
为运行 AI 工厂,电力成本可占运营支出(OpEx)的 40%。每瓦可用于开销、数据摄取、训练,或为客户生成 token。大多数站点的功率上限为由区域提供商提供的固定功率水平。在这些条件下,每瓦性能成为直接转化为 token 成本的关键效率指标。
NVIDIA 可为 AI 推理工作负载提供最低的单 token 成本,以及最低的大型模型训练成本。这是通过对电源、冷却和系统基础设施进行极致协同设计,以及与 OEM、ODM、CSP、NCP、系统集成商、ISV 和模型生态系统合作伙伴开展深度协作来实现的。
本文将探讨操作员如何在 AI 工厂中更大限度地提高每瓦性能并更大限度地降低 token 成本。
为什么推理优化对 AI 工厂很重要?
推理可以增加收入,因此优化推理是关键工作负载。当运算符提高每瓦特的推理吞吐量时,他们可以销售的 token 或可以创造的见解的数量就会直接增加。这也转化为每单位时间的额外收入。
在百兆瓦到千兆瓦的规模上,即使每兆瓦吞吐量提高几个百分点,也可以转化为有意义的利润收益。
模型架构也很重要。与具有相似总参数的密集模型相比,混合专家模型 (MoE) 的每单位智能能效通常更高,因为每个 token 中只有一组专家处于活动状态。例如,DeepSeek-R1 具有较大的参数数量,其中一小部分会针对每个 token 激活。与稠密的上一代产品相比,它能够以类似于或更低的每 token 计算成本实现更高的任务性能。换言之,MoE 设计可在生成每个 token 所需的能源相同或更少的情况下提供更多智能。
