
物理 AI (在基于物理性质的模拟环境中感知、推理和行动的 AI 系统) 正在改变团队设计和验证机器人和工业系统的方式,而这一切远早于任何产品交付到工厂车间。在 GTC 2026 大会上,NVIDIA 强调物理 AI 是机器人和 数字孪生 的关键方向,在基于物理的环境中训练和验证策略。
为使 NVIDIA Omniverse 更易于集成到现有应用中,NVIDIA 在现有平台的基础上增加了一个基于库的模块化架构。Omniverse 的核心组件 ( RTX 渲染、基于 PhysX® 的仿真和数据存储工作流) 将作为独立的、无外设的* 首个 C API (具有 C++ 和 Python 绑定) 公开:ovrtx、ovphysx 和 ovstorage。对于拥有成熟堆栈的开发者而言,这些库减少了对重大架构重写的需求,让您无需采用完整的 Omniverse 容器堆栈即可集成 Omniverse 功能。
通过模块化模拟实现价值
在大型机器人和工业部署中,整体式运行时可能会导致难以扩展仿真、无头部署或与现有的 CI/ CD 系统集成。库优先架构通过将渲染、物理和存储直接嵌入到现有服务中,而不是在单个 Omniverse 运行时中运行所有内容,从而解决这些限制。团队现在可以直接从自己的流程和服务调用 Omniverse 渲染、物理和存储 API,而无需采用完整的应用框架。
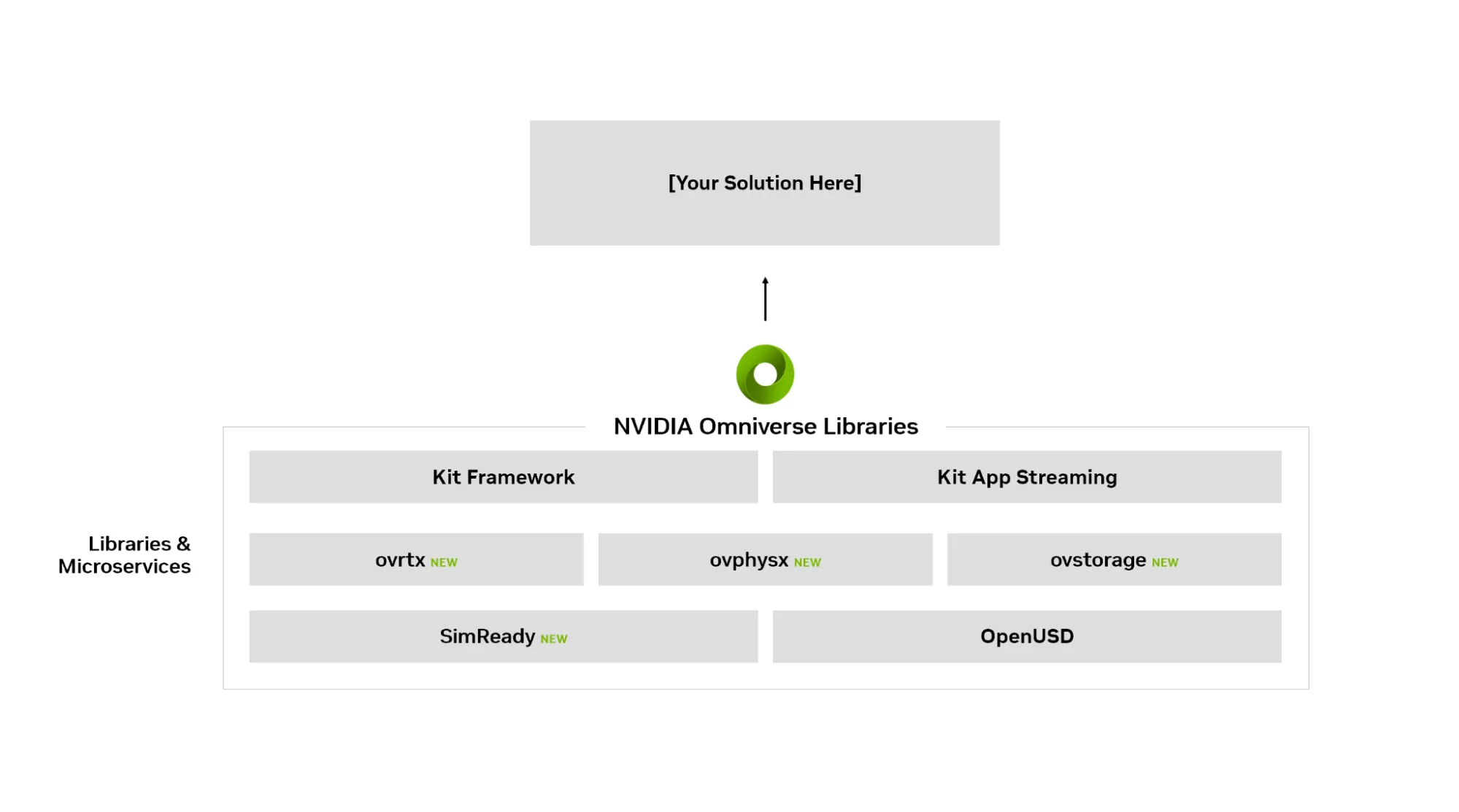
核心系列
这些库旨在解决工业软件开发的特定集成难题:
这些库可插入现有的 Omniverse 组件,用于场景描述 (OpenUSD)、仿真就绪型资产 (SimReady) 和应用开发 (Omniverse Kit 框架)。
库可用性和生产路径
目前,ovrtx、ovphysx 和 ovstorage 可在 GitHub 和 NGC 上抢先体验。抢先体验版可能会在不同版本之间更改 API;NVIDIA 通过 GitHub 和 Omniverse Discord 发布迁移说明并征求反馈。在抢先体验期间,我们专注于扩大覆盖范围 (物理特性、传感器模型) 和优化 GPU 利用率。我们计划在今年晚些时候推出具有 API 稳定性和长期支持的正式版本。
