
NVIDIA CUDA Tile(cuTile)是一种基于图块的编程模型,可让开发者以图块为单位进行操作(如加载、存储和矩阵乘积累加),编写 GPU 核函数,而无需手动管理线程、线程束和共享内存。
cuTile.jl 将相同的基于图块的方法引入了动态编程语言 Julia。用户无需使用 NVIDIA CUDA C++ 即可编写自定义 GPU 核函数。这类自定义内核在 Julia 的科学计算生态系统中通常至关重要,广泛应用于微分方程、概率编程和物理模拟等领域。
cuTile Python 拥有一个持续增长的 GPU 加速优化内核库。通过将这些内核转换为 cuTile.jl,Julia 生态系统能够直接使用经过实战验证的实现,而无需从零开始逐一重写。
本文将介绍跨域特定语言(DSL)的 GPU 内核翻译,包括将 cuTile 的 Python 内核移植到 cuTile.jl(Julia)。内容将展示如何:
- 在 cuTile Python 和 cuTile.jl 之间转换 GPU 核函数: 并行浏览完整的矩阵乘法示例。
- 避免陷入朴素翻译的语义陷阱:索引、广播、内存布局和循环形式在两个 DSL 之间存在差异,若默认不匹配,将产生错误结果,而非编译器报错。
- 构建可复用的技能驱动型 AI 工作流: 将翻译知识封装为 TileGym 中的 LLM 技能,使其能在一次执行中生成经过验证的 Julia 核函数,从而将一次性移植任务系统化。
跨 DSL GPU 内核转换
cuTile Python 和 cuTile.jl 前端共享相同的图块抽象,使翻译在很大程度上符合算法。但是,这两种语言之间的累积表面级差异并非易事,如表 1 所示。
| 类别 | Python ( cuTile) | Julia ( cuTile.jl) |
| 索引 | 基于 0 (ct.bid(0)) |
基于 1 的 (ct.bid(1)) |
| 广播 | 隐式 (a + b) |
显式点语法 (a .+ b) |
| 显存布局 | 行少校 | 主要列 |
| 内核定义 | @ct.kernel decorator |
普通 function ... end |
| 常量 | 签名中的 param: ct.Constant[int] |
签名中的 param::Int,启动时的 ct.Constant(val) |
| 类型转换 | tile.astype(ct.float32) |
convert(ct.Tile{Float32}, tile) |
| 矩阵乘法 | ct.mma(a, b, acc=acc) |
muladd(a, b, acc) |
从概念上讲,所有这些转换都不是很困难的,但错过了一个 ct.bid(0),应该是 ct.bid(1),您就会得到无声的数据损坏。使用 * 而不是 .* 进行元素乘法,然后 Julia 静默地执行矩阵乘法。这些错误会浪费数小时。
包含有限的循环陷阱的共享抽象非常适合 AI 辅助工作流,前提是该模型学习了需要注意的内容。
将 cuTile Python 翻译为 cuTile.jl
实际代码能够更好地理解这一过程。以下示例来自 TileGym,其中团队将一组 cuTile Python 内核移植到 cuTile.jl,并将其打包为自包含的 Julia 子项目。
矩阵乘法示例
正在运行的示例使用了 matmul,这非常复杂,足以显示关键的翻译挑战。除了基本的语法差异外,转换还必须处理循环结构、TF32 Tensor Core 转换以及从行主要布局到列主要布局的转换。
cuTile Python:
@ct.kerneldef matmul_kernel(A, B, C, tm: ct.Constant[int], tn: ct.Constant[int], tk: ct.Constant[int]): bid_m = ct.bid(0) bid_n = ct.bid(1) num_k = ct.num_tiles(A, axis=1, shape=(tm, tk)) acc = ct.full((tm, tn), 0, dtype=ct.float32) dtype = ct.tfloat32 if A.dtype == ct.float32 else A.dtype for k in range(num_k): a = ct.load(A, index=(bid_m, k), shape=(tm, tk), padding_mode=ct.PaddingMode.ZERO) b = ct.load(B, index=(k, bid_n), shape=(tk, tn), padding_mode=ct.PaddingMode.ZERO) a = a.astype(dtype) b = b.astype(dtype) acc = ct.mma(a, b, acc) acc = ct.astype(acc, C.dtype) ct.store(C, index=(bid_m, bid_n), tile=acc) |
cuTile.jl ( Julia) :
