
下一波企业生产力浪潮将以AI工厂为基础。随着企业部署能够实现大规模推理、自动化和实时决策的代理式AI系统,竞争优势将日益取决于支撑这些系统的基础设施。
成功不仅仅依赖于强大的计算能力,还需要一个可扩展且可预测的基础架构,能够协调智能体、高效管理数据传输,并在从试点到生产的整个过程中保持稳定的性能表现。 由 NVIDIA 支持的 AI 工厂 将工业级的规范引入人工智能领域,把基础设施转变为推动速度、可靠性和加速创新的战略引擎。
基础设施是人工智能五大层级之一,也是人工智能工厂的基石。然而,构建这一基石不仅需要选择高性能硬件,还需要经过验证的架构指导,以降低集成风险、缩短部署周期,并确保大规模环境下的系统性能。 NVIDIA 企业参考架构 (Enterprise RA) 为本地部署提供基础设施指导,明确了计算、网络、存储、软件及系统组件应如何集成到具备生产就绪能力的 AI 平台中。
借助企业参考架构,企业可从实验阶段迈向可扩展的AI运营,生成词元,从而在工业规模上推动智能化和业务成果。 NVIDIA Enterprise AI Factory 经验证的设计 通过精选经 NVIDIA 认证的全套 NVIDIA 软件及生态系统合作伙伴软件,助力企业为其代理式 AI 工作负载高效运营 AI 工厂,进一步完善该架构。
基于 NVIDIA 认证系统,由 NVIDIA 与合作伙伴共同构建,NVIDIA 企业参考架构旨在帮助企业部署和扩展本地 AI 工厂。这些参考架构涵盖 GPU 数量、内存、存储、网络和可观测性等方面,提供从硬件、软件、编排到监控的全栈集成,实现端到端的详细指导。经过 NVIDIA 认证的服务器节点,可作为企业 RA 集群的基本构建单元。
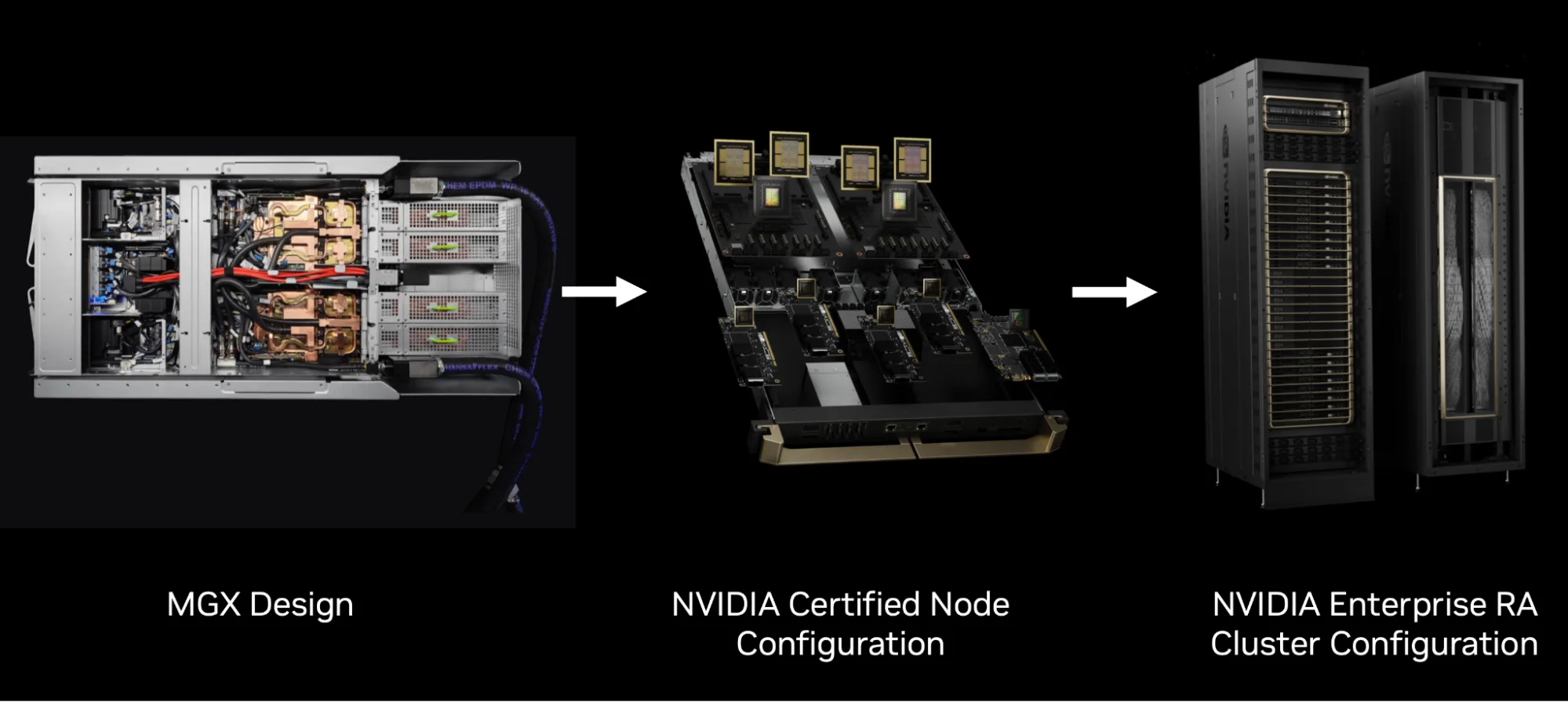
