
冷启动问题
在生产环境中的推理部署里,需求会随时间波动,因此推理副本需要弹性扩缩容。然而,在 Kubernetes 上冷启动推理工作负载可能需要几分钟。在这段时间里,GPU 已被分配却处于空闲状态,既不生成任何 token,也不处理任何请求。
这种延迟会增加在流量激增期间违反服务级别协议(SLA)的风险,因为系统无法足够快地扩展以吸收需求的突然增加。
对于单 GPU 的 vLLM(v0.20.0)工作负载,冷启动延迟可分解如下:
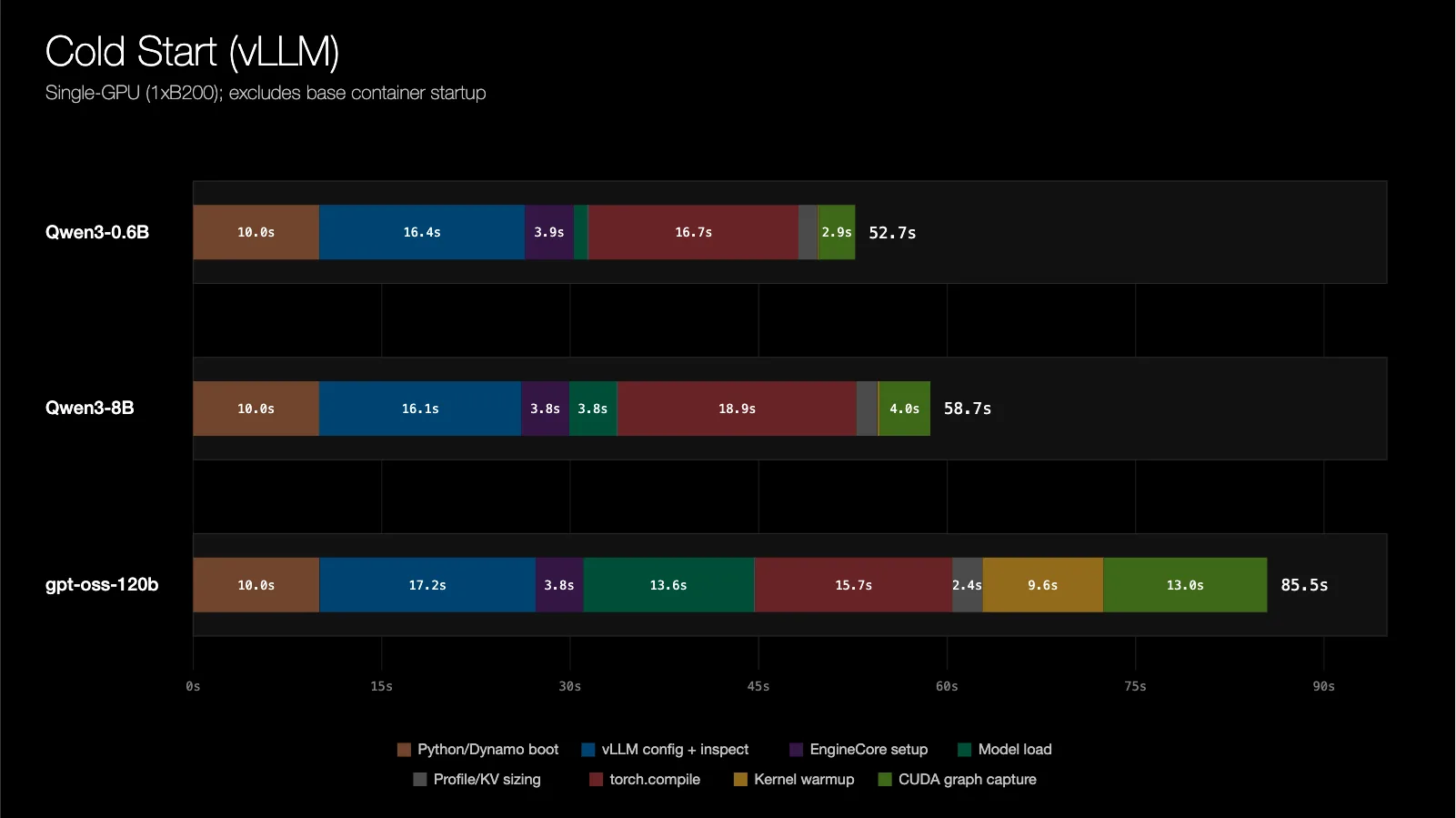
为了大幅缩短启动时间,我们推出了 NVIDIA Dynamo Snapshot,这是针对 Kubernetes 上 AI 推理工作负载的检查点与恢复解决方案。本文介绍了早期原型背后的设计决策和优化方法,该原型在单 GPU 工作负载下实现了接近瞬时的启动速度。
这是 Dynamo 快速启动系列的第一篇文章。
CRIU 和 cuda-checkpoint
正在运行推理工作器的可检查点状态有两个组成部分:
- 设备状态(GPU 侧):包括 CUDA 上下文、流、设备内存、虚拟地址映射等,在宿主机上不可见。为序列化该状态,我们利用 CUDA 驱动提供的检查点功能(也可通过
cuda-checkpoint命令行工具访问),将设备状态转储至拥有各 CUDA 上下文的进程的 CPU 内存中。如需了解更多,请参考 CUDA 驱动的检查点功能(也可通过 tz_0 命令行工具访问)。 - 主机状态(CPU 侧):包括 CPU 内存、线程、文件描述符、命名空间等。Linux 内核具备序列化该状态所需的全部账本信息。我们利用开源工具 CRIU(用户态检查点/恢复)遍历 Linux 内核的账本信息,并将进程树的状态保存到磁盘。
这两个工具可以很好地组合起来,以支持对完整推理工作线程状态进行检查点/恢复。在进行检查点时:
cuda-checkpoint将所有设备状态转储到 CPU 内存中。- CRIU 将所有宿主机侧进程树状态转储到存储中的一个文件夹。
恢复时(同一节点或不同节点):
