
随着 AI 系统从单轮交互转向协调的多智能体工作流,低延迟 推理 成为越来越重要。自回归 LLM 按顺序生成 token,这可能会限制 GPU 利用率,并限制延迟敏感型服务场景中的吞吐量。
预测解码帮助缓解这一瓶颈,使用轻量级模型起草未来token,然后由更大的目标模型并行验证。 DFlash是一个开源轻量级块扩散模型,专为预测性解码而设计,通过块扩散绘图器扩展了这种方法。此制图员在一次正向传递中生成整个候选token块,将顺序制图转化为块并行GPU工作,同时通过验证保持目标模型的输出质量。
在相同的交互性水平下,DFlash 可将 NVIDIA Blackwell 上 gpt-oss-120b 的推理性能提升高达 15 倍。与先进的 EAGLE-3 预测解码相比,在相同并发下,Llama 3.1 8B 的交互性几乎提高了一倍。
DFlash 也在迅速从研究转向开发者工作流。该研究团队已在 Hugging Face 上发布了 20 个 DFlash Checkpoint,其中包括 NVIDIA Blackwell 和 NVIDIA Hopper GPU 的配方。
在本文中,我们分享了在使用 TensorRT-LLM 的 NVIDIA Blackwell Ultra 系统上运行的 DFlash 的延迟 – 吞吐量 Pareto 曲线。我们还讨论了如何在 NVIDIA GPU 推理堆栈 (包括 SGLang 和 vLLM) 中更广泛地使用 DFlash。
DFlash 如何在 NVIDIA Blackwell 上以相同的交互性提供更高的吞吐量?
图 1 显示了在 TensorRT-LLM 中使用 DFlash 运行 gpt-oss-120b,在 8 个 NVIDIA DGX B300 系统上使用 SPEED-Bench 编码数据集 的 Pareto 延迟 – 吞吐量曲线。在整体上,与自回归解码相比,DFlash 可在与生产相关的延迟目标下提供更高的吞吐量。此配置为系统中所有八个 NVIDIA Blackwell GPU 提供 gpt-oss-120b 服务,为代码生成等代理式用例提供实现高交互性目标所需的 GPU 显存、计算和互连带宽。
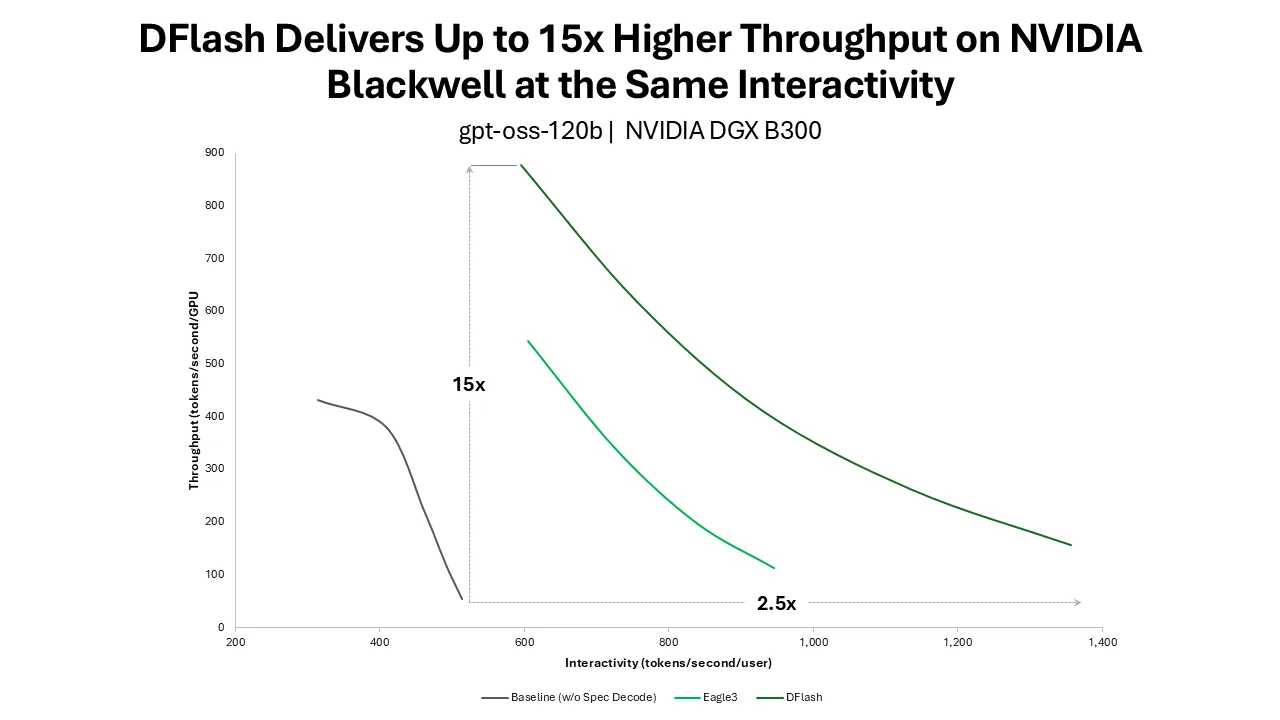
在每位用户 500-600 个令牌/ 秒的高交互性范围内,与自回归解码相比,DFlash 将 NVIDIA Blackwell 的吞吐量提高了 15 倍以上,比 EAGLE-3 预测解码高 1.5 倍。在最低并发点 (批量大小为 1) ,DFlash 可将 Blackwell 上的交互性提高一倍以上。
观察各种并发的帕累托曲线非常重要,因为服务团队通常会针对目标交互级别进行优化。交互式编码、推理和智能体工作负载通常需要在扩展并发性的同时,保持严格的每个用户 token 延迟。DFlash 通过在预测解码路径中添加并行性来改进这种权衡:其块扩散绘图器一次性生成多个候选令牌,而目标模型并行验证这些令牌。