企业参考架构是 AI 工厂的基础
要构建 AI 工厂,可选择三种 NVIDIA AI Factory 配置来加速计算架构:NVIDIA RTX PRO AI Factory(搭载 NVIDIA RTX PRO 服务器)、NVIDIA HGX AI Factory(基于 NVIDIA HGX-based 系统)以及 NVIDIA NVL72 AI Factory(采用基于 NVIDIA GB300 NVL72 平台的机架级系统)。每种架构适用于不同的规模、基础设施需求、工作负载和性能目标。
企业组织可以从符合其迫切需求的配置和架构开始,并随着 AI 目标的扩展而扩展。成熟的 AI 部署通常包括上述 AI 工厂配置的混合产品组合,以优化各种不同推理、训练和视觉计算工作负载的性能。
NVIDIA RTX PRO AI Factory:通用加速器
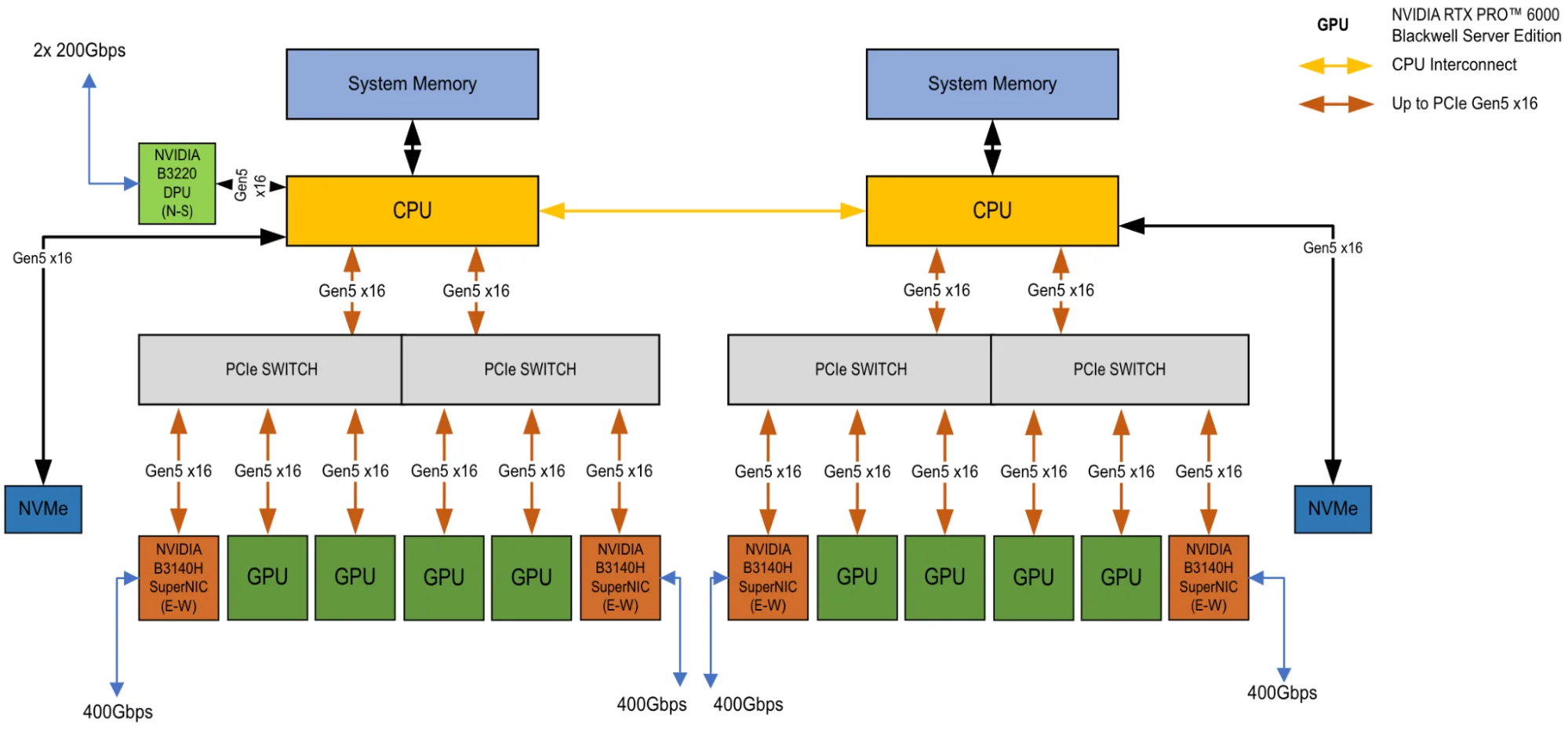
NVIDIA RTX PRO AI Factory 基于 2-8-5-200(CPU-GPU-NIC-东西向带宽)参考配置,为企业 AI 提供节能高效的模块化基础架构。该架构采用 NVIDIA RTX PRO Blackwell 服务器版 GPU 构建,专为中小型模型的推理、微调、生成式 AI、视觉计算及工业 AI 工作负载优化。企业可借此将 AI 深度融入核心业务流程,在标准企业数据中心空间内支持多模态代理系统、仿真、分析与渲染等应用。