- CRIU 会根据来自 NFS/SMB 等分布式存储的序列化状态恢复进程树,从而使我们能够从另一台节点获取已检查点的工件。
cuda-checkpoint将 CPU 内存中序列化的 GPU 状态恢复到新的 GPU 上。
CRIU 本质上是一种冻结再解冻机制。当一个进程被恢复时,执行会从它被检查点保存时的那条精确指令继续,完全不知道曾经发生过检查点保存或恢复。
因此,任何在检查点保存之前所需的协调,例如使工作负载静止,或在恢复之后所需的协调,例如重新建立外部状态,都必须通过编排器或特定于工作负载的钩子在外部处理。我们将在以下各节中描述这些机制。
Dynamo 快照:Kubernetes
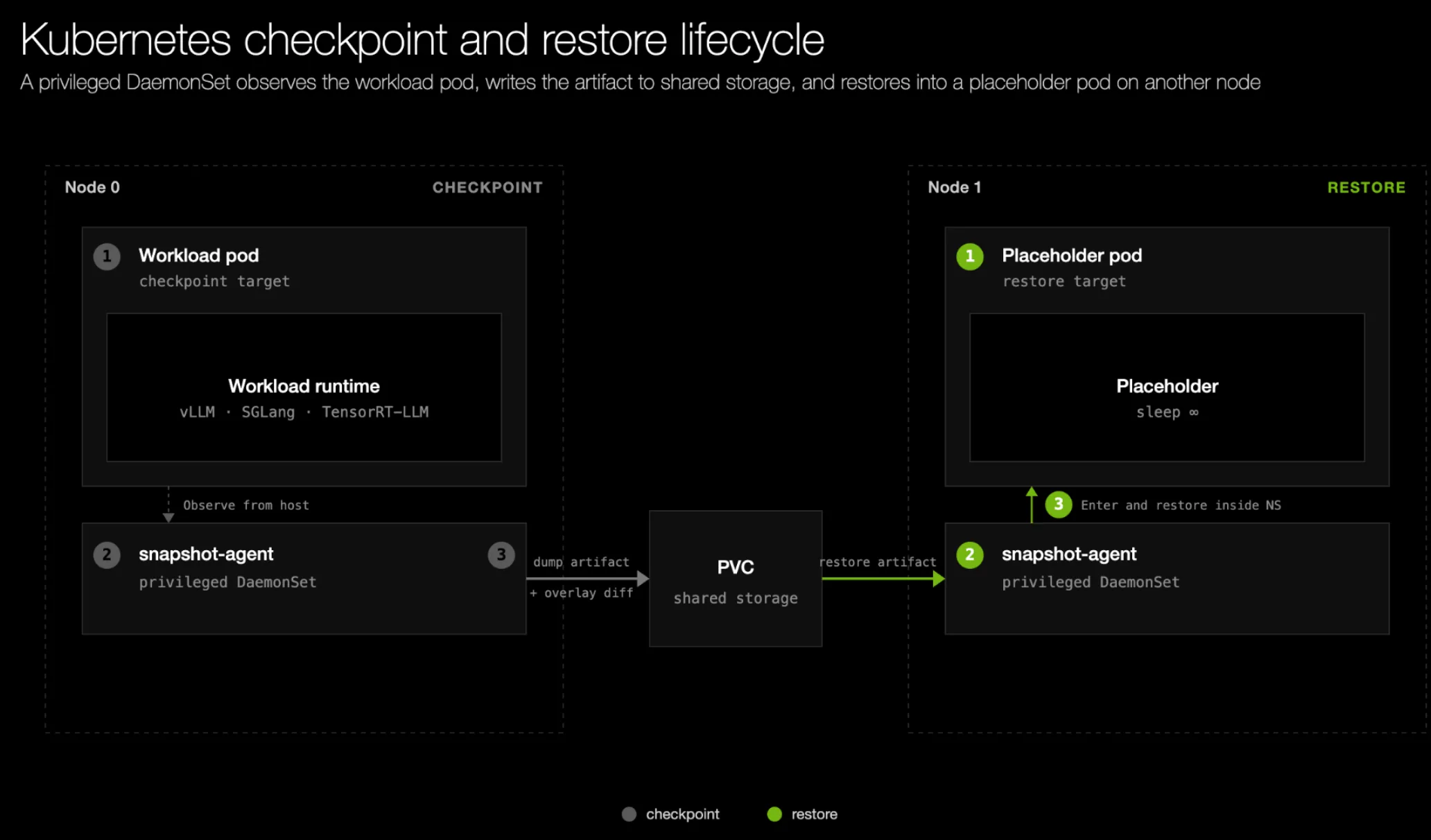
在 Kubernetes 中,工作负载运行在 Pod 内的容器里。由于 CRIU 检查点包含对容器可写文件系统层的引用,因此我们在容器级别进行检查点,以便进程树状态和文件系统一起迁移。
我们提供一个具备特权的 DaemonSet,名为 snapshot-agent,可通过 Helm chart 安装。一个代理会运行在每个节点上,并负责为由 runc 管理的容器进行检查点和恢复,而无需对 runc 本身进行修改。
在检查点时,代理会等待工作负载的就绪探针,然后在写入制品到共享存储之前,从主机侧调用 cuda-checkpoint 和 CRIU。工作负载可能已经创建或删除了容器本地的文件(即覆盖文件系统中的文件),代理还会在 CRIU 阶段之后对这些文件进行检查点。
恢复时,代理会启动一个轻量级占位 Pod,恢复覆盖文件系统,并将 CRIU/CUDA 检查点恢复到其命名空间中。随后,已恢复的工作进程接管执行。
每个代理都在其本地节点上独立运行,因此检查点和恢复可以在整个集群中自然并行化。我们构建这一方案,而不是依赖 runc 中 Kubernetes 原生的检查点/恢复支持,后者同样委托给 CRIU。DaemonSet 方法具有完全的可移植性,并且不依赖云提供商对检查点/恢复功能开关的支持。
