
NVIDIA CUDA 13.3 为整个 CUDA 生态系统的开发者带来了新功能和性能优化。通过在 C++ 中引入 NVIDIA CUDA Tile 编程,支持基于 Tile 的高级内核开发,能够自动管理复杂的底层 GPU 细节,从而实现卓越的性能和可移植性。此外,CUDA Tile 编程现在不仅支持所有其他已支持的 GPU 架构,还新增了对计算能力 9.0(NVIDIA Hopper)GPU 的支持。
我们还将发布 CUDA Python 1.0,巩固 CUDA Python 软件生态系统的支持和稳定性,并引入绿色上下文和进程检查点等关键功能。
对于性能爱好者来说,新推出的 NVIDIA CompileIQ 编译器自动调优框架可在 GEMM 和注意力等关键内核上实现最高达 15% 的性能提升。本次发布还在 NVCC 中正式支持 C++23,在 CCCL 3.3 中增强了与 DLPack/mdspan 的张量互操作性,并对数学库(cuBLAS、cuSPARSE、cuSOLVER)以及分析工具(Nsight Compute 和 Nsight Systems)进行了大量更新。
发布 CUDA Tile C++
随着 CUDA 13.3 的发布,CUDA Tile 的支持已扩展至 C++,使现有的大型 C++ 代码库和开发者能够构建高度优化的 GPU Tile 内核。该模型可自动处理并行计算、内存移动、异步操作等底层细节,生成可在 NVIDIA GPU 架构上移植的 C++ 代码。欲了解更多信息,请查看我们的博客文章。
CUDA Python 1.0 版本发布
CUDA Python 是一组将 CUDA 应用于 Python 编程语言的库。通过提供 1.0 版本,我们致力于语义版本控制:确保仅在主要版本发布期间中断 API 更改。次要版本增加功能,补丁版本则是问题修复。计划移除的任何公共 API 首先会在具有明确替换路径的次要版本中弃用。
以下是有关 CUDA Python 1.0 中包含的软件组件的更多信息。
| 库 | 说明 | 下一个主要版本 |
cuda.binding |
与 CUDA C API 的低级 Python 绑定。 | 13.3.0 |
cuda.core |
对 CUDA 运行时和其他核心功能的 Python 式访问 | 1.0.0 |
cccl-cuda |
以 Python 方式访问 CCCL 并行算法,并轻松访问 CCCL 高效且可定制的并行算法 | 1.0.0 |
cuda-pathfinder |
用于查找用户 Python 环境中安装的 CUDA 组件的实用程序 | 1.6 |
cuda.coop 也可在 cuda-cccl 软件包的 _experimental 命名空间下找到,该命名空间可能随 API 的变化而调整。cuda.coop 提供了可在 Numba CUDA 内核中使用的、适用于块级别和线程束级别的可复用设备原语。
cuda.core 现已稳定
cuda.core 提供 CUDA 运行时的 Python 接口,包括设备、流、程序、连接器、内存资源和图形。版本 1.0 将在之前的发布周期中保持稳定的 API 整合到一个受支持的界面中。同时,我们增加了对绿色上下文、CUDA 检查点等的支持。
- 绿色上下文: 将 GPU 的 SM 划分为互不重叠的分区,每个分区拥有独立的上下文和流,从而确保在同一进程中,延迟敏感型内核不会受到长时间运行的吞吐量型内核的影响。
- 进程检查点: 对正在运行的进程的完整 CUDA 状态(包括设备分配、流和上下文)进行快照,并支持后续恢复。实现类似 CRIU 的 GPU 进程工作流,支持容错的长时间作业、共享集群中的抢占与迁移,以及快速预启动推理任务。仅限 Linux 系统使用。
- 进程间共享(IPC): 无需经过主机复制,即可在 Python 进程间共享 GPU 显存。一个进程负责分配显存,其他进程则可将同一块物理显存映射到自身的地址空间中。非常适合用于多进程机器学习服务以及零复制的生产者/消费者工作流。
以下是如何使用 cuda.core API 的简单示例。
from cuda.core import Device, Stream, Program, ProgramOptions, LaunchConfig, launch# pick and activate a GPUdev = Device()dev.set_current()# create a CUDA streamstream = dev.create_stream()# NVRTC compile + lookupprog = Program(src, code_type="c++", options = ProgramOptions(arch=f"sm_{dev.arch}"))kernel = prog.compile("cubin").get_kernel("my_kernel") # launch a kernellaunch(stream, LaunchConfig(grid=64, block=256), kernel, *args)# JIT-LTO