NVIDIA 正在内部利用这些库为其下一代物理 AI 蓝图和框架提供支持:
- NVIDIA Isaac Lab:目前正在从 Omniverse Kit 框架过渡到由 ovphysx 和 ovrtx 驱动的模块化架构。这将实现显式执行控制、确定性模拟,以及在不依赖用户界面的情况下运行高密度、无外设物理的能力。
- NVIDIA Omniverse DSX Blueprint:DSX 参考设计的数字孪生演示,向开发者展示如何在 AI 工厂设施及其软硬件生态系统中使用 Omniverse 库进行设计、仿真和运营。
通过首先在高性能内部堆栈和工业蓝图中测试这些库,我们确保它们在全面可用之前满足企业级物理 AI 的严格要求。
代理式编排:使用支持 MCP 的库扩展物理 AI
为了让基于 LLM+ 的智能体能够进行仿真,Omniverse 通过模型上下文协议 (MCP) 服务器提供了其功能。这些服务器描述了机器可读模式中的操作 (例如,加载 USD 场景、编辑基元、步进模拟) ,因此 Claude 和 Cursor 等工具可以安全地调用它们。
- Kit USD 代理:一系列 MCP 服务器Kit、USD 和 OmniUI。这些功能可让智能体浏览 API、生成场景代码,以及操作高层描述中的层层次结构或 UI 元素。
MCP 服务器设置
每个 MCP 服务器都可以使用 Docker 或 Python 在本地运行。请参阅各个服务器文档:USD Code MCP、Kit MCP、OmniUI MCP。
快速入门 ( Docker – 推荐) :
# Set your NVIDIA API key firstexport NVIDIA_API_KEY=your_api_key_here # Linux/macOS# orset NVIDIA_API_KEY=your_api_key_here # Windows# Build wheels and start all MCP serverscd source/mcp./build-wheels.sh all # or build-wheels.bat all on Windowsdocker compose -f docker-compose.ngc.yaml up --build |
这将通过您的 API 密钥使用 NVIDIA 云托管的嵌入和重排序服务。无需本地 GPU。