这也让我们在性能调优方面对 CRIU 有更严格的控制,并允许检查点工件存放在灵活的存储后端中,而不是嵌入到 OCI 镜像里。
Dynamo 快照:工作负载
一个 Dynamo 推理工作器分两个阶段启动:
- 引擎初始化:已启动配置的推理引擎:已初始化通信器,已加载权重,已预热内核,已编译/捕获图等。在此阶段结束时,worker 已完全预热。它可以处理请求,但对其自身 pod 之外的任何对象来说仍不可发现。
- 分布式运行时启动:worker 连接到 Dynamo 控制平面,并在发现后端中注册自身,以便 router 和图中的其他部分能够找到它。从这一刻起,worker 就处于“live”状态——与控制平面之间存在开放连接,并且集群中的其他组件都已知晓这个 worker 的 pod 标识。
如果我们要天真地实现检查点/恢复,而让工作负载不知道自己正在被检查点化,那么检查点作业的就绪探针将对应于一个完全初始化、已注册到发现平面的分布式运行时,这意味着存在 CRIU 无法捕获的活动 TCP 连接。
解决这个问题的一般模式是 quiesce/resume 钩子:工作负载确保自身处于静止状态,并阻塞在一个外部信号上,当恢复完成时该信号会触发。这是 checkpoint/restore 的一种强大抽象,因为:
- 它允许工作负载在被检查点保存之前清理其资源,从而优化最终的检查点大小(并因此减少恢复时间)。
- 它允许工作负载在恢复后重新创建无法检查点保存的资源。这对于多 GPU 和多节点检查点尤其重要(计划在未来版本中支持):用于 RPC 的出站 TCP 连接无法在已建立状态下进行检查点保存,因为 Pod IP 会在检查点和恢复之间发生变化,而且 RDMA 注册和 NIC 状态在恢复后也需要重新创建。
在 Dynamo Snapshot 中,我们通过将就绪探针定义为存在一个“已准备好进行检查点”的信号文件来实现这些钩子。工作进程会在引擎初始化之后、分布式运行时启动之前写入该文件。
在这一时刻,worker 会进入一个轮询循环,等待一个单独的“恢复完成”信号文件,而 snapshot 代理会在外部对它进行检查点处理。检查点可以发生在该轮询循环中的任意指令处。
