
在上一篇文章中,我们介绍了通用稀疏张量 (UST),使开发者能够将张量的稀疏性与其内存布局解,从而提高灵活性和性能。我们很高兴地宣布将 UST 集成到 nvmath-python v0.9.0 中,以加速稀疏科学和深度学习应用程序。
本文将介绍 UST 的主要特性、实现详情和性能概述,包括:
- 零成本互操作性: 使用 PyTorch、SciPy 和 CuPy 实现无数据移动转换。
- 自定义格式:定义新型稀疏方案。
- 多态运算: 与稀疏无关的函数会自动使用优化的内核或生成自定义稀疏代码,从而无需手动对新格式进行编码。
- PyTorch 注入: 轻松地将 UST 的性能优势注入到现有的 PyTorch 模型中。
- 透明缓存: 避免 JIT/ LTO 重新编译和重新规划,即在后续重复执行相同操作时减少开销。
张量格式 DSL
UST 使用简单的领域特定语言 (DSL) 描述常见 (例如,COO、CSR、CSC 和 BSR) 和不太常见的稀疏张量存储格式。例如,对 CSC 格式的描述如下。
(i, j) -> (j : dense, i : compressed) # CSC |
在编程语言中集成此 DSL 需要做出设计决策并进行各种权衡。
例如,在 C++ 库 MatX 中,DSL 完全通过类型和模板实现,从而为特定存储格式实现有趣的编译时优化。例如,在以下调度方法 foo() 中,可以在编译时评估特定于格式的测试,这意味着只编译和发送相关分支,以较小的二进制大小换取略高的编译时间。
template<TensorType> foo(TensorType a) { if constexpr (TensorType::Format::isCOO()) { ... dispatch to COO code ... } else if constexpr (TensorType::Format::isCSR()) { ... dispatch to CSR code ... } else ...} |
在 nvmath-python 中,我们采用更 Pythonic 的方式来呈现 DSL,在检查格式对象时,以运行时灵活性换取一些性能。例如,上面显示的 CSC 格式表示如下。
i, j = ( Dimension(dimension_name="i"), Dimension(dimension_name="j") )CSC = TensorFormat( [i, j], {j: LevelFormat.DENSE, i: LevelFormat.COMPRESSED} ) |
这些对象的一个主要优势是可以在运行时动态构建所有对象 (包括从字符串解析) 。但是,执行格式特定的任务需要在运行时检查实际内容。由于此类决策通常在性能关键型路径之外进行,因此权衡通用性似乎是一个可以接受的选择。
与 PyTorch、SciPy、CuPy 的互操作性
nvmath-python UST 实现提供与 PyTorch、SciPy、CuPy 和 NumPy 张量的互操作性。转换过程通常为零成本,这意味着将 COO、CSR、CSC、BSR、BSC 和 DIA 等密集或稀疏格式转换为 UST 对象或返回时无需进行数据移动或复制。相反,UST 对象会引用原始数据结构的存储缓冲区。
例如,将 COO 格式的 SciPy 稀疏矩阵转换为 nvmath-python UST 对象时,会使用行、列和值数组来形成 UST 的位置、坐标和值数组。
row = np.array([0, 0, 1, 1, 2, 3], dtype=np.int32)col = np.array([0, 1, 1, 3, 2, 3], dtype=np.int32)val = np.array([1, 2, 3, 4, 5, 6], dtype=np.float32)coo = sps.coo_array((val, (row, col)), shape=(4, 8)) # SciPyust = Tensor.from_package(coo) |
此转换会自动为首席运营官 (COO) 生成 DSL,如下所示。转换其他格式将生成这些格式对应的 DSL。
TensorFormat( [i, j] -> {i: (<LevelFormat.COMPRESSED>, <LevelProperty.NONUNIQUE>), j: <LevelFormat.SINGLETON>} ) |
将 UST 对象转换回原包中的稀疏张量,如下所示。这也是零成本转换,只需传递对成分缓冲区的引用即可。
coo = ust.to_package() # this yields a SciPy coo format again |
不太常见的格式
开发者还可以使用 DSL 定义自己的新型稀疏格式。例如,以下代码将密集的 PyTorch 张量转换为 2 位增量压缩格式 (类似于 CSR,但对坐标使用运行时差异) ,PyTorch 不原生支持该格式。