为了扩展这些工作流,开发者可以利用 NemoClaw,一种面向 OpenClaw 社区的新基础架构堆栈,在由基于策略的护栏保护的隔离沙盒中部署安全、始终开启的自主代理。借助 MCP 服务器处理对 Omniverse 的低级远程程序调用 (RPC) ,团队可以专注于定义智能体行为和护栏,而无需对每次仿真 API 调用进行人工接线。
案例研究:使用模块化库优化 NVIDIA Isaac Lab
NVIDIA Isaac Lab 的最新工程演进充分展示了向库优先架构的转变。作为用于强化学习 (RL) 的高性能机器人仿真框架,Isaac Lab 需要极高的可扩展性和确定性控制。
借助 Isaac Lab 3.0 测试版,NVIDIA 已将 Isaac Lab 的基础层从整体式 Kit 框架转变为模块化的多后端架构。
- 在物理特性方面,开发者现在可以选择
` ovphysx`包含 PhysX SDK 的独立库,或由 MuJoCo-Warp 提供支持的无套件 Newton 后端,具体取决于其仿真要求。 - 在渲染方面,可插拔渲染器系统支持 OVRTX、Isaac RTX、Newton Warp 以及 Rerun 和 Viser 等轻量级可视化工具。
此版本目前处于测试阶段,计划于今年晚些时候全面推出。这种多后端设计显著改变了 NVIDIA 在内部构建仿真堆栈的方式,从单一运行时过渡到一组可互换的物理和渲染后端。
实现细节:解决“框架锁 “
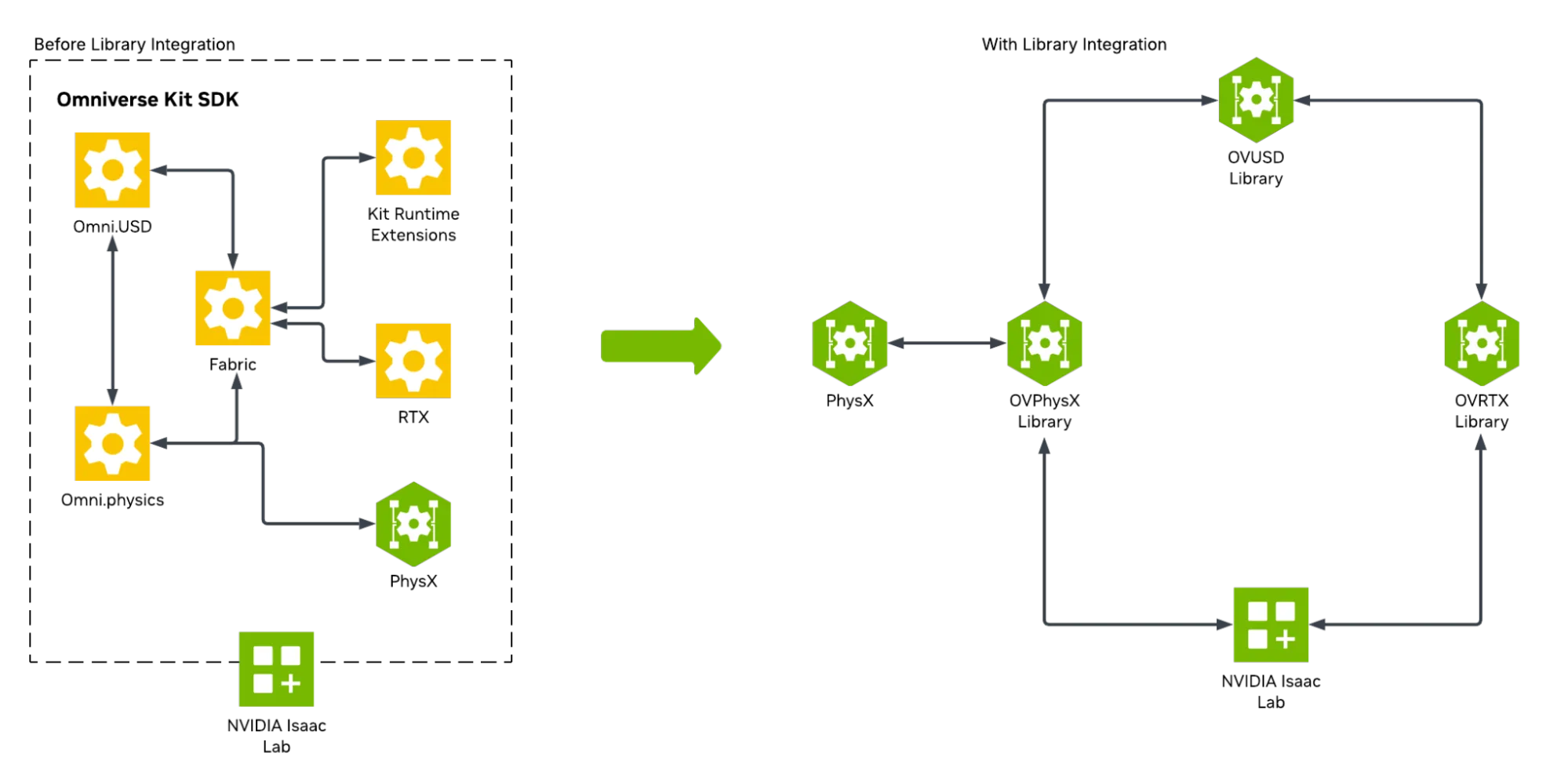
对于 Isaac Lab 工程团队而言,迁移到独立库解决了三个主要架构瓶颈:
- 显式执行控制:独立 API 取代 Kit 运行时循环,允许开发者手动触发物理步骤。这可确保确定性执行,并消除框架引起的延迟。
- 解更新频率:模块化库支持仿真组件的独立步进。高频传感器 (IMU) 和低频视觉系统现在可以在一个环境中以原生速率运行。
- 可扩展的无外设部署:解库可为 Linux 集群提供最小的二进制占用空间。开发者可以在不依赖用户界面的情况下执行高密度物理特性
视频流用于调试或可视化。