linkingfrom cuda.core import Linker, LinkerOptionsmodule = Linker( [obj1, obj2], options=LinkerOptions(arch=f"sm_{dev.arch}")).link("cubin")# NVRTC precompiled headersfrom cuda.core import ProgramOptionsopts = ProgramOptions(std="c++17", arch=f"sm_{dev.arch}", create_pch=True, pch_dir="/tmp/pch")# Memory resources, incl. NUMA-aware poolsfrom cuda.core import DeviceMemoryResource, PinnedMemoryResource, PinnedMemoryResourceOptions, ManagedMemoryResource, ManagedMemoryResourceOptions# NUMA-pinned host memorypinned = PinnedMemoryResource(PinnedMemoryResourceOptions(numa_id=0))# CUDA graphs: stream capture and explicit construction from cuda.core.graph import GraphBuilder, GraphDefgb = stream.create_graph_builder()gb.begin_building()graph = gb.end_building().complete()graph.launch(stream)gdef = GraphDef()gdef.add_kernel_node(kernel, LaunchConfig(grid=64, block=256), args=args)# IPC: share GPU memory across Python processesfrom cuda.core import DeviceMemoryResource, DeviceMemoryResourceOptionsmr = DeviceMemoryResource(dev, options=DeviceMemoryResourceOptions(max_size=1 << 20, ipc_enabled=True))buffer = mr.allocate(nbytes) # buffer is picklable and can be sent over mp.Queue# Green contexts: partition SMs into disjoint groupsfrom cuda.core import ContextOptions, SMResourceOptionssm = dev.resources.smlong_grp, crit_grp = sm.split(SMResourceOptions(count=(sm.sm_count - 16, 16)))[0]ctx_crit = dev.create_context(ContextOptions(resources=[crit_grp]))s_crit = ctx_crit.create_stream()# Process checkpoint / restore (Linux)from cuda.core import checkpointproc = checkpoint.Process(os.getpid())proc.lock(timeout_ms=5000)proc.checkpoint()proc.restore()proc.unlock()# device allocations and context are restored# TMA / TensorMapDescriptorfrom cuda.core import StridedMemoryView, TensorMapDescriptortmap = StridedMemoryView(tensor).as_tensor_map(box_shape=(128,))# DLPack-friendly strided viewsfrom cuda.core.utils import StridedMemoryViewview = StridedMemoryView(torch_tensor); capsule = view.__dlpack__()# System info (NVML)from cuda.core import systemprint(system.num_devices, system.driver_version)# cuda.bindings.nvmlfrom cuda.bindings import nvmlnvml.init()name = nvml.device_get_name(nvml.device_get_handle_by_index_v2(0))# cuda.bindings.nvfatbinfrom cuda.bindings import nvfatbinhandle = nvfatbin.create() |