如何优化系统级能耗和每瓦性能
NVIDIA 架构和平台旨在提高每代产品每瓦特产生的智能数量。在六代架构中,NVIDIA 将每兆瓦的推理吞吐量提高了 100 万倍。
NVIDIA GB200 NVL72 机架级扩展系统通过极致协同设计提高能效,并采用密集、直接面向芯片的液冷架构,可提供更高的每瓦吞吐量。它使用机架内功率平滑来降低峰值电流峰值,使运营商能够在相同的功率和基础设施预算内安全地部署更多 GPU。
此外,NVIDIA DSX 是一个开放的 AI 工厂级平台,可推动动态功耗分配和实时遥测,并应用先进的机架级控制来恢复搁浅功耗并增加每瓦 token 数。
浮点精度又增加了一层:较高的精度计算速度通常较慢且消耗更多能源,而NVFP4等窄精度格式则更节能,可提供更高的吞吐量,且精度与FP8相同。同样重要的是,NVIDIA Dynamo和NVIDIA TensorRT-LLM可通过提高吞吐量、降低成本,并更高效地在GPU基础设施上扩展推理模型,将这些收益转化为现实世界的推理性能。
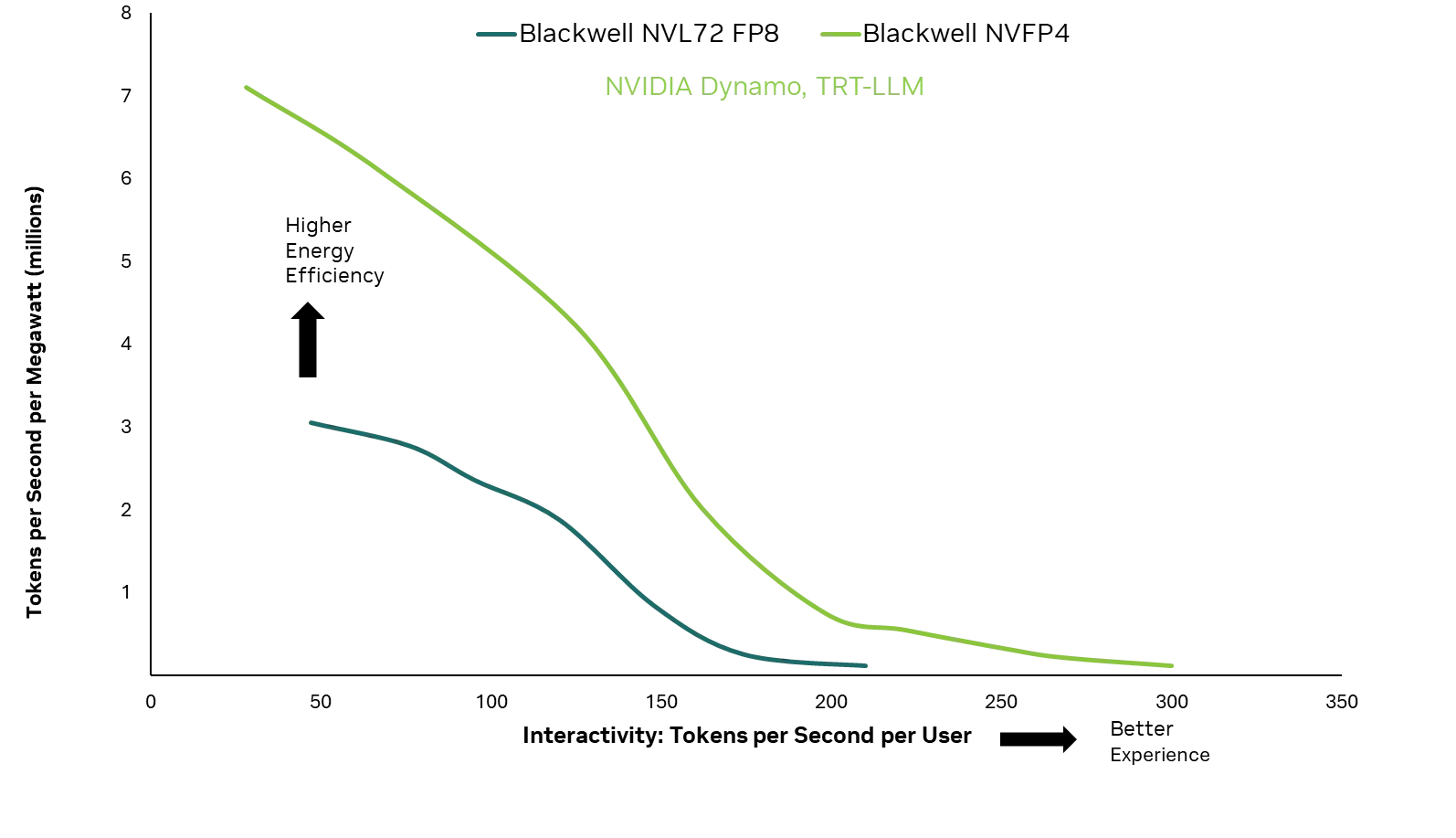 图 1. 在交互级别上,NVFP4 等窄精度格式每秒可提供比 FP8 等更高精度格式更多的 token,从而在固定功耗预算内实现更出色的 AI 输出