通过消除平台运行状况,Isaac Lab 可以利用张量数据交换,通过 GPU 缓冲区直接、高速地访问模拟状态 (例如,在没有主机副本的情况下,将位置/ 速度作为 PyTorch 张量) 。
增强已建立的堆栈:行业应用
Industrial 数字孪生 和 机器人仿真 合作伙伴正开始在其工作流中采用 Omniverse 库,包括试点或早期生产集成。
对于 ABB Robotics、Adobe、Cadence、PTC、Siemens 和 Synopsys 等合作伙伴而言,主要价值在于能够整合基础 RTX 渲染、高保真 PhysX 仿真和原生 OpenUSD 支持,而无需完全的架构重构。
ABB Robotics 等机器人仿真领域的领先企业 正在将 Omniverse 嵌入 RobotStudio,基于其行业值得信赖的虚拟控制器、离线编程和调试工作流进行构建,通过物理 AI 大规模训练和验证工业机器人,而 PTC 正在将 Onshape 直接连接到 Isaac Sim,以进行云+ 原生机器人设计、测试和部署。全球工业软件巨头如 西门子等 正在集成 Omniverse 库,以大规模构建工业级数字孪生。
决策指南:框架还是库?
选择正确的集成路径取决于应用堆栈的特定要求。
决策指南: 何时选择模块化库与完整平台。
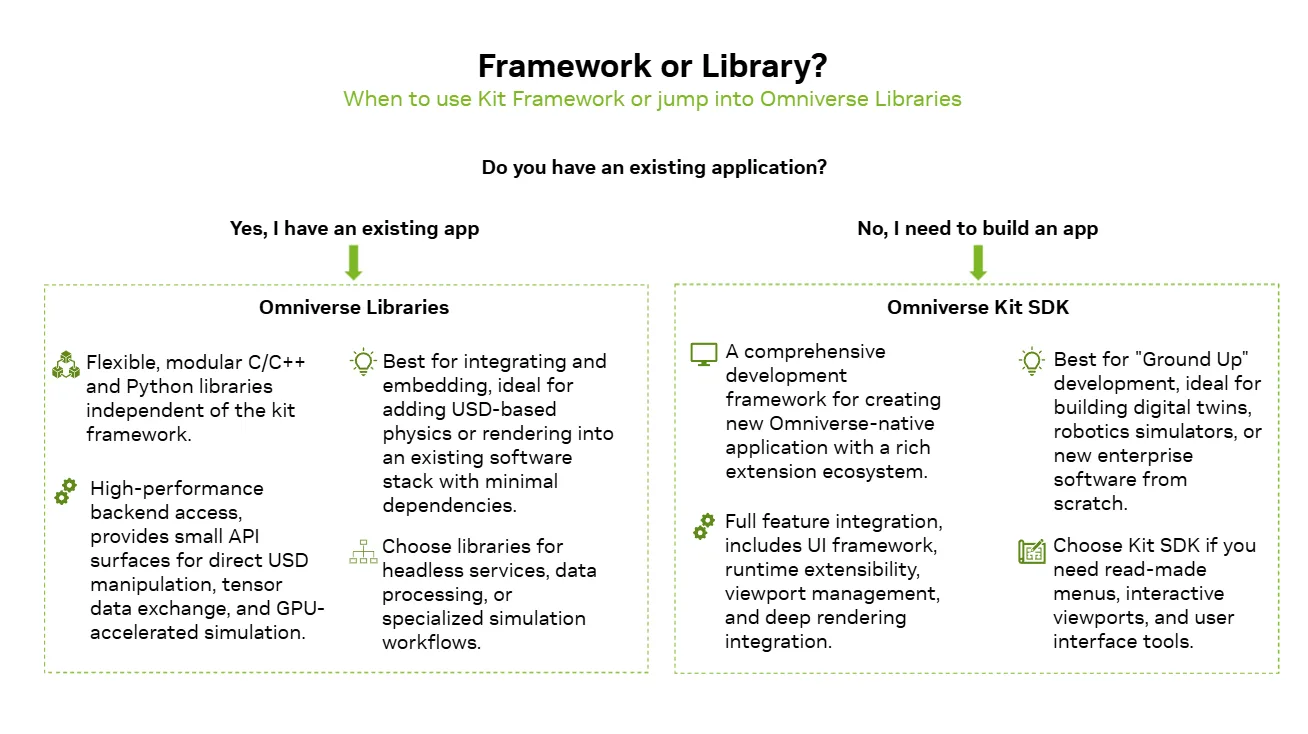
- 何时使用 Omniverse 库:当您想要将物理 AI 功能插入现有 3D 或 CAD 应用,或插入需要高保真物理或传感器渲染的新工作流时,使用 Omniverse 库,而无需采用完整的 Omniverse 堆栈。它们也非常适合轻量级 (通常是无外设) 部署或专门的自主智能体,在这些智能体中,您需要以最少的依赖项和复杂性实现集中功能。
- 何时使用 Omniverse Kit 框架:当您想要构建功能丰富的 OpenUSD 应用或服务时,请使用 Omniverse Kit,该应用或服务需要完整的用户界面、交互式视口,并且需要在渲染、物理和其他 Omniverse 功能之间进行紧密协调。如果您还没有应用程序,需要内置菜单和窗口,并且想要一个将多个扩展程序和库连接在一起的标准应用程序框架,以便您可以专注于域逻辑而不是低级集成,那么它是您的理想选择。
