占用率 V2+ DO 式启动包络,然后使用五数组散点图和预先计算的索引消除内环开销。这样可以避免运行时整数除法,并减少散点图负载压力。在标准配置中,V3 FP16 可达到 17.3 s,而 V2+ DO FP16 可达到 37.8 s,在相同的 dtype 下,速度可提升 2.18 倍。
FP8 路径进一步专门用于大型 L2 案例。由于特征和输出数据来自 L2,因此降低其 dtype 可以转化为实际的延迟收益。生产级 FP8 路径使用按通道计数切入点,LDG.64 索引打包适用于 C 80,更广泛的特征加载适用于 C 128 和 C 256。更激进的组合 (例如在填充索引路径顶部添加循环展开) 无法清晰地合成,因为它们增加了寄存器压力并溢出流量。
精度阶梯有一个实际的目标,而我们的 NVFP4 评估有助于明确每种格式的确切亮点:我们测试了 NVFP4 路径,该路径使用每 16 个单元的 E4M3 微块比例在 E2M1 中存储摄像头特征,同时将深度和输出保持在 FP8 中,甚至使用具有 __half2 填充累加器、融合比例深度系数和 ha 的积极优化实现
使用 Nsight Compute 进行分析表明,内核完全驻留在二级缓存中,DRAM 带宽利用率低,smsp__issue_active 悬停在远低于峰值吞吐量的水平,而 ALU 工作流传输的指令远超 FMA 工作流。
这表明,这种散点归约机制已经在 FP8 下获得了可用的字节效率优势,而 NVFP4 额外的每元素字节提取、值解码和每微块缩放折叠引入了内部循环工作,而 FP8 路径通过单个标量 FP8 到一半的转换避免了这种工作。最终实现了清晰的工作负载放置:对于流经 MMA.kind::nvfp4 的 Tensor Core 且受计算限制的矩阵乘法形状,NVFP4 仍然是一种非常强大的拟合,而对于 L2 – Resident 散点归约工作负载,FP8 则是 dtype 阶梯上的理想选择。
同样的分析也适用于 BEV 池化之外的情况。对于稀疏嵌入、体素化、直方图、分段归约和其他收集或散布密集型运算符,请先对内存机制进行分类,然后使用 Nsight Compute 确定活动上限是带宽、指令问题还是占用。
表 1 总结了 RTX PRO 6000 Blackwell Max-Q TensorRT 插件路径延迟,报告为 100 次迭代的中位延迟。
| 配置 | C 维 | V2 FP16 | V2+ DO FP16 | V3 FP16 | V3 FP8 | V3 FP8/ V2 |
| small | 80 | 137.8 微秒 | 31.5 s | 12.7 微秒 | 12.6 s | 10.94 倍 |
| canonical | 80 | 174.0 s | 37.8 微秒 | 17.3 s | 16.4 s | 16.71 倍 |
| large | 80 | 749.9 微秒 | 48.0 s | 27.3 s | 24.9 s | 30.12 倍 |
| xlarge | 80 | 1675.0 s | 61.9 微秒 | 48.0 s | 39.8 微秒 | 42.09 倍 |
| wide_c128 | 128 | 457.3 微秒 | 54.2 s | 21.4 s | 14.8 s | 30.90 倍 |
| wide_c256 | 256 | 880.9 微秒 | 152.3 s | 33.4 s | 22.0 s | 40.04 倍 |
边缘平台注意事项
同样的分析也可以扩展到边缘级 NVIDIA 平台,包括 NVIDIA DRIVE AGX Thor。在早期的边缘导向实验中,FP16 BEVPoolV3 路径可以很好地沿用,因为核心改进 (消除冗余散点流量、避免运行时索引解码和使用区间所有写入) 独立于架构。
然而,FP8 加速并不是自动的。在边缘级目标上,较小的问题大小、内存层次结构行为、寄存器压力和 FP8 转换开销可能会限制或抵消理论上的 dtype 带宽优势。这使得 FP8 成为内核和架构特定的优化,而非 FP16 的直接替代品。
开始使用鸟瞰图池化优化
要将 BEVPoolV3 工作流应用于您自己的 BEV 感知或收集/ 散布繁重的工作负载,请先隔离分析操作员。测量特征、深度、散点索引和输出张量大小,然后将总工作集与目标 GPU 二级缓存容量进行比较。
使用 NVIDIA Nsight Compute 验证活动瓶颈是内存带宽、指令问题、占用还是依赖延迟。然后选择与内存机制相匹配的优化策略:用于 DRAM 受限工作负载的字节归约和缓存保留存储,或用于 L2-Resident 工作负载的占用、预先计算的索引、矢量化负载,以及 dtype 专用化。
该方法同样适用于稀疏嵌入、体素化、直方图、分段归约和其他不规则内存受限的内核。使用 BEVPoolV3 结果作为指南,分析您自己的 Operator,为目标 GPU 选择正确的实现策略,并在通过 TensorRT 部署之前验证结果。有关相关资源,请参阅 TensorRT 文档、CUDA C++ 编程指南、Nsight Compute 文档 和 NVIDIA 开发者论坛。