
Slurm 是适用于 Linux 的开源集群管理和作业调度系统。它可以管理超过 65% 的 TOP500 系统 的作业调度。大多数运行大规模 AI 训练的组织在 Slurm 作业脚本、公平分配政策和会计工作流方面都有多年的投资。挑战在于将 Slurm 调度功能引入 Kubernetes (用于大规模管理 GPU 基础设施的标准平台) ,而无需维护两个独立的环境。
Slinky 是由 SchedMD (现为 NVIDIA 的一部分) 开发的开源项目,采用两种方法进行集成:
- slurm – Bridge将 Slurm 调度引入原生 Kubernetes 工作负载,允许 Slurm 充当 Pod 的 Kubernetes 调度程序
- slurm – Operator在 Kubernetes 基础架构上运行完整的 Slurm 集群,以 POD 形式管理 Slurm 守护程序的完整生命周期
本文重点介绍 slurm-operator,即 NVIDIA 如何在 Kubernetes 上为大规模 GPU 训练集群运行 Slurm。它将介绍 Operator 的架构以及如何将 Slurm 守护程序映射到 Kubernetes 基元,然后介绍部署,包括 Slinky slurm – Operator 如何与现有基础设施集成。它还介绍了 Kubernetes 生态系统集成,这些集成使得此模型切实可行。最后,我们分享了 NVIDIA 在拥有 1000 多个 GPU 工作节点和 8000 多个 GPU 的集群上在生产环境中运行 Slinky 的经验教训。
Slinky slurm – Operator 的工作原理是什么?
Slinky slurm-operator 将每个 Slurm 组件 ( slurmctld 用于调度,slurmdbd 用于会计,slurmd 用于计算工作者,slurmrestd 用于 API 访问) 表示为 Kubernetes 自定义资源定义 (CRD) 。Slinky 使用自定义资源定义 Slurm 集群,并创建容器化的 Slurm 守护程序,这些守护程序在其自己的 Pod 中运行,配置为属于各自的集群。
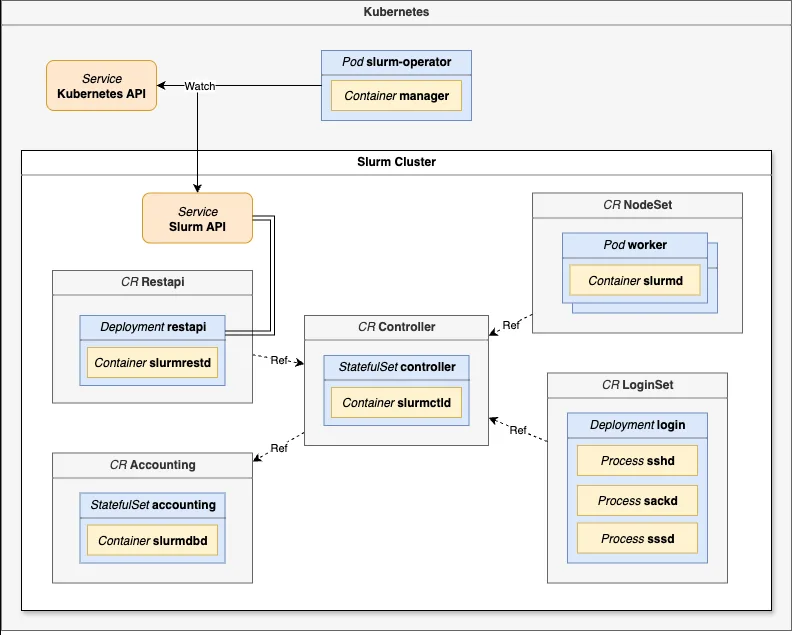
Slinky 可通过 Pod 再生确保 Slurm 控制平面 (slurmctld) 的高可用性 (HA) ,无需 Slurm 原生 HA 机制。配置更改会自动传播:Kubernetes 将安装的配置 ( ConfigMaps 和 Secrets) 同步到控制平面 Pod 中,该 Pod 会检测更改,并将新配置传播到其工作节点 (slurmd) ,且不会造成调度器停机。