在 NVIDIA Blackwell 上,这种并行性特别有价值。在解码受限的区域,LLM 推理通常受内存移动和 token 生成的顺序性质的限制,而非原始计算。DFlash 有助于将这项工作的一部分转移到并行块绘制和验证,使系统能够在保持相同交互性目标的同时使用更多的可用计算。
每个 NVIDIA Blackwell Ultra GPU 结合了两个光刻版大小的裸片,通过 10 TB/s 的高带宽芯片间互连技术连接,形成了一个包含 160 个 SM 和 640 个第五代 Tensor Core 的统一计算域。DFlash 非常适合此架构,因为它为 Blackwell 的 15 PFLOPS 密集 NVFP4 计算提供了更多并行工作,在相同的交互速率下同时为多达 15 倍的用户提供服务。
DFlash 还显示,在不同数据集上,与 EAGLE-3 预测解码相比,交互性加速。这一优势还延伸到了更小的模型,对于 Speed-Bench 多语言数据集,在 Llama 3.1 8B 上,DFlash 的性能比 EAGLE-3 几乎翻了一番。
| 相同用户并发级别下的加速 | ||||
| gpt-oss-120b | Llama 3.1 8B 说明 | |||
| 数据集 | EAGLE-3 | DFlash | EAGLE-3 | DFlash |
| 编码 | 1.8 倍 | 2.6 倍 | 2.3 倍 | 3.0 倍 |
| RAG | 1.7 倍 | 2.3 倍 | 2.4 倍 | 3.1 倍 |
| 推理 | 1.8 倍 | 2.3 倍 | 2.5 倍 | 2.8 倍 |
| 写作 | 1.5 倍 | 1.8 倍 | 2.3 倍 | 2.7 倍 |
| 多语种 | 1.8 倍 | 2.6 倍 | 1.4 倍 | 2.4 倍 |
| 总结 | 1.6 倍 | 2.0 倍 | 2.3 倍 | 2.6 倍 |
| 中等 | 1.7 倍 | 2.3 倍 | 2.2 倍 | 2.8 倍 |
NVIDIA 生态系统为开发者提供 DFlash,无需应用重构
加州大学圣地亚哥分校的研究人员于 2026 年 2 月发表了论文DFlash:Block Diffusion for Flash Speculative Decoding(Flash 预测解码块扩散),这是 NVIDIA Blackwell 上更快、更高效的 LLM 推理工作的一部分。DFlash 采用 PyTorch 构建,并支持原生 CUDA,可通过块扩散预测解码提高解码性能。NVIDIA 和开源推理社区帮助确保了 SGLang 和 vLLM 的强大框架支持,为开发者提供了一条清晰的路径,让他们可以在选择的服务堆栈中将 DFlash 引入推理部署中。
自该论文发布以来,研究团队已针对 Hugging Face with Blackwell 和 Hopper recipe 发布了 20 个 DFlash 模型检查点,涵盖了 Qwen、Kimi K2.6、Llama、Gemma 和 gpt-oss 等模型系列。方法包括支持 SGLang 和 vLLM 等热门推理框架。