因为 CRIU 会在执行到发生 checkpoint 时的确切指令处恢复执行,worker 会直接在轮询循环内继续运行,检测到信号文件后,便在不需要额外同步的情况下继续进行分布式运行时初始化。
优化 #1:KV 缓存取消映射并释放
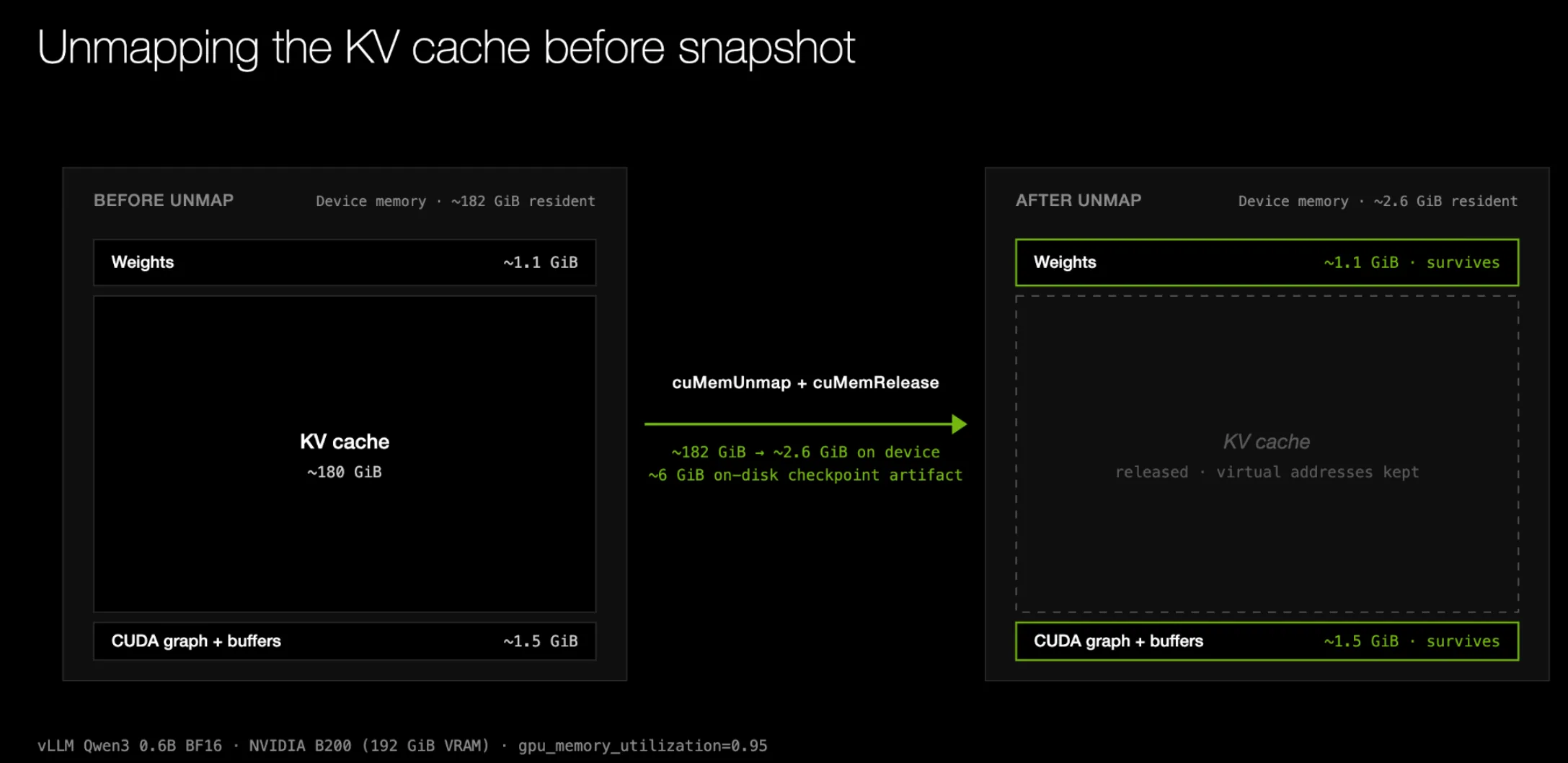
减少检查点大小的一种优化是在进行检查点保存之前释放 KV 缓存内存。在测量了权重、CUDA 图和其他缓冲区/激活占用的峰值 GPU 内存后,推理引擎会将剩余的 GPU 内存分配为一个大型 KV 缓存缓冲区。
由于我们的检查点保存时,副本尚未处理任何请求,处于静止状态,因此该 KV 缓存缓冲区本身无需被纳入检查点。但我们必须确保 KV 缓存的虚拟地址保持稳定,因为它已被写入 CUDA 图中。为此,我们通过 CUDA 虚拟内存管理 API(cuMemCreate 和 cuMemMap)来分配 KV 缓存缓冲区;随后,在保留虚拟地址不变的前提下,通过调用 cuMemUnmap 和 cuMemRelease 来释放底层的物理内存,而不是使用 cuMemAddressFree。幸运的是,vLLM 已原生支持这一机制(通过 sleep() 和 wake_up()),SGLang 同样原生支持(通过 torch_memory_saver)。
KV 缓存的取消映射和释放将 B200 上 Qwen3-0.6B 的总制品大小从约 190 GiB 降至约 6 GiB。收益在较大的 KV 缓存大小下最为显著(即相对于 GPU 大小而言,模型权重更小)。
优化 #2:加速 CRIU
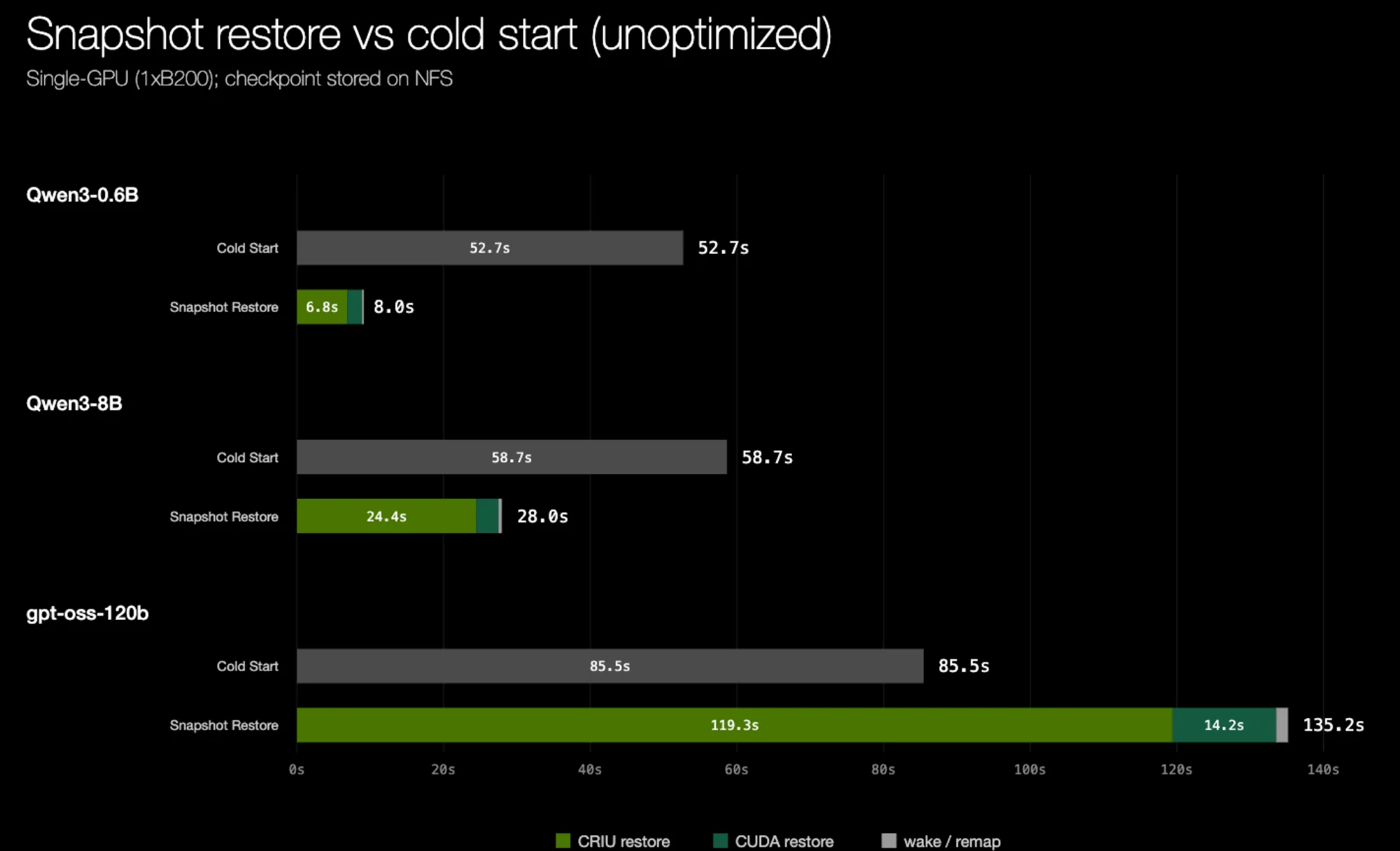
在这一点上,恢复时间仍然远远不能接受。对于更大或更大的模型,恢复时间实际上超过了冷启动时间,完全违背了检查点/恢复的初衷。