每台 NVIDIA 认证的 RTX PRO 服务器最多可集成 8 个 GPU,采用灵活的风冷设计,提供强大的 AI 计算性能。通过集群部署,GPU 数量可从数十个扩展至数百个,并提供支持 128 和 256 GPU 集群的现成示例。借助高速 NVIDIA Spectrum-X 以太网 和 NVIDIA BlueField-3 加速技术,实现高效的东西向通信与安全的南北向数据传输,为企业的 AI 推理、数字孪生、视觉计算、科学计算以及大规模数据分析提供了坚实基础。
NVIDIA HGX AI Factory:为企业 AI 提供突破性性能
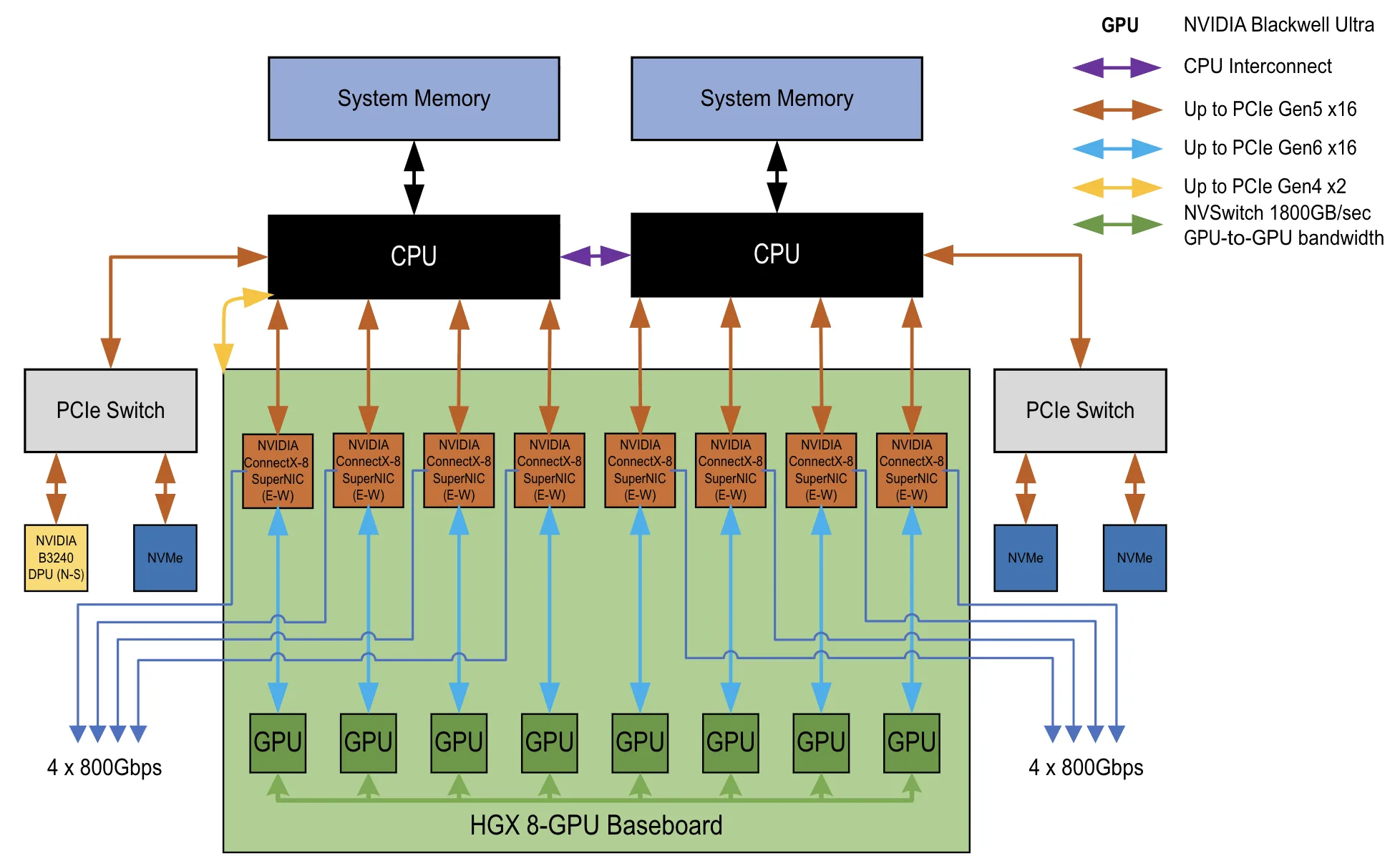
NVIDIA HGX AI Factory 配置是大多数大型企业在大规模训练、微调和部署 AI 模型时采用的标准基础架构。它专为在训练和推理工作负载中实现持续高效运行和性能平衡而设计。企业可依据 HGX AI Factory 架构部署部分集群,同时将其他集群部署在 RTX PRO AI Factory 架构上,后者正是 NVIDIA IT 内部运行自身 AI 工厂所采用的方案。
NVIDIA HGX AI Factory 基于 2-8 -9 -800 参考配置,专为训练和微调大语言模型或运行高吞吐量 AI 推理的组织而设计。它支持可预测的扩展,同时在需要 AI 性能和操作简便性的多用户企业环境中保持计算、内存和网络的效率。
NVIDIA HGX B300 平台的核心集成了 8 个通过第五代 NVIDIA NVLink 和 NVSwitch 技术互连的 NVIDIA Blackwell Ultra GPU,在单个节点内构建了一个高度集成、高带宽的计算单元。每个 GPU 配备高达 270 GB 的 HBM3 显存,单个节点的 GPU 显存总量可达 2.1 TB,专为大模型训练、微调以及中大型参数规模的 AI 推理工作负载优化设计。