图 1. 在交互级别上,NVFP4 等窄精度格式每秒可提供比 FP8 等更高精度格式更多的 token,从而在固定功耗预算内实现更出色的 AI 输出总体能源使用情况取决于计算量、硬件效率、GPU 利用率,以及系统在速度/ 能源权衡前沿上的运行位置。因此,系统设计、消除非 GPU 瓶颈以及调整用例、内存和并行性的批量大小是优化能耗和每瓦吞吐量的关键手段。
优化 LLM 训练的能效
大型模型训练需要使用多种并行化方法的组合在多个 GPU 上分配工作。在训练过程中,推动最大迭代速度的代价是巨大的能耗。
此外,单个 GPU 工作负载分配并不完全均衡,导致多个 GPU 处于空闲状态,而很少有 GPU 完成计算。如果所有 GPU 都跑到终点来完成一项任务,却只坐着等待其他人完成任务并同步,那么就会浪费精力。
密歇根大学 ML.ENERGY 计划 的研究人员已经表明,调整单个 GPU 的处理速度可以 减少大型模型训练中的能量膨胀。工作较多的任务处于关键路径 (工作流中最慢的任务链) 并以最高速度运行,而工作较少的任务会有意减慢速度。
这将实现以下目标:
- 更大限度地减少 GPU 提早完成的空闲时间
- 以较低速度运行的 GPU 消耗更少的能源
- 端到端训练时间保持不变
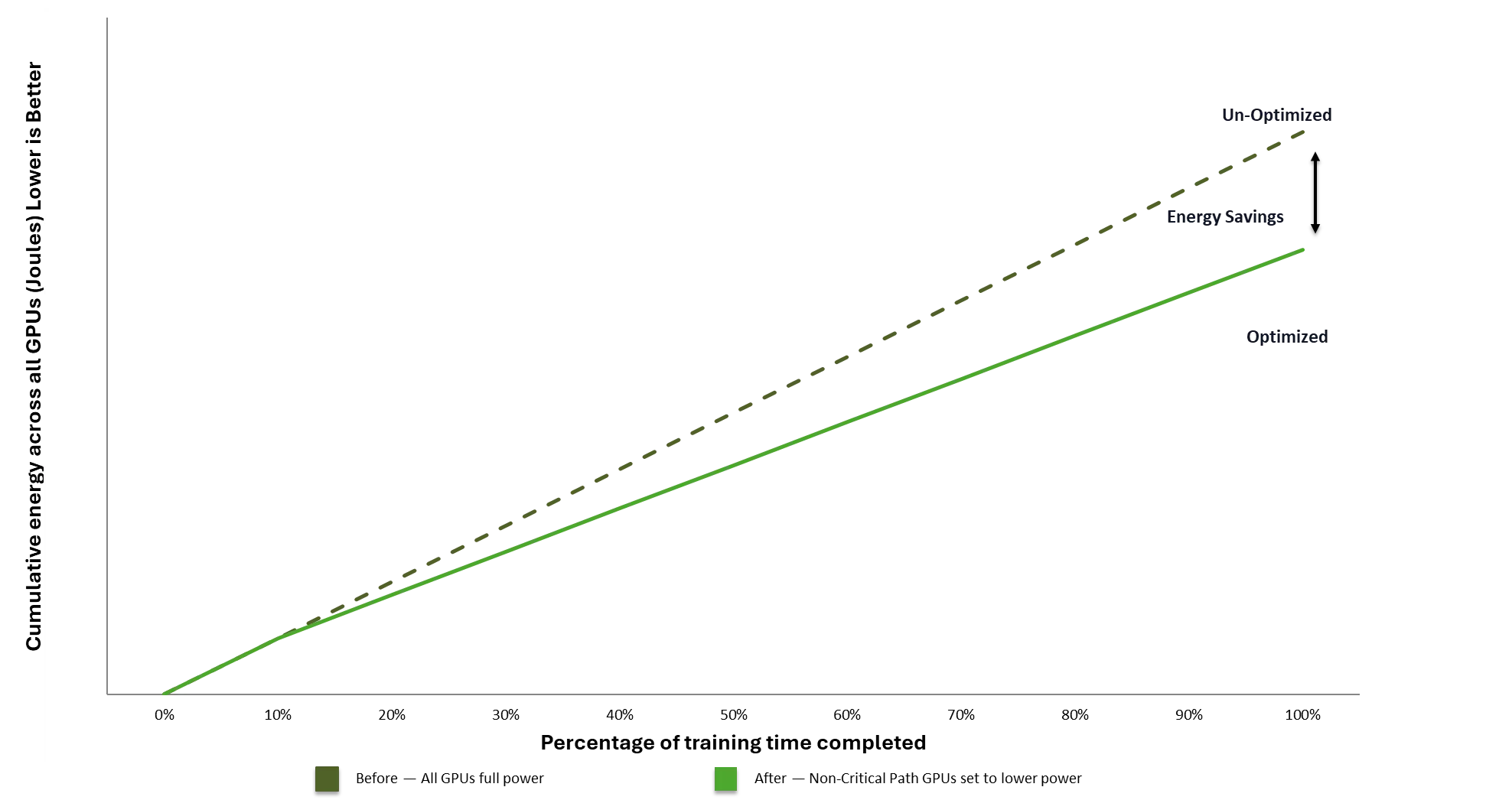
图 2. 协调 GPU 速度调整可降低总训练能耗,几乎不影响端到端训练时间,从而释放出更多功率用于额外的训练或推理