function matmul_kernel(A::ct.TileArray{T,2}, B::ct.TileArray{T,2}, C::ct.TileArray{T,2}, tm::Int, tn::Int, tk::Int) where {T} bid_m = ct.bid(1) bid_n = ct.bid(2) num_k = ct.num_tiles(A, 2, (tm, tk)) acc = zeros(Float32, tm, tn) U = T === Float32 ? ct.TFloat32 : T for k in Int32(1):num_k a = ct.load(A; index=(bid_m, k), shape=(tm, tk), padding_mode=ct.PaddingMode.Zero) b = ct.load(B; index=(k, bid_n), shape=(tk, tn), padding_mode=ct.PaddingMode.Zero) a = convert(ct.Tile{U}, a) b = convert(ct.Tile{U}, b) acc = muladd(a, b, acc) end acc = convert(ct.Tile{T}, acc) ct.store(C; index=(bid_m, bid_n), tile=acc) returnend |
除基本语法更改外,请注意以下事项:
- 布局会翻转: 在 Julia 中,Python 的行长
A(M,K)会变为列长A_jl(K,M),累加器、加载索引和存储索引也都会相应改变。若得到错误的累加器形状(例如(TM, TN)而不是(TN, TM)),结果将出错,且不会有任何编译器警告。 ct.mma → muladd:cuTile.jl 将矩阵乘积累加操作映射到 Julia 标准muladd,ct.PaddingMode.ZERO转换为ct.PaddingMode.Zero(PascalCase)。
Softmax 示例
Softmax 会进一步推动发展。为处理不同的张量大小,Julia 实施了三种策略:张量内存加速器 (TMA) 单瓦、在线和分块。除了 matmul 模式之外,softmax 函数还引入了广播点语法 (ct.exp(ct.sub(a, b)) * exp.(a .- b)) 、重命名归约 (ct.max → maximum,ct.sum → sum,axis = 1) ,以及元素级 ct.maximum(a, b) * max.(a, b)。
但真正的挑战并不在于语法,而是在于通过翻译来保持正确运行最大/ 总和统计数据。
生成具有智能体技能的工作流
这个项目的主要成果不是翻译后的内核,而是生成这些内核所需的技能。
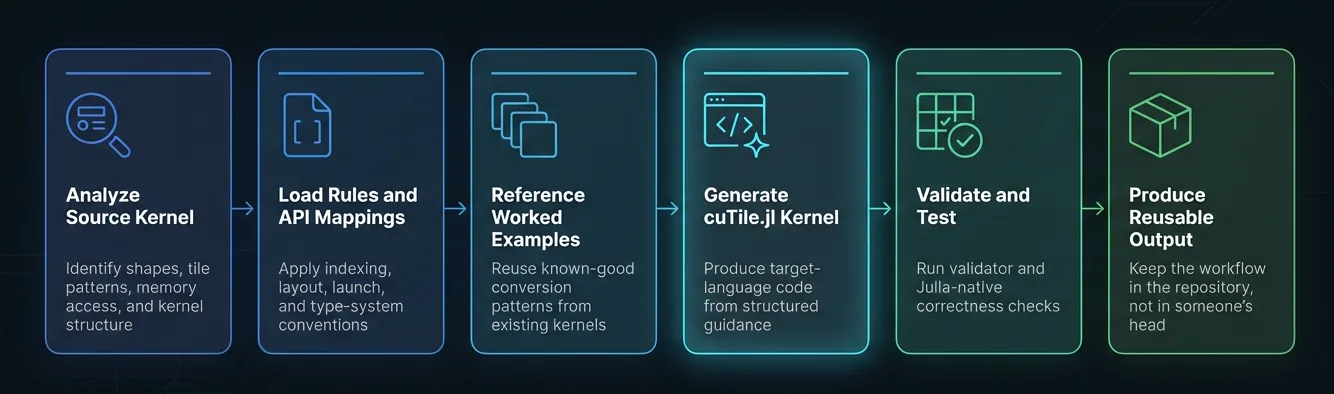
在这种情况下,技能是存储库中的结构化知识目录,由 LLM 智能体获取。获取此特定技能的路径为:.claude/skills/converting-cutile-to-julia/。
.claude/skills/converting-cutile-to-julia/├── SKILL.md # Entry point: workflow overview, top pitfalls├── translations/│ └── workflow.md # Step-by-step conversion with checklists├── references/│ ├── api-mapping.md # Bidirectional Python↔Julia API table│ ├── critical-rules.md # 17 rules (indexing, broadcasting, loops, ...)│ ├── debugging.md # Error diagnosis for MethodError, IRError, etc.│ └── testing.md # Test patterns, tolerances per dtype├── scripts/│ └── validate_cutile_jl.py # Static checker for common anti-patterns└── examples/ ├── 01_add/ # Python→Julia for vector addition ├── 02_matmul/ # Python→Julia for matrix multiply └── 03_softmax/ # Python→Julia for softmax (3 strategies) |
仅 critical-rules.md 就捕获了团队遇到的 17 个陷阱。表 2 详细介绍了最常见的陷阱和相关修复。
| # | 陷阱 (Pitfall) | 修复 |
| 1 | max(a, b) 位于图块上 IRError |
使用 max.(a, b) (广播点) |
| 2 | ct.load 和 order – 索引位置错误 |