A = torch.tensor([[1, 0, 0, 0, 0, 0, 0, 2], [0, 0, 3, 4, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 5]], dtype=torch.float64)U = Tensor.from_package(A) # dense USTdelta_format = TensorFormat([i, j], {i: LevelFormat.DENSE, j: (LevelFormat.DELTA, 2)}) # use 2-bitS = U.convert(tensor_format=delta_format) # sparse UST |
这将生成图 1 所示的稀疏 UST 存储,其中每个坐标使用与下一个存储元素的距离,而不是直接列索引。请注意,如果距离超过 3 (使用 2 位时最大值) ,则需要填充 ( 0 以红色显示) 。
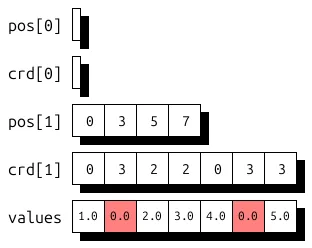
打印和绘图实用程序
提供各种实用程序,帮助用户调试、测试和熟悉 nvmath-python UST 实现。首先,dunder 方法 __repr__ 提供明确的字符串表示,可用于打印张量存储内容。
A = torch.arange(4 * 5).reshape(4, 5).cuda().to_sparse_csr()U = Tensor.from_package(A)print(U) |
此代码段会产生以下输出,其中显示了用于以下存储的类型 (int64) 、UST 存储中的位置和坐标数组 (也称为 int64) 、设备 (cuda) 、维度和级别范围、存储数据、用于存储的字节数摘要 (5* 8* 19* 8* 19* 8) 以及稀疏性 ( ( ( 1 – 19/ 20) x 100%) 。
---- Sparse Tensor<VAL=int64,POS=int64,CRD=int64,DIM=2,LVL=2>format : [i, j] -> (i: <LevelFormat.DENSE>, j: <LevelFormat.COMPRESSED>)device : cudadim : [4, 5]lvl : [4, 5]nse : 19pos[1] : [0, 4, 9, 14, 19] #5crd[1] : [1, 2, 3, 4, 0, 1, 2, 3, 4, 0, 1, 2, 3, 4, 0, 1, 2, 3, 4] #19values : [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19] #19data : 344 bytessparsity : 5.00%---- |
draw_storage () 和 draw () 方法可生成张量存储 (任何维度) 或张量内容 (最高支持 3D) 的图像。使用前一种方法生成图 1. 在上一个 UST 示例中调用后一种方法会得到图 2 所示的图像,其中灰色表示存储的非零元素 (在本例中几乎是所有元素) 。
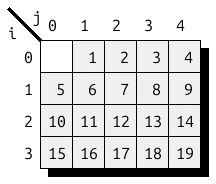
这两种方法都针对相对较小的示例显示了 UST,因为它们不会扩展到非常大的规模。对于较大的张量,可以使用 draw_raw () 方法 ( 2D 或 3D) 来获得张量非零结构的可视化,如图 3 所示,该矩阵取自 SuiteSparse 库。
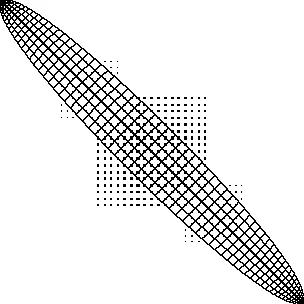
多态运算
UST 的张量格式 DSL 使开发者能够专注于张量稀疏性。然而,定义张量的存储只是其中一部分要求。开发者还可以指定要执行的操作。
借助 nvmath-python UST 实现,开发者能够使用与稀疏性无关的运算 (例如 matmul() 和 solve(),不同于张量索引表示法等替代方法) 来定义计算。这种方法功能强大,因为系统会检查操作数格式以确定执行路径:将常用格式分配到优化的手写库或内核,或者在没有优化解决方案的情况下依靠自动稀疏代码生成。
这种设计允许使用新的稀疏格式,无需显式手动编码,同时仍然通过使用现有的标准格式库解决方案实现高性能。规划和执行 matmul() 操作的语法如下所示。按照 nvmath-python 约定,操作可分为规划阶段 (决定在调度或 JIT LTO 代码生成之间作出决定,缓存以供将来重复使用,并设置所有必要参数) 和执行阶段 (执行实际操作) 。
# c := a @ b + cwith Matmul(a, b, c, beta=1.0) as mm: mm.plan() mm.execute() |
这种方法通过多次执行相同的 matmul() 调用来分摊初始规划成本,这在深度学习中的迭代稀疏求解器或 (剪枝) 线性层等方面确实有回报。