CCCL Python 版本 1.0.0:cuda.compute
cuda.compute 将 CUDA 核心计算库 (CCCL) 高度优化的并行算法 (排序、扫描、归约、转换、唯一、直方图、top-k 等) 引入 Python,作为可主机调用的构建块。自上一个版本以来的变化包括:
- Python lambda 可用作算法运算符,简化用于简单归约、扫描、转换和谓词的样板文件。
- 算法支持具有副作用 (状态) 的运算符,支持运行累加器和条件转换等用例。
- 新的
cuda.compute.upper_bound和cuda.compute.lower_boundAPI 将 CUB 的并行二进制搜索公开给 Python。 - 整合所有算法的缓存,实现更快的重复调用。
import cuda.computefrom cuda.compute import OpKindd_input = cp.arange(1, 1_000_001, dtype=cp.int32)d_output = cp.empty(1, dtype=cp.int32)h_init = np.array([0], dtype=np.int32)cuda.compute.reduce_into( d_input, d_output, OpKind.PLUS, d_input.size, h_init)cuda.compute.reduce_into( d_input, d_output, lambda a, b: a if a > b else b, d_input.size, h_init,) |
cuda.coop 公开了 CCCL 的线程束范围和块范围的协作基元,以供在 Numba CUDA 内核中使用。目前,此模块位于 _experimental 命名空间下,可能会有不遵循语义版本控制的 API 更改。
from numba import cudafrom cuda.coop._experimental import block, warpTHREADS = 128block_sum = coop.block.make_sum(numba.int32, THREADS)@cuda.jit(link=block_sum.files)def reduce_kernel(data, out): # Each thread contributes one element to the block-wide reduction total = block_sum(data[cuda.threadIdx.x]) if cuda.threadIdx.x == 0: out[0] = totalh_in = np.ones(THREADS, dtype=np.int32)d_in = cuda.to_device(h_in)d_out = cuda.device_array(1, dtype=np.int32)reduce_kernel[1, THREADS](d_in, d_out)assert d_out.copy_to_host()[0] == THREADS # 128 |
新的 Numba CUDA MLIR 后端
Numba CUDA MLIR 是一个兼容 Numba 的新 Python 内核生成器,基于 MLIR 和现代 NVVM 工具链从头开始编写。它保留了 Numba-CUDA 中熟悉的 @cuda.jit 编程模型,同时提供更低的编译延迟、更好的诊断,以及更清晰的路径,以便在新的 GPU 架构和功能登陆 NVVM 堆栈时将其作为目标。只需替换导入语句,即可将 Numba CUDA MLIR 用作 numba.cuda 的直接替代品:
# Beforefrom numba import cuda# Afterfrom numba_cuda_mlir import cuda@cuda.jitdef vector_add(a, b, out): i = cuda.grid(1) if i < out.shape[0]: out[i] = a[i] + b[i] |
除了现有的 Numba-CUDA 兼容性之外,Numba CUDA MLIR 还具有以下特性:
- 加快 JIT 编译速度. 在一组真实内核(向量加法、softmax、Cholesky、注意力、Black-Scholes、FFT、matmul)中,与 Numba-CUDA 相比,热 JIT 在 geomean 上的编译速度提升 1.4 倍,在单个内核上的编译速度最快提升 2 倍。
- 降低启动延迟. 主机端内核的调度开销减少了约2至3.5倍;对于包含大量标量参数的内核,开销减少了约17倍,此前参数打包是主要开销来源。