Megatron-LM 是用于训练大规模语言模型的 NVIDIA 开源参考实现。NVIDIA 与 ML.ENERGY 团队合作,通过在内核、调度和并行级别分析功耗和性能行为,然后使用这些测量结果来指导有针对性的能源感知优化,继续提高 Megatron-LM 训练的能效。
这项工作包括:
- 实施精细的细粒度内核和相位能量分析,以识别计算、内存、通信和功率受限区域
- 分析并行性配置、工作流不平衡和通信重叠如何影响性能每瓦
这些见解用于设计能源感知调度和 GPU 频率/ 功耗上限调整,使其与训练迭代的真正关键路径 (管道中最慢的任务链) 保持一致。下一步是概述如何将这些技术应用于更大规模的 Megatron-LM 训练。
这项工作旨在提高能效,以便在相同的功率范围内更快地完成模型训练,或以更低的能耗实现相同的训练吞吐量。因此,功率可以重定向到额外的训练运行,或从训练到在相同的优化基础设施上进行推理,从而在不提高站点总功率的情况下增加 token 生成。如需了解更多信息,请参阅 Kareus:在大模型训练中联合减少动能和静态能量。
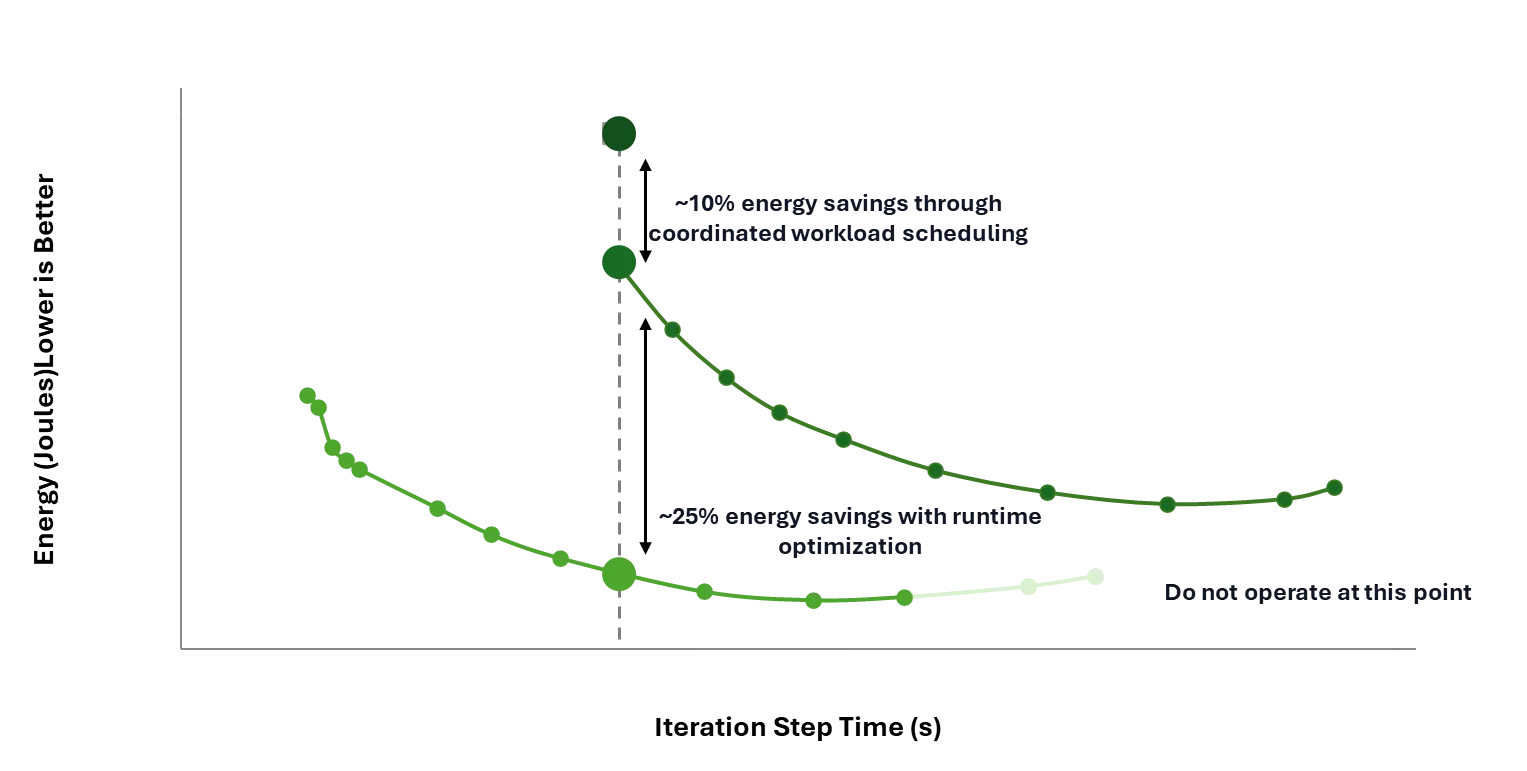
图 3. 能源感知型调度和运行时优化可将训练转移到更高能时的帕累托边界,在类似的迭代步骤时间下可节省约 25% 的能源
NVIDIA DSX 如何优化 AI 工厂性能?