order 重新映射形状和索引 |
还有一个静态验证器脚本,在 GPU 上运行之前,该脚本会捕获内核内部循环的剩余 ct.bid(0) 和 Python 类型名称等内容。完成所有这些操作后,模型无需每次都重新发现转换规则。它会读取技能、遵循检查清单并应用规则。
TileGym 中的 AI 智能体技能
具体交付成果是开源的 TileGym 中 julia/ 下的 Julia 子项目:
julia/├── Project.toml # Dependencies: CUDA.jl, cuTile.jl, NNlib.jl, Test├── kernels/│ ├── add.jl # 1D element-wise with alpha scaling│ ├── matmul.jl # 2D tiled MMA with column-major layout│ └── softmax.jl # 3 strategies: TMA, online, chunked└── test/ ├── runtests.jl # Test runner ├── test_add.jl ├── test_matmul.jl └── test_softmax.jl |
我们特意选择了这三个内核。添加内核是测试整个翻译面的最简单方法。Matmul 添加了循环结构、Tensor Core 和布局翻转。Softmax 引入了多通道算法,其中的不变量必须在转换后才能生存下来。每个内核都有与 CPU 参考进行比较的测试,包括尺寸与图块大小不匹配的边界案例。
成果和经验教训
技能到位后,每个内核的工作流程如下所示:
- 飞行前: 扫描源代码以查找需要特殊处理的模式 (
for循环、ct.mma、order=等) 。 - 转换: 应用 API 映射和关键规则。
- 验证:运行静态检查程序。
- 测试:针对参考实现运行 Julia 测试。
- 修复:如果出现故障,请使用调试指南进行修复,然后重新运行。
对于典型的通用矩阵乘法 (GEMM) 转换,该过程大约需要 4 分钟,在前沿 LLM 上大约需要 78K 词元,无需人工干预。后续内核的速度更快,因为示例和规则已经在存储库中。
表 3 列出了在移植期间导致错误的陷阱,所有这些现在都会在技能中自动处理。
| 陷阱 (Pitfall) | 症状 | 根本原因 |
ct.bid(0) 保持不变 |
图块加载错误,静音损坏 | 基于 0 的索引与基于 1 的索引 |
a * b 表示元素乘法 |
矩阵乘法而非元素乘法 | Julia * 是 matmul;需要 .* |
累加器形状 (TM, TN) |
matmul 中的错误结果 | 列主要需求 (TN, TM) |
ct.PaddingMode.ZERO |
UndefVarError |
Julia 使用 Pascal 大小写:.Zero |
要点并不在于 AI 编写了代码。它能够将所学内容捕捉为模型下次可以重复使用的内容。提示词可能会说,“小心编制索引”。技能可能会说,“以下是 17 个出错的特定内容,以下是检查这些内容的方法,以下是自动捕获这些内容的脚本。”
现在,未来的端口可以从已经有工作示例、经过测试的 API 映射、静态验证器和调试指南的存储库开始。每一次都比上一次花费更少的精力。
更广泛的观点是,将 AI 用于系统工作的挑战不在于代码生成,而是在于在编译器不会发现语义错误的领域中生成正确的代码。在版本控制中编码域规则及其描述的代码是解决这一问题的一种方法。
开始使用智能体技能将 Python 内核转换为 Julia
使用以下代码试用 Julia 子项目和转换技能:
cd TileGym# Explore the Julia kernelsls julia/kernels/ # add.jl, matmul.jl, softmax.jl# Explore the conversion skillls .claude/skills/converting-cutile-to-julia/# Install Julia dependencies (requires Julia 1.12+, CUDA 13.1+ driver)julia --project=julia/ -e 'using Pkg; Pkg.instantiate()'# Run the Julia kernel testsjulia --project=julia/ julia/test/runtests.jl |
要求:
- Julia 1.12+ 和 NVIDIA CUDA 13.1+ 驱动程序
- NVIDIA Ampere、NVIDIA Ada 或 NVIDIA Blackwell GPU (计算能力 8.x、10.x、11.x、12.x)
- 具备文件系统访问权限的 LLM 代理(例如 Claude Code)。若要将转换技能应用于您自己的内核,请让您的 LLM 代理访问 .claude/skills/converting-cutile-to-julia/SKILL.md,将 cuTile Python 内核作为输入,然后开始将其转换为 Julia 内核。