入门:将物理 AI 接入您的工作流
Omniverse 库的最大优势之一ovrtx以及ovphysx其可用性与总体 Omniverse Kit 框架脱钩。这两个库都提供基于其 C API 构建的精简 Python 绑定,因此可以轻松集成到您自己的应用中。
由于它们支持 DLPack,因此您可以使用零拷贝传输数据交换直接与 NumPy、PyTorch 和 Warp 等热门框架进行交互。
如何开始
使用 ovrtx 渲染帧:
ovrtx提供对 RTX 硬件加速渲染的轻量级访问。只需 10 行代码,即可使用 NumPy 加载场景、渲染帧并将其保存为 PNG 文件。
* 要求:Python 绑定使用ctypes并且不需要 C 库以外的依赖项,可在 Python 3.10+ 环境中运行。
from ovrtx import Rendererimport numpy as npfrom PIL import Image# 1. Create the renderer with optional configurationrenderer = Renderer()# 2. Ingest the scenerenderer.add_usd("/path/to/robot.usda") # 3. Step the sensor simulation and retrieve rendered outputsproducts = renderer.step(render_products={"/Render/Product_Robot_01"}, delta_time=1.0/60)# 4. Save rendered output into PNG via numpy DLPack and PILfor frame in products["/Render/Product_Robot_01"].frames: with frame.render_vars["LdrColor"].map(device="cpu") as mapping: pixels = np.from_dlpack(mapping.tensor) Image.fromarray(pixels).save("robot_pose.png") |
这里发生了什么?