ML.ENERGY Initiative 开发了用于分享测量结果的排行榜和基准,以及用于解释观察特定能量行为原因的推理框架。
这些基准测试可以与能源感知操作 (遥测驱动的系统) 相关联,展示如何在实际部署限制 (包括电力成本、碳强度、散热、冷却能力和电网限制) 下运行 AI 工厂。
NVIDIA DSX 提供这些能源感知操作。该平台提供了涵盖计算、机架、冷却、设施电力和工作负载调度的协调视图。它提供了一个通用的操作架构,可以将设计时模拟与运行时遥测连接起来,帮助操作员了解功率的使用位置、受困位置,以及在固定站点范围内可容纳的额外有用计算量。
DSX 定义了如何在整个堆栈中设计、构建和优化 AI 工厂,从芯片和系统到基础设施软件、设施、数字孪生和合作伙伴技术。它将开放软件库、工作流程指南和参考设计与 NVIDIA 计算平台和共同设计的 OEM 基础设施相结合,以实现广泛的软件和硬件解决方案生态系统。
通过通用架构对齐每一层,DSX 可提高每瓦 token 数,加速部署,并增强运营可靠性和弹性。
DSX 可管理机架内、AI 工厂层面以及 AI 工厂和电网之间的能效和行为。DSX MaxLPS 在 AI 工厂内部运行,而 DSX Flex 在电网和工厂之间运行。
DSX MaxLPS 是一套可更大限度地提高 AI 工厂吞吐量的技术,包括:
- 45°C 液冷:通过利用集成芯片、散热和系统级创新,运营商可以利用较高的 45°C 入口温度来提高电力使用效率 (PUE) ,确保将更大一部分 AI 工厂电力重新引导到创收计算上。
- 动态功耗分配:软件会持续监控 GPU 和机架级功耗,并在需要时进行重新分配,以解锁受限容量并优化整体利用率。它在规定的功率预算内运行,实时适应预算变化,并确保安全、合规的执行。
- 先进技术:先进方法直接集成到 NVIDIA GPU 中,可提高等值性能下的每瓦性能。其中包括动力转向、用于快速 GPU 配置的优化工作负载配置文件,以及用于编排机架间功率和性能优化的 NVIDIA Dynamo 等软件。