在 vLLM 上,开发者可以将 EAGLE-3 与 DFlash 检查点交换,而不会在配置之外更改代码。该集成通过开源的 Speculator 库运行,该库将 DFlash 起草者与 NVIDIA GPU 上 vLLM 推理路径内的目标模型的隐藏状态连接起来。在单个 Blackwell Ultra GPU 上运行的 Gemma 4 31B 上,与自回归解码相比,此路径在相同并发下可提供高达 5.8 倍的吞吐量 (表 2) 。
对于 SGLang,从 EAGLE 迁移到 DFlash 只需要将预测解码算法更新到 DFlash,并提供匹配的 DFlash 草稿模型检查点。在单个 Blackwell GPU 上运行的 Qwen3 8-B 上,此路径在与自回归解码相同的并发下可提供高达 5.1 倍的吞吐量 (表 3) 。
这种对 NVIDIA GPU 的早期模型和框架的广泛覆盖很重要,因为它使团队能够通过开发者已经使用的框架快速评估和部署新的优化,而无需进行任何应用程序重构。
| 提高并发速度 1 Gemma-4 31B | vLLM | 1 个 NVIDIA DGX B300 |
|
| 任务 | DFlash 与 AutoRegressive 的对比情况 |
| Math500 运算能力 | 5.8 倍 |
| GSM8K | 5.3 倍 |
| HumanEval | 5.6 倍 |
| MBPP | 4.4 倍 |
| MT 工作台 | 3.0 倍 |
| 提高并发速度 1 Qwen3 8-B | SGLang | 1 个 B200 |
|
| 任务 | DFlash 与 AutoRegressive 的对比情况 |
| Math500 运算能力 | 5.1 倍 |
| HumanEval | 4.2 倍 |
DFlash 预测解码的工作原理是什么?
预测解码分为两个阶段:起草和验证。一个较小的草稿模型提出了未来的 token。目标模型并行验证这些令牌,并接受最长的有效前缀。如果草稿正确,则系统会通过一个目标模型验证通道生成多个 token。
传统的预测解码方法通常使用自回归草稿模型。这些起草者仍然按顺序生成 token,因此起草成本会随着预测令牌数量的增加而增加。这限制了方法提高吞吐量的能力。
DFlash 将自回归绘图器替换为轻量级的块扩散绘图器。DFlash 起草员不会逐个生成 token,而是在一次前向传递中预测一个被掩码的 future token 块。

DFlash 结合了三种关键技术:
- 块扩散制图:制图员并行预测多个未来 token。
- 目标隐藏状态调节:起草者使用从目标模型中提取的上下文特征。
- KV 注入:目标上下文特征注入到草稿模型的各层关键值预测中,有助于保持高接受率。
这种设计使制图员既快速又高效。目标模型仍在执行验证,因此 DFlash 在加速生成的同时保留了目标模型的输出分布。
开始使用 DFlash 提升推理性能
研究社区继续在 NVIDIA GPU 上开发新的推理优化,而 DFlash 就是一个很好的例子,展示了 NVIDIA 生态系统如何快速将这些想法提供给开发者。
准备好开始了吗?DFlash 现已在 NVIDIA GPU 开放模型检查点上提供,并在 SGLang、vLLM 和 TensorRT-LLM 中受支持,访问 开放模型检查点 获取更多信息。