使用 Slurm 原生 OpenMetrics 支持和 Prometheus 监控 (从 Slurm v25.11 起) ,可以根据集群指标和所需扩展策略,通过 HorizontalPodAutoscaler (HPA) 自动扩展工作节点,从单个 Pod 扩展到每个可用的工作节点。在横向扩展时,Slinky 会在终止 POD 之前完全耗尽 Slurm 节点,确保运行工作负载首先完成。Slinky 会优先处理工作负载完成时间最短且可横向扩展的 POD。在推出新的 worker pod 镜像 (例如,更新的 Slurm 版本或操作系统补丁) 时,也适用相同的提前终止流程,因此升级不会中断运行作业。
如何部署 Slinky slurm – Operator
在 Kubernetes 上使用 Slinky 部署的 Slurm 集群的工作方式与非容器化 Slurm 部署类似。Slinky slurm-operator 可自动启用容器化操作所需的 Slurm 功能:
- 无配置无共享文件系统的配置分发模式
- 动态节点因此,worker 在启动时注册,而无需在
slurm.conf中进行预定义 - auth/ slurm使用use_client_ids用于集群范围内的用户身份验证,而无需按节点身份服务
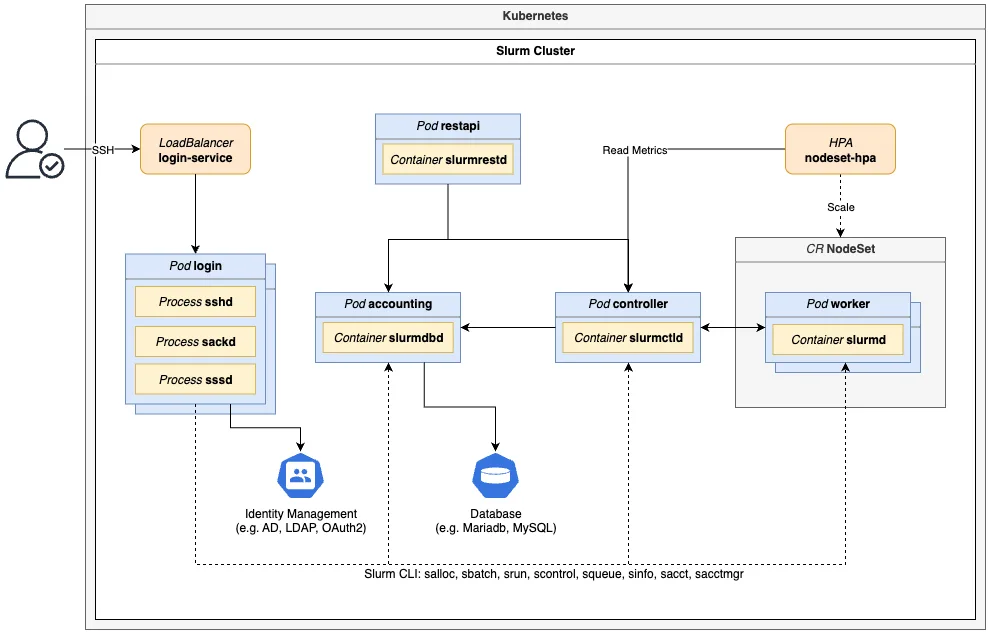
Slinky 可与您现有的数据库和身份基础设施配合使用。Slurm 记帐 (slurmdbd) 连接到任何兼容 MySQL 或 MariaDB 的数据库,无论是在集群内运行,还是作为外部托管服务运行。登录 Pod 的身份管理通过 SSD 进行,因此 Active Directory、LDAP 或任何其他受支持的后端无需更改即可集成。Slurm 25.11 允许 slurmd 在其容器内执行资源隔离 (cgroups v2) 。这意味着同一 worker 上的多用户并发工作负载完全独立。
Slinky 为每个 Slurm 组件提供参考容器镜像和 Docker 文件。您可以直接使用它们,使用自己的库和依赖项扩展它们,或者构建完全自定义的镜像,只要它们包含正常运行的 Slurm 安装。
在 Kubernetes 上运行 Slurm 有什么好处?