DSX Flex 是电网感知型电源编排层,可将 AI 工厂连接到电网信号和外部能源。
经过优化的端到端电力、冷却和电网集成可以将注意力转移到从工作负载本身中获得最大效率上。
关键的机会是使用基准来指导在优化的 AI 工厂上选择模型、批处理和精度。通过将工作负载放置、调度和电源分配与最高效的计算和冷却区保持一致,运营商可以在基础设施级收益的基础上进行工作负载级优化。
这包括在固定功耗预算下重新平衡工作负载,确定可以通过更高效的配置或模型系列降低功耗的工作负载,并优先考虑支持更高功率预算的工作负载,因为这些工作负载会增加每个 token 的收入。在此过程中,我们不断引导 AI 工厂实现每瓦最大 token 数,从而逐渐降低每个 token 的成本。
展望未来,AI tokenomics 指标应被视为一流的设计目标。团队应探索如何将数字生驱动的基础架构优化与数字生驱动的基础架构优化与基准驱动的工作负载调优相结合。
这种方法将受限功率转化为令牌容量和收入方面的专门竞争优势。
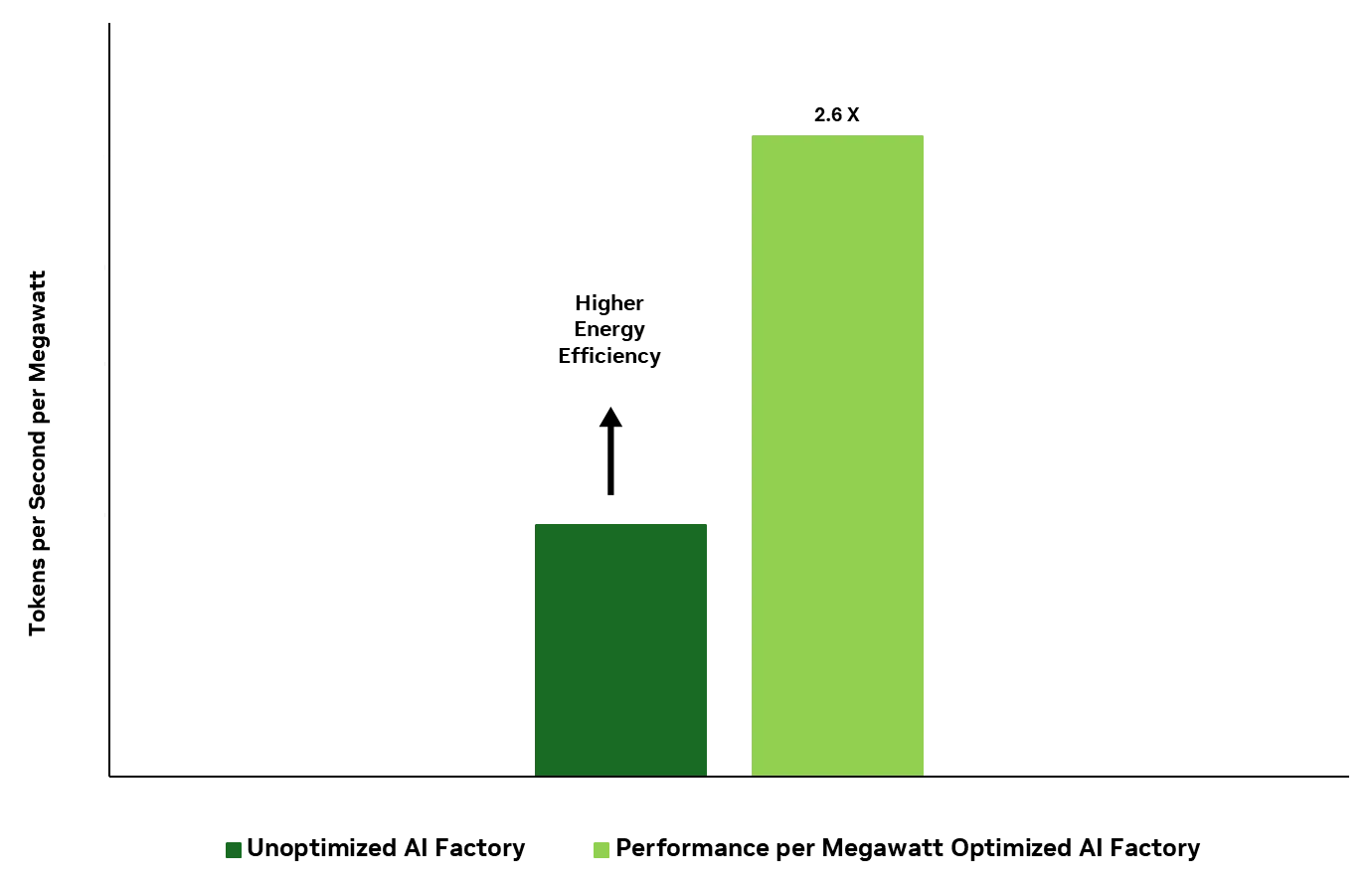
图 4. 在目标交互性方面,经优化的每兆瓦性能 AI 工厂每秒可提供的 token 数量比未经优化的 AI 工厂高出 2.6 倍
了解详情
AI 工厂从根本上受到功耗的限制,因此每瓦性能成为决定 token 成本和盈利能力的关键驱动因素。优化推理至关重要,因为它可以通过更高的 token 输出直接增加收入,同时硬件、软件和模型设计的全栈改进可以提高效率。
此外,还可以通过减少 GPU 空闲时间,在不影响速度的情况下提高训练的能效。NVIDIA DSX 可实现跨基础设施的实时能源感知优化,更大限度地提高每瓦 token 和每兆瓦收入。
如需详细了解功耗受限的 AI 工厂设计、仿真、运营和 NVIDIA DSX,请在 ISC 2026 上参观 NVIDIA 展台。
致谢
我们要感谢来自密歇根大学 ML 能源计划的 Mosharaf Chowdhury、Jae-Won Chung 和 Ruofan Wu 所做的贡献。