主要原因是,CRIU 和 cuda-checkpoint 无法以光速(SOL)速度复制内存。在 Linux 进程中,有两种类型的内存:匿名内存(进程的堆、栈等)和共享内存(进程之间共享)。CRIU 负责恢复这两种内存,而且对于大型模型来说,这两者都会成为显著的瓶颈。在本节中,我们概述了我们为 CRIU 开发的优化,以显著加快进程内存的恢复速度。
注: 这些 CRIU 优化尚未作为 Dynamo Snapshot 的一部分发布,待它们合并到上游 CRIU 后即可使用。
注 #2: 我们基准测试工作负载的覆盖文件系统非常小(<100 MiB),且在恢复时间中可忽略不计,因此省略。
优化 #2.1:并行 memfd 恢复
vLLM 的 sleep()/wake_up() 路径和 SGLang 的 torch_memory_saver(我们在 quiesce/resume 钩子中调用它)会将带权重标记的 GPU 分配移动到已锁页的 CPU 影子缓冲区中。这是进行高带宽主机到设备/设备到主机(H2D/D2H)内存拷贝的常见做法。CUDA 使用共享匿名内存来承载这些分配,然后通过 NVIDIA 驱动将其锁页。在 Linux 内核中,这些会显示为 memfd:一种匿名、由 RAM 支持的文件,可通过 MAP_SHARED 进行映射。
对于 gpt-oss-120b,这些缓冲区消耗了超过 120 GiB,分散在许多相互独立的、大小不超过 2 GiB 的缓冲区中。上游 CRIU 会串行恢复这些缓冲区:它先创建一个由 shmem 支持的对象,调整其大小,映射它,从检查点镜像中读取其内容,然后才继续处理下一个对象。
我们修改了 CRIU,先枚举所有唯一的、由 shmem 支持的对象,然后启动一个线程池并行恢复它们。每个工作线程独立分配自己的缓冲区并从检查点中读取,从而使恢复过程能够利用可用的存储带宽和 CPU 并行性,而不是一次处理一个缓冲区。
优化 #2.2:Linux 原生 AIO 用于匿名内存
在 CRIU 已经恢复了共享资源(文件、套接字、shmem 对象、memfd 等)之后,它仍然必须填充每个进程的私有内存:堆页、栈、匿名映射,以及写时复制的私有文件映射。这些页面不是共享的;它们属于某一个进程,并且需要落在它们在检查点之前所处的精确虚拟地址上。