采用NVIDIA Spectrum-X 以太网网络,采用NVIDIA ConnectX-8 SuperNICs,可为跨集群的东西向通信提供高达800 Gb/s的GPU带宽,有效减少分布式训练和大规模推理过程中的瓶颈。
NVIDIA NVL72 AI Factory:助力百亿亿次级 (Exascale) AI
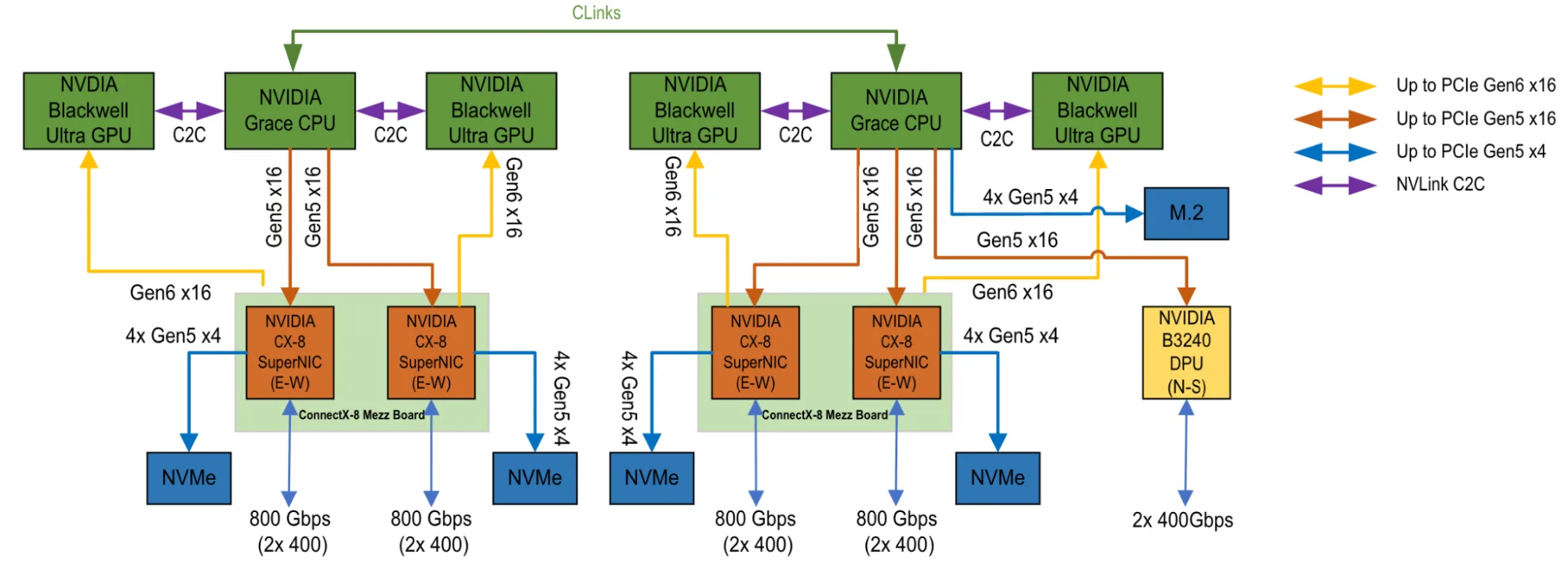
NVIDIA NVL72 AI Factory 是最先进的机架级平台之一,专为万亿参数模型和人工智能推理系统时代打造。该平台采用 NVIDIA GB300 NVL72 系统,可在每个机架中提供卓越性能,同时最大化提升计算、内存和网络资源的利用效率。
它专为需要大规模可扩展性的组织而设计,且不会影响可预测性或价值实现时间。该架构针对密集型企业 AI 工作负载进行了优化,包括大规模基础模型训练、微调、高吞吐量多租户推理和复杂的代理式 AI 工作流。
NVL72 AI Factory 是一个集成式液冷机架级扩展系统,由 36 个 Grace CPU 和 72 个 Blackwell Ultra GPU 组成,通过第五代 NVLink 互联。每个 GPU 都通过统一的高带宽 NVLink 结构与其他 GPU 进行通信,使机架能够作为单个连贯的计算域运行。这种紧密合的设计可更大限度地减少通信延迟,并消除传统集群架构中常见的瓶颈。集成的 NVIDIA ConnectX-8 SuperNIC 可确保用于 AI 训练和推理的高吞吐量东西向流量,而 NVIDIA BlueField DPU 可简化南北向数据流,从而使整个机架能够作为数据中心级的统一超级计算机运行。