- 轻松高效地创建场景:
ovrtx_add_usd ()使用高级缓存和流式传输将给定的 USD 层加载到场景中,以实现高效加载。 - 解步进:
ovrtx_step ()command 命令使用提供的增量时间确定地推进渲染器,使应用程序能够完全控制渲染执行。 - 语义感知张量:上下文管理器
(使用... 作为映射:)自动处理将渲染变量 (如 RGBA 或深度) 映射到 CPU 或 GPU 显存,通过 NumPy Unmapping 轻松共享结果,并在垃圾回收张量时自动处理清理。
如需了解更多信息,请访问 ovrtx Github 资源库。

使用 ovphysx 的最小可行物理循环
虽然ovrtx处理视觉效果,ovphysx充当核心 PhysX SDK 与 USD/ Tensor 环境之间的桥梁。
要运行物理模拟,您的应用程序流将遵循由核心 API 驱动的五个基本异步步骤:
- 实例生命周期:
ovphysx_create_instance
要加载 USD 场景、运行模拟或访问张量,您必须首先创建一个实例。 - 场景提取:
ovphysx_add_usd
此步骤通过将 Actor、关节和物理材质从 USD 文件加载到运行时阶段来定义物理世界。 - 仿真技术的进步:
ovphysx_step
这是您的仿真循环的核心,随着时间的推移,物理性质会不断向前发展。 - 同步:
ovphysx_wait_op
由于库使用的是流排序的异步执行模型,因此您必须使用运算来确保已完成 Step 或 USD 加载。这样可以防止您在尝试读取或写入数据时遇到竞争状况。 - 状态访问:r
ead_tensor_binding/ write_tensor_binding
张量带是库的可扩展 I/ O 机制。此步骤允许您以张量格式观察物理状态 (如速度和位置) 和施加控制 (如施加力) 。
有关更多信息,请访问 ovphysx Github 存储库。
将数据源与 ovstorage 连接
虽然ovrtx以及ovphysx为您的应用提供渲染和物理特性,ovstorage充当统一存储层。它通过统一的 API 层将您的 PLM 或现有资源库直接连接到 Omniverse 生态系统。这消除了同步作业和昂贵的数据迁移,使 USD 工作流无需移动文件。