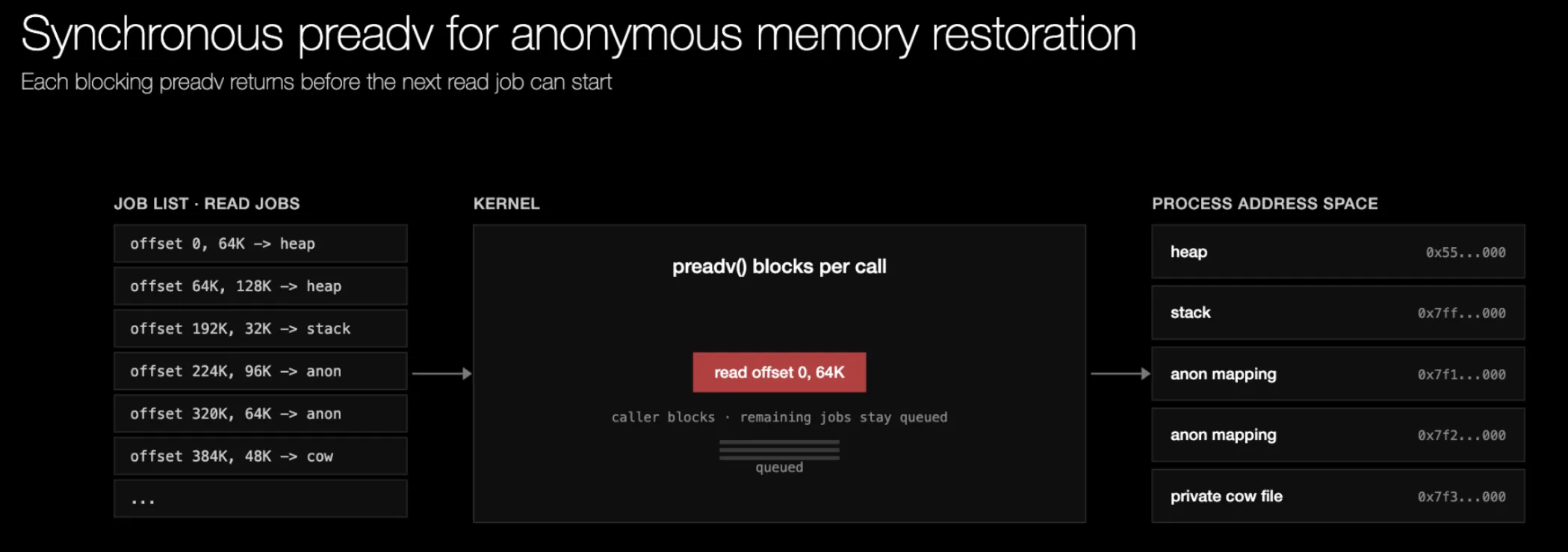
在上游 CRIU 中,该填充路径是一个同步的 preadv 循环。恢复器从列表中取出一个作业,把它交给 preadv,然后等待。内核对存储设备发出那一次读取,设备通过 DMA 将字节写入目标 VMA 页,随后 preadv 返回。只有到这时,恢复器才会继续处理下一个作业。任一时刻都只有一个读取在进行,这会使存储设备在请求之间处于空闲状态。单一的阻塞式流无法榨干高速 NVMe 的带宽,而在网络附加存储上,每次读取在下一次开始前还要额外承担一次往返延迟。
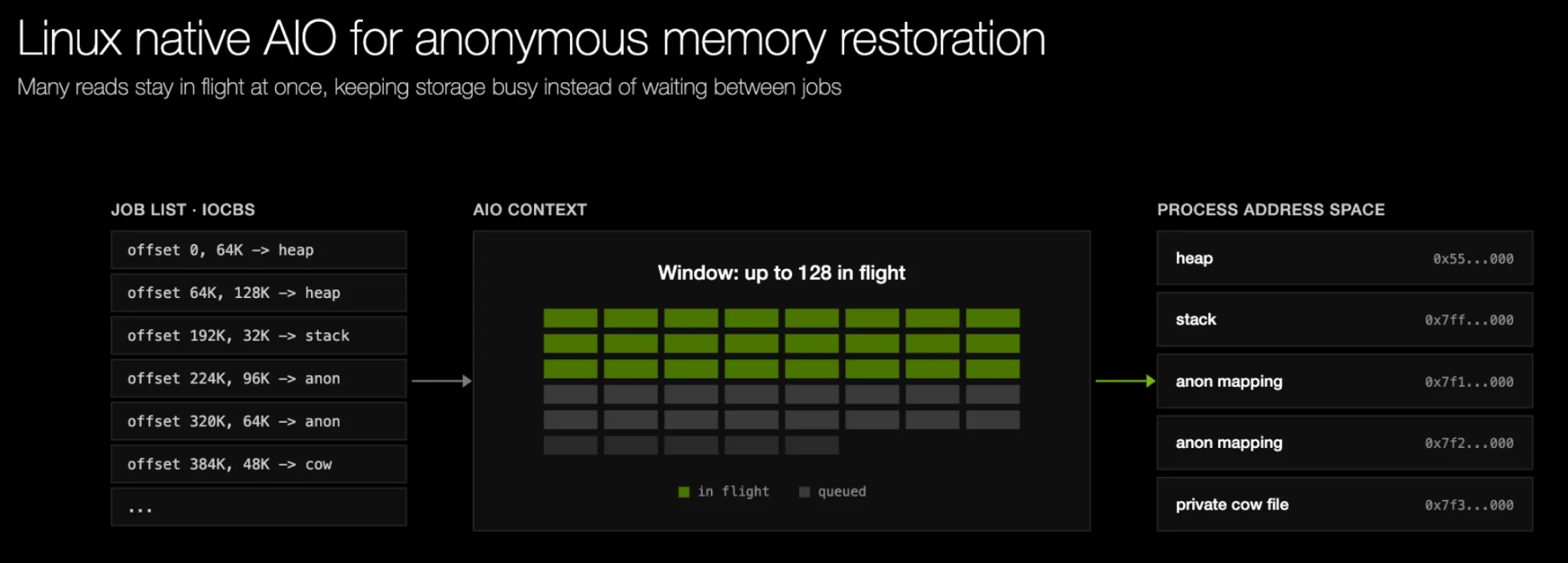
我们用 Linux 原生 AIO 替换了 preadv 循环。CRIU 会提前构建一个读取任务列表。每个任务都是一个 iocb,描述文件偏移量、字节数,以及一个指向目标 VMA 页面的 iovec。恢复器会创建一个 AIO 上下文,它可以同时保存许多不同的读事务,使存储设备能够通过其内部通道并发执行这些事务。恢复器会创建一个 AIO 上下文,提交一批带有 io_submit 的 iocbs,并保持最多 128 个读取处于飞行中状态。随着完成结果通过 io_getevents 返回,新的提交会补满这个窗口,直到每个任务都完成。
直接输入/输出和页面缓存
在存储后端支持的情况下,匿名内存和共享内存读取都会使用 O_DIRECT。恢复主要是从检查点文件到目标内存的一次性流式传输,因此把输入页缓存到内核页缓存中通常是浪费的。若不使用直接 I/O,较大的恢复过程会暂时用检查点数据填满页缓存,同时还要分配目标 shmem 页,从而增加内存压力,并把其他工作负载中有用的数据驱逐出去。
更重要的是,Linux 原生 AIO 只有在用 O_DIRECT 打开的文件上才真正是异步的。在 O_DIRECT 不可用或不可靠的文件系统上,例如某些 NFS 部署,restore 会回退到带有顺序预读的缓冲 I/O,因此内核仍然会看到一种可预测的流式访问模式,但 AIO 带来的收益会显著降低。