将 UST 注入 PyTorch
PyTorch 稀疏张量与 nvmath-python 之间的互操作性使开发者能够在 PyTorch 模型中试验新型稀疏存储方案。虽然 AI 研究人员功能强大,但他们不愿意重写模型代码,将在线性层中执行的 GEMM 运算替换为上面所示的 UST 多态运算,即使这样可以获得更好的性能。
UST 的 nvmath-python 实现提供了一种将 UST“注入”到现有模型中的方法,而无需重写原始模型代码。这是通过将 UST 封装到 Torch.Tensor 的子类中,并为 UST 的多态运算提供封装器来实现的。通过为常见的 PyTorch 张量运算 (例如点、mv、毫米和线性) 提供封装器,研究人员可以使用 UST,而无需学习许多内部工作原理。
这些封装器还添加了另一个缓存层 (在已缓存的 JIT/ LTO 查找之上) ,以便在类似操作中重复使用计划中的 MatMul 实例,从而将后续运行时间缩短到仅执行阶段。
此外,还提供 reformat_model() 方法,该方法可迭代所有线性层的权重,并使用户定义的函数能够检查、裁剪和稀疏 (或跳过) 每个权重矩阵
weights = torchvision.models.get_model_weights(model_name).DEFAULTmodel = torchvision.models.get_model(model_name, weights=weights)model.to(device)model.eval()...reformat_model(model, func=reformat)... with torch.inference_mode(): prediction = model(batch) |
用户提供的格式化方法的一般形式如下所示。返回“None” (无) 信号,使权重矩阵保持不变。之后,推理将对所有已修改的线性层应用使用 UST。
def reformat(weight): ... inspect (possibly even prune weight), then decide on storage ... if (...) return TorchUST.from_torch(weight.to_sparse_csr()) return None} |
性能示例
首先,我们比较使用 CuPy 的 @-操作在原生支持格式 ( COO、CSR 和 DIA) 上的 SpMV 性能,以及用于 COO 和 CSR 的 PyTorch mv () 与在 Matrix Market 的 1,489,752 x 1,48,9752 矩阵 atmosmodl 上使用 UST 的 matmul() 的性能。对于后者,我们仅测量 execute() 运行时,这对于具有重复乘法的应用程序来说是一个公平的比较 (因为 CuPy 和 PyTorch 都没有提供规划设置) 。生成的运行时如图 4 所示 (使用垂直轴的对数刻度) 。
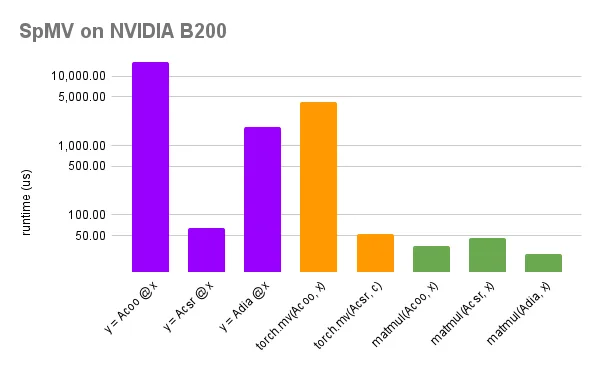
在这种情况下,UST 实现了从 1.1 到 444 的加速。我们注意到 CuPy 和 PyTorch COO 实现的性能不佳。对于 CSR 格式,所有版本都使用 cuSPARSE 实现,而 UST 从规划阶段的重复使用中受益。与 CuPy 首先转换为 CSR 的方法 (以及 PyTorch 缺乏 DIA) 相比,DIA 格式的加速是由于 UST 使用了专门的内核。
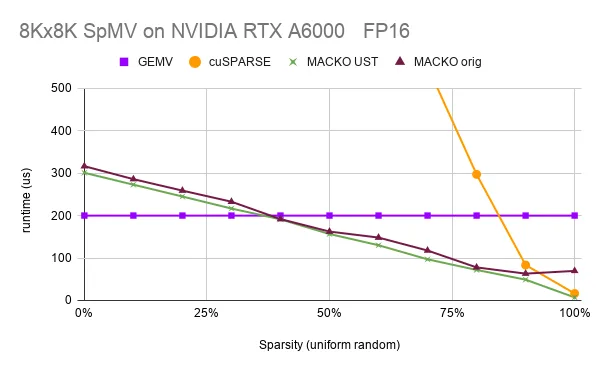
第二个实验基于出版物 MACKO:用于低稀疏的稀疏矩阵向量乘法,该出版物提供了 SpMV 运算的高效实现,这是深度学习中 single-词元推理的重要步骤。作者介绍了 MACKO 格式,该格式本质上是图 1 中的增量压缩格式,并提供了一个令人印象深刻的 NVIDIA CUDA 实现,它已经为 50% 的非结构化稀疏和更高提供了比密集实现更快的速度。
由于 nvmath-python UST 提供了一种在查找机制中整合新的手写内核的简单方法,因此我们尝试将其实现用作增量压缩格式的后端内核实现。图 5 比较了密集实现 (GEMV) 的运行时、SPMV 的 cuSPARSE 实现、MACKO UST,以及 8192 × 8192 均匀随机稀疏矩阵 (从 0 = 稀疏 (密集) 到 100% 稀疏 (零) 不等) 的原始 MACKO 实现。MACKO UST 的性能稍好一些,因为填充会在每行的末尾停止 (当然,原始 MACKO 也可以轻松整合这种优化) 。
了解详情
如需更深入地了解 nvmath-python UST 实现,请参阅 nvmath-python 在线文档。