专为支持 Kubernetes 的无外设部署而设计,ovstorage为您提供全面的架构控制,独立扩展微服务以满足生产需求,而不受单一传统堆栈的限制。
入门指南:
- 集成现有基础架构:将 Omniverse 连接到当前的存储后端 (例如 S3 或 Azure) ,以保持到位的版本控制。
- 部署服务网卡:快速构建自定义适配器,将任何存储后端公开给统一的 API,而无需修改客户端应用。
- 确保合规性:使用经过一致性测试的适配器来满足特定的数据驻留、主权和合规性要求,同时保留单一事实来源。
这些只是ovstorage更多精彩,敬请期待。
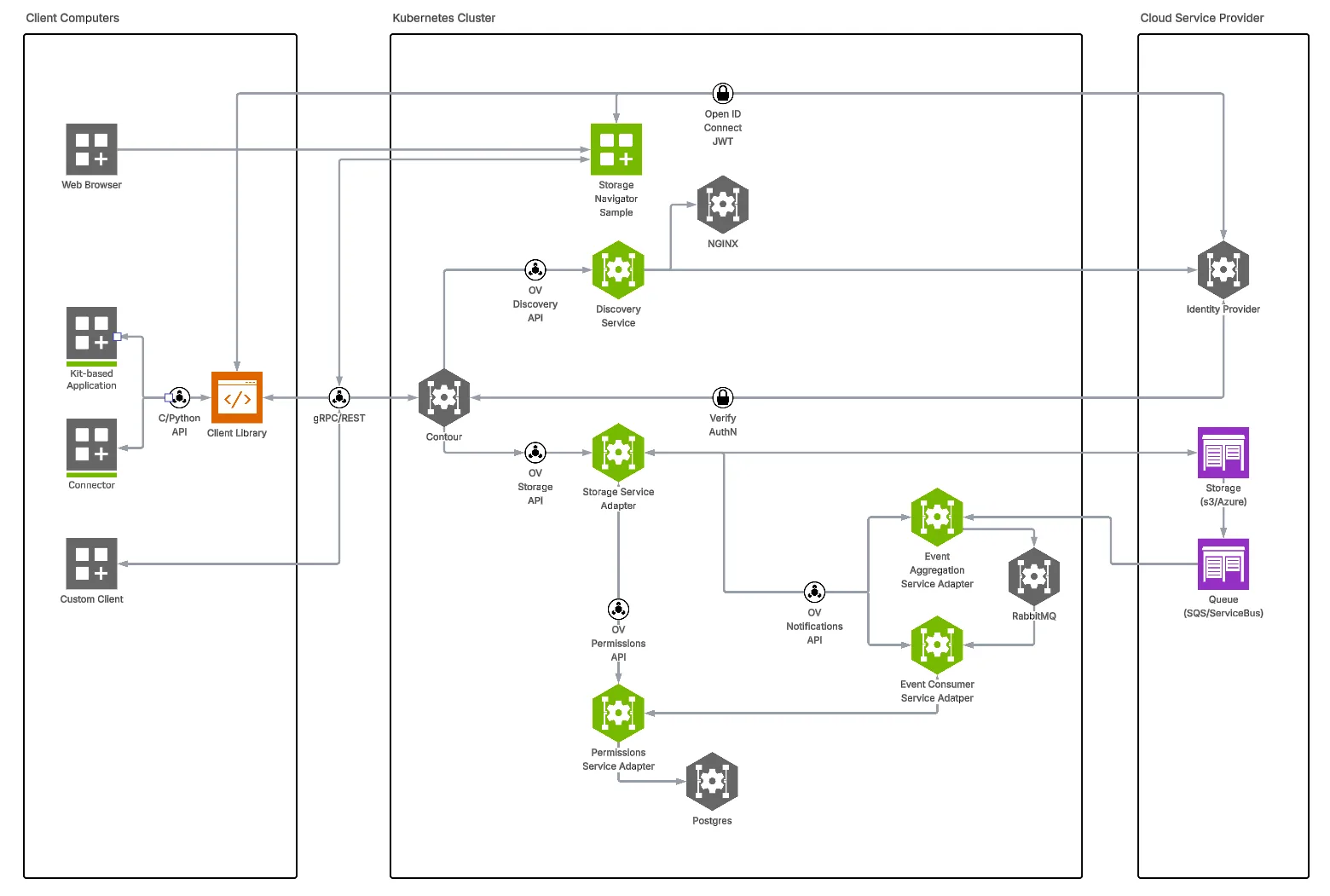
存储实现。如需了解更多信息,请访问 NVIDIA NGC 上的 ovstorage 资源,访问 NVIDIA NGC。
模块化物理 AI 的未来
NVIDIA Omniverse 正在成为一组模块化构建块,您可以将这些库和框架组合成自己的物理 AI 堆栈。通过提供高性能基元ovrtx以及ovphysxNVIDIA 使开发者能够在他们已经拥有的生态系统中构建新一代自主系统。
虽然 Omniverse Kit 框架仍然是开发者构建功能丰富的全新应用的理想选择,但这些独立的库使团队能够在其现有堆栈中进行创新。工业 ISV 和 Isaac Lab 的早期使用表明,模块化库可以更轻松地将仿真集成到现有产品和训练流程中。
立即开始
采取以下后续步骤,开始将模块化物理 AI 集成到您现有的应用中:
- 安装 Omniverse 库:下载
视频流以及ovphysx通过 GitHub存储从 NVIDIA NGC 开始将物理 AI 集成到您的工作流中。 - 了解详情:获取最新GTC 2026 会议并关注我们即将推出的OpenUSD Insiders 直播以便深入了解 Omniverse 开发。
- 与社区互动:与其他开发者分享您的反馈并开展协作Omniverse 开发者 Discord帮助塑造企业就绪型物理 AI 的未来。