结果
在相同的设置下,我们观察到 CRIU 恢复时间大幅提升,现在从检查点恢复比冷启动推理工作线程要快得多:
| 模型 | 检查点大小 | CRIU(上游) | CRIU(AIO) | CRIU(AIO + 并行 memfd) | 较上游提速 | SOL |
|---|---|---|---|---|---|---|
| Qwen3-0.6B | 6.2 吉比特 | 6.8 秒 | 2.9 秒 | 2.4 秒 | 2.8x | 0.95 秒 |
| Qwen3-8B | 26 吉比字节 | 24 秒 | 11 秒 | 4.7 秒 | 5.1x | 1.8 秒 |
| gpt-oss-120b | 129 GiB | 119 秒 | 54 秒 | 15 秒 | 7.9x | 11 秒 |
memfd 恢复显著降低了恢复延迟,并在不同模型规模上接近光速(SOL)性能。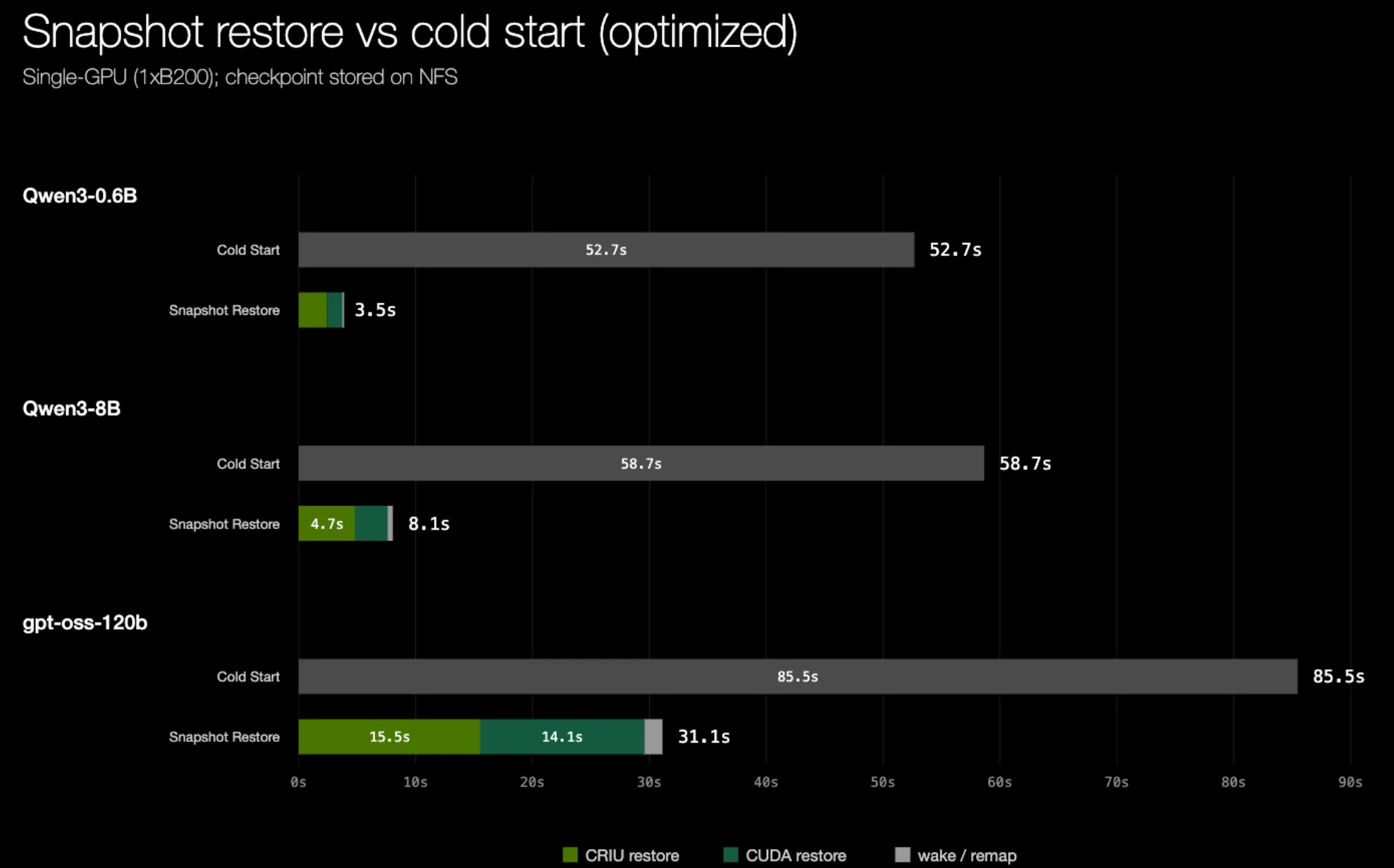
memfd 优化后的 CRIU 恢复时间此时 CRIU 的恢复时间已经大大接近 SOL,但端到端恢复时间仍主要受限于将大型模型权重按顺序从 PVC 经过主机内存再传到 GPU 的过程。这个过程本质上是串行的:在 CRIU 将这些权重物化到主机内存之前,cuda-checkpoint 无法恢复 GPU 内存。由于这些权重占据了检查点大小的大部分,把它们保留在 CRIU 镜像中会为恢复速度设下一个硬上限,并阻碍更快的、直接传输到 GPU 的通道。
优化 #3:GPU 内存服务
为消除这一瓶颈,我们开发了 GPU 内存服务(GMS)。GMS 使用 CUDA 虚拟内存管理(VMM)API,将大型模型权重与推理工作进程的进程生命周期解耦,并把进程内存的大部分卸载到一个单独的 GMS 产物中。