您可以从 PyPI numba-cuda-mlir[cu13] 安装 Numba CUDA MLIR 0.3,然后在 GitHub 上关注其开发过程。
立即试用 CUDA Python
直接从 PyPI 安装 CUDA Python 堆栈:
pip install cuda-python cuda-cccl numba-cuda-mlir[cu13] |
这将提取 cuda.bindings 13.3.0、cuda.core 1.0.0、cuda.compute 1.0.0 以及 cuda-pathfinder,用于库发现。
CompileIQ 已启动
名为 CompileIQ 的新编译器自动调整框架可在 GPU 内核上实现最高性能,该框架随 CUDA 13.3 一起启动。GPU 编译器会应用通用优化启发式方法,这些方法广泛有效,但不一定适合特定内核。CompileIQ 使用进化和遗传算法来生成针对每个内核定制的专业编译器配置,从而颠覆这种动态变化。
这样可以释放额外的性能。例如,对于占 LLM 推理计算 90% 以上的关键算子,如 GEMM 和注意力机制,CompileIQ 能在已优化的 Triton 注意力和 CUTLASS GEMM 算子基础上,实现最高达 15% 加速。阅读这篇博客文章,深入了解 CompileIQ 的工作原理及使用方法。
数学库
CUDA 13.3 中的核心 CUDA 数学库包含一些新功能和显著的性能改进,包括:
- cuSPARSE:
- SpSV 和 SpSM 中对 CSC 格式的支持。
- SpMVOp 中对混合精度的支持。
- 在 SpMvOp 计算中支持混合索引类型 ( 64 位偏移量、32 位索引) CSR 矩阵
- 改进
cusparseSpMVOp_createDescr()性能提升 2.5 倍。 - 推出新的 API SPMVOP_ALG1,支持:
- 更新矩阵值,同时保持相同的稀疏模式。
- 优化缓冲区大小。
- 减少预处理用度。
- cuBLAS:
- CUDA 绿色上下文支持。
- NVIDIA Blackwell Ultra 上的 FP4 matmuls 性能得到提升。
- NVIDIA Blackwell 和 Blackwell Ultra 上 TF32 matmuls 的性能提升。
- NVIDIA Hopper、Blackwell 和 Blackwell Ultra 的 SYMV 性能提升。
- 通过在问题空间中强制实施固定的工作空间大小,改善了 FP64 模拟 matmuls 的用户体验。
- cuSOLVER:
- 64 位接口
cusolverDnXpolar公开用于 cuSOLVERDn 中极性分解的 QDWH 算法实现 - 64 位接口
cusolverDnXstedc,该函数使用 divide and conquer 方法计算对称三对角线矩阵的特征值 (可选) 和特征向量 - 通过将特征向量后处理从主机移动到设备,
cusolverDnXgeev的性能提升获得特征向量。
- 64 位接口
- 公共 64 位接口
cusolverDnXpolar,用于在 cuSOLVERDn (在 13.2 U1 中提供) 中公开极分解的 QDWH 算法实现。 - 公共 64 位接口
cusolverDnXstedc:使用 divide and conquer 方法计算对称三对角线矩阵的特征值 (可选) 和特征向量 (在 13.2 U1 中提供) 。 - 通过将特征向量后处理从主机移动到设备,提高了使用特征向量的
cusolverDnXgeev的性能。 cusolverDn[D,Z]syevj使用低精度预处理,对于 B200 上的大中型矩阵,通常可将求解时间缩短 20%,而在 FP32:FP64 比率较大的 GPU 上,求解时间甚至会缩短 20%。
CCCL
CUDA 13.3 随附 CCCL 3.3。亮点包括 DLPack/mdspan 互操作性、全面的随机数分布库、新的搜索和分段扫描算法,以及灵活的 N-to-M 转换。
张量互操作性
深度学习框架使用张量,但 CUDA C++ 代码通常需在更低层级运行,涉及原始指针、形状、步长以及手动编写的索引。借助 CCCL,可以更轻松地在 Python 框架与 CUDA C++ 之间保留张量结构。通过 DLPack 互操作性,可使用 cuda::to_device_mdspan 将来自 PyTorch、JAX 和 CuPy 等框架的张量转换为 cuda::std::mdspan 视图,以便在 C++ 内核中使用,并使用 cuda::to_dlpack_tensor 将 cuda::std::mdspan 视图转换回 DLPack。
CCCL 还通过 cuda::shared_memory_mdspan 将该张量视图模型扩展至内核中。开发者无需再将共享内存视为平面缓冲区,而可以在共享内存图块上创建多维视图,使索引更加清晰,降低出错概率。此外,共享内存专用机制还提供地址空间的安全检查,并确保共享内存的加载/存储指令正确执行。
随机数分布