基于 NVIDIA 企业参考架构 (RA) 的 AI 工厂配置提供了架构基础,但来自我们系统合作伙伴的经验证的实施建立了信心。我们的系统合作伙伴使用这些参考架构构建由 NVIDIA 设计评审委员会 (DRB) 进行技术评审的解决方案,并根据 NVIDIA 定义的标准和标准对其设计进行评估。
部分合作伙伴会验证堆栈的特定层级,而其他合作伙伴则会对涵盖硬件、软件和网络的完整端到端系统进行验证。符合这些要求的设计将被视为 NVIDIA 认可的解决方案,当前的认可合作伙伴及其产品列表可于 NVIDIA 企业参考架构文档 页面获取。
全球系统合作伙伴正提供基于企业参考架构的解决方案,这些方案已在多种规模场景下(从小型试点部署到大型AI工厂集群)经过测试。这种生态系统方法为企业带来了更高的透明度、更多选择以及更强的信心。
加快部署速度,降低 TCO
企业参考架构不仅限于系统工程,还可作为加速部署和长期效率的可行方案。它们旨在帮助组织:
- 突破基础架构的不确定性。
- 减少重新设计周期和运营开销。
- 将部署时间从几个月缩短到几周。
- 优化利用率和长期 TCO。
- 借助企业级支持,更大限度地延长正常运行时间并优化性能。
这些指南不仅提供技术指导,还能帮助企业清晰、自信地从概念验证顺利过渡到生产阶段。当结合NVIDIA Enterprise AI Factory经过验证的设计,企业可获得全栈式支持与指导,高效部署本地AI工厂,缩短实现价值的时间,并借助AI推动业务创新。
准备好开始了吗?
立即咨询您的系统制造商或专业合作伙伴,获取基于 NVIDIA 企业参考架构的解决方案设计。
- 阅读 NVIDIA 认证系统白皮书。
- 阅读 NVIDIA 企业参考架构白皮书。
- 阅读 NVIDIA Enterprise AI Factory 验证设计指南。
- 详细了解 NVIDIA 认证系统 和 NVIDIA 企业参考架构。