通过将权重从核心 CRIU 检查点中分离,GMS 使我们能够并行执行进程状态恢复和权重恢复,利用不同的内存带宽通道,而非串行处理。权重恢复现在可经由最快的可用路径进行,例如 GPUDirect Storage(GDS)或点对点 GPU RDMA/NVLink。CRIU 检查点已大幅精简,仅包含容器进程树的主机侧状态及少量双缓冲的杂项缓冲区,而 GMS 权重工件则承载了大部分进程内存,从而实现更快速的恢复。
| 模型 | CRIU 检查点大小(基线) | CRIU 检查点大小(含 GMS) | GMS 权重工件 |
|---|---|---|---|
| Qwen3-0.6B | 6.2 吉比字节 | 4.3 GiB | 1.2 吉比字节 |
| Qwen3-8B | 26 GiB | 4.8 吉比字节 | 15 吉字 |
| gpt-oss-120B | 129 吉比特 | 6.7 GiB | 74 吉比特 |
即使重量恢复通过 NFS 进行,我们也能看到显著的恢复时间加速:
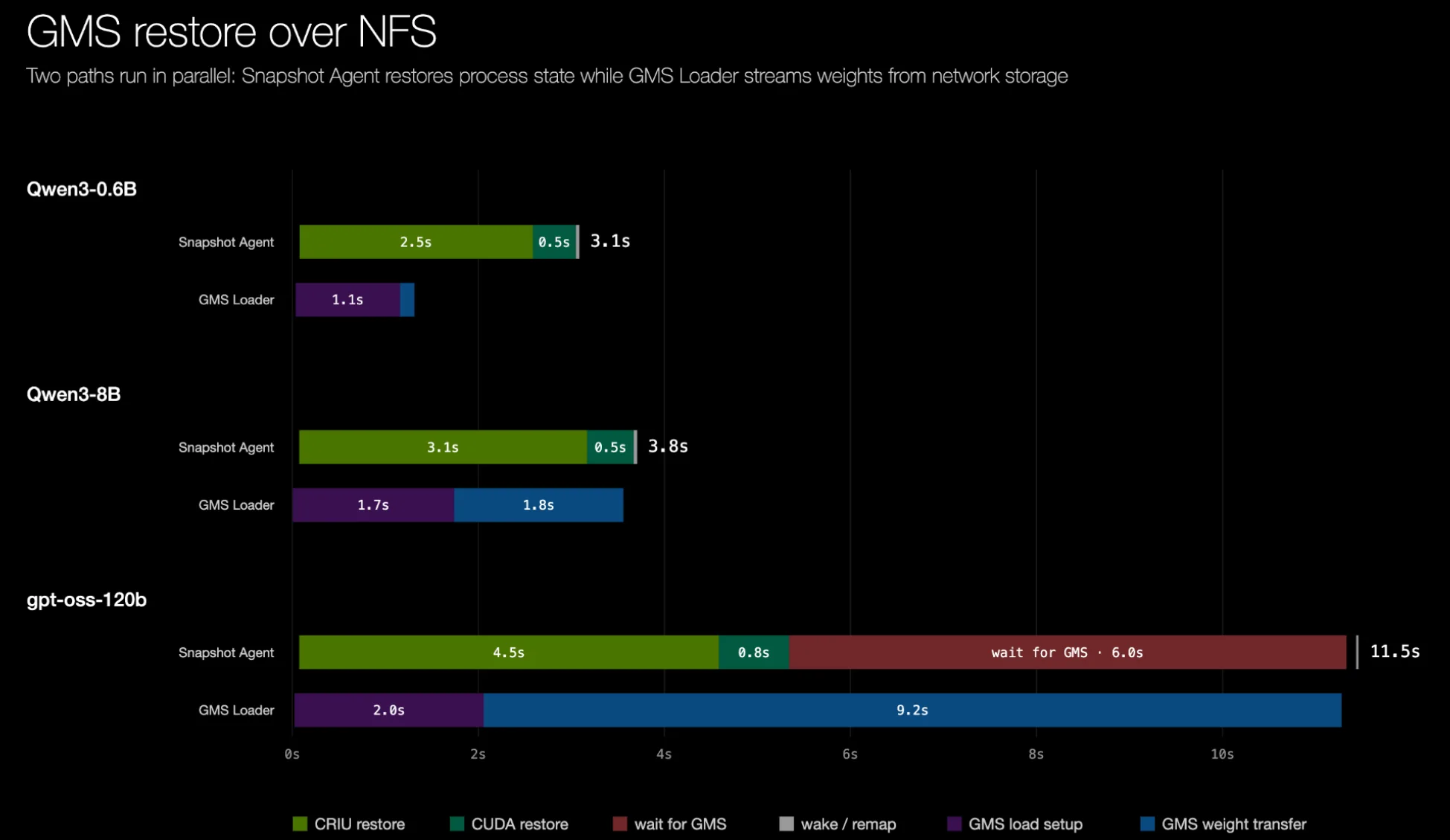
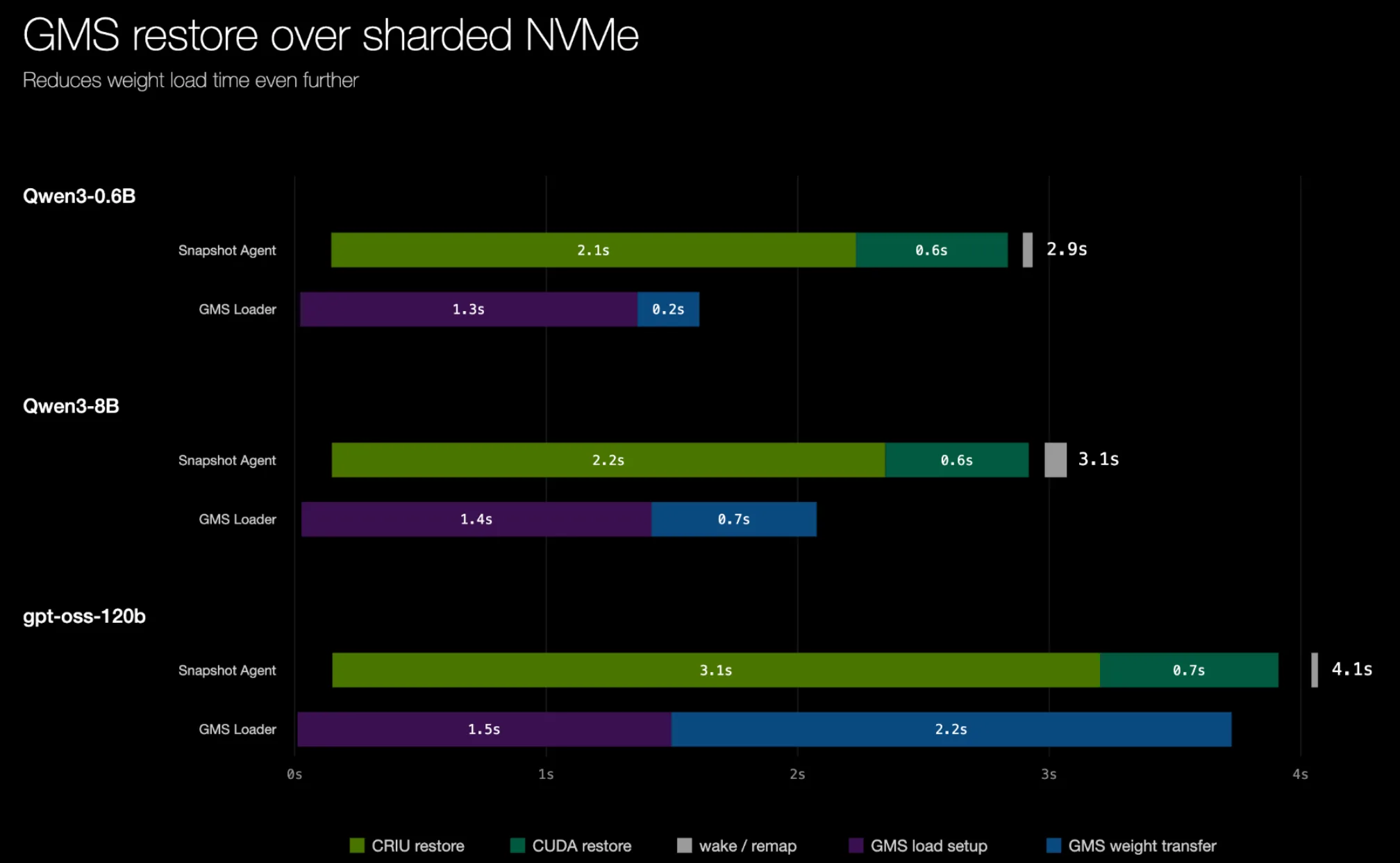
当权重通过另一条独立通道恢复时,我们才能真正看到解耦方法的优势——权重恢复可以在 CRIU 恢复尚未完成之前并行完成(前提是权重传输机制足够快)。下面是一个概念验证的权重恢复后端的结果:它将权重分条存储在 8 块本地 NVMe SSD 上——恢复过程可在 5 秒以内完成。最终结果是 gpt-oss-120b 的启动时间缩短了 21 倍。
可用性和路线图
目前我们已有初步证据表明,可以在 Kubernetes 上为推理工作负载实现快速启动。我们正致力于稳定该功能,并将其支持范围扩展至更广泛的工作负载。 Dynamo Snapshot 将在未来几个月内分阶段推出。
今天,该实验性发布通过非 GMS 检查点/恢复路径支持单 GPU vLLM 和 SGLang 工作负载。
我们目前正在整合以下功能:
- GMS 采用可插拔后端(GDS、UCX 等)的恢复路径,目前受待处理的 CUDA 驱动补丁限制
- TensorRT-LLM 支持
- 通过用于静默/恢复的钩子实现对 PyTorch、NCCL、NIXL 等的多 GPU 和多节点支持。