在 Kubernetes 上运行 Slurm 的操作收益来自生态系统。无需为 GPU 管理、监控、网络和节点生命周期构建和维护单独的工具链,您可以使用现有的 Kubernetes 工具来解决这些问题。平台团队通过声明性 YAML、Helm 部署、滚动更新以及 Prometheus 或 Grafana 实现可观察性来管理集群。
使用 NVIDIA GPU Operator 自动管理 GPU
NVIDIA GPU Operator 可自动执行 GPU 驱动程序安装、容器运行时配置和设备插件部署,使工作 pod 能够自动访问 GPU。
NVIDIA GPU Operator 还部署了 GPU 遥测收集器 DCGM Exporter。借助 Slinky DCGM 集成 和 HPC 作业映射支持,您可以启用使用 Slurm 作业 ID 标记的每项作业 GPU 指标,从而在整个集群中实现工作负载级 GPU 监控。
为此,请将以下内容添加到 NVIDIA GPU Operator Helm 值中:
dcgmExporter: hpcJobMapping: enabled: true directory: /var/lib/dcgm-exporter/job-mapping |
工作 pod 安装相同的目录,允许 Slurm prolog/epilog 脚本 (在作业开始和完成时运行) 编写 DCGM Exporter 自动获取的作业映射文件。
支持计算域的多节点 NVIDIA NVLink
对于 NVIDIA GB200 NVL72 等 GPU 架构,GPU 通过多节点 NVIDIA NVLink 进行跨节点通信,Slinky 支持访问 ComputeDomains。这是 NVIDIA DRA 驱动 提供的 Kubernetes 抽象,可动态管理节点间内存交换 (IMEX) 域,以实现高带宽 GPU 到 GPU 连接。
在 NVIDIA 部署中,Slinky 使用集群范围内的 ComputeDomain (numNodes: 0) ,在节点加入或离开集群时自动从 IMEX 域中添加和删除节点。这提供:
- 块拓扑感知:Slinky 集成了地形图该命令会自动发现集群的 GPU 块拓扑结构动态资源分配 (DRA)和标签由 NVIDIA GPU Operator 发布。
- IMEX 插件:Slurm 配置了
SwitchType = switch/nvidia_imex,以使用 NVIDIA IMEX 进行跨节点 GPU 通信。 - 拓扑感知调度:Slurm 25.11 支持带有
TopologyPlugin=topology/block的TopologyParam=BlockAsNodeRank,确保对分配进行排序,以便应用程序可以按节点秩发现段。
分布式训练作业可跨节点边界实现完整的 NVLink 带宽,而 ComputeDomains 会在工作负载运行到完成阶段时自动创建并拆解 IMEX 域。
双向状态同步
Slinky 可同步 Kubernetes 和 Slurm 在两个方向上的状态。Slurm 节点状态 (空闲、分配、混合、关闭、耗尽、完成、未响应) 会反映为 Pod 条件,从而让操作员能够通过标准 Kubernetes 工具查看 Slurm 状态。
当您使用 kubectl drain 将节点取出进行维护时,漏电状态和推理会自动同步到 Slurm。运行活动工作负载的 Pod 受 PodDisruptionBudgets 保护,因此进行中的作业不会被意外驱逐。
大规模 Slinky Slurm – Operator
NVIDIA 在生产环境中跨多个集群运行 Slinky slurm-operator,部分部署可扩展至 8000 多个 GPU。这些集群每天运行大规模 LLM 训练和多节点推理工作负载。GPU 通信基准测试 ( NCCL all-reduce 和 all-gather) 与非容器化 Slurm 部署的性能相匹配,并且 Slinky 运行的 Kubernetes 层不会产生可衡量的影响。使用 Helm 图表和声明性配置,新集群可在几个小时内从零开始运行作业,无需手动调配。在这种规模下,在 Kubernetes 化合物上运行 Slurm 的操作优势如下:
- 统一监控:Prometheus 可抓取 Slurm 指标 (作业、节点、分区、调度器延迟) 以及标准 Kubernetes 指标,而 Grafana 控制面板会在单个视图中同时显示这两个指标。HPC 没有单独的监控堆栈。
- 自动修复:当运行状况检查将某个节点标记为不健康节点时,状态将自动从 Kubernetes 同步到 Slurm,并且在两个系统中都可以看到相同的原因。Slurm 会耗尽节点,将作业调度到运行良好的硬件,并且团队不再需要单独协调 K8 和 Slurm 工具。
- 无中断滚动更新:更新数百张需要停机的工人 Pod 图像。借助保护正在运行的作业的
PodDisruptionBudgets,我们现在推出 Slurm 版本更新和操作系统补丁,同时在剩余容量上继续不间断地训练作业。 - 维护协调:标准 Kubernetes 节点漏极同步到 Slurm。作业顺利完成,维护继续进行,然后将节点重新联机,自动将其恢复到 Slurm 集群。
- 熟悉的工具:平台团队使用 kubectl 进行日常运营。Pod 条件会显示 Slurm 状态 (空闲、分配、排水) ,而无需访问 Slurm CLI,这意味着随叫随到的工程师可以使用处理其他所有内容的相同工具对 Slurm 问题进行分类。
需要注意的一个限制条件是:Slinky 的 slurm-operator 目前假设每个节点有一个 worker pod。如果您的工作负载完全是单节点 Slurm 作业,则这种相对于您所需内容的过度调配以及权重较轻的集成 (或 slurm-bridge) 可能更合适。Slinky 部署模型在多节点作业调度中得到了回报。
Slinky slurm – Operator v1.1.0 版本亮点
最近发布的 slurm-operator v1.1.0 填补了对生产部署至关重要的几个空白:
- Dynamic topology支持:在 v1.1.0 之前,Slurm 拓扑感知需要静态配置。在 v1.1.0 中,动态节点将基于运行 worker pod 的 Kubernetes 节点注册其拓扑,这意味着当 pod 在集群中移动时,拓扑感知调度可以正常工作。
- DaemonSet 式 worker pod 缩放:在 v1.1.0 之前,工作 pod 通过副本数量进行扩展。DaemonSet 风格的缩放将 Pod 与其
nodeSelector相关联,从而以 1:1 的比例静态映射 Slurm 到 Kubernetes 节点。这简化了集群的操作,其中每个 GPU 节点应始终运行 Slurm 工作进程。 - 未注册的 worker pod 修复:正常但未注册到 Slurm 集群的工作人员 Pod 将自动重新创建,从而缩小自我修复行为的差距。
从长远来看,该团队正在进行出色的 Slurm 集群升级、有计划的中断工作流、配置回滚和结构化守护程序日志记录。其目标是使 Slinky 操作模型符合平台团队对任何生产 Kubernetes 工作负载的期望:声明性、自我修复和可观察。
开始使用 Slinky slurm – Operator
Slinky 是开源的,现已推出。通过 Helm 安装 slurm-operator,将 Slurm 集群定义为自定义资源,您可以在一小时内在 Kubernetes 上运行作业。slurm-operator Quick Start Guide 将带您完成完整设置。
Kubernetes 是适合 GPU 计算的基础架构基板,而 Slurm 是极其强大的作业调度层,适用于在其上运行的工作负载。Slinky 使这种组合在生产中无缝发挥作用。我们计划继续投资,简化大规模 AI 训练基础设施的运行。如果您有任何疑问或想要分享您正在构建的内容,请访问 GitHub 上的 SlinkyProject 。