CCCL 3.3 为 <cuda/std/random> 添加了一整套设备兼容的随机分布,使 libcu++ 几乎与 C++ 标准库的 <random> 头文件功能相当。CCCL 3.3 提供了完整的 17 种随机分布,包括均匀分布、正态分布、泊松分布和伯努利分布。此外,CCCL 3.3 将 cuda::std::philox4x32 和 cuda::std::philox4x64 引擎从 C++26 向后移植至 C++17,并将 cuda::pcg64 作为 <cuda/random> 的扩展加入。PCG64 是 NumPy 中的默认 PRNG,在随机数质量和性能之间实现了良好平衡。
#include <cuda/random>#include <cuda/std/random>__global__ void sample_kernel() { cuda::pcg64 rng(threadIdx.x); cuda::std::normal_distribution<float> dist(0.0f, 1.0f); float sample = dist(rng);} |
搜索:cub::DeviceFind::FindIf
CCCL 3.3 添加了 cub::DeviceFind::FindIf,这是一种新的光速全设备搜索算法,用于查找满足谓词的第一个元素。
cub::DeviceFind::FindIf( d_temp, temp_bytes, input, output, [] __device__ (int value) { return value > 42; }, num_items); |
与 CCCL 3.2 中使用的搜索实现相比,该算法可将速度提升高达 7 倍,并加速 Thrust 的搜索和谓词查询算法,包括 thrust::find_if、thrust::all_of、thrust::any_of、thrust::none_of、thrust::equal、thrust::mismatch、thrust::is_sorted、thrust::partition_point 等。
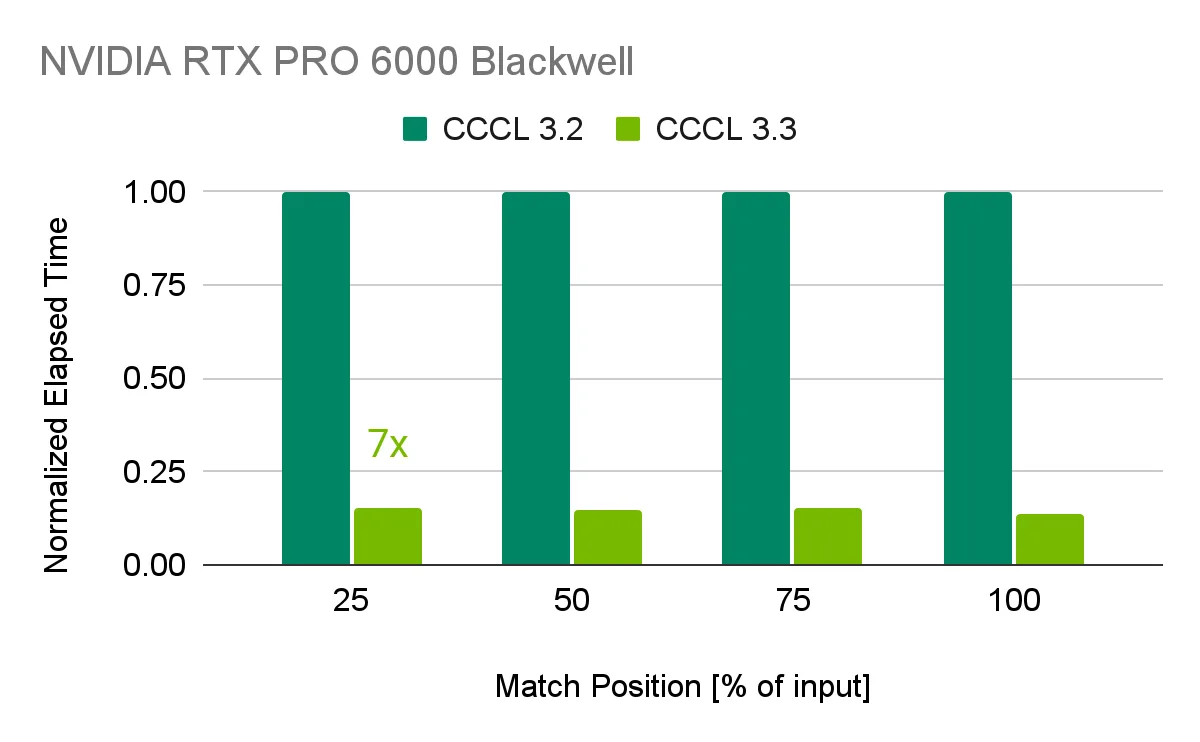
thrust::find_if 的标准化执行时间CCCL 3.3 中的更多新算法包括:
- 分段扫描:
cub::DeviceSegmentedScan提供并行扫描的分段版本,可高效计算多个独立段的扫描运算。 - 二进制搜索:
cub::DeviceFind::LowerBound/UpperBound对有序序列中的多个值执行并行搜索。 - Transform:
cub::DeviceTransform现在支持将 N 个输入序列转换为 M 个输出序列。
编译器/ NVCC
C++ 23 支持:nvcc 和 nvrtc 中完全集成 C++ 23,使开发者能够使用最新的语言标准。此版本实现了 CUDA 开发体验的现代化,确保代码库与现代标准保持一致,同时显著提高了跨平台可移植性。
- 增强的
nvrtc开箱即用体验:通过捆绑标准 CUDA C++ 头文件,NVRTC 可简化运行时编译流程并减少必备设置。此更新简化了包含路径管理,从而能够更快地实现可移植且强大的运行时编译工作流。 nvcc中集成的 nvprune:直接在编译器中包含剪枝功能,可实现更高效的构件管理和简化的多架构部署。
更多 CUDA 13.3 增强功能
本节将详细介绍 CUDA 13.3 中的更多增强功能。
MPS 部分错误隔离
MPS 现在支持部分错误隔离。启用该功能后,CUDA 驱动程序能够识别出发生错误的分区或客户端,并仅终止该客户端的任务,而其他分区中未引发错误的客户端将继续正常运行。有关如何使用此功能的详细信息,请参阅版本说明。
将图形重新捕获到现有图形中
在 CUDA 计算图中,新的 API cudaStreamBeginRecaptureToGraph() 允许您在现有的源计算图中启动流捕获。重新捕获图形时,现有节点中任何已更新的节点参数都将被同步更新。
在绿色环境中,默认流创建是可选的
CUDA 驱动程序 API 中使用的绿色上下文不再需要通过 CU_GREEN_CTX_DEFAULT_STREAM 标志创建默认 (NULL) 流。创建此流现在是可选的。
NVML 报告非活动的重映射行
新的 NVML API nvmlDeviceGetRemappedRows_v2 可以获取非活动行重映射的数量,而旧 API nvmlDeviceGetRemappedRows 现在仅返回活动行重映射的数量。
新增了对 mmap() 的支持
此版本增强了对 mmap() 的支持,可在无法安装 GDRCopy 内核驱动程序的环境中,实现对独立 GPU 显存的低延迟 CPU 映射。
开始使用
致谢
感谢 NVIDIA 贡献者 Andy Terrel、Rob Armstrong、Jackson Marusarz、Becca Zandstein、Mridula Prakash、Daniel Rodriguez 和 Georgii Evtushenko。